Команда head в Linux — быстрое руководство и примеры

- Команда head по умолчанию выводит первые 10 строк файла или входного потока. Используйте -n для строк и -c для байтов.
- head удобно комбинировать с grep, awk, cut, tail и wc для выборочного просмотра и оперативного мониторинга логов.
Быстрые ссылки
- Что такое команда head в Linux?
- Опции команды head
- Вывод определённого числа строк
- Чтение определённого числа байтов
- Просмотр конкретных символов
- Отображение имени файла
- Вывод нескольких файлов
- Использование head с другими командами
- Отображение концов строк и обзор альтернатив
Краткое резюме
- По умолчанию команда head (например, head example.txt) выводит первые 10 строк текстового файла или данных из стандартного ввода.
- Для вывода заданного числа строк применяйте -n N; для ограничения по байтам — -c N.
- head часто используется для быстрого анализа логов и других текстовых файлов, которые постоянно меняются.
Что такое команда head в Linux?
Linux содержит несколько команд для просмотра содержимого файлов: cat, less и view — самые популярные. Но если нужно быстро увидеть начало файла, удобнее всего использовать head. Она делает противоположное tail: показывает начало файла, а tail — конец.
По умолчанию head выводит первые 10 строк. Синтаксис простой и схож с другими утилитами:
head [OPTION]... [FILE]...Если файл не указан, head читает из стандартного ввода. Проверить версию утилиты можно так:
head --version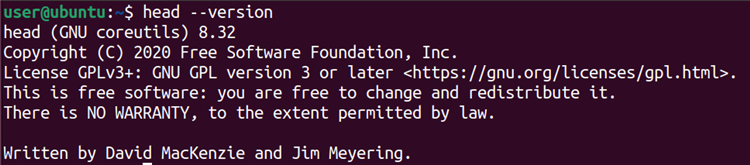
Справочную информацию выводит:
head --help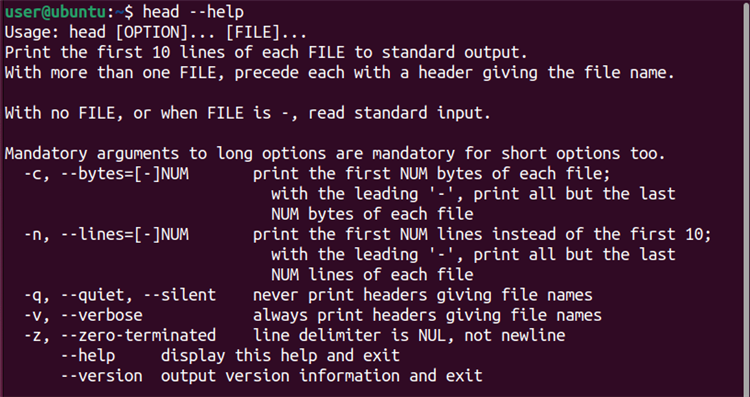
Опции команды head
Ниже переведённая таблица опций, часто используемых с head:
| Опция | Описание |
|---|---|
-n или --lines | Задаёт количество строк, выводимых с начала. |
-c или --bytes | Выводит указанное количество байтов с начала. |
-v или --verbose | Печатает имя файла перед его содержимым — полезно при нескольких файлах. |
-q или --quiet | Подавляет вывод имён файлов — полезно при единственном файле или при перенаправлении. |
-z или --zero-terminated | Заменяет символ новой строки на NUL (NULL) в конце каждой строки. |
Важно: опция -n и -c принимают и отрицательные значения. Отрицательное значение означает «вывести всё, кроме последних N строк/байтов».
Пример: подготовка тестового файла
Для демонстрации используем файл example.txt с 15 строками. Посмотреть его полностью можно так:
cat example.txt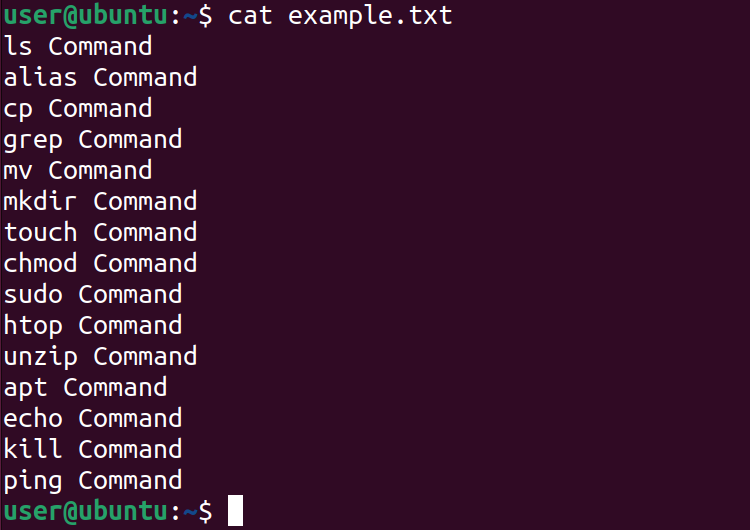
А команда head без опций покажет первые 10 строк:
head example.txt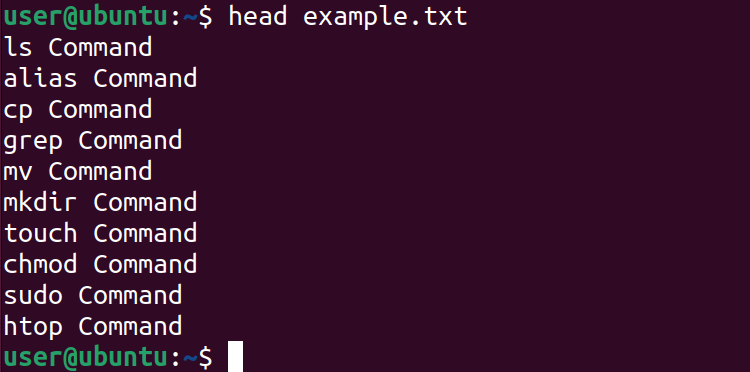
Вывод определённого числа строк
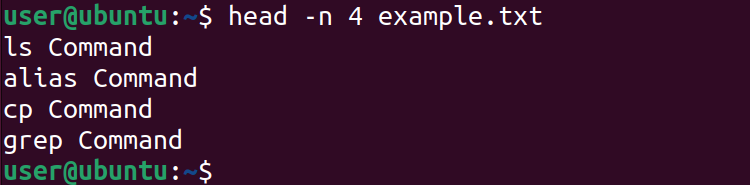
Чтобы вывести конкретное количество строк, используйте -n или --lines:
head -n 4 example.txtЭтот пример выведет первые четыре строки.
Отрицательное значение полезно, когда нужно пропустить N строк с конца:
head -n -2 example.txtКоманда выведет файл полностью, кроме двух последних строк.
Чтение определённого числа байтов
Опция -c позволяет ограничить вывод по байтам, а не по строкам:
head -c 20 example.txtДля ASCII-символов один символ равен одному байту. Но если файл в UTF-8 и содержит необычные символы, один символ может занимать несколько байтов — см. раздел про кодировку ниже.
Отрицательное значение -c -N выведет всё, кроме последних N байтов:
head -c -13 example.txt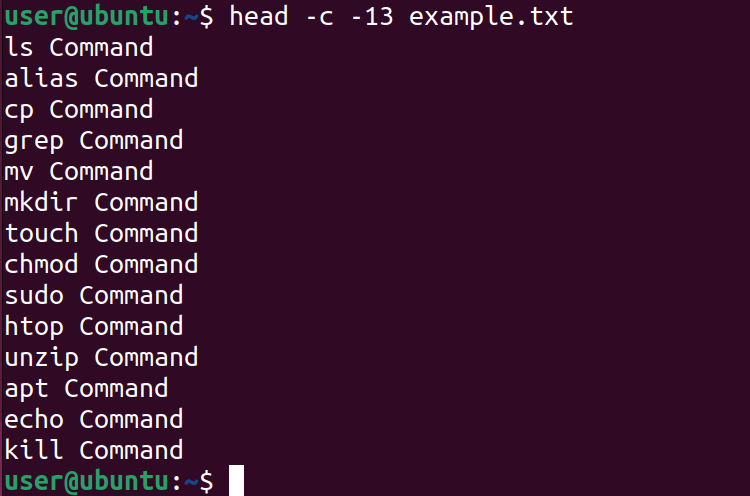
Просмотр конкретных символов и полей
Иногда нужно посмотреть не строки целиком, а отдельные символы или поля. Для этого head часто комбинируют с cut, awk или sed.
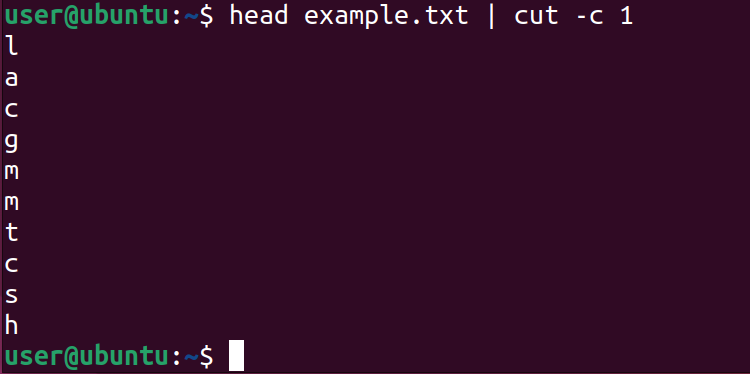
- Первые символы строк (по умолчанию первых 10 строк):
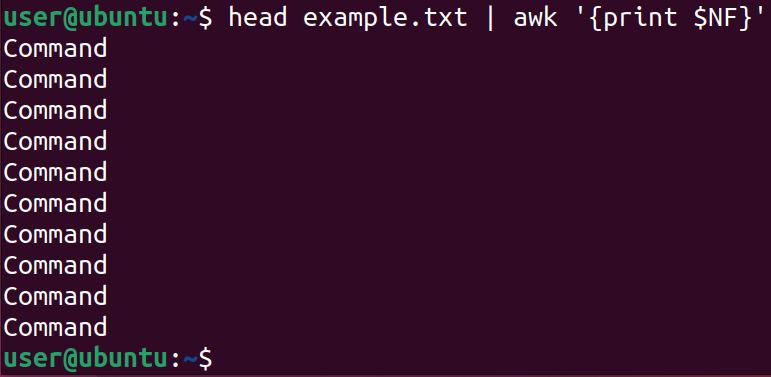
head example.txt | cut -c 1- Последнее слово каждой строки:
head example.txt | awk '{print $NF}'Комбинация head + команды для обработки строк удобна, когда файл большой, но нужен только фрагмент сверху.
Отображение имени файла
Если вы используете head с несколькими файлами, утилита по умолчанию печатает заголовок с именем файла. Для явного вывода заголовка используется -v:
head -v example.txt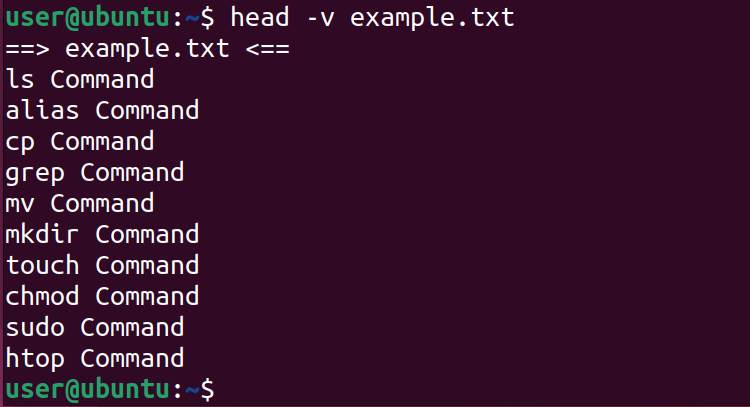
Чтобы подавить заголовки при множественных файлах, используйте -q:
head -q example.txt test.txt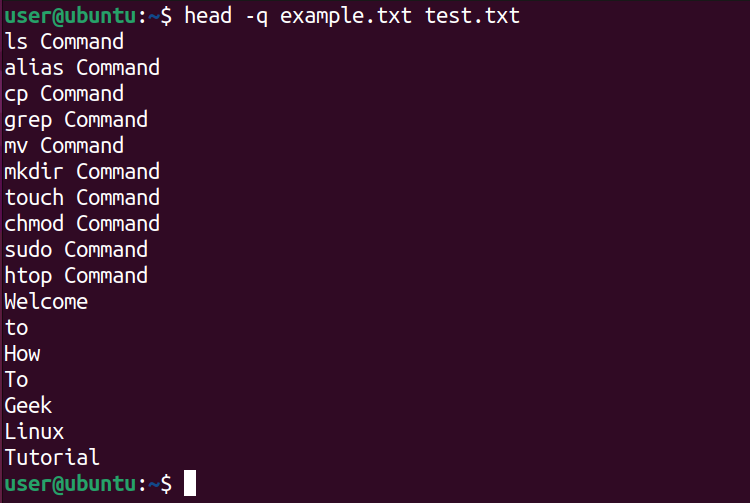
Вывод нескольких файлов и порядок
head принимает несколько файлов как аргументы и выводит их по очереди. Порядок вывода соответствует порядку аргументов в командной строке:
head file1.txt file2.txtЕсли указать -q, имена файлов не печатаются.
Использование head с другими командами
head интегрируется с большинством текстовых утилит в Unix-пайплайнах:
- Поиск строк сверху файла
head example.txt | grep ch- Подсчёт строк, слов и байтов у верхней части файла
head example.txt | wc- Получение диапазона строк (например, с 5-й по 11-ю):
head -n 10 example.txt | tail -n 5Этот приём сначала берёт первые 10 строк, затем tail оставляет последние 5 из них, что соответствует строкам 6–10 исходного файла (если считать с 1). Для точного вывода с 5-й по 11-ю строку используйте техники с awk или sed:
sed -n '5,11p' example.txtИли с помощью awk:
awk 'NR>=5 && NR<=11' example.txt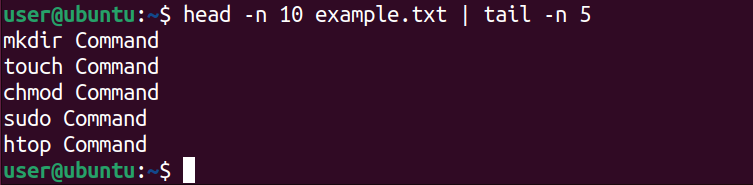
Кодировка, байты и символы: что важно помнить
- В ASCII один символ = 1 байт. В UTF-8 символ может занимать от 1 до 4 байтов. Опция
-cсчитает байты, а не символы. - Если файл в UTF-8 и вы используете
head -c N, вы можете обрезать многобайтовый символ посередине, что приведёт к некорректному выводу. - Если нужно вырезать N символов в многобайтовой кодировке, используйте инструменты, работающие с символами (например, awk при корректной локали) или преобразуйте кодировку.
Пример проверки локали:
env | grep -i langЧтобы гарантировать корректную обработку UTF-8, убедитесь, что LC_ALL или LANG установлены в UTF-8.
Когда head не подойдёт: ограничения и примеры ошибок
- Если нужно изменить середину файла или удалить диапазон строк, head не поможет — используйте sed или awk.
- Для больших двоичных файлов
-cможет быть полезен, но будьте осторожны с текстовыми редакторами, которые ожидают корректной кодировки. - head не индексирует файл; для быстрого доступа к произвольной позиции лучше применять инструменты, поддерживающие смещение (например, dd с seek/skip).
Пример, когда -c ломает UTF-8:
head -c 10 utf8file.txtЕсли 10-й байт оказался в середине символа, вывод может содержать «битые» символы.
Альтернативы и расширенные приёмы
- sed — гибко выбирает диапазоны строк и выполняет замены.
- awk — мощный для выборки по полям и более сложной логики.
- dd — подходит для побайтного доступа с более тонким управлением (skip/seek).
- perl — полезен для однострочных преобразований и работы с многобайтовыми символами.
Примеры:
- sed: вывести 5–11 строк:
sed -n '5,11p' example.txt- dd: вывести первые 512 байтов (бинарный режим):
dd if=example.bin bs=512 count=1 2>/dev/null | hexdump -C- awk: первые символы каждой строки без проблем с локалью (если LC установлен):
awk '{print substr($0,1,1)}' example.txt | headРуководство администратора: как использовать head для мониторинга
SOP для быстрого инспектирования логов:
- Подключитесь к серверу по SSH.
- Определите файл лога и его формат.
- Для быстрого просмотра версий последних записей используйте tail. Чтобы проверить начало файла (например, заголовок), используйте head.
- Для выборочного просмотра первых N записей лога:
head -n 50 /var/log/example.log- Чтобы проверить структуру записей — комбинируйте с cut/awk:
head /var/log/example.log | awk '{print $1,$2,$3}' | uniq -c- Если лог содержит PII, не выводите его в публичный чат и фильтруйте поля.
Критерии приёма
- Вывод команды корректно показывает ожидаемое число строк/байтов.
- Комбинации с пайпами не теряют структуру полей (проверить на тестовом файле).
- Нет утечек чувствительных данных при публикации результатов.
Рольные чек-листы
Для системного администратора:
- Проверить локаль (UTF-8).
- Использовать head для быстрого осмотра больших логов.
- При необходимости объединять head с grep/awk для поиска шаблонов.
Для разработчика:
- Использовать head в тестах для проверки начала выходных файлов.
- Комбинировать с diff для сравнения начальных частей файлов.
Для аналитика данных:
- Использовать head для выборки первых строк датасетов перед загрузкой.
- Проверять заголовки столбцов и формат данных.
Тесты и критерии приёмки
- Команда head без опций выводит 10 строк: запустить на файле >10 строк.
- head -n N выводит ровно N строк: тестовые файлы с известным количеством строк.
- head -c N на ASCII-файле выводит N байтов.
- head -c N на UTF-8 проверяет, что не происходит аварийной обрезки символов (или проверяет корректность ожидаемого результата).
Для автоматизированных тестов используйте assert на количество строк/байтов в выводе.
Совместимость, версия и миграция
- head — часть пакета coreutils в большинстве дистрибутивов Linux.
- Команды и опции совместимы между GNU coreutils и большинством Unix-подобных систем, но поведение опций может слегка отличаться в старых системах.
- Для POSIX-совместимости придерживайтесь основных опций: -n и -c.
Безопасность и приватность
- Логи часто содержат PII (имена, адреса, номера). При выводе частей логов используйте фильтрацию и маскирование.
- Не отправляйте выводы команд с полными логами в публичные чаты и тикеты без редактирования.
Важно: если файл содержит секреты, убедитесь, что доступ к нему ограничен по правам.
Когда лучше использовать tail или другие инструменты
- tail -f — для мониторинга добавляемых записей в режиме реального времени.
- Для обработки больших объёмов данных и сложных фильтров используйте awk или специализированные инструменты логирования (journalctl, rsyslog, ELK).
Набор практических примеров и приёмов (cheat sheet)
- Показать первые 20 строк:
head -n 20 file.txt- Показать первые 100 байтов:
head -c 100 file.txt- Показать первые 10 строк нескольких файлов без заголовков:
head -q file1 file2 file3- Показать первые символы первых 10 строк:
head file.txt | cut -c 1-3- Получить строки 5–11 (через head+tail):
head -n 11 file.txt | tail -n 7- Проверка кодировки перед байтовыми операциями:
file -i file.txtФакто-бокс: ключевые числа и поведение
- По умолчанию head выводит 10 строк.
- Опции: -n (строки), -c (байты), -v (заголовок), -q (без заголовков), -z (NUL-терминатор).
- Отрицательные значения для -n и -c означают «всё, кроме последних N».
Краткая сводка
Команда head — лёгкий и быстрый инструмент для получения начала файла. Она проста, но гибка в сочетании с другими утилитами Unix. Помните про различия между байтами и символами и фильтруйте конфиденциальные данные перед публикацией.
Короткая версия для анонса (100–200 слов)
Команда head в Linux позволяет быстро просмотреть начало текстового файла или потока данных. По умолчанию head выводит первые 10 строк; опции -n и -c дают контроль над количеством строк или байтов. Утилита часто используется вместе с grep, awk, cut и tail для выборочного анализа логов и других файлов. При работе с UTF-8 помните о многобайтовых символах: -c считает байты, а не символы. Для мониторинга конца файла лучше подходит tail, а для более сложных трансформаций — sed или awk. Используйте head в сценариях проверки заголовков файлов, предварительного осмотра больших данных и быстрой диагностики.
Социальный предпросмотр: короткое описание и заголовок для ссылок в мессенджерах включены в метаданные SEO.
Похожие материалы

RDP: полный гид по настройке и безопасности

Android как клавиатура и трекпад для Windows

Советы и приёмы для работы с PDF

Calibration в Lightroom Classic: как и когда использовать

Отключить Siri Suggestions на iPhone
