Как запустить локальный GPT‑чатбот на Windows

- Запуск локального GPT‑чатбота на Windows позволяет работать без онлайн‑ограничений и сохранять данные на своём ПК. Установите WSL2 и Docker, запустите сборку text‑generation‑web‑ui в контейнере Docker и загрузите модель openai‑community/gpt2 через веб‑интерфейс.
- В этой инструкции пошагово объяснено, как подготовить систему, выбрать вариант образа для GPU или CPU, запустить контейнер, загрузить модель и начать базовую настройку для безопасного использования.
Что вы получите из этой инструкции
- Полный план действий для установки локального GPT‑чатбота на Windows с Docker и WSL2.
- Понятные практические советы по конфигурации, тестированию и устранению неполадок.
- Рекомендации по безопасности, приватности и поддержке сервиса.
Введение
Локальный GPT‑чатбот — это модель генерации текста, запущенная на вашем компьютере без внешних API. Это полезно, когда вы хотите сохранять данные локально, тонко настраивать поведение модели или экспериментировать без ограничений внешних сервисов.
Коротко о терминах
- LLM — большая языковая модель, способная генерировать текст.
- Контейнер Docker — изолированная среда, где упаковано приложение и его зависимости.
- WSL2 — подсистема Windows для запуска Linux, рекомендованная для Docker на Windows.
Почему имеет смысл запускать локальный чатбот
- Приватность: данные остаются на вашей машине.
- Контроль: вы выбираете модель, версии и настройки.
- Гибкость: можно добавлять локальные корпус‑данные, LoRA и скрипты.
- Обучение и эксперименты: удобнее тестировать кастомные датасеты.
Важно: локальные модели обычно уступают по качеству современным облачным LLM, если речь о самых больших и свежих архетипах. Но для многих задач локальная модель с корректной настройкой и дообучением вполне достаточна.
Содержание
- Предварительные требования
- Шаг 1 Установка WSL2 и Docker, установка Windows Terminal
- Шаг 2 Скачивание репозитория text‑generation‑web‑ui‑docker
- Шаг 3 Запуск и проверка контейнера
- Шаг 4 Загрузка модели openai‑community/gpt2
- Шаг 5 Первые настройки и использование
- Рекомендации по безопасности и сохранению данных
- Критерии приёмки и тесты
- Справочник по устранению неполадок
- Чек‑листы по ролям
- Плейбук обновления и отката
- Решающее дерево принятия решений
Предварительные требования
- Windows 10 или Windows 11 с поддержкой WSL2.
- Достаточно свободного места на диске для образов Docker и моделей (несколько гигабайт минимум).
- Совместимый GPU от NVIDIA рекомендуется для ускорения работы модели; без GPU можно запустить вариант для CPU, но производительность будет ниже.
- Учётная запись с правами администратора для установки компонентов.
Совет: если вы планируете экспериментировать с более тяжёлыми моделями, подготовьте диск на 50–200 ГБ свободного места и как можно больше оперативной памяти.
Шаг 1: Установка WSL2, Docker и Windows Terminal
- Установите WSL2, если он ещё не включён. Откройте PowerShell от имени администратора и выполните:
wsl --installПосле установки перезагрузите систему, если система попросит.
Установите Docker Desktop для Windows. Во время установки убедитесь, что выбран режим использования WSL2. После установки откройте Docker Desktop и проверьте, что движок запущен.
Установите Windows Terminal из Microsoft Store или с сайта, чтобы удобно работать с PowerShell, CMD и WSL.
Важно: для корректной работы GPU в WSL2 с Docker потребуется установить драйверы NVIDIA для WSL. Посетите официальный сайт NVIDIA и установите рекомендованные драйверы для вашей карты и версии WSL.
Примечание: если вы не имеете GPU или не хотите использовать GPU, можно выбрать вариант сборки для CPU, но ожидание ответа будет дольше.
Шаг 2: Скачивание репозитория text‑generation‑web‑ui‑docker
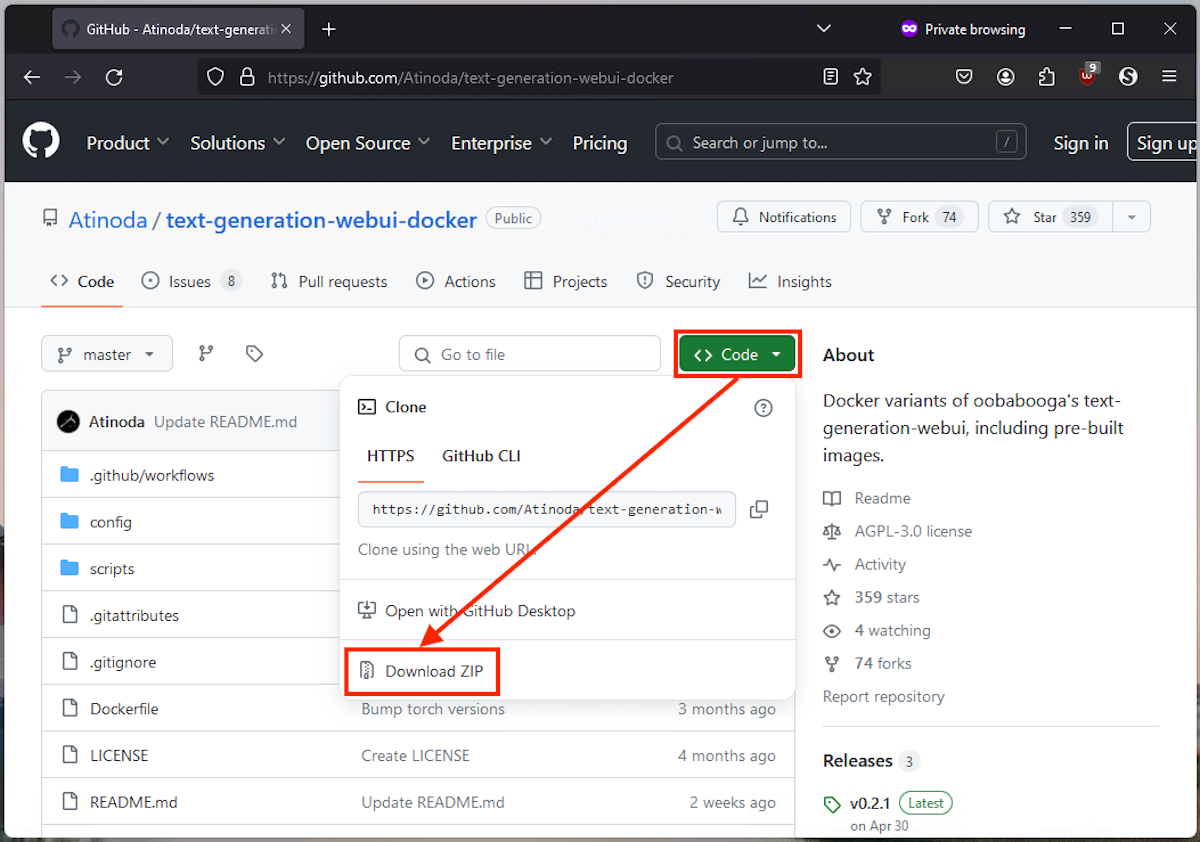
- Откройте страницу репозитория text‑generation‑web‑ui‑docker на GitHub.
- Нажмите «Code» и выберите «Download ZIP» или клонируйте репозиторий командой git, если предпочитаете:
git clone https://github.com/your/repo.git- Распакуйте ZIP в удобную папку и откройте её в Проводнике.
Совет: храните папку проекта на диске с достаточным пространством и делайте резервные копии важных настроек.
Шаг 3: Настройка и запуск text‑generation‑web‑ui в Docker
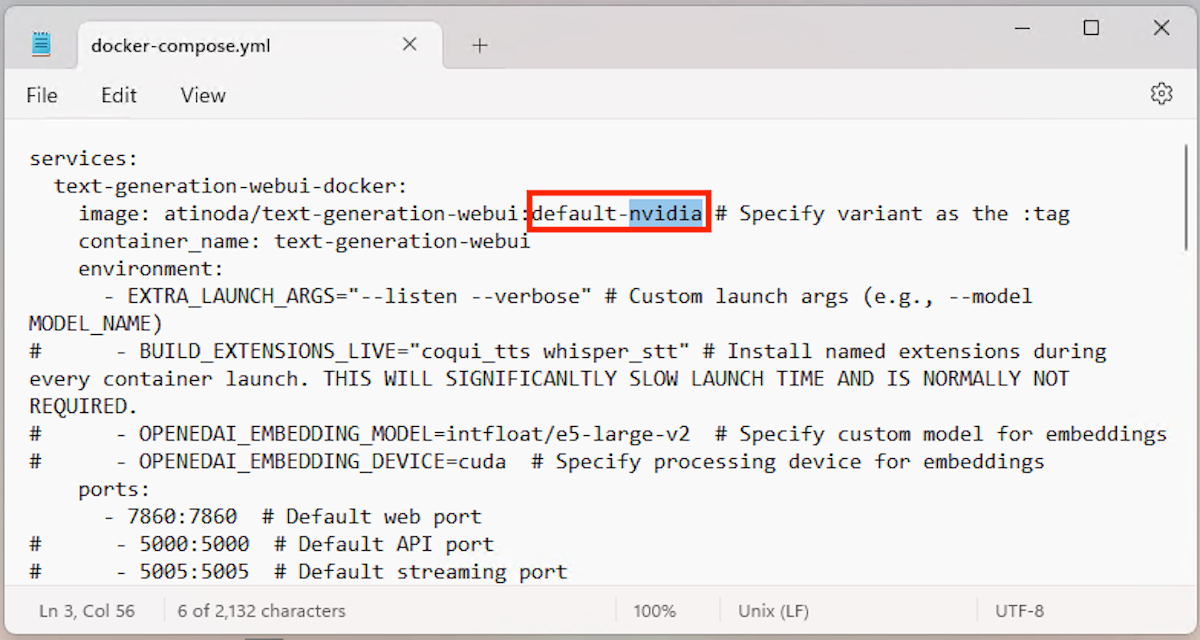
Перед запуском откройте файл docker‑compose.yml в любом текстовом редакторе. Найдите параметр, где указывается вариант образа или переменная variant и замените на подходящий для вашей машины: default‑nvidia или default‑cpu.
Откройте папку с распакованными файлами, кликните правой кнопкой и выберите «Открыть в терминале» чтобы запустить PowerShell или Windows Terminal в нужной директории.
- Убедитесь, что Docker Desktop запущен, и выполните команду:
docker compose up -dЭта команда поднимет контейнер в фоновом режиме. Если образа ещё нет локально, Docker загрузит его из реестра. Это может занять от нескольких минут до часа в зависимости от скорости интернета.
- Проверка статуса контейнера:
docker compose psили просмотрите логи:
docker compose logs -f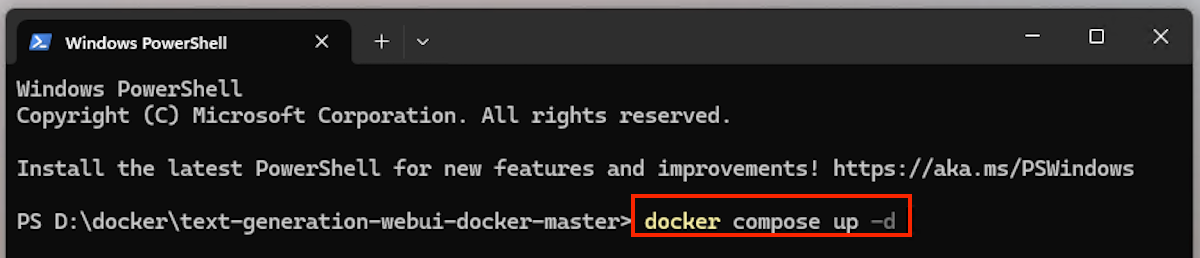
- Контейнер появится в Docker Desktop, где его можно стартовать, останавливать и перезапускать через графический интерфейс.
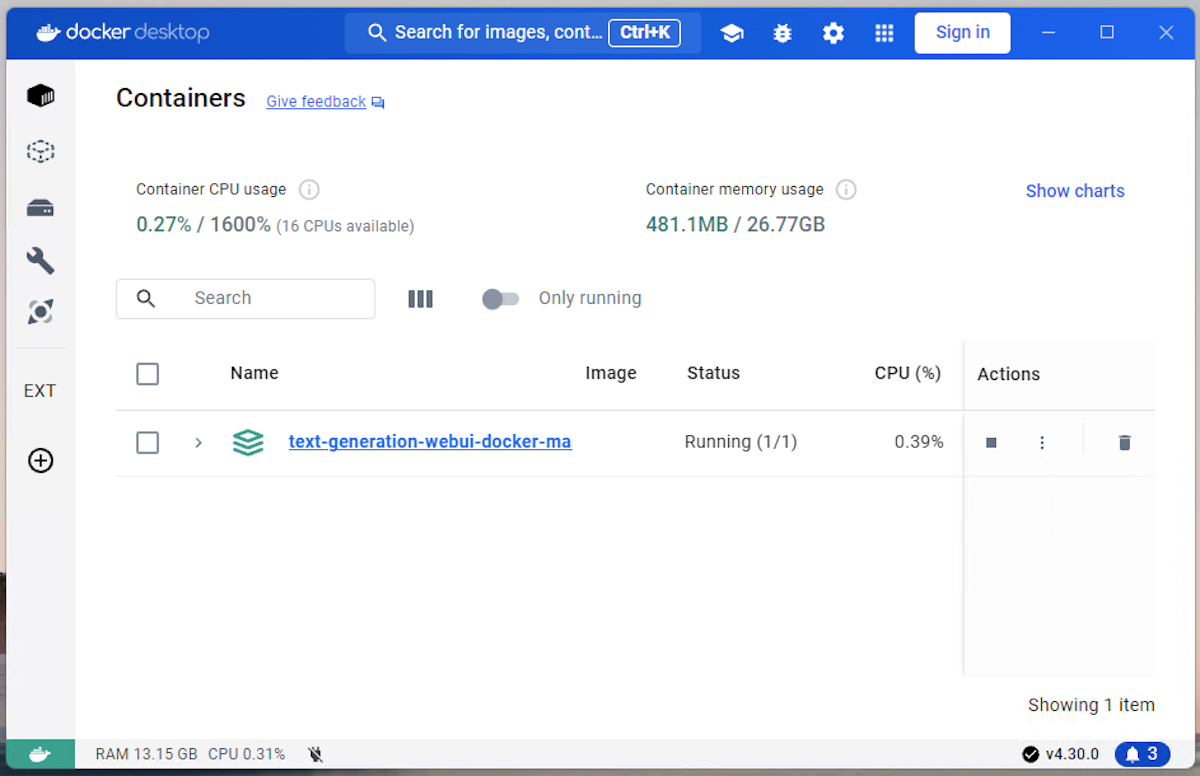
Важно: если контейнер не запускается, проверьте логи и ошибки в них. Наиболее частые причины — несовместимость драйверов GPU, нехватка прав, занятый порт или проблемы в составе docker‑compose.yml.
Шаг 4: Загрузка модели openai‑community/gpt2
- Откройте браузер и перейдите по адресу:
http://localhost:7860Веб‑интерфейс text‑generation‑web‑ui доступен на этом порту по умолчанию. В интерфейсе откройте вкладку Model.
В поле для загрузки модели введите:
openai‑community/gpt2и нажмите кнопку Загрузить.
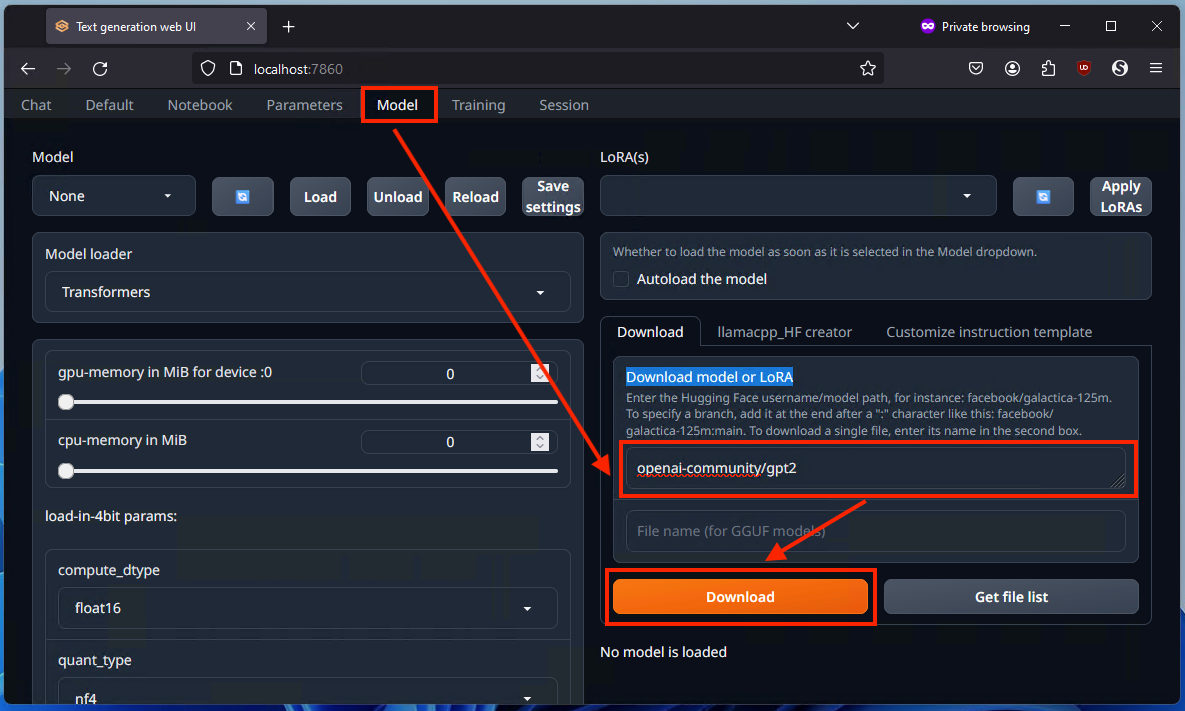
- После завершения загрузки нажмите Обновить и выберите модель openai‑community/gpt2 в выпадающем списке, затем нажмите Загрузить модель.
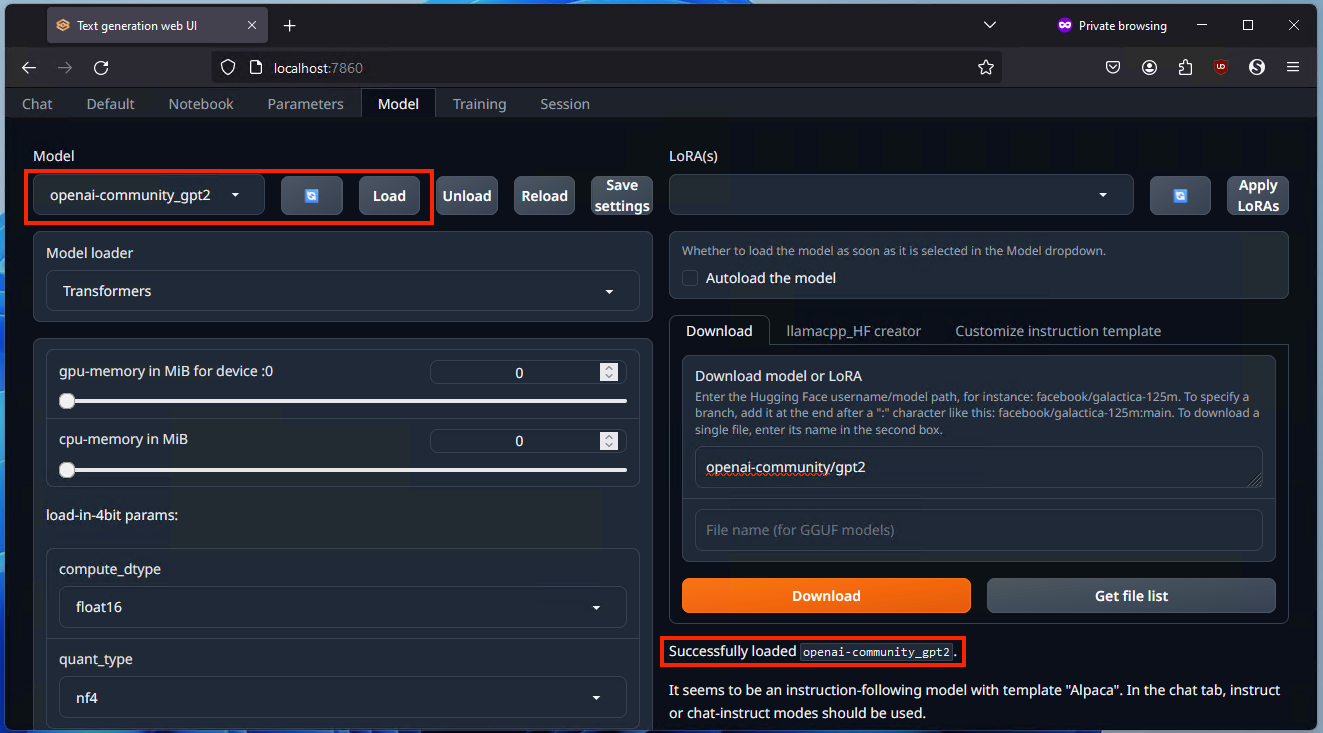
Примечание: модель GPT‑2 старее и легче современных гигантов. Она подходит для задач, где приоритет — автономность и быстрый старт, но по качеству ответов уступает современным крупным LLM.
Шаг 5: Первые шаги с чатботом и базовая настройка поведения
Локальный GPT без подсказки системы часто ведёт себя непредсказуемо. Рекомендуется задавать системные инструкции и шаблоны подсказок.
Пример шаблона системной подсказки:
- Вы — помощник по форматированию и кратким ответам. Отвечайте ясно и вежливо. Если не уверены, попросите уточнить.
Примеры подсказок пользователя:
- «Сделай краткий список задач по подготовке отчёта на основе файла X»
- «Напиши шаблон письма коллеге о переносе дедлайна»
- «Помоги с простым примером кода на Python, который делает X»
Совет: начните с коротких и чётких инструкций, затем добавляйте поведенческие правила и ограничения, чтобы получить более предсказуемую генерацию.
Тонкая настройка и расширение возможностей
- LoRA и дообучение: text‑generation‑web‑ui поддерживает подключение LoRA и других адаптаций. Это позволяет подогнать модель под специфичную лексику или стиль.
- Контекст и память: храните часто используемые подсказки в локальной библиотеке и подгружайте при запуске сеанса.
- Интеграции: можно подключать локальные базы данных, инструменты поиска по документам и индексирования для повышения точности ответов по корпоративным документам.
Критерии приёмки
- Ветеринария развертывания: контейнер запускается и слушает порт 7860.
- Модель загружена и успешно «Load» показывает статус готовности.
- Чатбот отвечает на базовые запросы корректно в течение 5–10 секунд на GPU или в разумные сроки на CPU.
Справочник по устранению неполадок
Проблема 1: сайт не открывается на localhost:7860
- Проверьте, что контейнер запущен: docker compose ps.
- Убедитесь, что порт 7860 не занят другим приложением.
- Проверьте логи: docker compose logs — ищите ошибки и исключения.
Проблема 2: GPU не обнаружен
- Установите драйверы NVIDIA для WSL и убедитесь, что в Docker Desktop включена интеграция с WSL.
- Включите поддержку GPU в docker‑compose.yml, если требуется.
- Проверьте, что команда nvidia‑smi внутри контейнера видна через docker exec.
Проблема 3: недостаточно памяти
- Используйте вариант модели меньшего размера или ограничьте длину контекста.
- Закройте лишние контейнеры и приложения, либо увеличьте выделение памяти в Docker Desktop.
Чек‑листы по ролям
Чек‑лист для разработчика
- Установить WSL2 и Docker.
- Проверить совместимость GPU.
- Сконфигурировать docker‑compose.yml для варианта GPU/CPU.
- Настроить окружение, проверить логи и автоматизацию перезапуска контейнера.
Чек‑лист для специалиста по данным
- Подготовить локальные корпуса для дообучения или LoRA.
- Проверить лицензии и права на использование данных.
- Настроить индексацию и поиск по документам для улучшения ответов.
Чек‑лист для администратора безопасности
- Убедиться, что доступ к порту 7860 ограничен локальной сетью.
- Настроить бэкапы конфигураций и моделей.
- Провести оценку риска и задокументировать поток данных.
Плейбук обновления и отката
- Подготовка: сделать бэкап docker‑compose.yml и конфигурационных файлов.
- Тестирование: развернуть обновлённую версию в тестовой среде.
- Миграция: применить изменения в рабочей среде в окне технического обслуживания.
- Откат: выполнить docker compose down, вернуть старые файлы конфигурации и docker compose up -d.
Инцидентный план
- Признак проблемы: сервис недоступен или отвечает ошибками.
- Действия: проверить логи, перезапустить контейнер, вернуть предыдущую версию конфига, восстановить бэкап модели.
- Эскалация: подключить инженера по инфраструктуре и специалиста по данным.
Тесты и критерии приёмки
Тесты функциональности
- Тест 1: интерфейс открывается по адресу http://localhost:7860.
- Тест 2: загрузка модели openai‑community/gpt2 завершается без ошибок.
- Тест 3: чат отвечает на простые запросы в адекватные сроки.
Критерии приёмки
- Все тесты успешно прохождены на целевой машине.
- Документированы шаги и конфигурация.
- Проведено тестирование безопасности и сохранения данных.
Безопасность и приватность
- Локальные данные остаются на вашем устройстве, но убедитесь, что само устройство защищено паролем и шифрованием диска.
- Если вы обмениваетесь моделями и данными, проверяйте лицензии и политику использования.
- Для корпоративного использования ограничьте доступ к интерфейсу через локальную сеть или VPN.
Примечание по GDPR и персональным данным
- Если в модели используются персональные данные, документируйте юридическую основу обработки и срок хранения данных.
- Подумайте о стратегиях удаления данных и анонимизации перед использованием для дообучения.
Ментальные модели и рекомендации
- Модель = инструмент. Отнеситесь к результатам как к подсказке, а не окончательной истине.
- Чем лучше шаблон подсказки и контекст, тем более полезный ответ.
- Локальная модель хороша для приватных, узкоспецифичных задач; облачные LLM лучше для общего интеллекта и свежих данных.
Решающее дерево для выбора конфигурации
flowchart TD
A[Есть NVIDIA GPU в системе?] -->|Да| B[Использовать вариант default‑nvidia]
A -->|Нет| C[Использовать вариант default‑cpu]
B --> D[Установить драйверы NVIDIA для WSL]
D --> E[Запустить docker compose up -d]
C --> E
E --> F[Открыть http://localhost:7860]
F --> G{Модель загружается?}
G -->|Да| H[Загрузить openai‑community/gpt2]
G -->|Нет| I[Проверить логи и настройки Docker]Советы по эффективному использованию
- Храните набор шаблонов подсказок и системных инструкций.
- Делайте бэкапы скачанных моделей и конфигураций.
- Начинайте с небольших экспериментов и увеличивайте масштаб по мере стабильности.
Когда локальный подход не подходит
- Если вам нужна самая свежая информация и самые крупные модели с лучшим качеством, облачные LLM могут быть предпочтительней.
- Если вы не готовы тратить время на настройку и администрирование — облачный сервис удобнее.
Ресурсы для дальнейшего изучения
- Документация text‑generation‑web‑ui на GitHub.
- Страницы моделей и LoRA на HuggingFace.
- Официальные инструкции NVIDIA по драйверам для WSL.
Краткое резюме
- Локальный GPT‑чатбот на Windows даёт контроль и приватность.
- Ключевые шаги: установить WSL2 и Docker, скачать репозиторий, выбрать вариант для GPU/CPU, запустить контейнер и загрузить модель openai‑community/gpt2.
- Настройка и дообучение позволяют улучшить ответы под ваши сценарии использования, но требуют времени и ресурсов.
Короткое объявление
Запустите локальный GPT‑чатбот на вашем Windows‑ПК — контролируйте данные, экспериментируйте с моделями и настройками, работайте без внешних ограничений. Инструкция по установке Docker, скачиванию репозитория, загрузке GPT‑2 и основам настройки поможет быстро начать.
Похожие материалы

RDP: полный гид по настройке и безопасности

Android как клавиатура и трекпад для Windows

Советы и приёмы для работы с PDF

Calibration в Lightroom Classic: как и когда использовать

Отключить Siri Suggestions на iPhone
