Пайплайн агрегации в MongoDB — руководство

Краткое определение
Агрегация в MongoDB — это многоэтапный конвейер обработки документов, где каждый этап (стадия) принимает входные документы, преобразует их и передаёт результат следующей стадии. Простая метафора: ленточный конвейер, где на каждой станции выполняется своё действие (фильтр, группировка, сортировка и т.д.).
Важно: агрегация удобна для вычислений на уровне БД и сокращает количество передаваемых клиенту промежуточных данных.
Что такое aggregation pipeline и как он работает
Пайплайн агрегации — последовательность стадий. Каждая стадия использует оператор MongoDB (например, $match, $group, $sort) и преобразует поток документов. Результат одной стадии автоматически передаётся в следующую. Это позволяет комбинировать несколько операций в одном запросе и избежать лишних проходов данных.
Пример потока: сначала отфильтровать записи ($match), затем развернуть массив ($unwind), сгруппировать по ключу ($group), отсортировать ($sort) и сохранить только нужные поля ($project).
Основные стадии пайплайна
Ниже описаны самые часто используемые стадии, их назначение и практические советы.
$match
Используется для фильтрации входных документов. По сути это тот же фильтр, что и в find(), и его стоит размещать в начале пайплайна, чтобы сократить объём данных для последующей обработки.
Пример: отобрать документы, где Sold >= 5.
$group
Группирует документы по ключу и вычисляет агрегаты (суммы, среднее, минимум, максимум).
Пример: рассчитать суммарные продажи и максимальную сумму по секциям на основе примера sales.
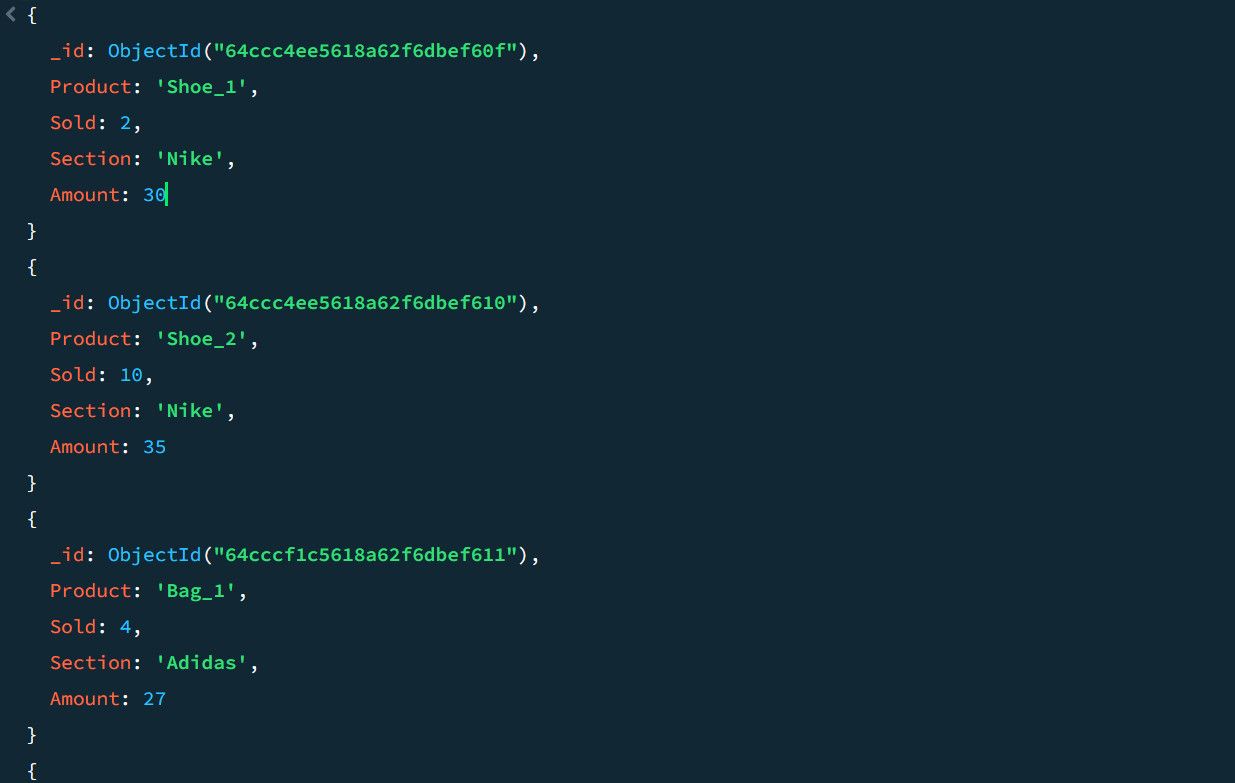
Пример стадии:
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
} Пояснение: _id: $Section группирует по полю Section; $sum, $max и другие формируют новые вычисляемые поля.
$skip
Пропускает указанное количество документов результата. Часто используется вместе с $limit для пагинации или для пропуска заголовков после сортировки.
Пример:
...,
{
$skip: 1
}, $sort
Сортирует документы по указанным полям. Стадия требует ресурсов; если сортировка происходит до значительной фильтрации, стоит убедиться в наличии индексa или переместить $match перед $sort.
Пример:
...,
{
$sort: {top_sales: -1}
}, $limit
Ограничивает количество документов в результате. Используйте, чтобы вернуть только топ-N записей.
Пример:
...,
{
$sort: {top_sales: -1}
},
{"$limit": 1} $project
Формирует выходной документ: может включать/исключать поля, переименовывать ключи и выполнять вычисления для новых полей.
Пример: привести итоговый документ в понятный вид.
...,
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
} $unwind
Разворачивает массив-поле в серии документов — по одному документу на каждый элемент массива. Полезно для подсчёта метрик по отдельным товарам в заказе.
Пример на коллекции Orders:
db.Orders.aggregate(
[
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},
{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",
}
}
]) Результат покажет суммарный доход по каждому продукту.

Полный пример пайплайна
Ниже агрегируем пример sales с фильтрацией, группировкой, сортировкой и проекцией:
db.sales.aggregate([
{
"$match": {
"Sold": { "$gte": 5 }
}
},
{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}
},
{
"$sort": { "top_sales": -1 }
},
{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
]) 
Сравнение: пайплайн агрегации и MapReduce
До MongoDB 5.0 MapReduce часто использовали для агрегирования, но MapReduce требует написания map и reduce функций и обычно выполняется медленнее. Пайплайн агрегации встроен в MongoDB, оптимизирован движком и предлагает выразительные операторы. Если вы используете MapReduce для простых агрегатов — переход на пайплайн почти всегда даёт выигрыш в производительности и простоте поддержки.
Важно: MapReduce остаётся полезным для крайне специфичных задач трансформации при наличии сложной логики на стороне сервера, но такие случаи редки.
Когда пайплайн может не подойти
- Если вычисления требуют сторонней библиотеки или среды выполнения (например, сложные ML-алгоритмы), лучше выгрузить данные и обрабатывать вне БД.
- Если объём данных в одном этапе превышает доступную память для операций сортировки или группировки без использования механизма diskUseAllowed, потребуется переработать запрос или добавить индексы.
- Если нужна межсерверная агрегация (скип-паттерн) между разными СУБД — тогда используют ETL-инструменты.
Альтернативные подходы
- MapReduce — для редких случаев кастомных функций на стороне сервера.
- Клиентская агрегация (выборка и вычисления на приложении) — кормить БД меньшими выборками, если вычисления сложны и специфичны.
- Инструменты ETL / аналитические движки (Spark, Flink) — если необходима масштабируемая обработка больших наборов данных вне MongoDB.
Практическое руководство по проектированию пайплайна (мини-методология)
- Сформулируйте цель запроса: какой итоговой документ вы хотите получить? (например, топ-5 продуктов по выручке за квартал).
- Минимизируйте объём данных: сначала $match и, при возможности, $project для исключения ненужных полей.
- Разворачивайте массивы только при необходимости ($unwind).
- Выполняйте группировку ($group) и агрегаты после фильтрации, чтобы сократить вычисления.
- Сортируйте только то, что нужно, и применяйте $limit после $sort.
- На финальном этапе используйте $project, чтобы привести поля в клиентский формат.
- Тестируйте и профилируйте.
Отладка и SOP для проблем с производительностью
Важно: для любой медленной агрегации используйте explain() и профайлинг.
Шаги отладки:
- Выполните .explain(“executionStats”) для агрегированного запроса.
- Проверьте, какие стадии занимают больше всего времени и трафика данных.
- Убедитесь, что ранний $match использует индекс (сравните планы с помощью explain).
- Если стадия $sort или $group превышает память — используйте allowDiskUse: true или пересмотрите архитектуру запроса.
- Разбейте сложный пайплайн на несколько шагов в разработке, добавляя временные проверки между стадиями.
Пример запуска с разрешением на использование диска:
db.collection.aggregate(pipeline, { allowDiskUse: true })Примечание: allowDiskUse помогает при больших группировках, но увеличивает I/O, поэтому рассматривайте индексирование и предварительную фильтрацию как первый шаг.
Рекомендации по индексированию и оптимизации
- Помещайте $match как можно ближе к началу пайплайна, чтобы сокращать обрабатываемые документы.
- Если $match использует поля из индекса, MongoDB может эффективно фильтровать данные до их загрузки в пайплайн.
- Индексы на полях, участвующих в $sort и $group (особенно в части ключа группировки), могут снизить нагрузку.
- Избегайте разворачивания очень больших массивов без дополнительной фильтрации.
- Используйте $facet для параллельных подсчётов по одному набору данных, но учитывайте, что $facet копирует входные документы для каждого фасета.
Важно: индексирование помогает на этапе выбора и сортировки; общие вычисления (агрегаты вида $sum/$avg) всё равно выполняются внутри агрегации.
Чек-листы по ролям
Разработчик:
- Сформулировать точный формат выходных документов.
- Разбить пайплайн на логические стадии.
- Протестировать пайплайн на подвыборке данных.
DBA / Инфраструктура:
- Проверить планы выполнения и использование индексов.
- Настроить мониторинг и лимиты памяти для операций агрегации.
- Оценить необходимость allowDiskUse и влияния на I/O.
Аналитик данных:
- Убедиться, что агрегаты соответствуют бизнес-метрикам.
- Подготовить тестовые сценарии и ожидаемые значения.
Критерии приёмки
- Результат содержит нужные поля и формат согласно ТЗ.
- Время выполнения запроса соответствует SLA/ожиданиям (или подтверждён поведенческий план оптимизации).
- План выполнения использует индексы для фильтрации входных данных (если применимо).
- Отсутствие непредвиденного роста использования памяти (или использовано allowDiskUse с обоснованием).
Decision flowchart (Mermaid)
flowchart TD
A[Есть ли сложная серверная логика?] -->|Да| B[Подумать о MapReduce или внешней обработке]
A -->|Нет| C[Можно ли отфильтровать данные в БД?]
C -->|Да| D[Добавить $match в начало]
C -->|Нет| E[Оценить клиентскую обработку]
D --> F[Планируем $group и $sort]
F --> G[Проверить индексы и explain]
G --> H{Исполнение в лимитах?}
H -->|Да| I[Развернуть в прод]
H -->|Нет| J[Оптимизировать: индексы / allowDiskUse / пересмотреть запрос]Тестовые случаи и примеры приёмки
- Тест 1: Пайплайн возвращает корректный суммарный объём продаж для известной подвыборки (проверить на контрольных данных).
- Тест 2: При применении $limit=1 результат соответствует ожидаемому топ-элементу после $sort.
- Тест 3: Для заказов с массивом items после $unwind суммарный revenue совпадает со сводным расчётом вне БД.
- Тест 4: План выполнения использует индексы для $match (если индекс задан).
Безопасность и приватность
- Не выполняйте агрегации, раскрывающие PII (персональные данные) без соответствующей маскировки.
- Оценивайте объём данных, который выгружается в приложении — минимизируйте экспозицию.
Миграция с MapReduce на пайплайн
Шаги:
- Определить map и reduce функции и их эквиваленты в стадиях $project/$group/$addFields и т.д.
- Перенести вычисления в пайплайн по шагам: сначала фильтрация, затем преобразования, затем группировка.
- Сравнить результаты и выполнить профилирование.
Полезно: замена MapReduce на агрегацию часто сокращает количество кода и повышает производительность за счёт встроенных оптимизаций.
Сводка и рекомендации
- Используйте пайплайн агрегации для большинства задач агрегации в MongoDB.
- Проектируйте пайплайн, начиная с фильтрации и уменьшения объёма данных.
- Профилируйте и анализируйте планы выполнения; применяйте индексы и, при необходимости, allowDiskUse.
- В редких случаях, когда нужна внешняя среда выполнения, рассматривайте MapReduce или ETL-инструменты.
Итог: пайплайн агрегации — гибкий и производительный инструмент для аналитики и трансформации данных прямо в MongoDB. Систематический подход к проектированию и проверке позволит создать устойчивые и быстрые запросы.
Примечание
Если нужно, я могу адаптировать это руководство под конкретную схему коллекции, подготовить готовый пайплайн для ваших данных или помочь с explain() и планом выполнения.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
