Создание сводных таблиц в Python

Вводное описание
Сводные таблицы остаются одним из самых популярных инструментов в MS Excel. Независимо от того, являетесь ли вы аналитиком данных, инженером данных или просто частым пользователем — умение быстро агрегировать и смотреть данные по срезам часто экономит часы работы.
Python и библиотека pandas дают возможность воспроизвести большинство возможностей Excel PivotTable и при этом масштабировать обработку на большие наборы данных. В этой статье вы найдёте пошаговый разбор: от подготовки окружения до продвинутых приёмов и практических контрольных списков.
Кому будет полезно
- Аналитикам, которые хотят автоматизировать отчёты.
- Инженерам данных, готовящим агрегированные таблицы для BI.
- Тем, кто хочет заменить ручную работу в Excel на код reproducible.
Основные варианты использования (ключевой поисковый интент)
- Создание сводных таблиц в Python
- pandas pivot_table примеры
- мультииндекс в pandas
- агрегирование данных Python
- эквивалент Excel PivotTable в pandas
Предварительные требования
Перед началом убедитесь, что у вас есть:
- Установленный Python (рекомендуется 3.8+).
- IDE: Jupyter Notebook / JupyterLab, PyCharm, VS Code или Spyder.
- Библиотека pandas: установка через pip install pandas (или conda install pandas).
- Пример данных — в статье используется набор Sample Superstore в формате Excel (файл: Sample - Superstore.xls).
Дальнейшие примеры будут опираться на импорт Excel в DataFrame.
Импорт необходимых библиотек
Pandas — ключевая библиотека для создания сводных таблиц:
import pandas as pdЕсли вы используете Jupyter, полезно подключить отображение таблиц через display из IPython.display, но это опционально.
Импорт Excel в DataFrame
Для формирования сводной таблицы сначала импортируйте данные из Excel и проверьте первые строки:
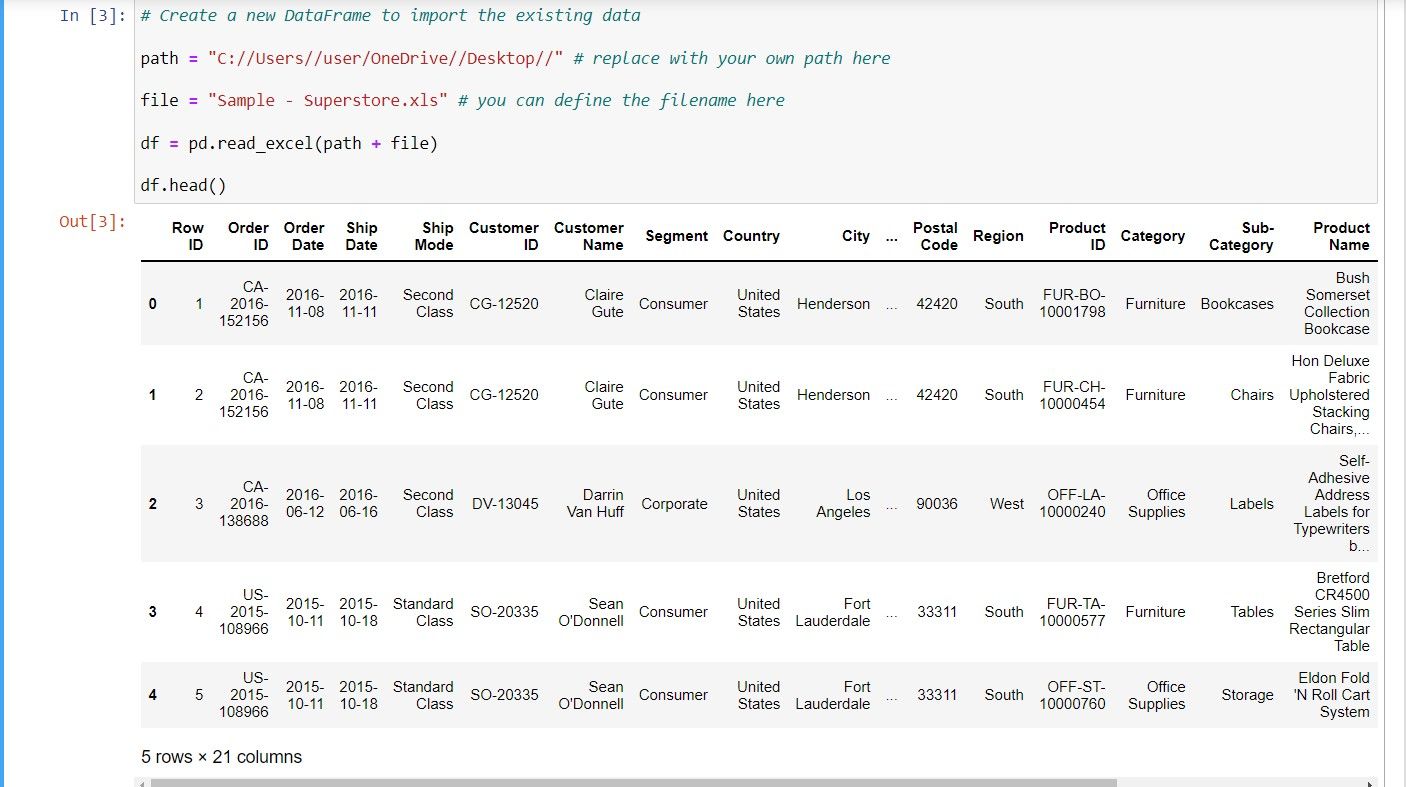
# Create a new DataFrame
# replace with your own path here
path = "C://Users//user/OneDrive//Desktop//"
# you can define the filename here
file = "Sample - Superstore.xls"
df = pd.read_excel(path + file)
df.head()Где:
- df — переменная DataFrame.
- read_excel() — функция pandas для чтения Excel-файла.
- head() — показывает первые 5 строк по умолчанию.
Совет: после импорта проверьте df.info() и df.describe() — это поможет увидеть типы столбцов и пропуски.
Поля сводной таблицы в pandas
Аналогично Excel, у pivot_table есть логические поля:
- Data — исходный DataFrame.
- values — столбцы, по которым считаются агрегаты.
- index — строки группировки (может быть список для мультииндекса).
- columns — столбцы для агрегации по отдельным стобцам в результирующей таблице.
Назначение index
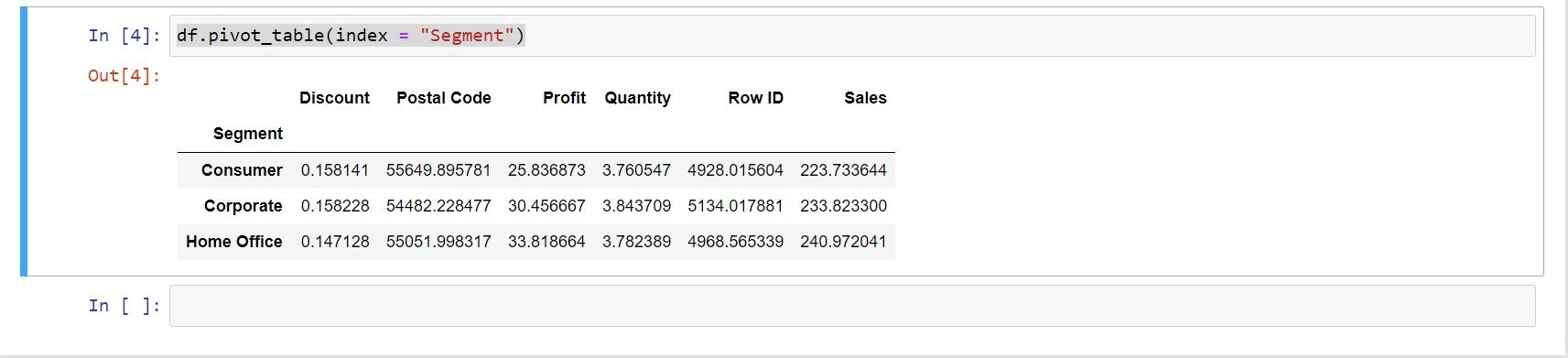
index задаёт уровень(и) группировки — то, что в Excel называется «строки» сводной таблицы. Например, чтобы увидеть агрегаты по сегментам:
df.pivot_table(index = "Segment")Это вернёт средние (mean) числовых столбцов по каждому Segment по умолчанию.
Important: переменные в Python чувствительны к регистру — используйте точные имена столбцов.
Мультииндекс (несколько уровней index)
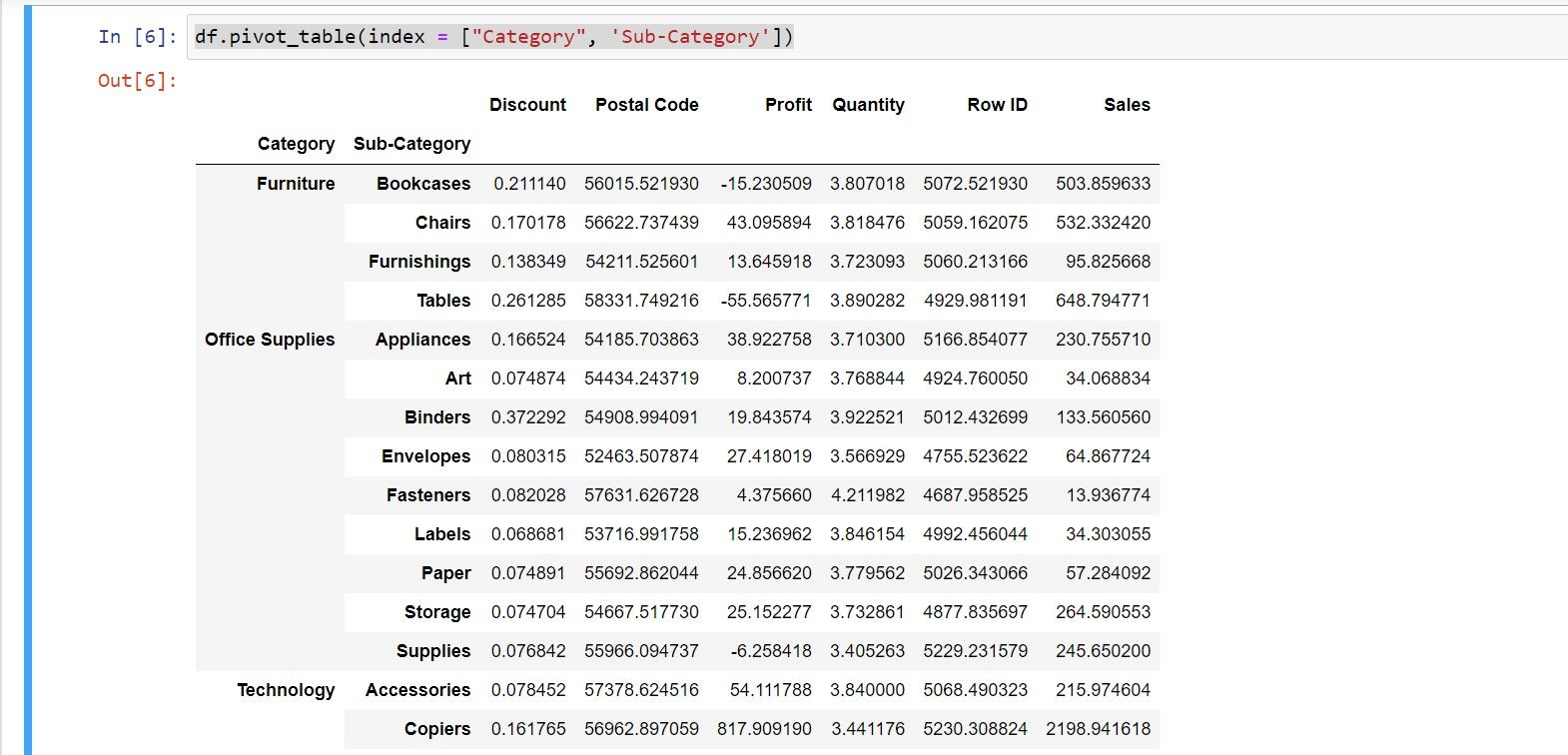
Чтобы использовать несколько уровней группировки, передайте список:
df.pivot_table(index = ["Category", "Sub-Category"])Результат будет иметь вложенную структуру индекса (MultiIndex) — pandas отобразит среднее всех числовых столбцов для комбинаций Category / Sub-Category.
Ограничение столбцов (values)
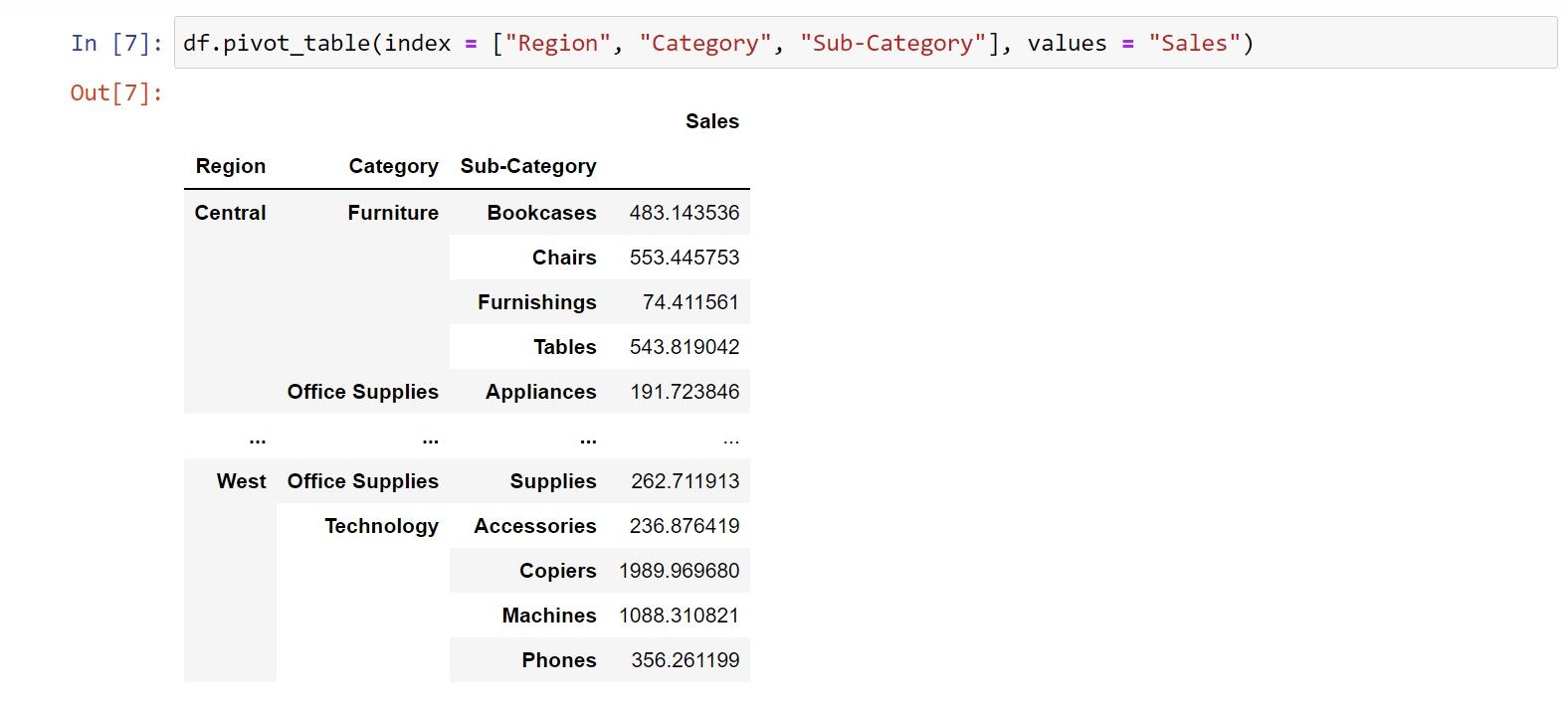
По умолчанию pivot_table агрегирует все числовые столбцы. Чтобы выбрать конкретный столбец:
df.pivot_table(index = ["Region", "Category", "Sub-Category"], values = "Sales")Теперь в таблице будут только средние значения Sales для каждой комбинации индексов.
Пользовательские функции агрегации (aggfunc)
По умолчанию используется mean. Но вы можете передать любую функцию или список функций:
df.pivot_table(index = ["Category"], values = "Sales", aggfunc = [sum, max, min, len])Где:
- sum — сумма.
- max — максимум.
- min — минимум.
- len — количество значений (аналог count).
Совет: вместо встроенных функций вы можете передать лямбда или функцию numpy, например numpy.sum, numpy.mean, или собственную функцию.
Агрегация разными функциями по разным столбцам
Если нужно использовать разные агрегаты для разных столбцов, передайте словарь:
df.pivot_table(index='Region', values=['Sales','Quantity'], aggfunc={'Sales':sum, 'Quantity':'mean'})Это даёт гибкость, сравнимую с Excel, но в кодируемом виде.
Добавление итогов (Grand Totals)
Чтобы получить общие итоги по строкам и столбцам, используйте параметры margins и margins_name:
df.pivot_table(index = ["Category"], values = "Sales", aggfunc = [sum, max, min, len], margins=True, margins_name='Grand Totals')margins=True добавляет строку и/или столбец итогов; margins_name задаёт подпись для этих итогов.
Полный пример кода
import pandas as pd
# replace with your own path here
path = "C://Users//user/OneDrive//Desktop//"
# you can define the filename here
file = "Sample - Superstore.xls"
df = pd.read_excel(path + file)
df.pivot_table(index = ["Region", "Category", "Sub-Category"], values = "Sales",
aggfunc = [sum, max, min, len],
margins=True,
margins_name='Grand Totals')Частые ошибки и когда сводные таблицы в pandas не подходят
- Очень большие датасеты (десятки миллионов строк) — pivot_table может быть медленнее, чем специализированные системы OLAP или оптимизированные SQL-запросы. В этом случае рассмотрите децентрализованную агрегацию на уровне СУБД или Dask.
- Неподготовленные данные: строки с различными типами в одном столбце, NaN в ключевых столбцах — приводят к неожиданным результатам.
- Если требуется интерактивный drag-and-drop интерфейс для конечных пользователей — Excel/BI-инструменты удобнее.
Альтернативные подходы
- groupby + agg: аналогична логика, но даёт больший контроль над порядком и видами агрегации.
df.groupby(['Region','Category'])['Sales'].agg(['sum','mean','count']).reset_index()- pivot (без агрегации) — преобразует длинный формат в широкий, но требует уникальных сочетаний index/columns.
- Использование Dask для распределённой агрегации и работы с данными, превышающими память.
Упрощённая методология (чек-лист) для создания сводной таблицы
- Исследуйте данные: df.info(), df.isnull().sum(), df.nunique().
- Приведите типы: даты => datetime, числовые столбцы => float/int.
- Определите уровни index и columns.
- Выберите values и aggfunc.
- Постройте pivot_table, проверьте NaN и отсортируйте.
- Экспортируйте результат: to_excel / to_csv / to_parquet.
Рекомендации по валидации и тест-кейсы (Критерии приёмки)
- Результат должен содержать ожидаемое количество строк/группировок для заданных index — сверить с df[columns].nunique().
- Суммы/средние по основным колонкам должны совпадать с контрольными вычислениями через groupby.
- Обработка пустых значений: при необходимости заполнить NaN через fill_value в pivot_table.
Примеры тестов:
- Для небольшого поднабора данных рассчитать вручную и сравнить с pivot_table.
- Проверить поведение при изменении aggfunc (sum vs mean) и при разных типах данных.
Сниппет — часто используемые параметры pivot_table (шпаргалка)
df.pivot_table(
index=['Region','Category'],
columns='Year',
values='Sales',
aggfunc={'Sales': sum},
fill_value=0,
margins=True,
margins_name='Итого',
dropna=False,
sort=False
)- fill_value — заменяет NaN результатами агрегирования.
- dropna=False — сохраняет колонки с NaN, если нужно увидеть пустые комбинации.
- sort=False — отключает автоматическую сортировку индекса.
Ментальные модели и эвристики
- «Index = уровни, Values = что считать, Aggfunc = как считать» — повторять вслух перед кодом.
- Думайте сначала о бизнес-вопросе: какой срез нужен пользователю? Затем формируйте index/columns.
- Если результат неудобочитаем — примените reset_index() и/или pivot/stack/unstack.
Роль‑ориентированные контрольные списки
Аналитик:
- Проверить корректность типов.
- Убедиться, что агрегация совпадает с бизнес-логикой.
Инженер данных:
- Автоматизировать импорт и проверку качества (CI tests).
- Обеспечить reproducible pipeline и регрессионные тесты.
Конечный пользователь/BI-разработчик:
- Подготовить читабельный экспорт (Excel/CSV).
- Добавить комментарии и метаданные (описания столбцов).
Безопасность и приватность
Если данные содержат персональные данные (PII), убедитесь, что:
- Доступ к файлам ограничен по ролям.
- При экспорте агрегированные таблицы не раскрывают отдельные записи.
- Выполняется соответствие локальным требованиям по защите данных (например, GDPR в ЕС): минимизация передаваемых полей, псевдонимизация при необходимости.
Короткий глоссарий (одной строкой)
- DataFrame — табличная структура pandas, похожая на таблицу в Excel.
- index — уровень(и) группировки в pivot_table.
- values — столбец(ы) для агрегирования.
- aggfunc — функция(и) агрегирования (sum, mean и т.д.).
Итог и рекомендации
Сводные таблицы в pandas дают мощный и гибкий инструмент для агрегирования и подготовки данных к отчётам. Если вы уже пользуетесь Excel, перенос логики в pandas позволит автоматизировать повторяющиеся отчёты, интегрировать агрегации в ETL и обрабатывать большие объёмы данных. В случаях экстремально больших объёмов или потребности в интерактивной визуализации лучше комбинировать pandas с Dask, SQL или BI-системой.
Note: Начинайте с небольших шагов — сначала воспроизведите существующую Excel-сводную таблицу в pandas, затем постепенно автоматизируйте и оптимизируйте.
Краткое резюме
- pandas.pivot_table воспроизводит основную функциональность Excel PivotTable.
- Используйте index, columns, values и aggfunc для гибкой агрегации.
- Для больших данных рассматривайте Dask/СУБД, а для интерактивности — BI-инструменты.
Спасибо за внимание — пробуйте примеры на своём наборе данных и адаптируйте шаблоны под рабочие задачи.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
