Как заполнять пропущенные значения в pandas

- Пропуски (NaN) в данных влияют на анализ и модели. В pandas есть несколько приёмов: fillna (значение/ffill/bfill), replace, interpolate и удаление строк. Выбирайте метод, исходя из типа столбца и задачи: числовые — mean/median/interpolate, категориальные — mode или замена по контексту. Всегда проверяйте результаты визуально и через тесты.
Зачем это важно
Пропущенные значения в данных искажают статистику, обучение моделей и визуализации. Корректная стратегия обработки пропусков уменьшает смещение оценок и повышает качество предсказаний. Ниже — понятные шаги, примеры кода и практические чеклисты для разных ролей.
Подготовка среды и пример набора данных
Установите pandas в ваше виртуальное окружение через pip:
pip install pandasВ статье используются небольшие тестовые данные с пропусками (NaN). Код создания DataFrame:
import pandas
import numpy
df = pandas.DataFrame({
'A' :[0, 3, numpy.nan, 10, 3, numpy.nan],
'B' : [numpy.nan, numpy.nan, 7.13, 13.82, 7, 7],
'C' : [numpy.nan, "Pandas", numpy.nan, "Pandas", "Python", "JavaScript"],
'D' : ["Sound", numpy.nan, numpy.nan, "Music", "Songs", numpy.nan]
})
print(df)Набор данных выглядит примерно так:
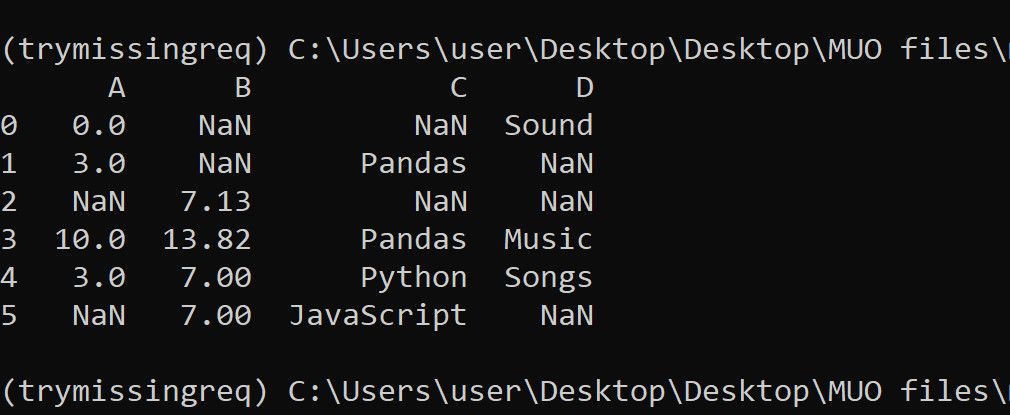
Важно: сохраняйте исходный DataFrame или делайте копии перед массовыми заменами — это поможет откатить изменения.
1. fillna() — базовый инструмент для заполнения
fillna() заменяет NaN на указанное значение или использует стратегию заполнения по соседним значениям.
Ключевые аргументы:
- value — конкретное значение или словарь значений по столбцам.
- method — ‘ffill’ (forward fill) или ‘bfill’ (backward fill).
- inplace — если True, изменения применяются в исходном DataFrame.
Заполнение средним, медианой и модой
Для числовых колонок удобно использовать mean/median. Пример для вставки среднего по каждому числовому столбцу:
# Вставить среднее по числовым столбцам (округление для наглядности)
df.fillna(df.mean(numeric_only=True).round(1), inplace=True)
# Или медиану:
df.fillna(df.median(numeric_only=True).round(1), inplace=True)
print(df)Пояснение: аргумент numeric_only=True ограничивает операцию числовыми колонками; для строковых колонок усреднение неприменимо.
Для категориальных (строковых) столбцов используйте моду (наиболее частое значение):
string_columns = df.select_dtypes(include=['object']).columns
df[string_columns] = df[string_columns].fillna(df[string_columns].mode().iloc[0])
print(df)Или по-столбцово:
df['C'].fillna(df['C'].mode()[0], inplace=True)Можно комбинировать разные стратегии для разных столбцов через словарь:
df.fillna({
"A": df['A'].mean(),
"B": df['B'].median(),
"C": df['C'].mode()[0]
}, inplace=True)
print(df)Заполнение по направлению: ffill и bfill
- ffill (forward): заменяет NaN значением предыдущей (выше по индексу) ненулевой ячейки.
df.fillna(method='ffill', inplace=True)- bfill (backward): заменяет NaN значением следующей ненулевой ячейки.
df.fillna(method='bfill', inplace=True)Комбинация bfill и ffill помогает заполнить пропуски в обе стороны, если порядок строк имеет смысл (временные ряды, последовательности событий).
Important: ffill и bfill работают по индексу/основной оси; для временных рядов сначала отсортируйте по времени.
2. replace() — гибкая замена любых значений
replace() полезен, когда нужно заменить не только NaN, но и специфические метки (‘unknown’, -999 и т. п.). Пример замены NaN в отдельных столбцах:
import pandas
import numpy
# Заменить NaN в столбце A на среднее
df['A'].replace([numpy.nan], df['A'].mean(), inplace=True)
# В столбце B на медиану
df['B'].replace([numpy.nan], df['B'].median(), inplace=True)
# В столбце C на моду
df['C'].replace([numpy.nan], df['C'].mode()[0], inplace=True)
print(df)replace() принимает списки значений, словари и регулярные выражения — удобно для массовых чисток.
3. interpolate() — аппроксимация по соседям
interpolate() использует численные методы (линейная интерполяция и др.) для оценки пропущенных чисел. Работает только для числовых колонок.
# Линейная интерполяция, направление backward
df.interpolate(method='linear', limit_direction='backward', inplace=True)
# Линейная интерполяция, направление forward
df.interpolate(method='linear', limit_direction='forward', inplace=True)interpolate() полезна для временных рядов, где значения плавно меняются во времени. Метод можно менять: ‘linear’, ‘time’, ‘polynomial’ и т.д., но выбирайте метод осознанно.
Когда удалять строки с пропусками
Иногда проще удалить строки или столбцы с большим количеством пропусков:
# Удалить строки с любым NaN
df.dropna(axis=0, how='any', inplace=True)
# Удалить столбцы, где более 50% значений пустые
threshold = len(df) * 0.5
df.dropna(axis=1, thresh=threshold, inplace=True)Удаление оправдано, если пропуски случайны и не несут информации, но удаление большого количества строк может привести к потере репрезентативности.
Руководство по выбору метода — минимальная стратегия
- Числовые данные с малым количеством NaN:
- Если данные стационарны и распределение не перекошено — mean.
- Если есть выбросы — median.
- Для временных рядов — interpolate или ffill/bfill в зависимости от контекста.
- Категориальные данные:
- mode если значение чаще всего встречается и логично.
- Создать пометку “Unknown”/“Missing” если отсутствие данных может быть информативным.
- Когда NaN образуют закономерности (не случайно): исследуйте причину — возможно, нужно модельное предсказание пропусков или сигнал о проблеме в источнике данных.
Чек-лист перед массовыми заменами
- Сохранить копию исходных данных: df_original = df.copy()
- Проверить долю NaN по столбцам: df.isna().mean()
- Визуализировать пропуски (heatmap/missingno) — поиск паттернов
- Выбрать стратегию по типу столбца и задаче
- Применить замену локально (на копии) и прогнать тесты/метрики
- Сравнить описательную статистику до и после
Практическое SOP (шаблон действий для проекта)
- Анализ пропусков
- df.isna().sum()
- df.isna().mean()
- Построить графики распределения и missingness map
- Принятие решения
- Для каждого столбца задать стратегию: drop / fill(mean/median/mode) / interpolate / model-based
- Реализация
- Применить замену на тестовой копии
- Проверить изменения метрик и визуально
- Документирование
- Записать причину замены и использованный метод
- Ревью и утверждение
- Коллега или владелец данных подтверждает корректность
Тестовые случаи и критерии приёмки
Критерии приёмки:
- После обработки колонка не содержит NaN (если это требование) или доля NaN не превышает согласованный порог.
- Базовые статистики (mean/median/count) изменились в пределах ожидаемого диапазона.
- Модель/аналитика дают стабильные результаты на тестовой выборке.
Примеры тестов (unit tests):
- Тест: после df[‘A’].fillna(df[‘A’].mean(), inplace=True) — assert df[‘A’].isna().sum() == 0
- Тест: при использовании interpolate() значения сохраняют монотонность (если применимо)
Ментальные модели и когда методы не работают
- Модель “локальная замена”: fillna(mean/median/mode) — простая и быстрая, но скрывает структурные пропуски.
- Модель “соседей”: ffill/bfill/interpolate — хороша для временных рядов, плохо работает при редких событиях.
- Модель “маркер пропуска”: оставить отдельный класс “Missing” — полезно если отсутствие данных само по себе информативно.
Counterexample: заполнение mean в сильно скошенном распределении приводит к искажению и снижению дисперсии — предпочтительна медиана или model-based imputations.
Альтернативные подходы
- Model-based imputation: обучить модель (например, регрессию или KNN) для предсказания пропущенных значений по другим признакам.
- Multiple imputation: несколько заполнений с учётом неопределённости, затем агрегирование результатов.
- Специализированные библиотеки: fancyimpute, sklearn.impute (IterativeImputer), statsmodels для временных рядов.
Пример использования KNN imputer (scikit-learn)
from sklearn.impute import KNNImputer
import pandas as pd
numeric_df = df.select_dtypes(include=['number']).copy()
imputer = KNNImputer(n_neighbors=3)
filled = imputer.fit_transform(numeric_df)
numeric_df[:] = filledЭтот подход учитывает схожесть между наблюдениями, но требует нормализации признаков.
Decision tree для выбора стратегии
flowchart TD
A[Начало: есть пропуски?] -->|Нет| B[Оставить как есть]
A -->|Да| C[Тип столбца]
C -->|Числовой| D{Временной ряд?}
D -->|Да| E[interpolate / ffill/bfill]
D -->|Нет| F{Распределение}
F -->|Симметричное| G[mean]
F -->|Скошенное| H[median]
C -->|Категориальный| I{Значим ли NaN}
I -->|Да| J[Создать метку 'Missing']
I -->|Нет| K[mode или replace]
E --> L[Проверка качества]
G --> L
H --> L
J --> L
K --> LРиски и рекомендации
- Риск: утрата информации при удалении строк — всегда оцените процент удаляемых данных.
- Риск: введение смещения при неадекватной замене (например, среднее вместо медианы при выбросах).
- Рекомендация: логировать и документировать каждую операцию замены.
Краткий глоссарий (1 строка на термин)
- NaN — специальное значение в pandas/NumPy, обозначающее отсутствующие данные.
- fillna — метод для заполнения NaN заданным значением или методом по соседям.
- replace — общий метод замены любых значений в DataFrame.
- interpolate — метод аппроксимации пропущенных чисел на основе соседних значений.
- mode — мода, наиболее часто встречающееся значение.
Краткое резюме
- Выбор метода зависит от типа данных и бизнес-контекста. Для чисел: mean/median/interpolate; для категорий: mode или маркер “Missing”. Всегда протестируйте и задокументируйте замену.
Notes:
- Всегда сохраняйте оригинал данных и проверяйте изменения статистик и метрик после заполнения.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
