Парсинг Reddit в Bash: curl + jq
Быстрые ссылки
- Установка curl и jq
- Получение JSON с Reddit
- Извлечение полей из JSON
- Готовый скрипт
- Советы по расширению и безопасности
Введение
Reddit предоставляет JSON‑фиды для каждого субреддита. В этой статье вы узнаете, как написать Bash‑скрипт, который скачивает JSON‑список постов и извлекает из него нужные поля (title, url, permalink). Этот подход удобен для быстрой автоматизации, агрегации заголовков и интеграции с другими инструментами командной строки.
Важно: любой доступ к публичным API следует делать аккуратно — используйте корректный User‑Agent и соблюдайте добрую практику с учётом ограничений по частоте запросов.
Установка curl и jq
Для работы нужны две утилиты: curl для скачивания данных и jq для разбора JSON. На Debian/Ubuntu и производных установите их так:
sudo apt-get install curl jqНа других дистрибутивах используйте пакетный менеджер вашей системы (dnf, pacman, zypper и т.д.).
Получение JSON с Reddit
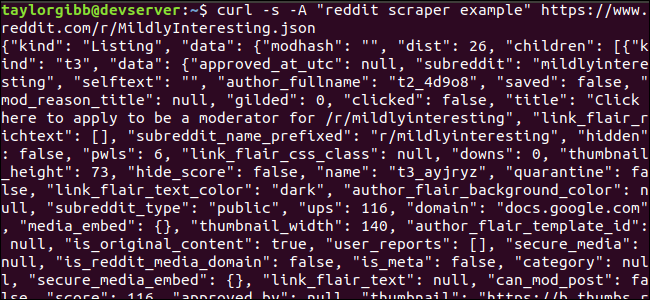
Пример запроса для получения последних постов из /r/MildlyInteresting:
curl -s -A "reddit scraper example" https://www.reddit.com/r/MildlyInteresting.jsonПояснения к опциям:
-s— silent: отключает прогресс и лишние выводы curl.-A "reddit scraper example"— устанавливает пользовательский User‑Agent. Reddit использует строку User‑Agent при разграничении лимитов и при отладке. Указывайте понятную строку, которая описывает ваше приложение.
Вывод обычно большой (JSON). Примерный снимок экрана ниже показывает формат ответа — корневой объект с полями kind и data, где data.children — массив постов.
Извлечение полей из JSON с помощью jq
Мы хотим получить только три поля: title, url и permalink. jq понимает структуру JSON и позволяет выполнить точную выборку и трансформацию данных.
Сначала просто отформатируем и раскрасим JSON для удобочитаемости:
curl -s -A "reddit scraper example" https://www.reddit.com/r/MildlyInteresting.json | jq .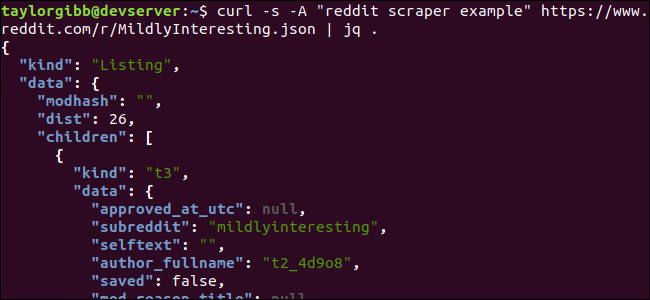
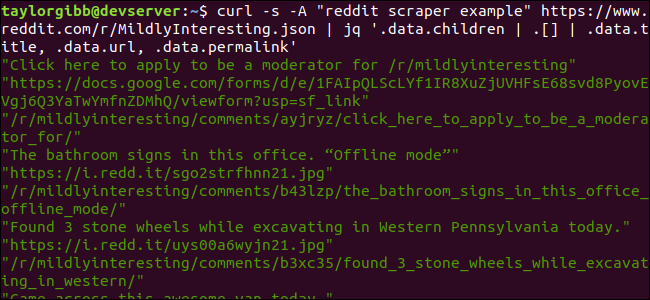
Структура запроса для выборки трёх полей:
curl -s -A "reddit scraper example" https://www.reddit.com/r/MildlyInteresting.json | jq '.data.children | .[] | .data.title, .data.url, .data.permalink'Разберём выражение jq:
.data.children— переходим к массиву постов.| .[]— итерируемся по каждому элементу массива.| .data.title, .data.url, .data.permalink— для каждого элемента извлекаем три поля.
Вывод будет выглядеть как последовательность строк: title, затем url, затем permalink для каждого поста.
Готовый скрипт
Ниже — полный скрипт, объединяющий всё вместе и записывающий результат в таб‑разделённый файл. Скопируйте в файл scrape-reddit.sh.
#!/bin/bash
if [ -z "$1" ]
then
echo "Please specify a subreddit"
exit 1
fi
SUBREDDIT=$1
NOW=$(date +"%m_%d_%y-%H_%M")
OUTPUT_FILE="${SUBREDDIT}_${NOW}.txt"
curl -s -A "bash-scrape-topics" https://www.reddit.com/r/${SUBREDDIT}.json | \
jq '.data.children | .[] | .data.title, .data.url, .data.permalink' | \
while read -r TITLE; do
read -r URL
read -r PERMALINK
echo -e "${TITLE}\t${URL}\t${PERMALINK}" | tr --delete \" >> ${OUTPUT_FILE}
doneДетали работы скрипта:
- Скрипт проверяет, передано ли имя субреддита, и завершается с ошибкой, если нет.
- Формирует имя файла с временной меткой:
_ .txt - Выполняет запрос curl и передаёт результат в jq, который выводит три строки на каждый пост.
- В цикле while читаются три строки (TITLE, URL, PERMALINK), склеиваются через табуляцию и записываются в файл. Команда tr удаляет кавычки.
Сделайте скрипт исполняемым и запустите его:
chmod u+x scrape-reddit.sh
./scrape-reddit.sh MildlyInterestingФайл будет создан в текущем каталоге. Пример вывода в терминале показан ниже.
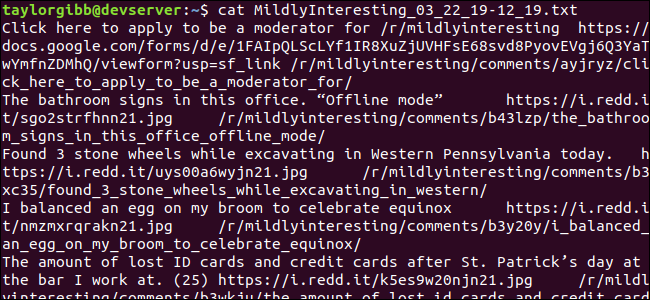
Каждая строка содержит три поля, разделённых табуляцией.
Расширение и практические советы
Полезные флаги и уточнения
- Чтобы получать только топ‑посты за день/неделю/месяц, используйте параметры запроса, например
https://www.reddit.com/r/./top.json?t=day - Если вы хотите ограничить количество результатов, добавьте
?limit=50. - Всегда используйте понятный и уникальный User‑Agent, чтобы Reddit мог отличить ваш инструмент.
Обработка специальных символов
Заголовки могут содержать табы, переносы строк или кавычки. В примере мы удаляем двойные кавычки и используем табы как разделитель. Для более надёжной сериализации используйте формат CSV с корректной экранировкой или JSONL.
Альтернативные подходы
- Python + requests + praw (официальные/неофициальные библиотеки) — для более сложной логики и аутентификации.
- Node.js + fetch + reddit API wrappers — если вы пишете приложение на JS.
- Использование официального Reddit API и OAuth — если нужны привилегированные методы и большие объёмы запросов.
Безопасность и стабильность
Примечание: при массовом сканировании соблюдайте этику и правила платформы.
Рекомендации:
- Не запускайте скрипт в tight loop без задержек; добавьте sleep и экспоненциальное ожидание при ошибках.
- Логируйте ошибки HTTP и ответы с кодами 4xx/5xx. Обрабатывайте 429 (Too Many Requests).
- Если требуется больший объём данных, используйте авторизацию через OAuth и официальные конечные точки API.
Конфигурации и чек-лист перед запуском
Роль — Что проверить:
- Разработчик: проверить зависимые утилиты (curl, jq) и права на запись файла.
- Операции: убедиться, что скрипт не запущен с частым интервалом и не нарушает политику использования.
- Безопасность: не храните токены в коде, используйте переменные окружения.
Чек‑лист перед запуском:
- curl установлен
- jq установлен
- Проверен User‑Agent
- Путь для вывода доступен для записи
- Поняты лимиты запросов
Когда этот подход не подходит
- Если вам нужна авторизация или доступ к приватным данным, требуется OAuth и официальная API с клиентскими ключами.
- Для масштабных задач с высокой частотой запросов стоит перейти на бэкенд‑сервис с очередями и кешем.
- Для сложных фильтров и агрегации лучше использовать язык программирования (Python/Node) с полноценными SDK.
Приёмка и тесты
Критерии приёмки
- Скрипт создаёт файл с именем в формате
_ .txt - Каждая строка файла содержит три поля: title, url, permalink, разделённые табуляцией.
- Скрипт корректно завершается с кодом 1 при отсутствии аргумента.
- Скрипт не содержит видимых ошибок shell‑парсинга и работает на POSIX‑совместимом Bash.
Минимальные тесты
- Запуск с реальным субреддитом — файл создан и содержит строки.
- Запуск без аргументов — выводится сообщение об ошибке и код возврата 1.
- Обработка заголовков с кавычками — кавычки удаляются.
Шаблон быстрого cheat sheet
Команды для быстрого старта:
- Форматированный просмотр JSON:
curl -s -A "app" https://www.reddit.com/r/.json | jq . - Выборка полей:
jq '.data.children | .[] | .data.title, .data.url, .data.permalink' - Ограничение:
https://www.reddit.com/r/.json?limit=25 - Топ за день:
https://www.reddit.com/r//top.json?t=day
Паттерны мышления и эвристики
- Думайте о JSON как о дереве: сперва добираетесь до нужного узла (
.data.children), затем итерируете элементы (.[]) и берёте поля. - Минимизируйте обработку строк в shell — отдавайте преобразования инструментам, которые знают структуру данных (jq, csvkit).
- Разделяйте этапы: скачивание → парсинг → преобразование → запись.
Миграция и совместимость
- jq доступен на большинстве Unix‑систем и в пакетных менеджерах. Если вы мигрируете на macOS, установите через Homebrew:
brew install jq curl. - Для Windows подсистемы WSL подойдёт тот же скрипт; можно также использовать Git Bash или Cygwin, но поведение date и tr может отличаться.
Конфиденциальность и соответствие правилам
- Мы работаем с публичными данными, но при сохранении и дальнейшей обработке убедитесь, что не передаёте персональные данные третьим лицам.
- Если интегрируете с корпоративными системами, уточните внутренние правила хранения логов и доступа.
Подводные камни и типичные ошибки
- Неправильный User‑Agent приводит к иному лимитированию или временной блокировке.
- Отсутствие обработки HTTP ошибок — скрипт будет пытаться парсить HTML страницы с ошибкой вместо JSON.
- Прямая операция
tr --delete \"удаляет все двойные кавычки во входящих строках, что может менять смысл заголовков — думайте, нужен ли вам CSV с экранированием.
Краткое резюме
- curl + jq — быстрый и мощный инструмент для вытаскивания структурированных данных из Reddit.
- Скрипт сохраняет три ключевых поля в таб‑разделённый файл для последующей автоматизированной обработки.
- Для больших объёмов и приватного доступа рассматривайте официальный API и OAuth.
Спасибо за чтение. Удачного хакерства и аккуратного использования API!
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
