Проверка и оповещение о заполнении диска на Linux
Быстрые ссылки
- Проверка использования диска на Linux
- Мониторинг в одном экране
- Оповещения при высоком заполнении диска
Часто легко заметить ошибки с памятью или загрузкой CPU. Но дисковое пространство может бесшумно сокращаться. Если вы оставите сервер без наблюдения, место закончится внезапно. Ниже — практические команды и шаблоны для автоматизации оповещений.
Проверка использования диска на Linux
Основная утилита для быстрой проверки — df (disk filesystems). Она выводит список файловых систем и их использование.
df -hT- Опция -h выводит размеры в удобочитаемом формате (KB/MB/GB).
- Опция -T показывает тип файловой системы.
Вы увидите размер, занятую и доступную ёмкость и точку монтирования для каждой файловой системы.
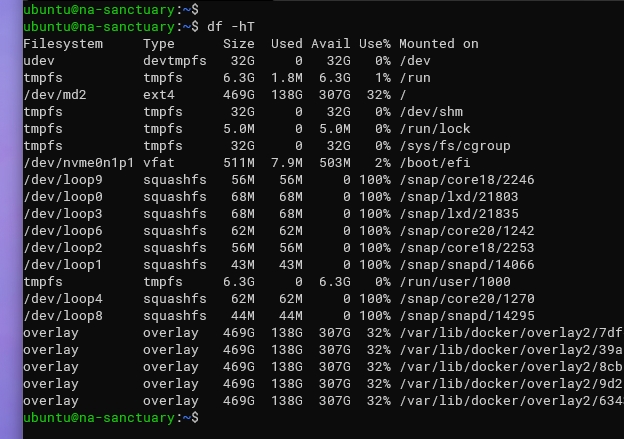
На серверах часто больше «файловых систем», чем физических дисков. Это нормальная ситуация: Linux использует tmpfs, devtmpfs, squashfs, overlay и другие виртуальные файловые системы для контейнеров, сжатых образов и системных ресурсов. Реальный диск часто помечен как ext4, xfs или btrfs и примонтирован в корень (/).
Чтобы отфильтровать вывод по типу файловой системы, используйте -t:
df -hT -t ext4Или исключите ненужные типы с помощью -x:
df -hT -x squashfs -x overlay -x tmpfs -x devtmpfsМожно запрашивать конкретные устройства или точки монтирования:
df -h /dev/md*
df -h /Мониторинг в одном экране
Командный набор удобно заменяет утилита glances. Это консольный дашборд для многих метрик системы: CPU, память, сеть и диски.
Установка через pip:
sudo pip install glancesЗапустить просто:
glances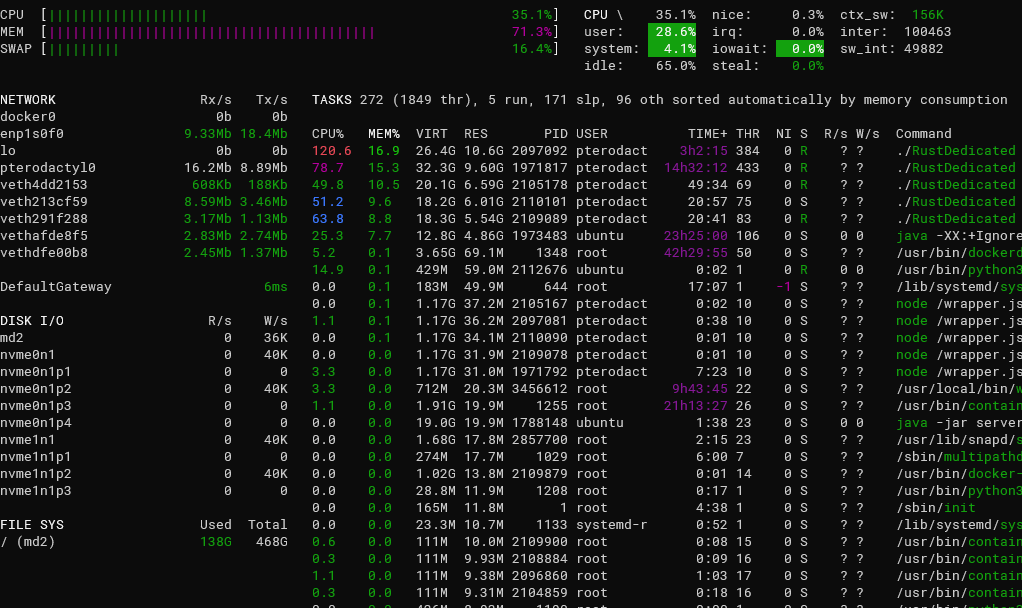
Нижний левый угол обычно показывает использование дисков и текущие скорости ввода-вывода. Это помогает заметить растущую нагрузку или быстро заполняющиеся разделы.
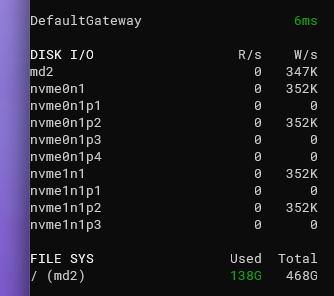
Glances не единственный инструмент, но он прост, информативен и кросс-платформенен.
Оповещения при высоком заполнении диска
Командные инструменты полезны, но требуют активности от администратора. Лучше настроить автоматические оповещения. Ниже — пошаговый метод и рабочие примеры.
Основная идея:
- Скрипт запускает df и получает процент использования корневого раздела.
- Скрипт сравнивает текущую загрузку с порогом (например, 90%).
- При превышении порога он отправляет уведомление (почта, Slack, Telegram и т.д.).
Оригинальный простой пример (сохраняем для совместимости):
#!/bin/bash
CURRENT=$(df / | grep / | awk '{ print $5}' | sed 's/%//g')
THRESHOLD=90
if [ "$CURRENT" -gt "$THRESHOLD" ] ; then
curl -X POST -H 'Content-type: application/json' --data "{"text":"Your server `$(hostname)` is currently at ${CURRENT}% disk capacity."}"
fiЭтот скрипт демонстрирует идею. Но в нём есть проблемы с экранированием и безопасностью. Ниже — улучшённая и безопасная версия с примерами отправки в Slack и по почте.
Надёжный пример для Slack (Webhook)
Создайте файл /usr/local/bin/check_disk.sh и сделайте его исполняемым.
#!/bin/bash
set -euo pipefail
# Настройки
MOUNT="/"
THRESHOLD=90
SLACK_WEBHOOK_URL="https://hooks.slack.com/services/XXXXXXXXX/XXXXXXXXX/XXXXXXXXXXXXXXXXXXXXXXXX"
# Получаем процент без символа %
CURRENT=$(df --output=pcent "$MOUNT" | tail -n1 | tr -dc '0-9')
if [ -z "$CURRENT" ]; then
echo "Не удалось получить использование для $MOUNT" >&2
exit 1
fi
if [ "$CURRENT" -gt "$THRESHOLD" ]; then
HOSTNAME=$(hostname -f)
PAYLOAD=$(printf '{"text":"%s: раздел %s заполнен на %s%%"}' "$HOSTNAME" "$MOUNT" "$CURRENT")
curl -sS -X POST -H 'Content-type: application/json' --data "$PAYLOAD" "$SLACK_WEBHOOK_URL"
fiПояснения:
- df –output=pcent удобнее и стабильнее для парсинга.
- set -euo pipefail помогает ловить ошибки.
- Не храните webhook в репозитории; используйте защищённые переменные окружения или vault.
Пример отправки на почту (mailx)
if [ "$CURRENT" -gt "$THRESHOLD" ]; then
echo "Текущая загрузка $CURRENT% на $(hostname) (раздел $MOUNT)" | mailx -s "ALERT: Заполнение диска $CURRENT%" admin@example.com
fiCron и systemd-timer
Добавьте в crontab (пример ежедневной проверки в 08:00):
0 8 * * * /usr/local/bin/check_disk.shИли используйте systemd-timer для лучшего логирования и управления правами.

Когда это не сработает
- Файлы удалены, но процессы всё ещё держат дескрипторы — df покажет свободное место, но inode/логика приложений может вести себя иначе. lsof + grep deleted поможет найти такие процессы.
- Заполнение временных папок (например, /tmp внутри tmpfs) не видно в выводе команд, если вы фильтруете типы FS неправильно.
- Проблемы с метриками контейнеров: контейнеры могут иметь тонкие слои overlay и quota, которые не отражаются простым df.
Альтернативные подходы
- Использовать мониторинг на базе Prometheus + node_exporter и настроить правила алертов в Alertmanager.
- Использовать облачные метрики и оповещения (AWS CloudWatch, GCP Monitoring).
- Хостовые агенты (Datadog, Zabbix, New Relic) для агрегации и долгосрочной истории.
Чек-листы по ролям
Системный администратор:
- Настроить df и glances на всех узлах.
- Развернуть check_disk.sh с правильными правами.
- Настроить безопасное хранение webhooks/паролей.
DevOps инженер:
- Интегрировать метрику в существующий мониторинг (Prometheus, Datadog).
- Создать алерты с уровнем серьезности и эскалациями.
Менеджер/оператор:
- Установить пороги и SLA. Например: предупреждение при 85%, критический алерт при 95%.
- Определить владельцев инцидента и процедуру расширения диска.
Критерии приёмки
- Скрипт успешно выполняется по расписанию без ошибок в логах в течение 7 дней.
- При достижении порога отправляется уведомление в канал/почту, проверяемое вручную.
- Webhook/учётные данные не хранятся в публичных репозиториях.
- Для production-приложений есть план действия при алерте (удаление временных файлов, архивирование, увеличение диска).
Тестовые сценарии
- Генерируем заполнение тестового раздела до 92% и проверяем, что алерт пришёл.
- Удаляем webhook URL и проверяем, что скрипт логирует ошибку, но не раскрывает секреты.
- Симулируем процесс, который держит удалённые файлы, и проверяем, как это влияет на df и на lsof.
Безопасность и надёжность
- Не храните токены в скрипте с правами 644. Доступ только root или специальный сервисный аккаунт.
- Ограничи доступ к логам, где может появиться тело уведомления с чувствительной информацией.
- Используйте TLS для webhooks и проверяйте сертификаты (curl по умолчанию проверяет).
- Разделяйте уровни оповещений: информационные, предупреждения, критические.
Минимальная методология внедрения
- Добавьте df-скрипт на один ненагруженный сервер.
- Протестируйте отправку уведомлений (Slack/почта).
- Протестируйте cron/systemd-timer.
- Раскатайте по группе, мониторьте логи и false-positive.
- Интегрируйте с центральным мониторингом и настройте эскалации.
Краткий глоссарий
- df — утилита для отображения использования файловых систем.
- glances — монитор в реальном времени для множества метрик.
- webhook — URL для отправки HTTP POST уведомлений в сторонние сервисы.
- tmpfs — файловая система в памяти.
Итог
Проверка дискового пространства — обязательная часть поддержки серверов. Простые команды (df), интерактивные инструменты (glances) и автоматические оповещения (cron + curl / интеграция с мониторингом) дают надёжную систему наблюдения. Настройте пороги, протестируйте уведомления и храните секреты безопасно.
Важно: проверяйте не только используемый процент, но и inode, открытые удалённые файлы и квоты контейнеров. Это уменьшит количество неожиданных инцидентов.
Похожие материалы

RDP: полный гид по настройке и безопасности

Android как клавиатура и трекпад для Windows

Советы и приёмы для работы с PDF

Calibration в Lightroom Classic: как и когда использовать

Отключить Siri Suggestions на iPhone
