Средний ping и стандартное отклонение в Linux — что это значит
Коротко о том, что вы видите в ping
Команда ping на Linux возвращает не только статус доставки пакетов, но и статистику по временам отклика (RTT — round‑trip time). После завершения серии запросов вы увидите строку с отчётом вида:
rtt min/avg/max/mdev = 20.123/26.819/35.456/3.456 msЗдесь значения разделены слешами в порядке: минимальное / среднее / максимальное / mdev (стандартное отклонение по популяции). Среднее — это арифметическое среднее, а mdev в реализации ping отражает стандартное отклонение по всей выборке (population std dev).
Средний ping — что это и как его читать
Средний (average, mean) — это сумма всех измеренных времен отклика, делённая на количество измерений. Это простой показатель центральной тенденции и даёт представление о «типичном» времени ответа при текущих условиях сети.
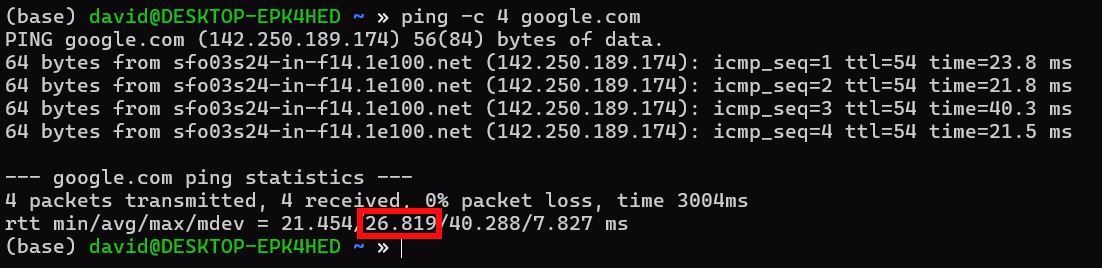
Пример: чтобы послать 4 пакета к google.com, выполните:
ping -c 4 google.comВ выводе вы увидите строку rtt, где второе значение после первого слеша — это среднее. На скриншоте ниже среднее равно 26.819 ms.
Важно: среднее чувствительно к выбросам. Один длинный отклик (например, из‑за краткого заикания сети) может заметно поднять среднее.
Стандартное отклонение (mdev) — зачем смотреть
Стандартное отклонение показывает разброс значений вокруг среднего. Чем больше mdev, тем менее предсказуемы времена отклика. В выводе ping поле называется mdev и соответствует корню из дисперсии по популяции:
- Низкое mdev: значения «собраны» около среднего.
- Высокое mdev: часто есть выбросы или сильная изменчивость (jitter).
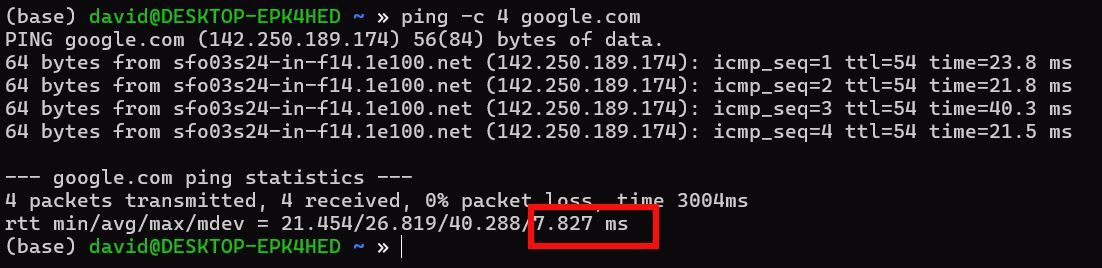
Заметьте: линейная интерпретация (например, «68% значений внутри ±1σ») работает для нормального распределения. На практике распределение ping часто скошено вправо (много быстрых пакетов и несколько медленных), поэтому стандартное отклонение и предположения нормальности нужно трактовать с осторожностью.
Когда медиана лучше среднего
Если распределение скошено (правосторонний хвост), медиана (срединное значение упорядоченной выборки) более устойчива к выбросам. Для оценки «обычного» отклика в такой ситуации используйте медиану или процентили (например, 95‑й перцентиль), а не только mean.
Больше пингов = точнее? — методология измерений и предосторожности
Теоретически большая выборка даёт более устойчивую оценку среднего (закон больших чисел), и выборка >30 часто упоминается как минимально необходимая для базовой статистики. На практике:
- Мало пакетов (например, 4–10) дают неустойчивые оценки.
- Частые запросы к одному серверу могут восприниматься как злоумышленная активность; не пересылайте сотни ICMP‑пакетов к чужим серверам без согласия.
- Для длительного мониторинга используйте инструменты типа smokeping или fping, которые настроены для агрегации и корректного интервала.
Пример аккуратного измерения (локально):
ping -c 100 -i 0.2 example.com | tee ping-results.txt-i 0.2 ставит интервал 200 мс между пакетами; 100 пакетов дают более стабильную статистику, но учитывайте политику целевого сервера.
Небольшой Python‑скрипт для подсчёта медианы и стандартного отклонения из файла с выводом ping:
# python3 parse_ping.py ping-results.txt
import sys, re, statistics
text = open(sys.argv[1]).read()
nums = [float(x) for x in re.findall(r'time=(\d+\.\d+)', text)]
print('count', len(nums))
print('mean', statistics.mean(nums))
print('median', statistics.median(nums))
print('stdev', statistics.pstdev(nums)) # population std devПочему Wi‑Fi чаще «плавает» — интерпретация и примеры
Беспроводные интерфейсы чаще показывают более высокий mdev из‑за интерференции, переключения между точками доступа, адаптивного управления скоростью и прочих факторов среды. Проводное соединение обычно стабильнее в плане задержек.
На диаграмме ниже показано типичное правостороннее скошенное распределение времен отклика по Wi‑Fi: пик находится у низких значений, но есть длинный хвост медленных ответов.
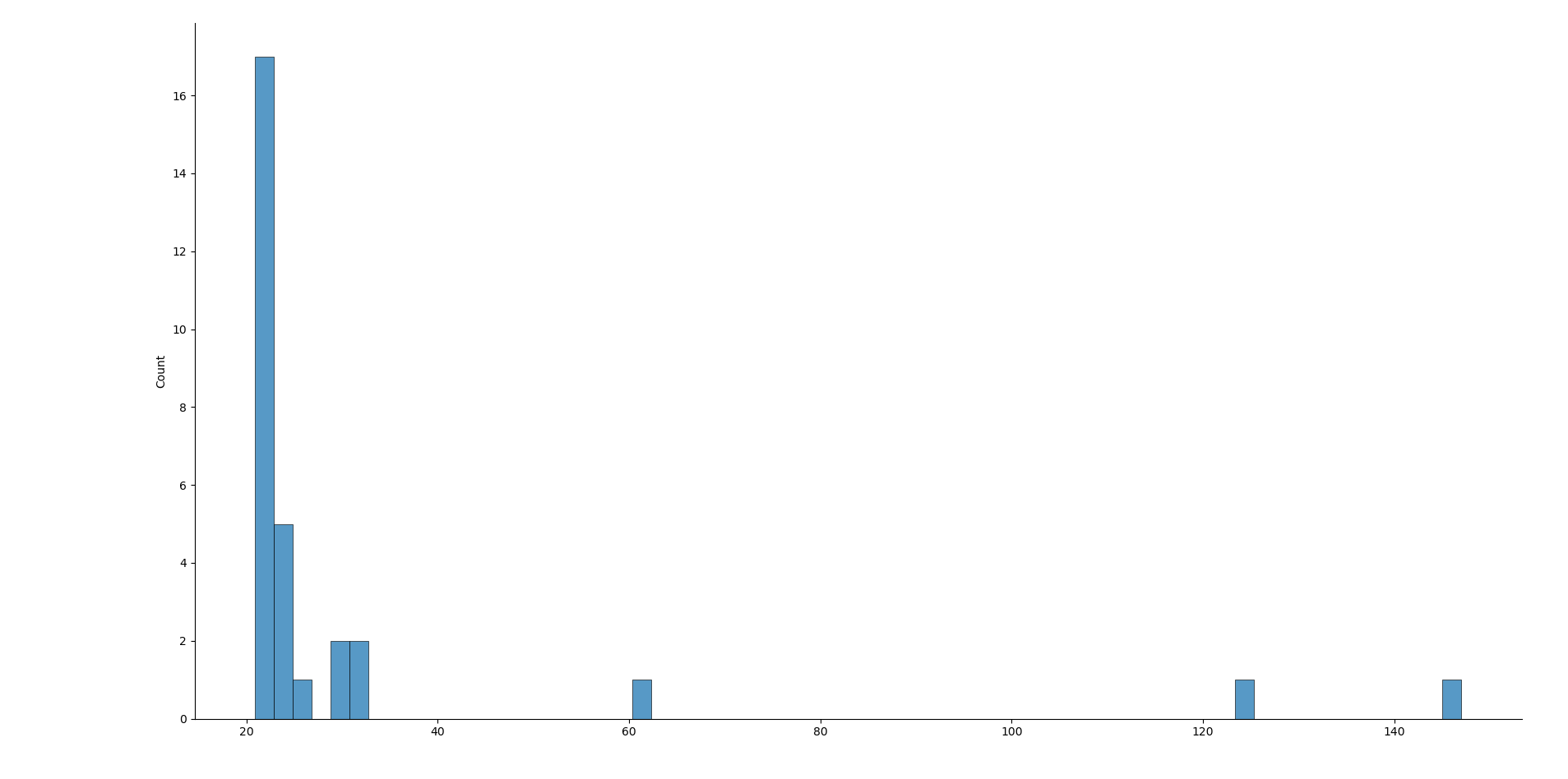
Если для приложения важна стабильность (онлайн‑игры, видеоконференции), ориентируйтесь не только на среднее, но и на медиану, перцентили и packet loss.
Альтернативные инструменты и подходы
- mtr — комбинирует traceroute и ping, показывает путь и задержки по каждому прыжку.
- traceroute — помогает найти проблемный хоп.
- iperf3 — измеряет пропускную способность и латентность TCP/UDP на уровне приложения.
- smokeping — длительный мониторинг латентности с графиками.
- tcping — замеры TCP‑соединения к конкретному порту (полезно, если ICMP блокируется).
Руководство по расследованию (короткий runbook)
- Запишите симптомы: высокое среднее, высокий mdev, потеря пакетов, время и частота.
- Повторите замер локально: ping к ближайшему шлюзу (роутер), затем к внешнему серверу.
- Сравните проводное и беспроводное соединение (подключите кабелем).
- Посмотрите трассировку: mtr
или traceroute . - Запустите длительный сбор (fping/smokeping) или сделайте сбор пакетов (tcpdump) для анализа.
- Свяжитесь с администратором/провайдером, приложив логи и скриншоты.
Важно: при обращении в поддержку приложите: дата/время, целевой хост, количество отправленных пакетов, вывод ping/mtr, описание симптомов.
Критерии приёмки (примерные ориентиры)
- Нормальный для повседневных задач: среднее латентности невысокое, а mdev не превышает уровня, при котором вы заметите заикания (оцените субъективно).
- Для игр/видеоконференций: предпочтительна низкая медиана и малый mdev; минимальные всплески задержек.
- Для критичных систем: используйте мониторинг с алертами по packet loss и 95‑му перцентилю задержки.
(Эти ориентиры не являются жёсткими правилами — конкретные пороги зависят от приложения и ожиданий.)
Чек‑листы по ролям
Пользователь/домашний офис:
- Проверьте с проводным подключением.
- Перезапустите роутер и клиентское устройство.
- Измерьте ping к провайдеру и к публичному серверу.
Сисадмин/сетевой инженер:
- Соберите длительные логи (smokeping/fping).
- Запустите mtr и traceroute в момент проблемы.
- Анализируйте packet loss на каждом хопе.
Поддержка провайдера:
- Сверьте метрики по интерфейсу абонента.
- Проверьте перегрузки, QoS и ошибки линка.
Небольшая методология измерений (SOP)
- Определите цель (короткий тест, длительный мониторинг, тест на нагрузку).
- Выберите цель измерения (IP‑адрес, домен, локальный шлюз).
- Выберите длину выборки (для повседневной диагностики 50–200 пакетов; для мониторинга — непрерывно).
- Установите разумный интервал между пакетами (0.2–1.0 с) и не перегружайте удалённый хост.
- Соберите данные, вычислите mean/median/mdev и перцентили.
- Сохраните вывод и при необходимости создайте тикет с вложениями.
Сравнение: mean vs median vs mdev vs packet loss
| Показатель | Что показывает | Когда важен |
|---|---|---|
| mean (среднее) | Среднее время отклика | Быстрое приближённое число, чувствителен к выбросам |
| median (медиана) | Центральное значение | При скошенных данных даёт стабильную оценку |
| mdev (σ) | Разброс значений | Оценивает изменчивость и jitter |
| packet loss | Процент потерянных пакетов | Критичен для стабильности соединения |
Небольшой словарь (1‑строчные определения)
- RTT: время для пакета пройти туда и обратно.
- mean: арифметическое среднее всех измерений.
- median: срединное значение упорядоченной выборки.
- mdev: стандартное отклонение по популяции (из вывода ping).
- jitter: изменчивость задержки между последовательными пакетами.
- packet loss: процент потерянных пакетов при отправке.
Дерево решений для базовой диагностики (Mermaid)
flowchart TD
A[Проблема: высокая задержка или «лаг»] --> B{Периодичность}
B --> |Постоянно| C[Пинг до локального шлюза]
B --> |Интермиттентно| D[Длительный сбор ping/mtr]
C --> E{Локально нормал?}
E --> |Да| F[Пинг к внешнему серверу и mtr]
E --> |Нет| G[Проверить Wi‑Fi/кабель, драйвера]
F --> H{Проблема на хопе провайдера?}
H --> |Да| I[Обратиться к провайдеру с логами]
H --> |Нет| J[Проверить целевой сервер]Когда статистика вводит в заблуждение — примеры провалов
- Малое количество пакетов (n < 10): среднее и mdev ненадёжны.
- Если ICMP приоритизируется или фильтруется, результаты не отражают поведение TCP/UDP.
- Сильная сетевая буферизация может давать низкую среднюю, но повышенную вариативность для коротких пиков.
Заключение и рекомендации
- Смотрите вместе на несколько метрик: mean, median, mdev, packet loss и перцентили.
- Для базовой диагностики начните с ping к локальному шлюзу и внешнему серверу, затем mtr/traceroute.
- Для стабильности подключайтесь кабелем, если это возможно; для длительного мониторинга — используйте специализированные инструменты.
Важно: всегда фиксируйте время и окружение замера — одинаковые условия помогают корректно сравнивать результаты.
Ключевые шаги для быстрой проверки: подключитесь проводом, выполните ping -c 100 с разумным интервалом, посчитайте медиану и mdev, запустите mtr для трассировки.
Похожие материалы

RDP: полный гид по настройке и безопасности

Android как клавиатура и трекпад для Windows

Советы и приёмы для работы с PDF

Calibration в Lightroom Classic: как и когда использовать

Отключить Siri Suggestions на iPhone
