Сортировка и анализ логов по столбцу
Важно: перед обработкой логов убедитесь, что у вас есть права доступа на чтение файлов и что вы не нарушаете политику конфиденциальности при работе с персональными данными.
Почему сортировать по столбцу полезно
Сортировка логов по конкретному столбцу ускоряет поиск повторяющихся событий, частых IP, ошибок и шаблонов. Логи обычно хранятся в виде простого текста, поэтому стандартные утилиты командной строки дают быстрый и гибкий способ извлечения и анализа данных без тяжёлого визуального ПО.
Краткая дефиниция: cut — простая утилита для извлечения полей; awk — мощный текстовый процессор с поддержкой выражений и переменных; sort — сортировка, uniq — удаление или подсчёт дубликатов; grep — поиск по строке.
Извлечение столбцов: cut и awk
Если ваш лог имеет разделитель по пробелам или табуляции, вы можете использовать cut или awk для извлечения нужных колонок. Проблема возникает, когда данные внутри колонки содержат пробелы (например, даты “Wed Jun 12”), и тогда одно поле фактически представлено несколькими токенами.
cut прост в использовании, но менее гибок:
cat system.log | cut -d ' ' -f 1-6Пояснение: -d ' ' указывает разделитель (пробел). -f 1-6 выводит первые шесть полей. Для третьего столбца используйте -f 3.
awk разделяет строку по пробелам по умолчанию и хранит поля в переменных $1, $2, $3 и т.д. Простейший пример:
cat system.log | awk '{print $1, $2}'awk выполняет тело команды для каждой строки. Переменная $0 содержит всю строку. Например, чтобы вывести третий столбец перед всей строкой:
awk '{print $3 " " $0}'Чтобы избежать дублирования третьего столбца, можно временно очистить поле и затем распечатать строку:
awk '{printf $3; $3=""; print " " $0}'Или исключить первые три столбца при печати:
awk '{$1=$2=$3=""; print $0}'Подсказка: если у вас логи с кавычками или с временными метками, содержащими пробелы, то лучше предварительно задать другой разделитель или использовать регулярные выражения в awk для корректного парсинга.
Сортировка и подсчёт: sort и uniq
Команда sort сортирует вход по указанному ключу столбца:
sort -k 1-k указывает номер столбца-ключа. По умолчанию сортировка алфавитная. Полезные флаги:
-n— числовая сортировка;-h— сортировка с суффиксами (1M > 1K);-M— сортировка по сокращениям месяцев;-V— сортировка версий (file-1.2.3 > file-1.2.1).
uniq удаляет повторяющиеся соседние строки. Поэтому обычно используют вместе:
sort -k 1 | uniqЧтобы вывести только повторяющиеся строки, используйте uniq -d.
Для подсчёта частоты применяют флаг -c:
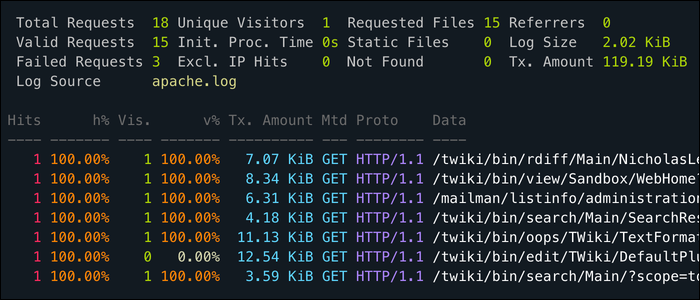
cut -d ' ' -f 1 | sort | uniq -c | sort -nr | headЭта цепочка команд извлечёт столбец с IP, сгруппирует идентичные строки, посчитает каждую, отсортирует по убыванию и покажет топ-строк. Пример вывода:
21 192.168.1.1
12 10.0.0.1
5 1.1.1.1
2 8.0.0.8Совет: регулярное использование длинных цепочек удобнее выносить в bash-скрипт или в alias в ~/.bashrc.
Фильтрация: grep и awk
grep выдаёт строки, содержащие заданный текст:
cat access.log | grep "404"Но grep не ограничивает поиск столбцом. Если «404» встречается в другом поле, то результат будет ложным. Чтобы точнее фильтровать по столбцу статуса (например, 9-й столбец в стандартном access.log), используйте awk:
cat access.log | awk '{if ($9 == "404") print $0;}'Негативная фильтрация (всё, что не 200):
cat access.log | awk '{if ($9 != "200") print $0;}'awk также позволяет применять регулярные выражения, подсчёт, группировку и сложную логику.
GUI и инструменты в реальном времени
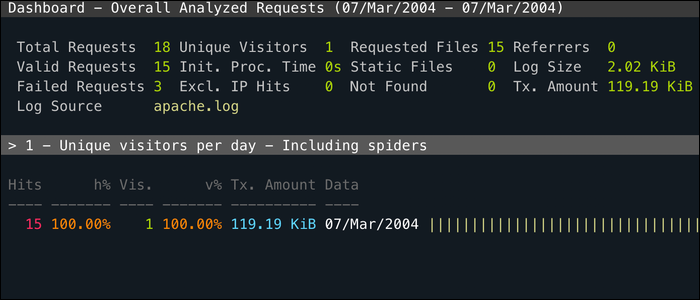
GoAccess — CLI‑утилита с возможностью web‑интерфейса. Хороша, когда нужно быстро получить интерактивную сводку по access.log и просматривать топы по любому полю.
apachetop — инструмент для Apache в реальном времени. Удобен для быстрого мониторинга и фильтрации по колонкам.
Альтернатива: для длительного хранения и визуализации используйте стеки типа ELK (Elasticsearch, Logstash, Kibana) или Grafana Loki, если нужны индексация, поиск и дашборды.
Когда описанный подход не работает (контрпримеры)
- Логи в бинарном формате или сжатые (gzip) требуют предварительной декомпрессии или специальных утилит (
zcat,zgrep). - Если поля разделены не пробелом, а комплексной структурой (JSON), лучше использовать парсер JSON (jq) вместо cut/awk.
- Для огромных файлов (десятки гигабайт) сортировка с использованием sort может оказаться медленной. В таких случаях используйте stream‑подходы, индексацию или специализированные системы логирования.
Альтернативные подходы
- jq для JSON‑логов:
jq -r '.field' log.json. - zgrep/zcat для сжатых логов:
zcat access.log.gz | awk '...'. - Python/Perl для сложной трансформации, когда awk становится громоздким.
- ELK/Grafana для хранения, поиска и визуализации с ретеншеном и правами доступа.
Ментальные модели и эвристики
- Разделитель — ключ: сначала определите, чем лог делит поля (пробел, таб, кавычки, JSON).
- Структура строк — фиксированная или нет: фиксированная — проще; если нет — парсер.
- Размер файла: до ~1–2 ГБ для локальной обработки; выше — задуматься о потоковой обработке или индексировании.
- Предварительная фильтрация — экономит ресурсы: сначала grep по узкому критерию, затем сложная обработка.
Мини‑методика: быстрый рабочий цикл для анализа инцидента
- Создайте копию или отфильтруйте временной интервал:
sed -n 'START,ENDp' access.log > window.log. - Выделите ключевой столбец (IP, статус, путь):
cut -d ' ' -f 1 > ips.txt. - Отсортируйте и посчитайте частоты:
sort ips.txt | uniq -c | sort -nr | head. - Для детализации используйте awk для контекста:
awk '$1=="192.168.1.1" {print $0}' window.log. - Документируйте вывод и при необходимости экспортируйте в CSV:
awk '{print $1","$9","$7}' window.log > report.csv.
Чек-листы по ролям
Системный администратор:
- Убедиться в правах на файлы.
- Проверить размер логов и доступное место на диске.
- Запустить потоковую обработку для больших файлов (
tail -f+ фильтрация).
Разработчик:
- Сфокусироваться на поле запроса и статусе.
- Собрать репликацию ошибки: пример строки, временной диапазон, ID сессии.
- Передать логи в баг‑трекер в формате CSV/JSON.
SRE/инженер по надежности:
- Собрать метрики (SLO/SLI) по ошибкам.
- Наладить алерты на всплески уникальных IP/ошибок.
- Настроить ретеншен и ротацию логов (logrotate).
Сниппеты и шпаргалка
Подсчёт топ‑10 IP:
cut -d ' ' -f 1 access.log | sort | uniq -c | sort -nr | head -n 10Топ URL по количеству 500‑статусов:
awk '$9 ~ /^5/ {print $7}' access.log | sort | uniq -c | sort -nr | headПоказать строки с кодом 404 и временем вокруг них (±3 строки):
grep -n " 404 " access.log | cut -d: -f1 | xargs -I{} sed -n "{},{+3}p" access.log(замена {+3} на вашу оболочку: проще использовать perl/awk для контекста).
Таблица сравнения утилит
| Задача | cut | awk | grep | sort/uniq | jq |
|---|---|---|---|---|---|
| Быстрое извлечение простых полей | + | + | — | — | — |
| Сложная логика/условия | — | ++ | — | — | ++ (для JSON) |
| Поиск по строке | — | + | ++ | — | — |
| Подсчёт частоты | — | + | — | ++ | + |
| Работа с JSON | — | — | — | — | ++ |
Примечание: + — подходит, ++ — предпочтительно, — — не подходит.
Безопасность и конфиденциальность
- Логи часто содержат персональные данные (IP, пути, параметры). Ограничьте доступ и применяйте маскирование чувствительных полей перед экспортом.
- При использовании облачных инструментов убедитесь в настроенных ролях и шифровании данных в покое и в транзите.
- Используйте ротацию и ретеншен для уменьшения объёма хранимых персональных данных.
Практические ограничения и оптимизация производительности
- Для очень больших файлов используйте
sort --parallelи--buffer-size, либо внешние инструменты (Hadoop, Spark) для распределённой обработки. - Для непрерывной агрегации используйте стейтовые системы (Elasticsearch, ClickHouse, Loki), чтобы не сортировать всю историю каждый раз.
- Для однократного инцидента предпочтительна локальная фильтрация по времени и узким критериям, затем уже более тяжёлая агрегация.
Глоссарий (в одну строку)
- cut — утилита для извлечения полей по разделителю.
- awk — текстовый процессор с переменными и выражениями.
- sort — сортировка строк по ключу.
- uniq — удаление/подсчёт подряд идущих дубликатов.
- grep — поиск строк по шаблону.
Критерии приёмки
- Можно извлечь нужный столбец и получить корректный список значений из тестовой выборки.
- Подсчёт частоты повторов совпадает с эталонным результатом для выбранного интервала.
- Скрипт обрабатывает случаи с пробелами в полях либо корректно проигнорирует такие строки.
Краткое резюме
- Используйте cut для быстрых и простых задач. Выбирайте awk, когда нужна логика. sort и uniq идеально подходят для подсчёта частот. Для JSON‑логов используйте jq. При работе с большими объёмами подумайте о потоковой обработке или системах хранения и индексации.
Итог: сочетая эти инструменты, вы получите быстрый и гибкий набор приёмов для быстрого расследования и регулярного мониторинга логов.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
