Анализ тональности в Microsoft Excel без кода

Анализ тональности помогает выявлять скрытые тренды в текстовых данных. Его можно применять к историческим документам, отзывам клиентов, комментариям в социальных сетях и опросам. В этом руководстве показан простой подход с использованием Excel и надстройки Azure Machine Learning, который не требует навыков программирования.
Зачем нужен анализ тональности
Для продукт-менеджеров, маркетологов, исследователей и политтехнологов понимание эмоций, выраженных в тексте, часто решающе важно. Анализ тональности помогает быстро получить количественную картину из большого объема неструктурированных текстов.
Коротко о том, где это полезно:
- Мониторинг репутации бренда в социальных сетях.
- Анализ отзывов о продукте для приоритизации улучшений.
- Качественный обзор опросов и открытых комментариев.
- Исторический анализ письменных источников для выявления настроений автора.
Анализ тональности лучше работает на больших наборах данных. Один или несколько сообщений в личной переписке редко дают полезную статистику. Зато тысячи твитов с определенным хештегом могут показать выраженный тренд.
Объем данных и тональность
Высокий объем упоминаний важен, но не достаточен. Много упоминаний может быть положительным или отрицательным. Разделение объема и тональности помогает отличить рост интереса от PR-кризиса. Сочетание метрик объема и настроения дает более точную картину.
Как выполнить анализ тональности в Microsoft Excel
Ниже — пошаговая инструкция для пользователей Excel без навыков программирования. Подход использует надстройку Azure Machine Learning и внутренние словари и алгоритмы для оценки тональности каждой строки текста.
Важное: перед запуском убедитесь, что у вас есть подписка на Microsoft 365 и доступ к надстройкам. Если вы работаете с конфиденциальными персональными данными, сначала прочитайте раздел о конфиденциальности ниже.
- Организуйте данные в листе Excel. Каждая строка — отдельный текстовый документ, комментарий или отзыв.
- Очистите данные: удалите пустые строки, лишние пробелы, HTML-теги и корректируйте кодировку. Удалите автоматические переносы строк внутри комментариев, если они ломают структуру строки.
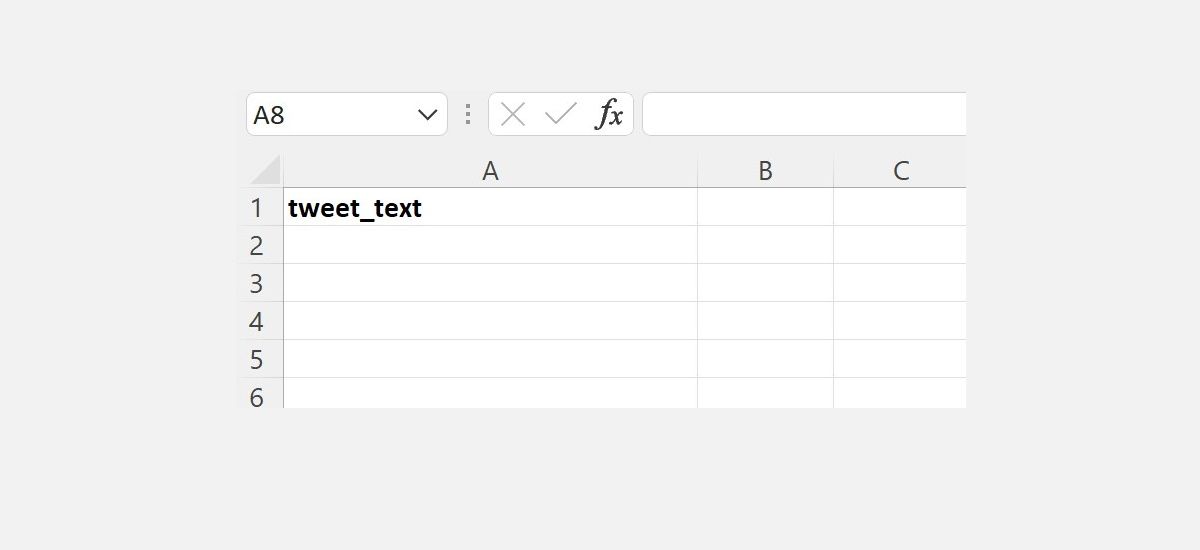
- Сделайте первую ячейку столбца, содержащего текст, с именем tweet_text в нижнем регистре. Это имя распознает надстройка как входной столбец
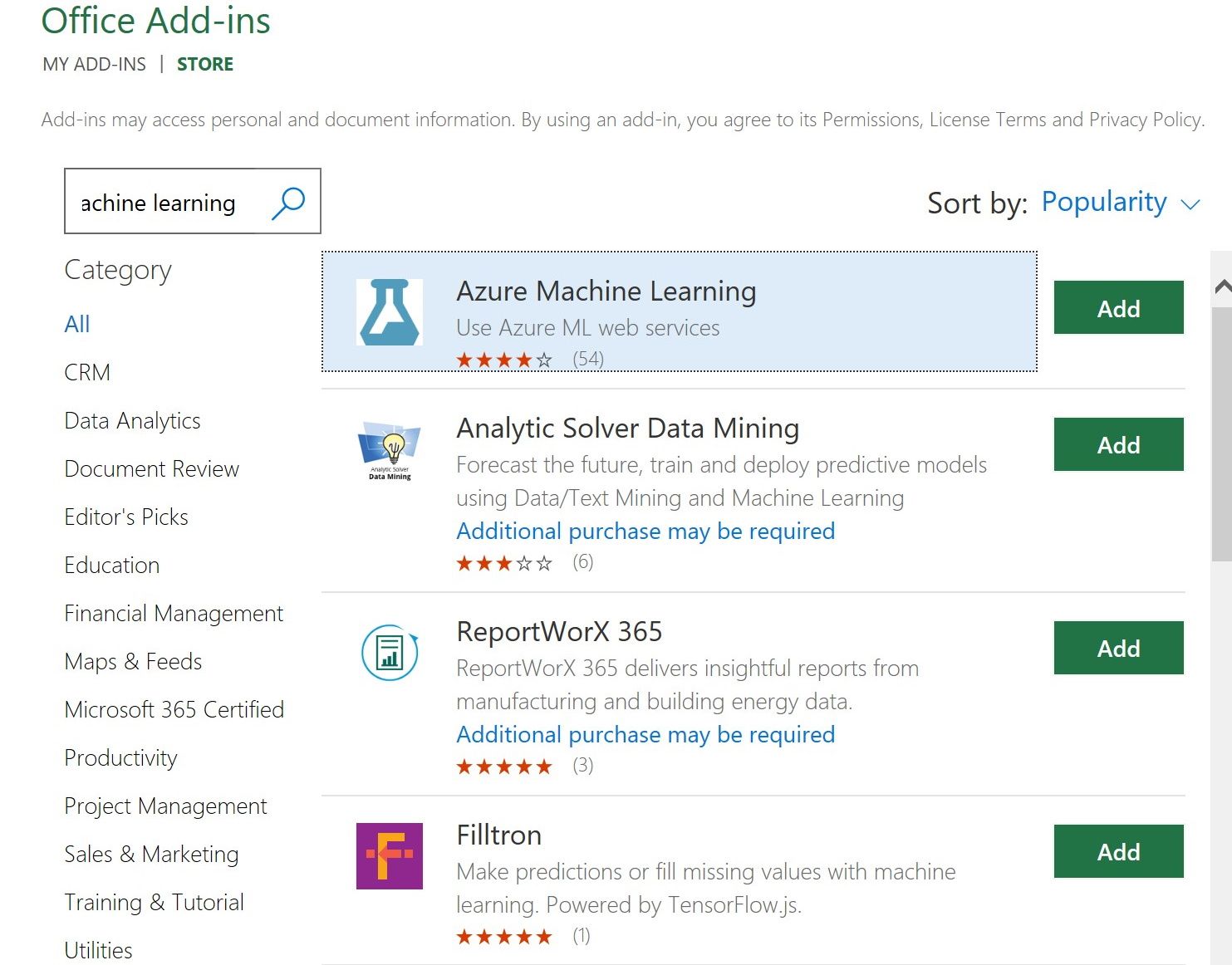
- Откройте меню Вставка > Надстройки.
- В поле поиска найдите Azure Machine Learning и установите надстройку
- После установки справа появится панель Azure Machine Learning.
- В списке моделей выберите Text Sentiment Analysis
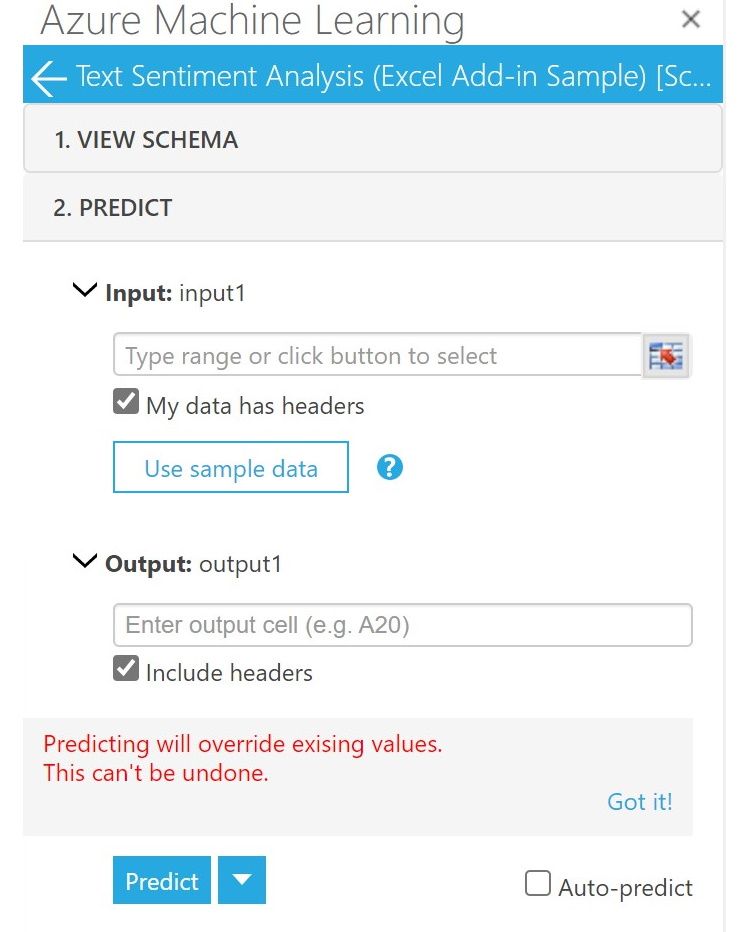
- Нажмите Predict, затем Input и укажите диапазон ячеек с текстом.
- Убедитесь, что опция My data has headers включена.
- В разделе Output укажите ячейку, в которую нужно выгружать результаты.
- Нажмите Predict.
После выполнения столбцы с результатами появятся в указанной области: класс тональности и оценка. Чем ближе оценка к минимальному значению, тем более негативен текст. Если вы переключите отображение оценки на процентный формат, значение около 50% обычно соответствует нейтральной тональности, ближе к 100% — положительная, ближе к 0% — отрицательная.
Пример ниже показывает результаты для отрывка из романа «Остров сокровищ» Роберта Льюиса Стивенсона.

Советы по предобработке и улучшению качества
Качество входных данных сильно влияет на точность. Вот практические рекомендации:
- Нормализуйте регистр текста и вырезайте HTML и ссылки.
- Удаляйте стоп-слова только если вы уверены, что это не исказит смысл.
- Обрабатывайте эмодзи и знаки препинания: для многих моделей эмодзи дают сильный эмоциональный сигнал.
- Обрабатывайте отрицания (например, «не хорошо») — простая замена может улучшить результат.
- Разделяйте тексты на смысловые единицы, если в одной ячейке смешаны разные темы.
- Если тексты на нескольких языках, сначала фильтруйте по языку или используйте модель, поддерживающую нужный язык.
Интерпретация результатов: Тональность и Оценка
Надстройка возвращает два основных поля: классификация тональности и числовая оценка. Принципы интерпретации:
- Классификация показывает категорию: Положительная, Отрицательная или Нейтральная.
- Оценка показывает силу выраженной эмоции. В процентном виде 100% — максимально положительная, 0% — максимально отрицательная.
- Оценки вокруг 50% обычно нейтральны, но порог можно настраивать под ваш кейс.
Практическая подсказка: при многотемном формате отзывов создайте колонку с темами (например, доставка, функциональность, цена) и анализируйте тональность по каждой теме отдельно.
Как извлекать инсайты из результатов
После получения классификаций и оценок вы можете:
- Построить сводную таблицу для подсчета количества положительных, отрицательных и нейтральных упоминаний.
- Визуализировать распределение оценок с помощью диаграмм и тепловых карт.
- Отфильтровать все отрицательные упоминания и проанализировать, какие слова или фразы чаще встречаются в них.
- Сегментировать по темам, географии или временному интервалу и сравнивать динамику тональности.
- Выделить лучшие позитивные отзывы для маркетинговых материалов и распространения внутри команды.
Если у вас есть доступ к Visio в составе Microsoft 365 Business, его можно использовать для создания диаграмм и иллюстрации распределения тональности по сегментам.
Когда Excel-подход не подходит
Анализ в Excel полезен для простых сценариев, но имеет ограничения. Рассмотрите альтернативы в следующих случаях:
- Очень большие объёмы данных в реальном времени, требующие быстрой обработки и масштабирования.
- Необходимость в тонкостях: распознавание сарказма, сложных контекстных связей, множественной кластеризации эмоций.
- Специфические доменные словари: медицинская, юридическая и техническая лексика часто требует кастомных моделей.
- Строгие требования к точности и аудиту моделей в регламентированных отраслях.
Альтернативные подходы
Если Excel не удовлетворяет требованиям, рассмотрите:
- Использование библиотек на Python: NLTK, spaCy, Hugging Face Transformers для кастомных моделей.
- API крупных облачных провайдеров: Azure Text Analytics, Google Cloud Natural Language, AWS Comprehend.
- Платформы мониторинга соцсетей с встроенной аналитикой тональности для потоковой обработки и визуализации.
Каждый вариант требует разного уровня компетенций и бюджета. Облачные API дают готовые решения с оплатой по использованию, Python дает свободу кастомизации, а специализированные платформы экономят время внедрения.
Упрощенная методология и чеклист реализации
Мини-методология в 6 шагов:
- Цель: определите, зачем вы проводите анализ и какие решения на его основе будете принимать.
- Сбор: соберите релевантные источники данных и оцените объемы.
- Предобработка: очистите тексты и нормализуйте формат.
- Анализ: запустите модель и получите классификации и оценки.
- Интерапретация: визуализируйте и сегментируйте результаты.
- Действие: сформируйте список задач на основе выявленных проблем и позитивных сигналов.
Чеклист перед первым прогоном в Excel:
- Колонка с именем tweet_text присутствует
- Тексты на одном языке или помечены языком
- Пустые строки удалены
- Эмодзи и смайлы обработаны по политике проекта
- Место вывода результатов выделено и сохранено
Роли и их основные задачи
- Маркетолог: проверяет распределение позитивных упоминаний и выбирает промо-контент.
- Менеджер поддержки: фильтрует отрицательные отзывы для эскалации.
- Продукт-менеджер: сегментирует оценки по функциям и приоритизирует улучшения.
- Исследователь: проверяет валидность модели и собирает дополнительные метрики.
Процедура выполнения: пошаговый playbook
- Подготовьте копию исходного листа и работайте в ней.
- Очистите данные по чеклисту.
- Запустите надстройку Azure Machine Learning как описано выше.
- Сохраните сырые результаты в отдельный лист с метками времени выполнения.
- Создайте сводную таблицу и базовые графики распределения.
- Отфильтруйте крайние отрицательные и позитивные кейсы и проведите ручную проверку выборки для оценки качества модели.
- Запишете выводы и назначьте конкретные задачи по результатам анализа.
Важно фиксировать версии данных и дату анализа для воспроизводимости.
Критерии приёмки
Примеры критериев приемки для проекта анализа тональности:
- Данные: столбец tweet_text заполнен не менее чем на 95% строк.
- Покрытие: модель обработала 100% выбранного диапазона.
- Качество выборки: при ручной проверке 200 случайных записей точность классификации не ниже приемлемого порога, согласованного с проектной группой.
- Отчётность: есть сводная таблица с количеством позитивных, негативных и нейтральных записей; есть графики трендов по времени.
Тестовые сценарии и приемочные кейсы
- Тест 1: строки с явно позитивной лексикой должны помечаться как положительные.
- Тест 2: строки со словами отрицательной окраски должны помечаться как отрицательные.
- Тест 3: строки с нейтральным описанием должны попадать в нейтральную категорию или около 50% в оценке.
- Тест 4: строки с отрицательными словами и явным отрицанием должны корректно интерпретироваться (например, не плохо vs плохо).
Результаты тестов фиксируйте в отдельной таблице и используйте их для корректировок предобработки.
Риски и защита персональных данных
Анализ текстов часто затрагивает персональные данные пользователей. Внимание к соответствию требованиям конфиденциальности критично.
Рекомендации по минимизации рисков:
- Анонимизируйте персональные данные перед загрузкой в надстройку.
- Избегайте передачи идентифицируемой информации в сторонние облачные сервисы без согласия.
- Для Европейского Союза соблюдайте принципы GDPR: законность обработки, минимизация данных, прозрачность и права субъектов данных.
- Документируйте, какие данные отправляются в облако и кто имеет к ним доступ.
Важно: если вы используете надстройку, уточните, где и как хранятся данные и соответствует ли это политике вашей организации.
Мини-словарь
- Тональность: эмоциональная окраска текста, например положительная, отрицательная или нейтральная.
- Предобработка: шаги по очистке и нормализации текста перед анализом.
- Классификация: присвоение тексту категории тональности.
- Оценка: числовая мера силы эмоции в тексте.
Факто-бокс: практические ориентиры
- Масштаб: анализ тональности полезен при сотнях и особенно при тысячах строк текста.
- Валидация: ручная проверка случайной выборки от 100 до 500 записей даёт представление о качестве модели.
- Ограничения: встроенные модели дают приближенные результаты; для высокой точности потребуется кастомизация.
Короткое объявление для соцсетей (100–200 слов)
Ищете быстрый способ понять, что люди говорят о вашем продукте или бренде без кода и дорогих платформ Наша инструкция по анализу тональности в Microsoft Excel показывает, как с помощью надстройки Azure Machine Learning получить классификации и оценки настроений прямо в таблице. Вы узнаете, как подготовить данные, запустить модель в Excel и превратить результаты в действующие инсайты. В гайде есть чеклисты, критерии приёмки, сценарии тестирования и рекомендации по конфиденциальности. Подойдёт маркетологам, продукт-менеджерам и всем, кто хочет начать работать с текстовыми данными без команды разработчиков.
Когда это не заменит эксперта
Помните, автоматический анализ тональности облегчает задачу, но не отменяет экспертной проверки. Машина обеспечивает согласованность, но не всегда улавливает сарказм, полисемию и культурные нюансы. Используйте модель как фильтр и масштабируемый инструмент, а окончательные решения принимайте с учётом качественного анализа.
Важно: не полагайтесь на модель как на единственный источник истины. Всегда комбинируйте машинную аналитику с человеческой проверкой для критичных решений.
Краткое резюме
Анализ тональности в Excel — быстрый и доступный способ получить представление о настроениях в текстах. Он хорош для проверки гипотез, первичной фильтрации больших объемов и обучения команд основам машинного анализа текста. При росте требований к точности и масштабированию переходите к специализированным инструментам или кастомным моделям.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
