Как извлечь текст из изображения в Chrome
Краткое введение
Обычно для извлечения текста из изображения используют OCR (оптическое распознавание символов). Начиная с Chrome 76, появился способ использовать встроенную экспериментальную функцию браузера — Shape Detection API — чтобы получать текст из изображений без дополнительного ПО. Эта функция использует аппаратное ускорение на устройстве, где она запущена, и может работать быстрее и экономнее по ресурсам.
Что такое Shape Detection API
Shape Detection API — это набор веб-интерфейсов, которые позволяют браузеру обнаруживать штрих‑коды (включая QR), лица и текст в изображениях с помощью аппаратных возможностей устройства. Коротко: Text Detection = попытка найти текстовые блоки на изображении и вернуть их в виде структурированных данных.
Важно: это экспериментальная возможность. Её реализация и поведение зависят от устройства, драйверов и версии Chrome.
Кому и когда это полезно
- Быстрый перенос печатного текста из скриншота в заметку без установки OCR-приложений.
- Локальная обработка конфиденциальных изображений, когда не хочется отправлять данные в облако.
- Быстрая проверка качества распознавания при разработке фич, связанных с изображениями.
Когда это не сработает (примеры отказов)
- Нечёткие, смазанные или очень маленькие шрифты.
- Рукописный текст (ручное письмо распознаётся плохо или не распознаётся вовсе).
- Сложные макеты, наложенный текст поверх насыщенного фона.
- Языки/шрифты без поддержки в текущей реализации API.
Шаг за шагом: включение и использование в Chrome
- Откройте Chrome.
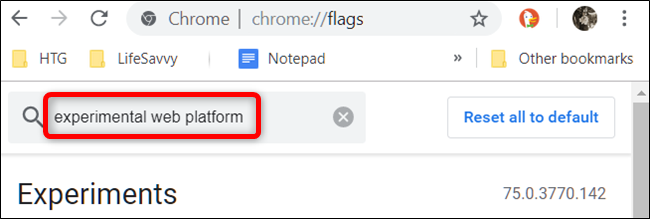
- В адресной строке введите:
chrome://flags- В строке поиска флагов введите “Experimental web platform”. Либо вставьте прямо:
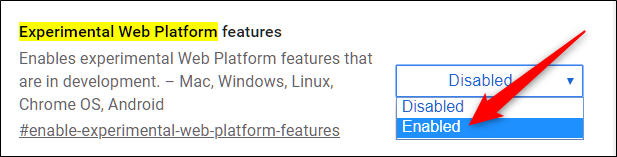
chrome://flags/#enable-experimental-web-platform-features- Рядом с флагом «Experimental Web Platform» выберите “Enabled” (Включено).
- Нажмите синюю кнопку «Relaunch Now» (Перезапустить сейчас) внизу, чтобы перезапустить Chrome и применить изменения.
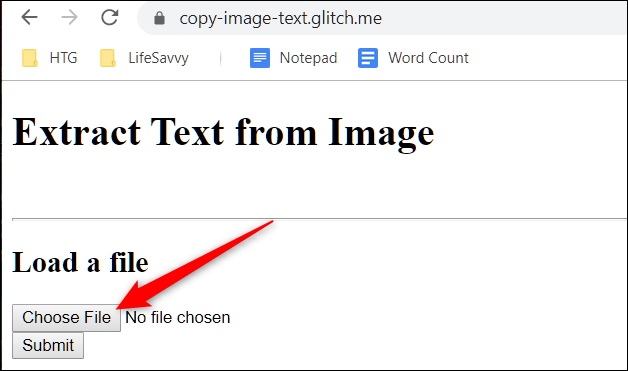
Откройте сайт https://copy-image-text.glitch.me/ — он выполняет распознавание локально и может работать офлайн после первой загрузки ресурсов.
Нажмите «Choose File» (Выбрать файл) и откройте изображение с текстом.
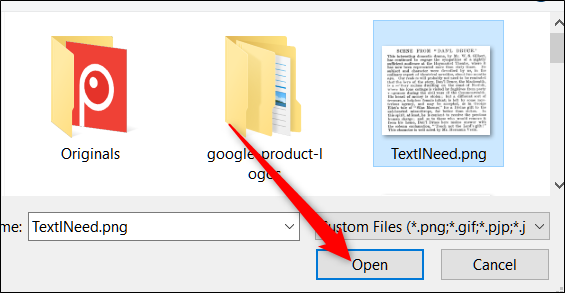
- Выберите файл и нажмите «Open» в системном диалоге.
- После загрузки нажмите «Submit» — страница перезагрузится с результатами распознавания.
- Скопируйте распознанный текст с веб‑страницы и вставьте в текстовый редактор.
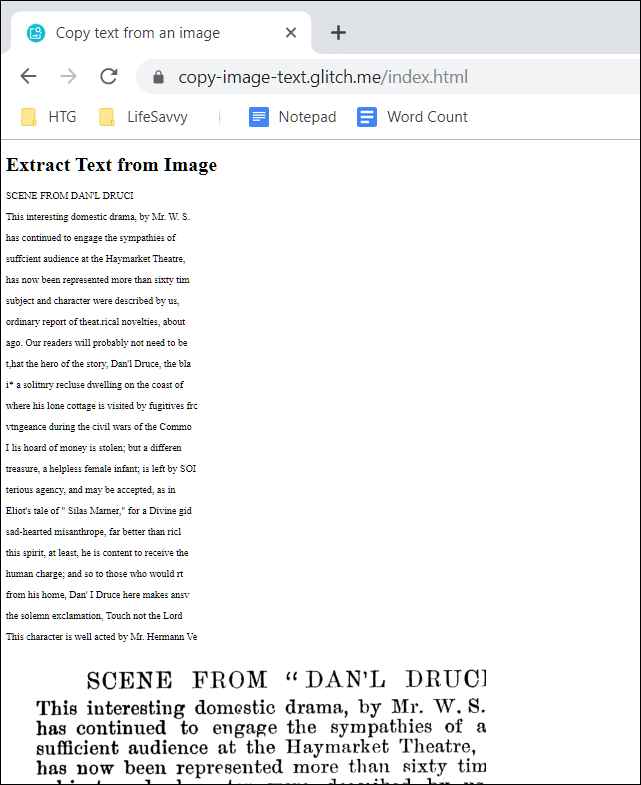
Важно: сайт работает локально после кеширования, но сам механизм распознавания остаётся экспериментальным. На некоторых изображениях результат может быть неполным или ошибочным.
Пример кода (базовая проверка поддержки и вызов детектора текста)
Этот фрагмент показывает простую проверку наличия TextDetector и вызов detect на ImageBitmap. Это минимальный пример, не учитывающий получение ImageBitmap из или файла.
if ('TextDetector' in window) {
const detector = new TextDetector();
// imageBitmap — предварительно созданный ImageBitmap из файла или canvas
detector.detect(imageBitmap).then(detections => {
console.log('detections', detections);
}).catch(err => console.error(err));
} else {
console.log('TextDetector не поддерживается в этом окружении');
}Альтернативные подходы
- Локальные OCR-библиотеки: Tesseract (в виде npm-пакета или нативных сборок). Подходит для пакетной обработки и кастомных настроек.
- Облачные OCR-сервисы: Google Cloud Vision, AWS Textract, Azure Cognitive Services. Надёжны, но требуют отправки изображений в облако и могут стоить денег.
- Мобильные инструменты: Google Lens, встроенный OCR в Google Photos, приложения типа Text Scanner. Удобно для смартфона.
- Десктоп: OneNote и некоторые PDF-конвертеры умеют извлекать текст из изображений.
Контроль качества и критерии приёмки
- Точность извлечения: не менее 95% символов для печатного текста стандартного размера (для приемочных тестов использовать заранее размеченные эталонные изображения).
- Устойчивость: корректный ответ для 10 разных изображений со стандартным контрастом.
- Безопасность: данные не отправляются на внешние сервисы (если это требование).
Тестовые кейсы:
- Чёткий печатный текст на белом фоне.
- Нечёткий / размытый текст.
- Текст на разноцветном фоне.
- Рукописный текст.
- Несколько строк и столбцов текста.
Чек-листы по ролям
- Разработчик:
- Проверить поддержку TextDetector в целевых браузерах.
- Добавить graceful fallback (сообщение или альтернативный OCR).
- Обработать ошибки и тайм‑аута.
- Продвинутый пользователь:
- Включить флаг, перезапустить браузер, протестировать на нескольких изображениях.
- Сохранять резервные копии оригиналов.
- Специалист по конфиденциальности:
- Убедиться, что сайт/приложение не отправляет изображения в облако.
- Проверить кеширование и локальное хранение данных.
Резюме и рекомендации
- Shape Detection API в Chrome — быстрый и удобный способ извлечения текста без установки OCR‑ПО. Подходит для быстрых задач и экспериментов.
- Для критичных и массовых задач используйте проверенные OCR-решения (Tesseract или облачные сервисы) и проверяйте качество на контрольных наборах изображений.
Важно: поскольку функция экспериментальная, поведение может меняться с релизами Chrome. Оставляйте обратные пути и альтернативы в пользовательском интерфейсе.
Частые вопросы
Q: Нужно ли подключение к интернету для работы copy-image-text?
A: Первый заход может загрузить ресурсы, но распознавание выполняется локально; сайт может работать офлайн после кеширования.
Q: Поддерживает ли API рукописный текст?
A: Как правило, рукописный текст распознаётся хуже или не поддерживается; для рукописного распознавания лучше использовать специализированные сервисы.
Q: Это безопасно для конфиденциальных документов?
A: Если вы используете локальное распознавание (как на copy-image-text после кеша) и не отправляете изображения на серверы, это безопаснее, чем облачные сервисы. Тем не менее, проверяйте сетевую активность и политику сайта.
Ключевые выводы:
- Включите флаг «Experimental Web Platform», перезапустите Chrome и используйте copy-image-text.glitch.me.
- Метод быстрый, локальный и экспериментальный; для производственных задач выбирайте устойчивые OCR-решения.
- Тестируйте на нескольких образцах и подготовьте откатный план.
Похожие материалы

RDP: полный гид по настройке и безопасности

Android как клавиатура и трекпад для Windows

Советы и приёмы для работы с PDF

Calibration в Lightroom Classic: как и когда использовать

Отключить Siri Suggestions на iPhone
