Регулярные выражения в Excel: REGEXTEST, REGEXEXTRACT, REGEXREPLACE

Быстрые ссылки
Как использовать REGEXTEST
REGEXEXTRACT: найти фрагменты текста
Обработка данных с помощью REGEXREPLACE
Регулярные выражения (REGEX) — это шаблоны для поиска и работы с текстом: проверка соответствия, извлечение частей строки и создание новых строк на основе шаблонов. Из-за своей выразительности и множества токенов они могут выглядеть сложными. В этой статье вы найдёте упрощённые объяснения, практические примеры для Excel и готовые шаблоны, которые можно вставить и адаптировать.
Важно: функции REGEX доступны в Excel для подписчиков Microsoft 365 (Windows, Mac и веб). Если у вас старая версия Excel, часть функционала может быть недоступна — в разделе «Альтернативы» описаны обходы.
Ключевые идеи
- REGEXTEST возвращает TRUE/FALSE для проверки шаблона.
- REGEXEXTRACT извлекает подстроки по шаблону; возвращает одиночный результат или массив.
- REGEXREPLACE формирует новую строку, заменяя соответствия на указанный шаблон замены.
Важно: при работе с табличным форматом Excel учтите особенности «спиллов» (spilled arrays). Если вы используете массивные результаты, применяйте формулы в обычных диапазонах, а не в форматированных таблицах.
Как использовать REGEXTEST
Эта функция проверяет, соответствует ли строка заданному шаблону. Возвращает TRUE, если соответствует, и FALSE — если нет. Идеально подходит для валидации форматов: SKU, номера заказа, кодов товара и т. п.
Синтаксис
REGEXTEST(a,b,c)где
- a (обязательно) — текст, значение или ссылка на ячейку, которую нужно проверить;
- b (обязательно) — шаблон регулярного выражения для проверки;
- c (необязательно) — 0 для чувствительности к регистру, 1 для нечувствительности.
Пример: проверка структуры кода товара
В таблице есть список кодов продуктов, которые должны соответствовать строгой структуре.
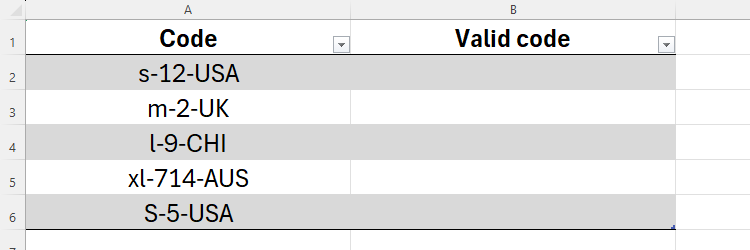
Правильный код содержит:
- обозначение размера в нижнем регистре: “xs”, “s”, “m”, “l”, “xl”;
- одно- или двузначный код материала;
- три заглавные буквы — код страны производства;
- дефис между частями.
В ячейке B2 вводим:
=REGEXTEST([@Code],"[xs|s|m|l|xl]-[0-9]{1,2}-[A-Z]{3}",0)Пояснения к шаблону:
- [@Code] — структурная ссылка на столбец с кодами;
- [xs|s|m|l|xl] — перечисление вариантов для размера (в примере автор использует вертикальную черту как «или»);
- [0-9]{1,2} — одна или две цифры для кода материала;
- [A-Z]{3} — ровно три заглавные буквы для кода страны;
- - — дефисы как разделители;
- 0 — указание на чувствительность к регистру.
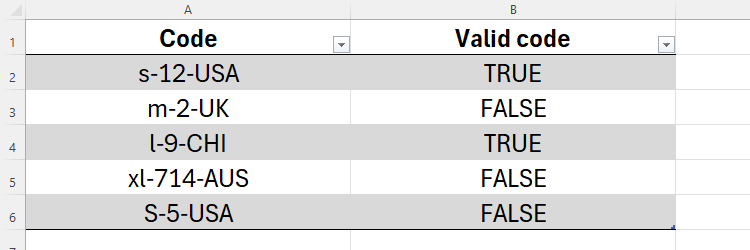
После применения формулы выясняется, что только два кода валидны (TRUE). Ошибки в невалидных кодах: две заглавные буквы вместо трёх, лишняя цифра и использование заглавной буквы для размера.
Частые ошибки при использовании REGEXTEST
- Неправильное использование символьных классов: запись [xs|s|m] не эквивалентна (xs|s|m). В сложных случаях лучше применять явные группы: (xs|s|m|l|xl).
- Ошибки с экранированием спецсимволов: если символ имеет особое значение (точка, плюс, скобки), его нужно экранировать
\.и т. п. - Неправильные ожидания по поводу чувствительности к регистру — проверьте аргумент c.
REGEXEXTRACT: извлечение фрагментов текста
Эта функция возвращает части текста в ячейке по шаблону. Полезна для разбиения имени и фамилии, извлечения телефона, кода и т. д.
Синтаксис
REGEXEXTRACT(d,e,f,g)где
- d (обязательно) — текст/ссылка, из которого извлекают;
- e (обязательно) — шаблон для извлечения;
- f (необязательно) — 0: первый матч; 1: все матчи как массив; 2: группы из первого матча;
- g (необязательно) — 0: чувствительность к регистру; 1: нечувствительно.
Примечание: в форматированных таблицах Excel массивные результаты (spilled arrays) обрабатываются аккуратно — при использовании f=1 лучше работать в обычных диапазонах.
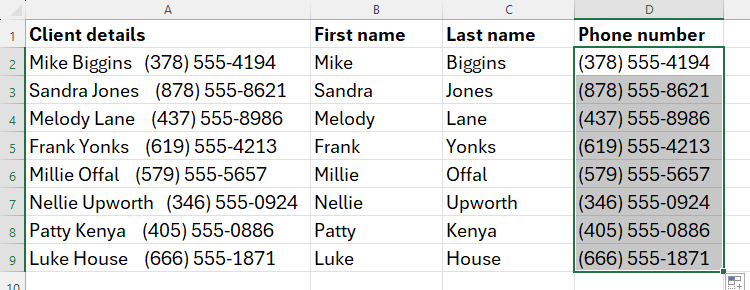
Пример: разделение имени и телефона
Есть список клиентов, где в ячейке A2 содержатся имя, фамилия и номер телефона. Нужно выделить имя, фамилию и номер в отдельные столбцы.
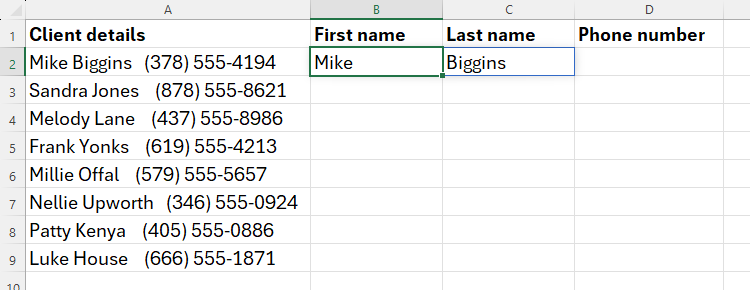
Для извлечения имён используем в B2:
=REGEXEXTRACT(A2,"[A-Z][a-z]+",1)Объяснение:
- [A-Z][a-z]+ — слово, начинающееся с заглавной буквы, за которой следуют строчные буквы;
+означает «один или более символов»; - аргумент
1говорит Excel вернуть все совпадения как массив (первое слово — имя, второе — фамилия).
После Enter Excel создаёт спилловый диапазон и извлекает имя и фамилию в B2 и C2.
Для телефона используем в D2:
=REGEXEXTRACT(A2,"[0-9()]+ [0-9-]+")Здесь шаблон разбит на две части:
- [0-9()]+ — код в скобках (например, (495));
- пробел;
- [0-9-]+ — оставшаяся часть номера с дефисами.
Excel извлечёт номер, и формулу можно протянуть вниз.
Альтернативы: для простых случаев Excel предоставляет TEXTSPLIT и Flash Fill; их проще применять, но они менее гибкие при сложных шаблонах.
Обработка данных с помощью REGEXREPLACE
REGEXREPLACE создаёт новую строку на основе шаблона замены. Несмотря на слово “replace” в названии, оригинальная ячейка не изменяется — функция возвращает результат в целевой ячейке.
Синтаксис
REGEXREPLACE(h,i,j,k,l)где
- h (обязательно) — исходный текст/ссылка;
- i (обязательно) — шаблон, который нужно заменить;
- j (обязательно) — текст замены (может содержать ссылки на группы вида $1, $2);
- k (необязательно) — номер вхождения для замены (по умолчанию заменяются все);
- l (необязательно) — 0 для чувствительности к регистру, 1 для нечувствительности.
Пример: перестановка имени и фамилии
Есть столбец с «Имя Фамилия», и нужно получить «Фамилия, Имя».
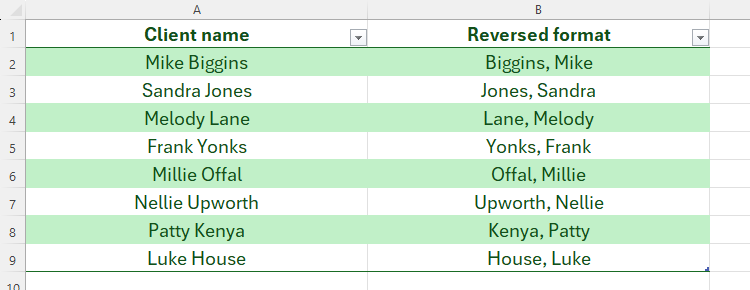
В B2 вводим:
=REGEXREPLACE([@Client name],"([A-Z][a-z]+) ([A-Z][a-z]+)","$2, $1")Пояснения:
- В шаблоне
([A-Z][a-z]+)используются группы, которые улавливают имя и фамилию; - В строке замены
$2, $1меняет порядок групп и добавляет запятую с пробелом; - Долларовые ссылки
$1,$2относятся к захваченным группам; без$Excel вернёт буквальные символы2, 1.
При применении формулы к таблице Excel автоматически заполнит все строки в столбце B.
Шпаргалка по основным токенам регулярных выражений
Ниже — практическая карта часто используемых символов. Она ориентирована на типичные задачи в Excel.
| Токен | Значение | Пример | Описание |
|---|---|---|---|
| . | любой символ (кроме новой строки) | a.b → “acb” | Подбирает любой одиночный символ |
| ^ | начало строки | ^ABC | Позиционный якорь: начало строки |
| $ | конец строки | 123$ | Позиционный якорь: конец строки |
| [] | символьный класс | [A-Za-z0-9] | Любой символ внутри скобок |
| [^] | отрицание в классе | [^0-9] | Любой символ, кроме перечисленных |
| {n,m} | квантификатор | [0-9]{2,4} | от n до m повторений |
| + | один или более | [a-z]+ | по крайней мере один символ |
| * | ноль или более | ab* | ноль или более b после a |
| ? | ноль или один | colou?r | опциональный символ |
| () | группа/захват | (ABC) | Позволяет ссылаться как $1, $2 |
| альтернативы | (cat | dog) | Соответствует cat или dog | ||
| \ | экранирование | . | ( | ) | Используется для специальных символов |
Примечание: синтаксис регулярных выражений может немного отличаться в разных реализациях. Этот список — для быстрых операций в Excel и общих задач.
Полезные шаблоны (копировать и адаптировать)
- Электронная почта (упрощённый вариант):
[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,} - Телефон (пример для формата +7 (999) 123-45-67):
\+?\d{1,3} ?\(?\d{1,4}\)?[ -]?\d{1,4}[ -]?\d{1,4} - Дата (формат YYYY-MM-DD):
\d{4}-\d{2}-\d{2} - SKU (пример: ab-12-XYZ):
([a-z]{1,2})-(\d{1,2})-([A-Z]{3}) - IP-адрес (IPv4, упрощённо):
\b(?:\d{1,3}\.){3}\d{1,3}\b
Используйте эти шаблоны как стартовую точку и дорабатывайте под свои данные.
Когда регулярные выражения не подходят
- Очень большие объёмы данных: сложные регулярные выражения влетают в производительность; рассмотрите парсинг на стороне сервера или Power Query.
- Сильно нечёткие данные: если структура данных плохо предсказуема, REGEX будет давать много ложных совпадений — лучше ручная проверка или алгоритмы очистки.
- Задачи, требующие восстановления контекста (семантика): REGEX работает в лексическом пространстве и не «понимает» смысл.
Альтернативные подходы в Excel
- TEXTSPLIT / TEXTBEFORE / TEXTAFTER — для простого разделения строк по разделителю;
- Flash Fill — быстр для типовых преобразований при единообразных шаблонах;
- Power Query — мощный инструмент для сложной очистки и трансформаций с визуальными шагами;
- Надстройки и скрипты Office Scripts / VBA — если нужно автоматизировать вне формул.
Методология внедрения регулярок в рабочие листы (мини-метод)
- Исследуйте данные: выберите репрезентативные примеры и исключения.
- Напишите упрощённый паттерн и протестируйте его на паре строк с REGEXTEST.
- Разработайте шаблон для REGEXEXTRACT или REGEXREPLACE и проверьте на нескольких строках.
- Протестируйте граничные случаи: пустые строки, неожиданные символы, неверный регистр.
- Добавьте документированную формулу/шаблон и комментарий в таблице.
- Автоматизируйте и мониторьте: при ошибках фиксируйте примеры и корректируйте.
Отладка и советы
- Используйте REGEXTEST как первый шаг: он быстрее показывает, попадает ли строка в диапазон шаблона.
- Разбивайте сложные шаблоны на части: сначала проверьте одну группу, затем всё вместе.
- Для сложных преобразований возьмите режим пошаговой отладки: временные столбцы с промежуточными результатами.
- Тестируйте с крайними примерами: очень длинными строками, строками с несколькими совпадениями и пустыми ячейками.
Критерии приёмки
- Все шаблоны покрывают >95% ожидаемых случаев по рабочей выборке (если доступны метрики) или соответствуют принятым правилам формата;
- Формулы документированы в отдельном столбце или комментарии;
- Для каждой формулы добавлен тестовый набор примеров с ожидаемым результатом;
- При изменении источника данных есть план регрессионного тестирования шаблонов.
Ролевые чек-листы перед внедрением
Аналитик данных:
- Проверить репрезентативность тестовой выборки;
- Составить набор примеров и антипримеров;
- Настроить автоматические проверки с REGEXTEST.
Бухгалтер / офисный пользователь:
- Убедиться, что шаблоны не затрагивают числовые поля и форматирование;
- Использовать REGEXREPLACE с черновой копией данных;
- Документировать изменения в колонке комментариев.
Разработчик / инженер данных:
- Оценить производительность при больших объёмах;
- Рассмотреть Power Query или серверный парсинг для масштабной обработки;
- Добавить логирование ошибок и тесты.
Шпаргалка: Ошибки и их исправления
- Неверный результат (нет совпадений): проверьте экранирование
\.и корректность границ^и$. - Ожидали массив, получили одно значение: проверьте аргумент f в REGEXEXTRACT и формат ячеек (таблица vs обычный диапазон).
- Замена не срабатывает: убедитесь, что группы в шаблоне захвачены скобками, и что в строке замены используются
$1,$2.
Примеры тест-кейсов
- Ввод:
"m-2-UK"— ожидаем результат REGEXTEST = FALSE (только две заглавные буквы в коде страны). - Ввод:
"xl-714-AUS"— ожидаем FALSE (три цифры в материале вместо 1–2). - Ввод:
"s-12-USA"— ожидаем TRUE.
Ментальные модели и эвристики
- “Разбей и проверь”: сначала проверяйте мелкие группы, затем объединяйте.
- “Чётко задавай границы”: используйте ^ и $ для строгих соответствий, если нужно полное совпадение.
- “Минимизируй жадность”: для извлечения коротких фрагментов используйте ленивые квантификаторы, если они поддерживаются, или уточняйте класс символов.
Таблица совместимости и миграции
- Microsoft 365 (Windows, Mac, Web) — поддержка функций REGEX в актуальных выпусках;
- Старые версии Excel — функции REGEX могут отсутствовать; используйте Power Query, VBA или внешнюю обработку;
- Google Sheets — имеет собственные функции REGEXMATCH, REGEXEXTRACT, REGEXREPLACE с похожим синтаксисом, но возможны различия в деталях реализации.
Пример рабочего процесса (Mermaid)
flowchart TD
A[Начало: описать задачу] --> B{Нужна ли проверка формата?}
B -- Да --> C[Использовать REGEXTEST]
B -- Нет --> D{Нужно извлечь данные?}
D -- Да --> E[Использовать REGEXEXTRACT]
D -- Нет --> F{Нужно преобразовать строки?}
F -- Да --> G[Использовать REGEXREPLACE]
F -- Нет --> H[Использовать TEXTSPLIT / Flash Fill / Power Query]
C --> I[Тест → развернуть на диапазон]
E --> I
G --> I
I --> J[Документировать и мониторить]Безопасность и конфиденциальность
При обработке персональных данных (телефоны, e‑mail, адреса) убедитесь, что вы соблюдаете внутренние политики безопасности и требования законодательства о защите данных. Регулярные выражения не «маскируют» данные автоматически — для обезличивания применяйте однозначные правила и храните исходные данные в защищённых местах.
Быстрый чек-лист перед публикацией листа с REGEX
- Сохранить резервную копию исходных данных;
- Добавить комментарии к основным формулам;
- Прогнать тестовый набор с граничными примерами;
- Проверить работу в разных средах (веб/десктоп);
- Обучить коллег краткому гайду использования и отката.
Резюме
Регулярные выражения в Excel — мощный инструмент для валидации, извлечения и преобразования строк. Начинайте с простых шаблонов, тестируйте через REGEXTEST, извлекайте массивы с REGEXEXTRACT и выполняйте преобразования через REGEXREPLACE. Включайте в рабочие листы документацию, тесты и план отката — это уменьшит риск ошибок и упростит сопровождение.
Регулярные выражения полезны не только в Excel: они пригодятся при очистке вставленного текста из PDF, пакетном переименовании файлов, форматировании валюты, удалении HTML‑тегов и многих других задачах по автоматизации.