Безопасное чтение файла построчно в Bash
Быстрые ссылки
- Файлы, текст и идиомы
- Чтение строк из файла: однострочный пример
- Чтение строк из файла в скрипте
- Передача строки в функцию
- Полезные строительные блоки и рекомендации
Файлы, текст и идиомы
В каждом языке программирования есть набор идиом — простых и надёжных приёмов для повседневных задач. Идиома для чтения файла построчно — это тот строительный блок, который пригодится в большинстве скриптов: логах, конфигурациях, генерации задач и т. д.
Идиома не обязана быть уникальной для языка. Главное — она должна быть понятной, надёжной и предсказуемой. Когда вы знаете стандартный приём, вы быстрее понимаете чужой код и шьёте собственные решения.
Определение: Идиома — короткий, повторяемый способ выполнить типовую задачу (например, «читать файл построчно»).
Чтение строк из файла: однострочный пример
Если нужно быстро посмотреть, как работать со строками, можно использовать однострочный while в командной строке. Допустим, файл data.txt содержит список месяцев:
January
February
March
.
.
October
November
DecemberПростой однострочник:
while read line; do echo $line; done < data.txt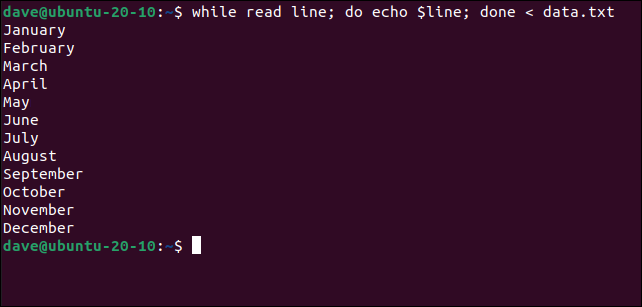
Этот цикл читает строку, передаёт управление в тело цикла, где мы просто печатаем строку. Когда строк больше нет, команда read возвращает признак неуспеха и цикл завершается.
Плюс такого подхода — простота: перенаправление файла в цикл освобождает нас от явного открытия/закрытия дескрипторов. Минус — этот однострочник негибок и не учитывает несколько важных нюансов: пробелы в начале/конце строки, обратные слэши, отсутствие перевода строки в последней строке.
Рассмотрим частый пример проблемы. Пусть в файле data2.txt к каждой строке добавлены символы \n буквально:
January\n
February\n
March\n
.
.
October\n
November\n
December\nЕсли запустить тот же однострочник:
while read line; do echo $line; done < data2.txt
Вы увидите, что обратный слэш не сохранился: Bash интерпретирует его как начало escape‑последовательности. Часто хочется, чтобы read не интерпретировал обратные слэши: они должны попасть в переменную как обычные символы.
Чтобы надёжно обрабатывать строки — особенно если планируете парсить или модифицировать их — лучше использовать скрипт с корректной конфигурацией read.
Чтение строк из файла в скрипте
Ниже — корректный и распространённый шаблон для bash‑скрипта. Сохраните как script1.sh.
#!/bin/bash
Counter=0
while IFS='' read -r LinefromFile || [[ -n "${LinefromFile}" ]]; do
((Counter++))
echo "Accessing line $Counter: ${LinefromFile}"
done < "$1"Пояснения по частям:
- IFS=’’ — внутренний разделитель полей (Internal Field Separator) выставлен в пустую строку. Это предотвращает усечение ведущих и замыкающих пробелов.
- read -r — ключ -r говорит read не обрабатывать обратный слэш как escape, то есть сохранять
\как обычный символ. - || [[ -n “${LinefromFile}” ]] — этот хит необходим для обработки последней строки в файле, если она не завершена переводом строки (не POSIX‑совместный файл). Команда read вернёт ненулевой статус, если достигнут EOF до перевода строки и не посчитает последний фрагмент успешной строкой; проверка [[ -n ]] вернёт true если в переменной есть текст, что позволит обработать последнюю строку.
- done < “$1” — редиректим файл из первого аргумента скрипта.
Сделайте скрипт исполняемым:
chmod +x script1.shЗапуск:
./script1.sh data2.txt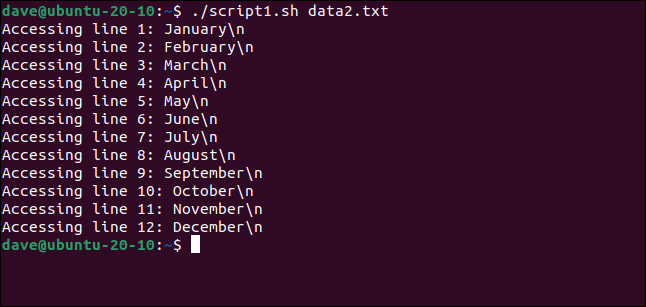
Теперь каждая строка выводится дословно, включая обратные слэши.
Важно: мы намеренно используем строгую кавычку при передаче переменной и при выводе. Не делайте echo $LinefromFile без кавычек — это приведёт к разделению по пробелам и подстановке glob‑шаблонов.
Передача строки в функцию
Часто обработка строки выполняется в отдельной функции. Это улучшает структуру кода и упрощает тестирование. Пример script2.sh:
#!/bin/bash
Counter=0
function process_line() {
echo "Processing line $Counter: $1"
}
while IFS='' read -r LinefromFile || [[ -n "${LinefromFile}" ]]; do
((Counter++))
process_line "$LinefromFile"
done < "$1"Ключевые моменты:
- Функцию нужно определить до первого вызова.
- Внутри функции аргументы доступны как $1, $2 и т. д. Мы передаём одну строку целиком, заключив её в кавычки — это защищает её от разбиения на слова.
- Переменная Counter объявлена в основном теле и видна внутри функции (она не локализована). Если хотите локальную переменную внутри функции, используйте local.
Пример входного файла data3.txt с более сложными строками:
January
February
March
.
.
October
November \nMore text "at the end of the line"
DecemberЗапуск:
./script2.sh data3.txt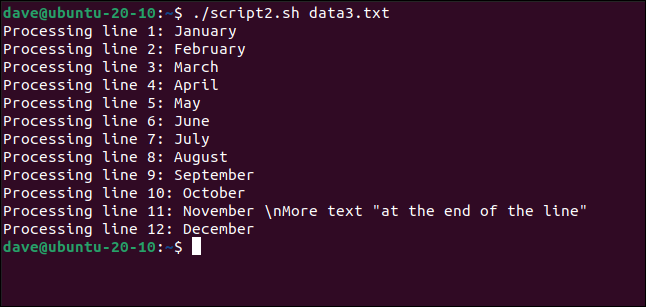
Строки корректно передаются в функцию, включая пробелы, кавычки и обратные слэши.
Полезные строительные блоки и советы
Ниже — собранные рекомендации, приёмы и альтернативы, которые пригодятся при работе с потоками, большим количеством данных и неочевидными сценариями.
Основной надёжный шаблон
Используйте этот шаблон в большинстве случаев:
while IFS= read -r line || [[ -n "$line" ]]; do
# обработка строки
done < "$file"Заметка: IFS= и IFS=’’ работают одинаково для целей read — я предпочитаю IFS= как более краткий вариант.
Общие ошибки и как их избегать
- Ошибка: while … | command — цикл в пайпе выполняется в подзадаче (subshell). Изменённые в цикле переменные не сохранятся после завершения. Решение: используйте перенаправление < file, либо shopt -s lastpipe в неинтерактивном bash, либо process substitution.
- Ошибка: echo $line без кавычек. Решение: echo “$line” или printf ‘%s ‘ “$line”.
- Ошибка: использование eval для обработки строк из файлов. Никогда не делайте этого с небезопасными источниками.
Альтернативные подходы
- readarray / mapfile (Bash‑только): считывает весь файл в массив строк.
readarray -t lines < file.txt
for i in "${!lines[@]}"; do
printf 'Line %d: %s\n' "$((i+1))" "${lines[i]}"
done- awk — когда нужна мощная обработка и парсинг полей.
awk '{ print NR ": " $0 }' file.txt- sed — для быстрой замены или фильтрации строк.
Ограничения метода read
- Нулевые байты (NUL, \x00) — встроенная команда read не может корректно обрабатывать строки, содержащие NUL. Такие файлы считаются двоичными.
- Очень длинные строки — read умеет читать большие строки, но при крайне больших размерах всё зависит от доступной памяти.
- Конец файла без перевода строки — решается трюком с || [[ -n ]].
Совместимость между шеллами
- POSIX sh: поддерживается конструкция while IFS= read -r line; do … done < file; но read -r и поведение IFS описаны в POSIX. Некоторые расширения (readarray, mapfile) — не POSIX и доступны только в bash.
- dash/ash: базовый read работает, но синтаксис функций и shopt не поддерживаются.
- ksh: обладает своей реализацией, но общие идиомы похожи.
Модель мышления (heuristic)
- Если файл маленький (< несколько MB) — readarray удобен и прост.
- Если файл огромный — читайте потоково while read, чтобы не загружать память.
- Если нужна сложная логика парсинга — используйте awk или комбинируйте awk + bash.
Безопасность и практики харднинга
- Никогда не исполняйте содержимое строк как код (eval).
- Всегда экранируйте или кавычьте переменные при выводе или передаче в команды.
- При работе с файлами из ненадёжных источников проверяйте права доступа и формат.
- Обрабатывайте CRLF (Windows) — используйте dos2unix или tr -d ‘\r’ или встроенные приёмы:
while IFS= read -r line || [[ -n "$line" ]]; do
line="${line%$'\r'}" # убираем CR в конце
done < file.txtТесты и критерии приёмки
Критерии приёмки:
- Все строки исходного файла обработаны, включая последнюю без \n.
- Сохранены ведущие и замыкающие пробелы.
- Обратные слеши (\) не интерпретируются и сохраняются.
- Скрипт не подвержен подстановке шаблонов (globbing) из содержимого строк.
Минимальные тесты:
- Файл с обычными строками (несколько строк, все с \n) — ожидаем корректный вывод.
- Файл со строкой без завершающего \n — ожидаем обработку последнего фрагмента.
- Строки с пробелами в начале/конце — пробелы должны сохраниться.
- Строки с кавычками и обратными слэшами — должны выводиться дословно.
- Файл с CRLF — строки должны нормально обрабатываться после удаления CR.
Чек‑лист для разработчика/админа
- Использован IFS= и read -r
- Обработан случай последней строки без \n
- Все переменные правильно экранированы при выводе
- Нет использования eval или небезопасной подстановки
- Тесты на CRLF/пустые строки пройдены
- Документированы предположения о формате входного файла
Шаблоны/сниппеты (cheat sheet)
- Базовый шаблон:
while IFS= read -r line || [[ -n "$line" ]]; do
printf '%s\n' "$line"
done < file.txt- Сигналы и прерывания: аккуратно закрываем ресурсы
trap 'echo "Interrupted"; exit 1' INT TERM
while IFS= read -r line || [[ -n "$line" ]]; do
# обработка
done < file.txt- Обработка больших файлов параллельно (пример с GNU parallel):
cat file.txt | parallel --pipe -L1000 my_worker_script(учтите, что использование пайпа приведёт к запуску worker в отдельных процессах — переменные в родительском shell не изменятся)
Поведенческие примеры: когда подход не подходит
- Если файл представляет собой бинарный формат с NUL‑байтами — используйте специализированные утилиты (xxd, hexdump, perl, python).
- Если требуется атомарная обработка и изменение исходного файла — пишите во временный файл и заменяйте через mv.
- Если нужна сложная потоковая фильтрация по полям и шаблонам — чаще удобнее awk.
Итог и рекомендации
Важно запомнить несколько простых правил:
- Используйте IFS= и ключ -r для read.
- Обрабатывайте последнюю строку без перевода строки с помощью || [[ -n ]].
- Кавычьте все расширения переменных при выводе или передаче в команды.
- Не используйте eval на данных из файла.
Важно
- При перенаправлении через пайп будьте внимательны: некоторые реализации создают subshell, и изменения переменных в цикле не сохранятся в родительском процессе.
Заметки
- Для простых задач cat file | while read … визуально прост, но имеет подводные камни; предпочтительнее done < file.
- Для больших файлов используйте потоковую обработку, чтобы избежать потребления памяти.
Ключевые выводы
- Шаблон while IFS= read -r line || [[ -n “$line” ]] — наиболее универсален для bash.
- Следите за кавычками и безопасностью при обработке строк.
- Используйте дополнительные инструменты (awk, readarray) там, где они более эффективны.
Сводка: этот набор идиом и шаблонов покрывает большинство практических сценариев чтения текстовых файлов в Bash. Применяйте его как строительный блок и расширяйте под конкретные требования.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
