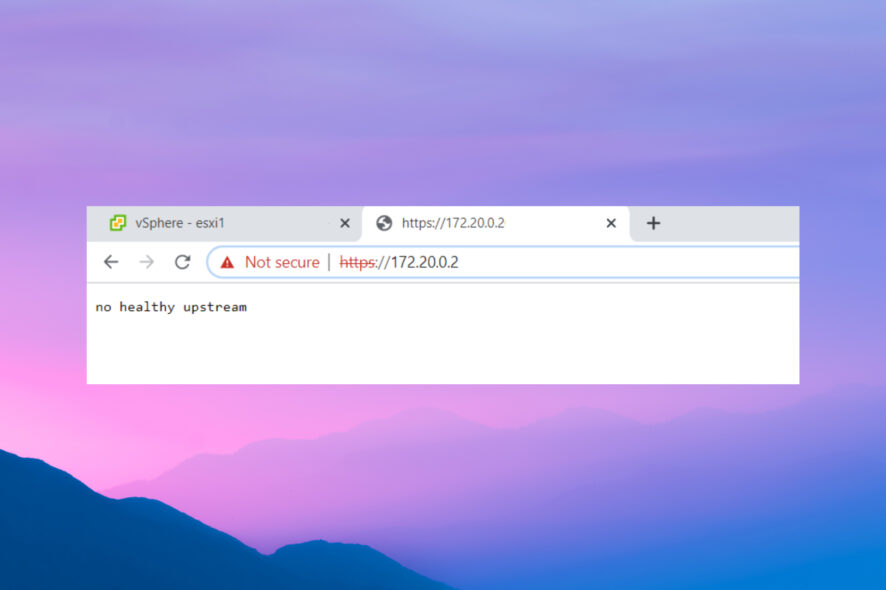
Ошибка «No healthy upstream»: причины и пошаговое решение
Проблемы с браузером? Попробуйте альтернативу: Opera One Более 300 миллионов человек ежедневно используют Opera One — полноценный браузер с встроенными инструментами, улучшенным потреблением ресурсов и современным дизайном. Что предлагает Opera One:
- Оптимизация использования ресурсов
- Инструменты с ИИ и удобный интерфейс
- Встроенный блокировщик рекламы
- ⇒ Установить Opera One
Многие читатели сообщали об ошибке no healthy upstream. Она возникает при попытке открыть разные сайты или веб-приложения. Ниже — обзор причин и конкретные шаги по исправлению.
Что означает No healthy upstream
Ошибка указывает на то, что балансировщик нагрузки, шлюз или прокси не видит доступных «здоровых» (healthy) бэкендов для передачи трафика. Простыми словами: у точки, принимающей запросы от клиентов, нет рабочего сервера для обработки этих запросов. Из‑за этого приложение может не отвечать или выдавать ошибки.
Определение терминов в одну строку:
- upstream — набор бэкенд-серверов, на которые прокси/балансировщик перенаправляет трафик.
Когда использовать это руководство
- Вы — пользователь веб‑приложения и видите ошибку: сначала сообщите администратору; выполните базовые проверки (обновите страницу, перезапустите браузер).
- Вы — администратор/инженер DevOps: используйте чеклист и команды ниже для диагностики и исправления.
Быстрая проверка для пользователя
- Обновите страницу (Ctrl/Cmd+R).
- Попробуйте открыть сайт в другом браузере или инкогнито.
- Проверьте подключение к интернету и VPN.
- Если ошибка сохраняется — свяжитесь с техподдержкой и приложите скриншот и время ошибки.
Диагностика для администратора: общий порядок действий
- Проверьте статус бэкенд‑сервисов (подов, экземпляров сервисов, VM).
- Проверьте правильность health‑check’ей и маршрутов.
- Просмотрите логи балансировщика/ingress/прокси.
- Убедитесь в корректности сертификатов и их сроков действия.
- Проверьте сетевые ACL/файрволы между компонентами.
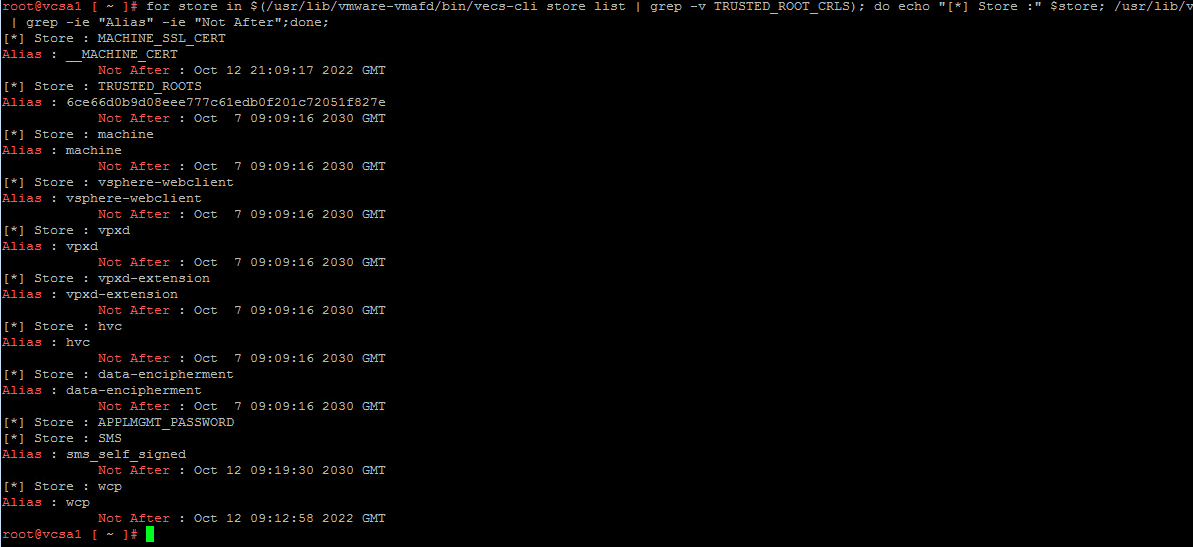
Проверка истёкших сертификатов (vCenter пример)
Если проблема проявляется в vCenter, сертификаты SSL могут быть просрочены. Последовательность действий для vCenter Appliance:
- Зайдите в vCenter Appliance.
- Выполните команду в shell для проверки всех хранилищ сертификатов:
for store in $(/usr/lib/vmware-vmafd/bin/vecs-cli store list | grep -v TRUSTED_ROOT_CRLS); do
echo "[*] Store :" $store
/usr/lib/vmware-vmafd/bin/vecs-cli entry list --store $store --text | grep -ie "Alias" -ie "Not After"
done- Посмотрите даты «Not After» для сертификатов Machine_SSL и Solution User. Если они просрочены — замените их.
Альтернатива в Windows/PowerShell для vCenter:
$VCInstallHome = [System.Environment]::ExpandEnvironmentVariables("%VMWARE_CIS_HOME%")
foreach ($STORE in & "$VCInstallHome\vmafdd\vecs-cli" store list){
Write-host "STORE: $STORE";
& "$VCInstallHome\vmafdd\vecs-cli" entry list --store $STORE --text | findstr /C:"Alias" /C:"Not After"
}Если вы не можете войти в систему, попробуйте сбросить root‑пароль и повторить проверку.
Частые причины и альтернативные подходы
- Health check неправильный или слишком строгий — откорректируйте путь и таймауты.
- Бэкенды упали — проверьте автоперезапуск, пул инстансов или масштабирование.
- Сетевые ошибки/ACL — проверьте правила между LB и бэкендами.
- Неправильная маршрутизация в Kubernetes (Ingress/Service) — проверьте аннотации, selector, endpoints.
Альтернативы устранения:
- Временно исключите health check, чтобы выполнить отладку (только для диагностики).
- Перенаправьте трафик на рабочий стек/канарный релиз.
Пошаговый чеклист для администратора (роль‑ориентированный)
Для системного администратора:
- Проверить состояние хостов/VM/подов.
- Просмотреть последние логи прокси/Ingress (ошибки соединений).
- Проверить health checks и их интервалы.
- Проверить сертификаты и дату окончания действия.
- Проверить сетевые правила (firewall, security groups).
Для разработчика/DevOps:
- Проверить конфигурации маршрутизации (route rules, ingress rules).
- Проверить readiness/liveness probes в Kubernetes.
- Проверить систему мониторинга и метрики (latency, error rate).
Диаграмма принятия решения
flowchart TD
A[Пользователь видит ошибку 'No healthy upstream'] --> B{Вы администратор?}
B -- Нет --> C[Сообщить техподдержке: время, URL, скриншот]
B -- Да --> D[Проверить статус бэкендов]
D --> E{Бэкенды работают?}
E -- Да --> F[Проверить health checks и маршрутизацию]
E -- Нет --> G[Перезапустить/масштабировать бэкенды]
F --> H{Сертификаты в порядке?}
H -- Нет --> I[Обновить/заменить сертификаты]
H -- Да --> J[Проверить сетевые ACL и логи]
J --> K[Исправить конфигурации и повторно протестировать]Когда этот метод не поможет
- Проблема на стороне внешнего поставщика (CDN, сторонний API). В этом случае свяжитесь с поставщиком.
- Клиентские ошибки (локальные расширения, прокси клиента) — попросите пользователя отключить расширения и проверить сеть.
Критерии приёмки
- Запросы успешно доходят до бэкенда и получают 2xx/3xx ответы.
- Monitoring показывает уменьшение ошибок 5xx и отсутствие ошибок «no healthy upstream».
- Проверка health checks проходит стабильно в течение N минут (в зависимости от SLA).
Важно: не меняйте настройки production‑балансировщика без предварительного теста в staging.
Короткое резюме
- «No healthy upstream» означает отсутствие доступных бэкендов для обработки запросов.
- Для пользователя: обновите страницу и сообщите администратору.
- Для администратора: проверьте бэкенды, health‑checks, маршруты, сертификаты и сеть.
Если руководство помогло — напишите в комментариях, какие шаги решили вашу проблему.
Важные заметки:
- Если ваше окружение использует Kubernetes, обратите внимание на Service Endpoints и readiness probes.
- Проводите замену сертификатов по согласованному плану с резервом и откатом.
Похожие материалы

kubectl logs: просмотр логов Pod в Kubernetes
Сортировка логов по столбцу — cut, awk, sort

Outlook не показывает имя отправителя — как исправить

Как отразить изображение — Adobe Express и Picsart

Как исправить ошибку «На компьютере недостаточно памяти»
