Как мониторить использование CPU со временем и строить графики
Краткое введение
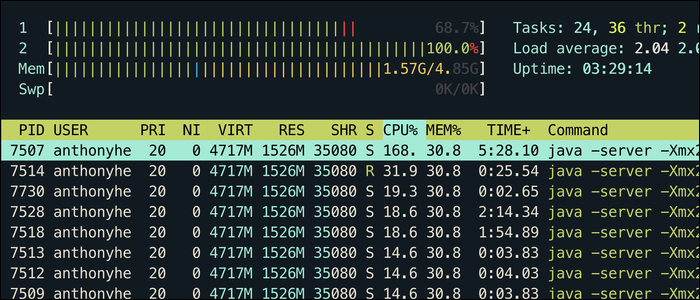
Утилиты top и htop показывают мгновенную загрузку CPU по процессам. Но для анализа трендов и своевременных оповещений нужна история: записи по времени и удобная визуализация. В статье перечислены простые и более зрелые способы получить такие данные — от «самодельных» CSV до production‑решений.
Important: если вы используете облако (AWS/GCP/Azure), начните с их встроенных инструментов — это самый быстрый путь к графикам и алертам.
Основные варианты (быстрое сравнение)
- Облачные метрики (CloudWatch, GCP Monitoring, Azure Monitor): быстро, удобно, обычно платно за частоту/ретеншн.
- /proc/loadavg → CSV: минимальные зависимости, просто, подходит для одноразовой диагностики.
- sysstat (sar): системный сборщик, хранит исторические данные, удобен для анализа и экспорта.
- Monit: лёгкий мониторинг и триггеры оповещений по правилам.
- Внешние системы метрик (Prometheus, InfluxDB + Grafana): масштабируемые, гибкие, требуют настройки.
Облачные графики — тривиальное решение
Если ваш провайдер предоставляет мониторинг, используйте его:
- AWS CloudWatch: в разделе Metrics выберите EC2 → CPUUtilization. График по умолчанию аггрегирован по 5 минутам; можно включить детальный мониторинг (1 минута) за дополнительную плату. У CloudWatch можно быстро настроить alarms для порогов.
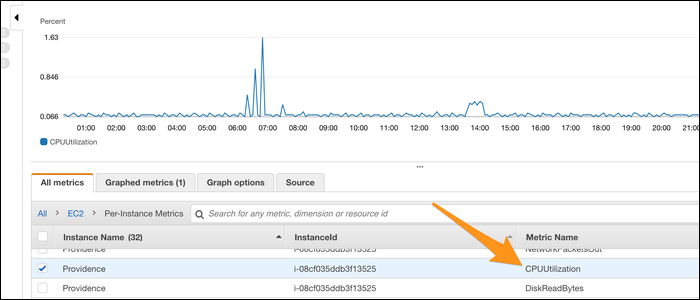
- GCP: вкладка Monitoring у экземпляра показывает графики по CPU.
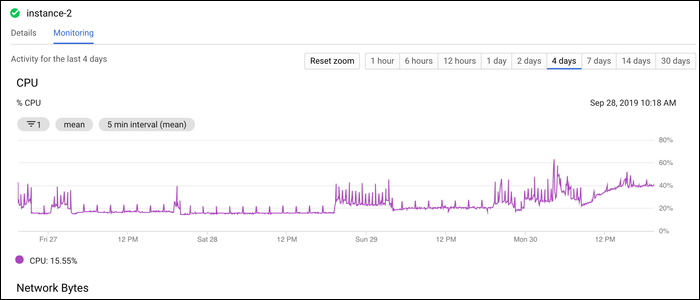
- Azure Monitor: аналогичные графики и алерты.
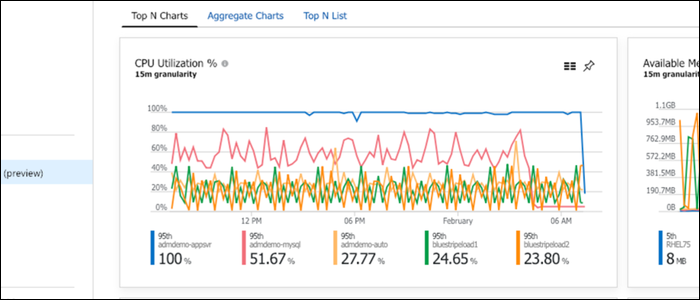
Когда облачные графики подходят:
- Вы хотите быстро видеть тренд и настраивать оповещения.
- Не хотите запускать и поддерживать дополнительные сервисы.
Когда облачные графики не подходят:
- Вы в локальной сети без облачного мониторинга.
- Нужен очень длинный ретеншн или специфическая агрегация.
Чтение /proc/loadavg — самый простой самодельный график
Где top берёт часть своих данных? Из /proc/loadavg. Файл содержит 1‑, 5‑ и 15‑минутные средние нагрузки.
Команда для просмотра:
cat /proc/loadavgПример вывода:
1.71 1.32 1.38 2/97 6429Чтобы регулярно сохранять первые три поля в CSV:
cat /proc/loadavg | awk '{print $1","$2","$3}' >> cpu.csvСоветы по использованию:
- Запланируйте cron на нужную частоту (например, каждую минуту).
- Периодически ротируйте файлы (logrotate) или переносите в архив.
- CSV можно импортировать в Excel или LibreOffice Calc и построить линейный график.
Ограничения этого подхода:
- /proc/loadavg даёт нагрузку на систему (load average), а не процент использования всех ядер. Для многопроцессорных систем 1.0 не всегда равен 100%.
- Нельзя легко группировать по процессам или сохранять дополнительные метрики (IO, память) без расширения логики.
Установка sysstat (sar) — зрелый системный сборщик
Утилита sar входит в пакет sysstat и собирает метрики в фоне. Она сохраняет данные по расписанию и позволяет генерировать отчёты.
Установка на Debian/Ubuntu:
sudo apt-get install sysstatДалее включите сбор, отредактировав /etc/default/sysstat и установив ENABLED в true. По умолчанию sysstat собирает данные каждые 10 минут и хранит их по умолчанию неделю. Эти настройки можно поменять в /etc/cron.d/sysstat и /etc/sysstat/sysstat.
Пример живого отчёта за CPU:
sar -u 1 3Данные сохраняются в /var/log/sysstat/. Вы можете экспортировать их в CSV или использовать готовые визуализаторы, например sargraph.
Преимущества sysstat:
- Нативный сбор с низкой нагрузкой.
- Стандартные отчёты и утилиты для анализа.
- Хорош для ретроспективного анализа инцидентов.
Ограничения:
- Меньше гибкости для кастомных метрик, чем у Prometheus.
- Требует доступа к файловой системе сервера для чтения логов.
Monit — оповещения и простые проверки

Monit — лёгкая система для проверки состояния сервера. Она умеет:
- Проверять загрузку CPU, использование памяти, статус процессов и сервисов.
- Отправлять оповещения (email, webhook, syslog).
- Перезапускать сервисы при падении или при достижении порога.
Пример простой проверки в конфигурации Monit (фрагмент):
check system myhost
if loadavg (1min) > 8 then alert
if memory usage > 95% then alertMonit полезен, если вы хотите получать быстрые оповещения и иметь возможность автоматически действовать при проблеме.
Альтернативы для полноценного мониторинга
Если вы хотите масштабируемую систему мониторинга с графиками, алертингом и длительным хранением:
- Prometheus + node_exporter + Grafana — популярный стек для метрик. Prometheus захватывает подробные метрики и хранит их временные ряды, Grafana визуализирует.
- InfluxDB + Telegraf + Grafana — схожая архитектура, ориентированная на временные ряды.
- SaaS решения (Datadog, New Relic) — платные, но быстрые для внедрения.
Выбор зависит от требований к ретеншну, частоте сбора, затратам и сложности поддержки.
Мини‑методология для внедрения мониторинга CPU (шаги)
- Определите цель: обнаружение пиков, долгосрочный тренд, SLA‑оповещения.
- Выберите инструмент: облачный график, sysstat для истории, Prometheus для гибкости.
- Настройте частоту сбора: 1 минута для быстрых реакций, 5–10 минут для трендов.
- Задайте пороги алертинга (обычно в процентах использования CPU или в load average). Тестируйте пороги на пиковых нагрузках.
- Настройте ретеншн и ротацию логов/бд.
- Проверяйте систему на отказоустойчивость (например, храните метрики удалённо).
Рекомендации по порогам и алертам (эмпирично)
- Для процента использования CPU: общий рекомендуемый порог для предупреждений — 70–85% при длительной нагрузке. Для критических алертов — 90–95%.
- Для load average: сопоставляйте load average с количеством ядер. Load average ~ N означает полную загрузку N‑ядерной системы.
Важно: подстройте пороги под нагрузку приложения и характер нагрузки (короткие пики против длительной загрузки).
Критерии приёмки
- Метрика CPU собирается с заданной частотой (например, 1 мин).
- Исторические данные сохраняются в течение требуемого периода (ретеншн).
- При достижении порога генерируется оповещение и (опционально) выполняется корректирующее действие.
- Есть простая визуализация трендов для быстрого анализа.
Плейбук реагирования при высокой загрузке CPU
- Получен alert о длительной высокой загрузке CPU.
- Оцените время и длительность пика (используйте графики и sar данные).
- На сервере выполните:
top
# или
htop
# посмотреть процессы, сортировать по %CPU- Определите процесс‑виновник. Если это ожидаемое поведение — масштабируйте (добавьте инстансы/ресурсы). Если нет — перезапустите процесс/службу.
- Соберите диагностические логи и снимки состояния (strace, pmap) при необходимости.
- После инцидента проанализируйте причину и обновите пороги или автоскейлинг.
Чеклист развертывания (роль‑ориентированный)
Для инженера по эксплуатации:
- Выбрать подходящий инструмент мониторинга.
- Настроить сбор метрик (node_exporter/sysstat или облачный агент).
- Настроить алерты и каналы оповещений.
- Проверить ретеншн и бэкап метрик.
Для SRE/DevOps:
- Интегрировать метрики в дашборд (Grafana).
- Автоматизировать масштабирование и автоперезапуск.
- Провести нагрузочное тестирование и скорректировать пороги.
Когда предложенные подходы не работают (edge cases)
- Очень краткие, но частые пиковые нагрузки: 1‑минутной агрегации может не хватать. Нужен субминутный сбор или трассировка на уровне приложения.
- Контейнерные среды с быстрым запуском/уходом: агрегаторы должны учитывать краткоживущие метрики.
- Ограниченные права доступа: некоторые методы (sysstat, node_exporter) требуют прав для чтения системных метрик.
Краткая шпаргалка команд
- Просмотр мгновенной загрузки:
top
htop- Просмотр loadavg:
cat /proc/loadavg- Собрать sar в режиме реального времени:
sar -u 1 3- Пример cron для записи /proc/loadavg каждую минуту:
* * * * * root cat /proc/loadavg | awk '{print strftime("%Y-%m-%d %H:%M:%S"),","$1","$2","$3}' >> /var/log/cpu-load.csv(стрftime в стандартном awk может не работать; используйте gawk или добавьте timestamp другими средствами)
Заключение
Мониторинг CPU может выглядеть просто или очень масштабно — выбор зависит от целей. Для быстрого результата используйте облачные графики. Для локальных серверов начните с /proc/loadavg для простых диаграмм или установите sysstat для длительного хранения и отчётности. Для продакшна с высокой сложностью лучше использовать стек метрик (Prometheus/Grafana) и автоматические алерты.
Summary:
- Облачный мониторинг — самое простое решение.
- /proc/loadavg + cron → быстрый самодельный график.
- sysstat/sar — надёжный системный сборщик.
- Monit — лёгкие проверки и оповещения.
Notes: Подбирайте частоту сбора и пороги под характер нагрузки приложения.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
