Регулярные выражения (Regex) — основы для поиска и работы с текстом в Linux

Быстрые ссылки
Что такое Regex?
Варианты синтаксиса (flavors)
Быстрое введение: обзор ключевых понятий
DOTALL: метасимвол «точка» и когда он совпадает со всем
Классы символов: как описать допустимые символы
Группы совпадения: ограничиваем подвыражения
Квантификаторы: точные и переменные количества
Жадные и ленивые квантификаторы
Якоря: начало и конец строки
Модификаторы: флаги, влияющие на поведение
Применение: использование регулярных выражений с командами shell
Что такое Regex?
Регулярное выражение (regex) — это язык описания шаблонов для строк. Проще: вы пишете правило, а инструмент находит все строки, которые ему соответствуют. Правила могут быть простыми (например, найти слово “foo”) или очень сложными (например, найти пути, соответствующие определённой структуре, или извлечь данные из логов).
Пример практического сценария: нужно найти файл с именем foo.jpg или foo.png, но вы не помните расширение. С regex это просто:
fd 'foo\.(jpg|png)'Где применять: почти везде. grep, ripgrep, sed, awk, Perl, текстовые редакторы (Vim, Emacs, VS Code) и многие языки программирования понимают регулярные выражения. Освоив базу, вы сможете сэкономить много времени при поиске и обработке данных.
Важно: разные инструменты поддерживают немного разные диалекты регулярных выражений. Мы разберём общие элементы, которые встречаются повсеместно.
Варианты синтаксиса регулярных выражений
Термин “flavor” означает диалект или набор правил. Самый мощный и богатый — PCRE (Perl Compatible Regular Expressions). Многие инструменты близки к PCRE, но встречаются отличия:
- PCRE: богатый набор возможностей (группы захвата, позитивный/негативный lookahead/lookbehind в современных версиях и т. п.).
- POSIX ERE/POSIX BRE: старые стандарты, более простые и в некоторых случаях менее гибкие.
- Rust regex crate: ориентирован на производительность и совместим с большинством конструкций PCRE, но без некоторых тяжёлых возможностей (например, произвольных lookbehind).
Совет: если вы планируете переносить выражения между утилитами, старайтесь использовать базовые конструкции (классы символов, группы, квантификаторы, якоря). Если нужен специфичный функционал (например, lookbehind), проверьте, поддерживает ли его целевой инструмент.
Быстрый обзор: ключевые понятия
Ниже — краткая таблица основных строительных блоков регулярных выражений и их простых объяснений.
| Понятие | Описание |
|---|---|
| Классы символов | Список символов в квадратных скобках, например [abc] — любой из перечисленных. |
| Группы совпадения | Скобки служат для группировки подвыражений, например (foo). |
| Модификаторы | Флаги, меняющие поведение (g — глобально, i — нечувствительность к регистру, m — мультилайн). |
| Якоря | ^ — начало строки, $ — конец строки. |
| Квантификаторы | Определяют количество повторов: ?, *, +, {n,m}. |
| Альтернация | “или” в выражениях — символ |, например foo|bar. | | DOTALL | Точка . обычно совпадает с любым символом кроме перевода строки; в DOTALL-режиме она может совпадать и с ним. |
По сути, комбинируя эти элементы, вы описываете структуру строк, которые нужно найти.
DOTALL: метасимвол «точка» и когда он совпадает со всем
Точка в regex — короткая запись «любой символ» (включая буквы, цифры, знаки препинания). В некоторых реализациях по умолчанию точка не совпадает с символом новой строки. Когда активен DOTALL, точка.match-ит и перенос строки.
Применение: удобно, когда нужно захватить произвольный фрагмент текста между двумя маркерами: например, извлечь содержимое тега, многострочного блока или пути, где между компонентами могут быть любые символы.
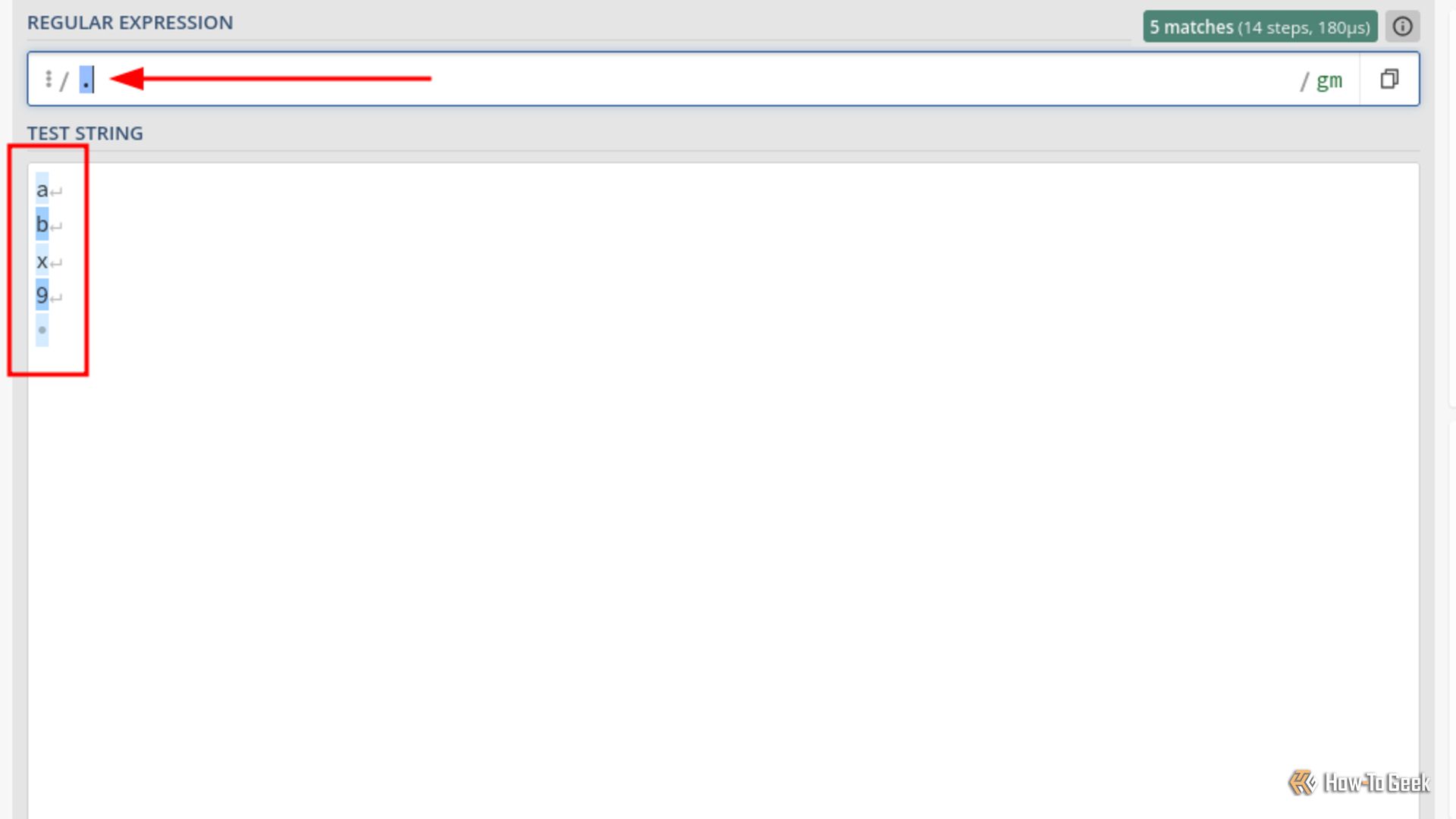
Пример:
^.*$ # без DOTALL — совпадение по строке, . не захватывает \n
(?s)^.*$ # с флагом DOTALL (в некоторых синтаксисах (?s)) — поймает весь текст, включая переводы строкиСовет: не делайте .+ без необходимости на больших текстах — это может быть дорого по времени. Лучше ограничивать контекст, если известно, какие символы ожидаются.
Классы символов: точный набор допустимых символов
Класс символов — это всё, что находится в квадратных скобках: [ … ]. Он описывает один символ из набора.
Примеры:
[abz129] # совпадает с 'a' или 'b' или 'z' или '1' или '2' или '9'
[a-zA-Z0-9] # любой латинский символ (нижний/верхний регистр) или цифра
[-a-z] # если '-' стоит первым — трактуется как литерал
[a-z\-] # или экранируйте '-' внутри классаКласс всегда соответствует ровно одному символу, если не применён квантификатор.

Пояснение глобального поиска: если инструмент работает в глобальном режиме (g), то он не останавливается после первого совпадения и ищет дальше, поэтому один класс символов может найти множество отдельных совпадений в содержимом.
Группы совпадения: ограничиваем подвыражения
Круглые скобки группируют части выражения и позволяют оперировать ими как единым целым: повторять, выбирать альтернативы или извлекать подстроки.
Пример разницы:
foo(bar|baz) # совпадёт с foobar или foobaz
foobar|baz # совпадёт с foobar или baz — поведение другоеГруппы полезны для захвата (capturing) частей строки: многие инструменты возвращают захваченные группы отдельно, что удобно для замен и парсинга.
Совет: если вам не нужен захват (только группировка для квантификатора или альтернации), используйте негруппирующие скобки, если они поддерживаются: (?: … ). Это избавляет от лишних нумераций групп.
Квантификаторы: точные и переменные количества
Квантификаторы говорят, сколько раз должен повториться предыдущий элемент (символ, класс или группа).
Основные квантификаторы:
- ? — 0 или 1 (опционально)
- — 0 или больше
- — 1 или больше
- {n} — ровно n
- {n,} — n или больше
- {n,m} — от n до m
Примеры:
[abz]* # ноль или более символов из набора
[abz]+ # один или более
[abz]? # 0 или 1
[abz]{2} # ровно два символа из набора
[abz]{2,4} # от 2 до 4 символовВажно: метасимволы + и ? часто не работают в утилитах POSIX без соответствующих флагов (например, grep требует -P для PCRE; sed — флаг -E для расширенных выражений). Всегда проверяйте документацию.
Краткий справочник по квантификаторам
- ? — опционально
- — 0 или больше
- — 1 или больше
- {n,m} — диапазон повторов
Жадные и ленивые квантификаторы
По умолчанию квантификаторы жадные: они стремятся захватить как можно больше символов, оставаясь в рамках всего выражения. Ленивые квантификаторы минимизируют захват — обычно это достигается добавлением ? после квантификатора.
Примеры:
[abz]+ # жадный — захватит максимум подряд
[abz]+? # ленивый — захватит минимально возможное количество
[abz]*? # ленивый вариант для * (может совпадать с пустой строкой)Когда ленивость полезна: при извлечении минимального блока между двумя маркерами (например, текст между
Производительность: ленивые квантификаторы иногда быстрее, потому что не приходится перерабатывать большие фрагменты текста, но это зависит от реализации. На больших объёмах данных лучше тестировать оба варианта.
Якоря: начало и конец строки
Якоря ^ и $ помогают ограничить область совпадения началом и концом строки соответственно. Это критично, когда нужно точно совпасть со всей строкой или с её началом/концом.
Пример точного соответствия:
^foo$ # совпадёт только если строка ровно 'foo'
^foo # совпадёт если строка начинается с 'foo'
foo$ # совпадёт если строка заканчивается на 'foo'
Модуль мультирежима (m) меняет смысл якорей: при активном m ^ и $ работают с началом/концом каждой строки в многострочном тексте, а не всей строки целиком.
Модификаторы: флаги, меняющие поведение
Модификаторы (flags) обычно записываются в конце шаблона или в явном синтаксисе (например, (?i) для нечувствительности к регистру). Основные флаги:
- g — глобальный поиск (найти все совпадения, а не только первое)
- i — нечувствительность к регистру
- m — multiline: ^ и $ привязаны к строкам, а не к полному тексту
- s — DOTALL: точка совпадает с переводом строки

Особенность: разные утилиты по-разному включают флаги. grep, sed, Perl, JavaScript и другие используют собственный синтаксис. Часто флаги можно задать в команде или в самом шаблоне.
Глобальный модификатор
g позволяет найти все совпадения в тексте, а не только первое. В grep это управление делается через поведение инструмента (grep по строкам), в других утилитах g добавляется явно (например, в редакторах и инструментах замены).
Нечувствительность к регистру
i — удобный флаг для поиска без учёта регистра. Вместо [aA][bB]… — используйте i.

Мультирежим
m разделяет поведение якорей: с m ^ и $ работают по строкам. При анализе логов это часто полезно.
Замечание: если включаете m и хотите обработать каждую строку — часто нужен и g, чтобы получить все совпадения по каждой строке.
Собираем всё вместе: практическое применение с командами
Ниже — примеры использования одного и того же шаблона с разными инструментами. Это поможет понять небольшие различия и типичные флаги.
Шаблон, который мы будем использовать:
^.+/[fo]+\.(jpg|png)$Назначение: ищет POSIX-путь к файлам .jpg или .png, имя файла состоит из букв f и o (по крайней мере одна буква), перед именем есть слэш. Пример совпадения:
/foo/bar/baz/foo.jpgРазбор выражения по сегментам:
| Сегмент | Пояснение |
|---|---|
| ^ | начало строки |
| .+ | любой символ один или более раз |
| / | буквальный слэш — граница перед именем файла |
| [fo]+ | один или более символов ‘f’ или ‘o’ (имя файла) |
| . | буквальная точка (экранирована) |
| (jpg|png) | альтернация: jpg или png | | $ | конец строки |
Пример файла examples с тестовыми строками:
/foo/bar/baz/foo.jpg
/one/two/thr/foo.png
/this/should/not/match.jpggrep
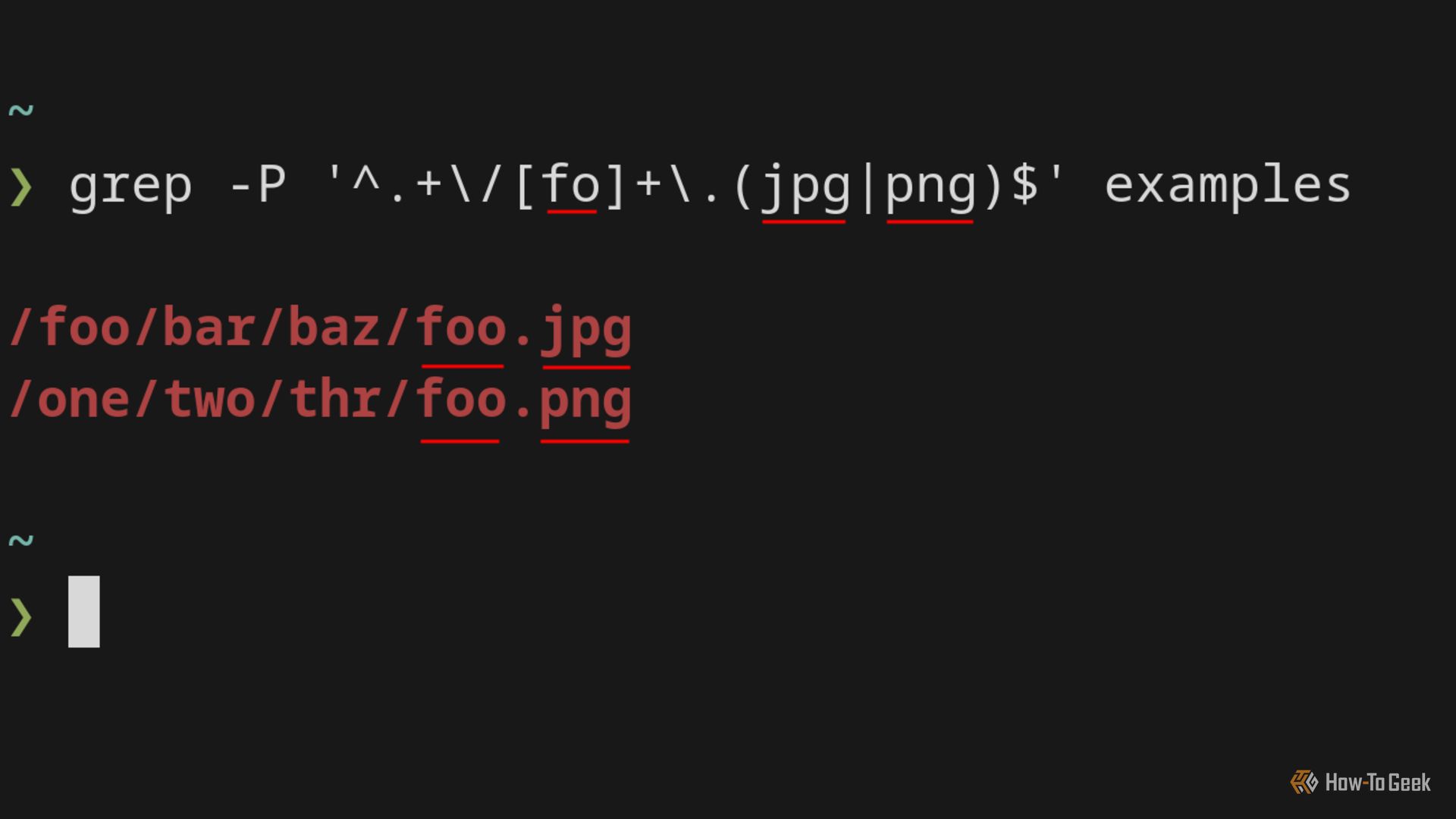
Grep поддерживает PCRE-совместимость через флаг -P (в GNU grep). Так что:
grep -P '^.+/[fo]+\.(jpg|png)$' examplesЭто найдёт строки с полными путями и нужными расширениями. Если -P недоступен в вашей сборке grep, используйте ripgrep или fd либо posix-совместимые выражения с find.
Совет: для поиска по именам файлов prefer fd или find, а для содержимого файлов — grep или ripgrep.
find
find поддерживает несколько regextype. Узнать доступные можно командой:
find -regextype helpЧаще всего для совместимости с PCRE выбирают posix-extended (posix-extended близок к POSIX ERE). Пример с regextype:
find . -regextype posix-extended -regex '^.+/[fo]+\.(jpg|png)$'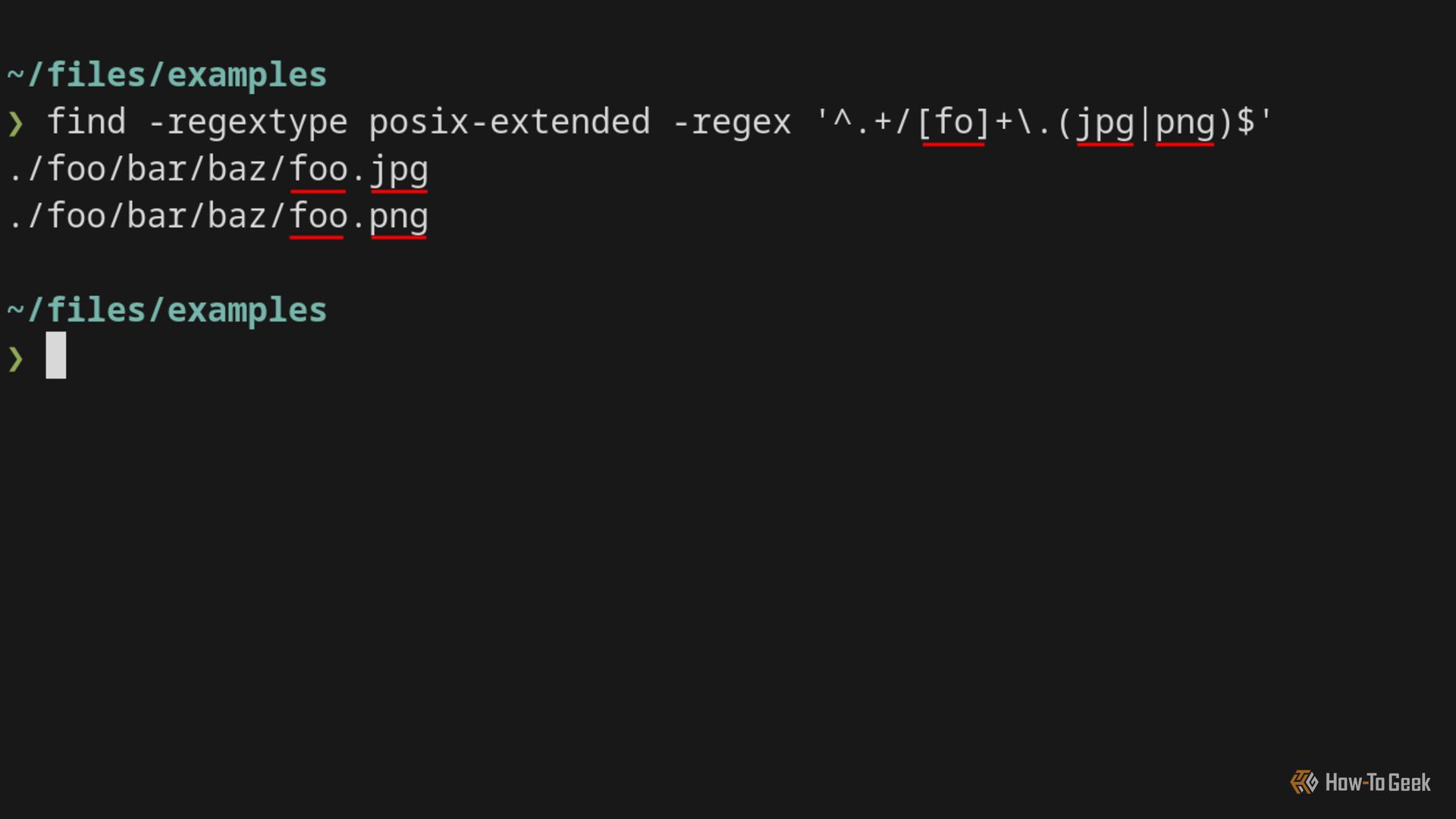
Если команда выглядит громоздкой, создайте алиас в своём shell-профиле.
fd
Fd использует Rust regex crate. По умолчанию fd сопоставляет только имя файла, а не полный путь. Чтобы сопоставлять полный путь, используйте –full-path:
fd --full-path '^.+/[fo]+\.(jpg|png)$'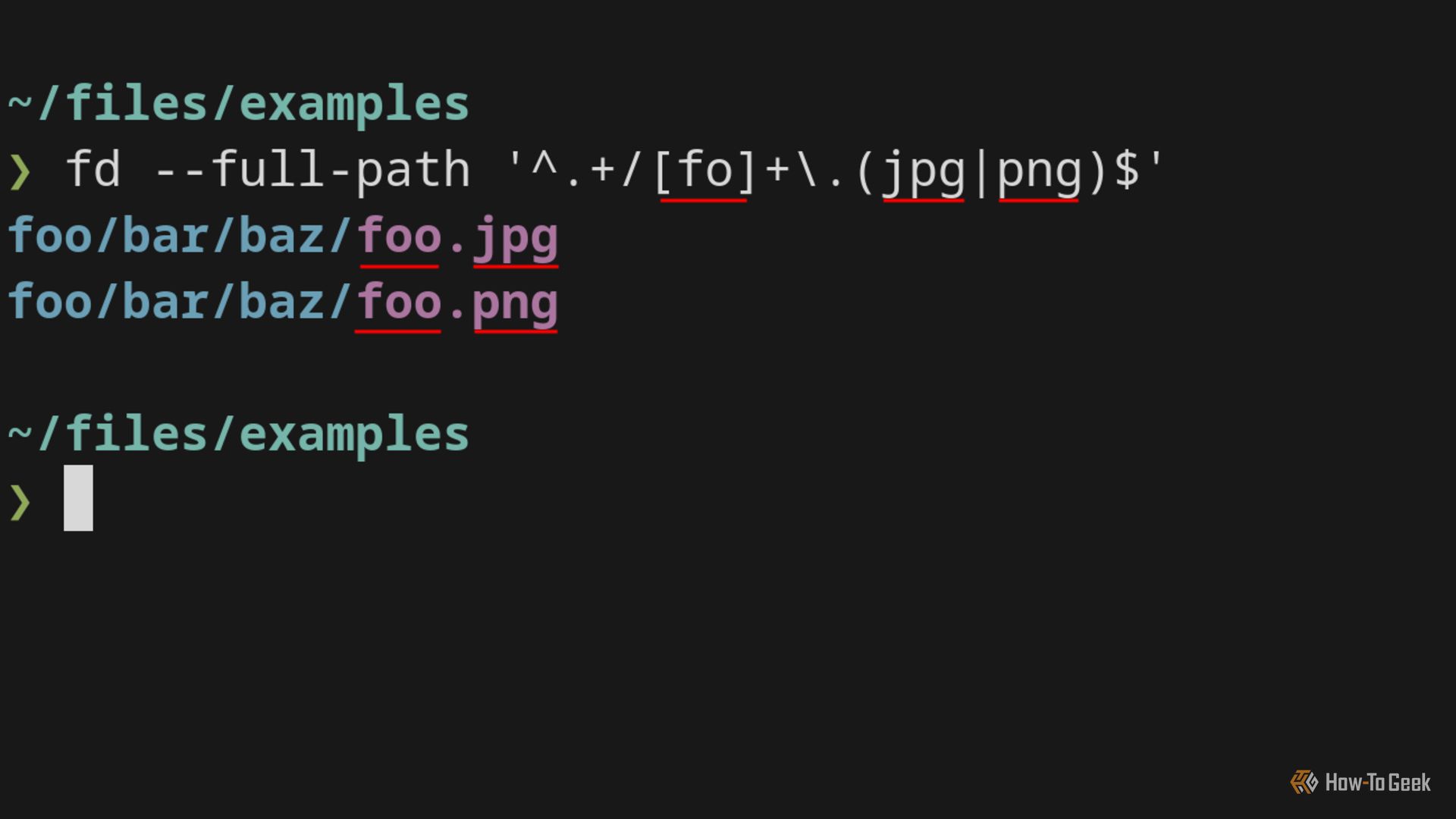
Fd — удобен для интерактивного поиска и быстрее, чем find в большинстве сценариев благодаря оптимизациям.
ripgrep (rg)
Ripgrep тоже использует Rust regex crate и по умолчанию ищет в содержимом файлов. Для поиска путей и имён файлов можно использовать –files и фильтры или искать в выводе других команд.
Пример поиска в списке путей:
rg --no-line-number -N '^.+/[fo]+\.(jpg|png)$' examples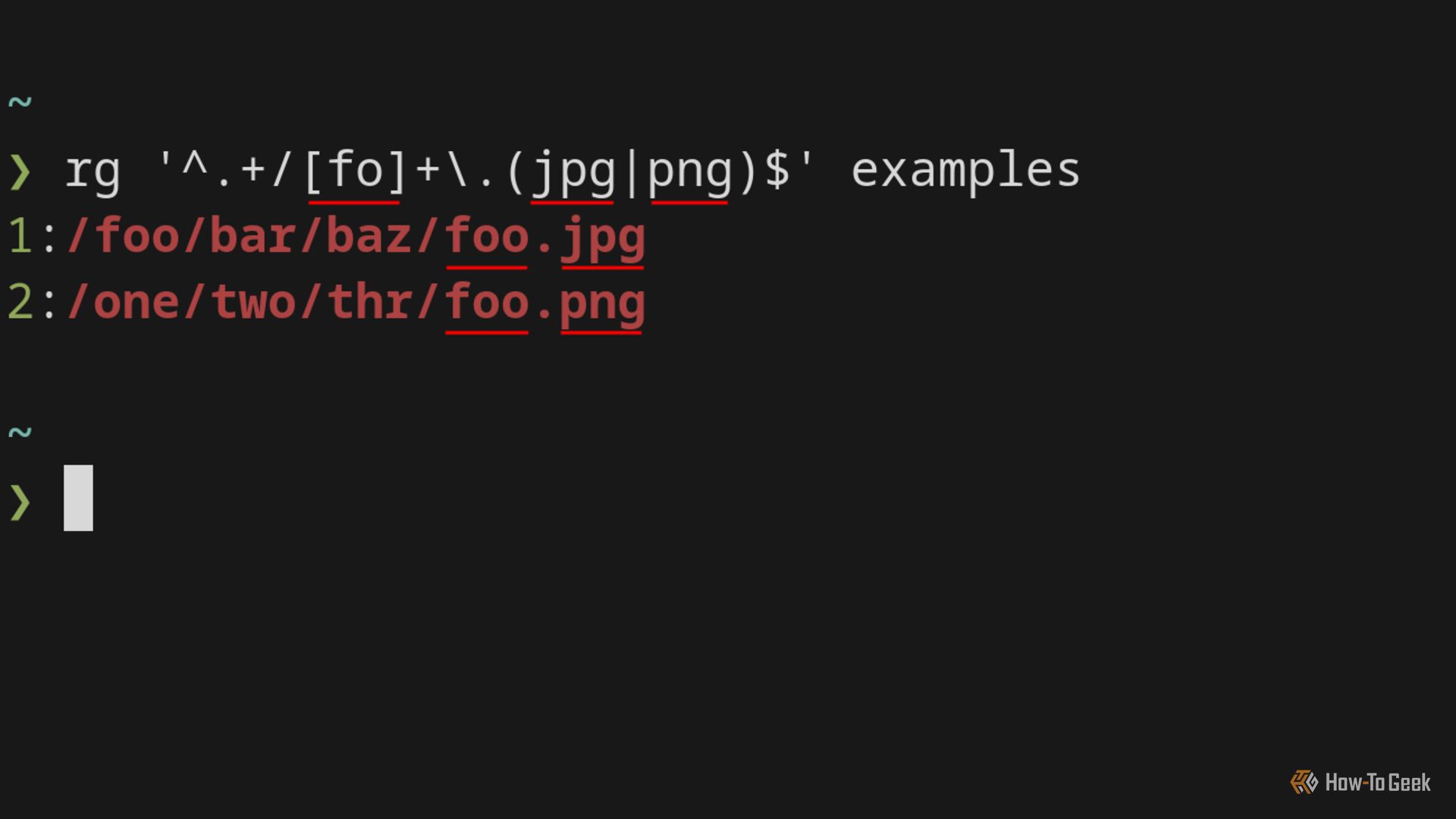
sed
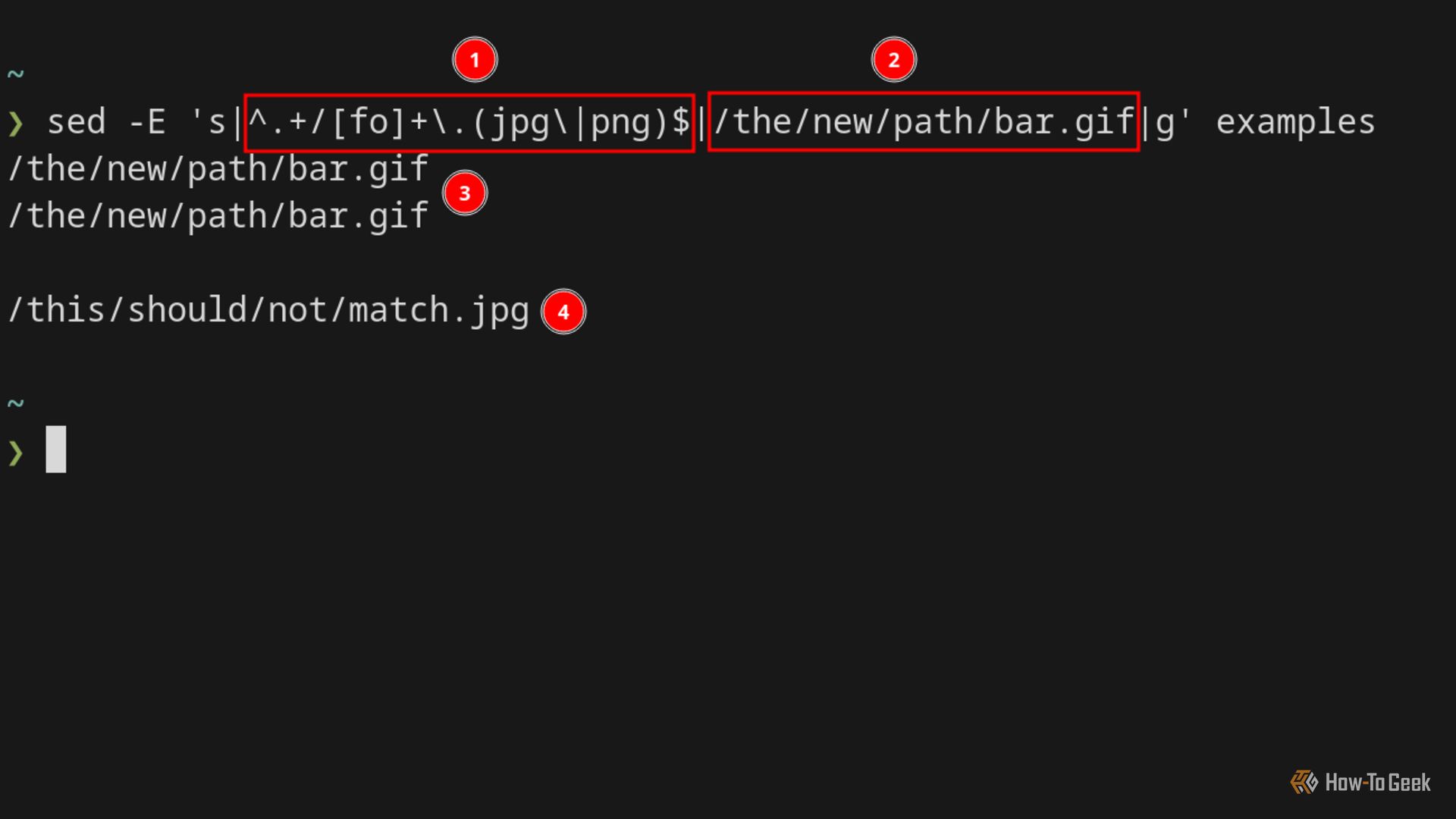
Sed — инструмент поиска и замены в потоках текста. Общая форма замены:
s/pattern/replacement/Вы можете использовать любой разделитель вместо /, например |, чтобы не экранировать слэши в путях. Для GNU ERE используйте флаг -E:
sed -E 's|^.+/[fo]+\.(jpg|png)$|REPLACED|' examplesSed может править файлы на месте с флагом -i. Будьте осторожны: лучше сначала протестировать без -i.
Полезные приёмы и советы
- Проверяйте выражения в песочнице (regex101, онлайн-тестеры) — там видны группы и совпадения.
- Не используйте .+ без явной необходимости; лучше сузить класс символов.
- Для работы с большими файлами отдавайте предпочтение ripgrep/fd — они оптимизированы.
- Всегда экранируйте символы, если хотите буквальное совпадение: . ^ $ * + ? ( ) [ ] { } | \ /
- Если вам не нужно захватывать группу, используйте (?:…) там, где это поддерживается — это делает индексацию групп предсказуемой.
Когда регулярные выражения не подходят (контрпример)
- Сложный парсинг вложенных структур (например, правильно распарсить HTML с произвольной вложенностью) — регулярные выражения быстро становятся громоздкими и ненадёжными. Для таких задач лучше использовать парсер (HTML/XML-парсер, библиотеку JSON и т. п.).
- При очень больших данных с неоптимальными выражениями — возможны угловые случаи катастрофической рекурсивности (backtracking). В таких сценариях стоит упростить шаблон или использовать более строгие классы.
Альтернативные подходы
- Глобальные парсеры: использовать специализированный парсер HTML / XML / JSON вместо regex.
- Инструменты для обработки потоков: awk или perl могут быть удобнее, если требуется более сложная логика обработки.
- Комбинация: сначала используйте grep/fd для отбора нужных файлов, затем sed/awk/Perl для извлечения данных.
Ментальные модели и эвристики
- “Строитель домиков”: представляйте выражение как набор блоков (классы, группы, квантификаторы), которые вы соединяете в конструкцию. Чем меньше блоков “.*” — тем предсказуемее результат.
- “Ограждение”: если хочется захватить минимально возможный фрагмент между маркерами — думайте о ленивых квантификаторах и якорях.
- “Якорь-преграда”: ставьте ^ и $ там, где важно точное соответствие, чтобы избежать ложных срабатываний.
Шаблоны для практики (mini-методология)
- Начните с простого — найдите самые очевидные совпадения.
- Сузьте класс символов (из .+ в [^/]+ или [\w-]+, если знаете допустимые символы).
- Добавьте границы: / или ^ $.
- Проверьте на реальных данных (тестовый набор). Протестируйте краевые случаи.
- Профилируйте на больших файлах (ripgrep/fd обычно быстрее).
Ролевые чек-листы
Для разработчика:
- Используйте тернарные группы для извлечения данных.
- Проверьте выражение в тестовом окружении.
- Избегайте ненужных захватов, используйте (?:…).
Для системного администратора:
- Используйте ripgrep/fd для быстрого поиска в файловой системе.
- Создайте алиасы для часто используемых выражений (например, find с regextype).
- Бэкапьте файлы перед массовой заменой sed -i.
Для тестировщика:
- Сформируйте набор строк с позитивными и негативными случаями.
- Проверяйте совпадения и захваченные группы.
- Автоматизируйте тесты на регрессию для критичных выражений.
Шпаргалка: часто используемые выражения
Поиск e-mail (упрощённый):
[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}Поиск номера телефона (простой шаблон):
\+?\d{1,3}[ \-]?\(?\d{1,4}\)?[ \-]?\d{3,4}[ \-]?\d{3,4}Поиск пути UNIX (упрощённый):
/[^\s]*\.(jpg|png|gif)Захват имени файла и расширения:
.*/([^/]+)\.(jpg|png)
Критерии приёмки
- Выражение корректно матчит все позитивные примеры из набора тестов.
- Выражение не совпадает с негативными примерами (ложные срабатывания).
- Производительность приемлема на реальном объёме данных (тестирование на выборке).
- Нумерация групп предсказуема и документирована (или используются незахватывающие группы).
Приёмы отладки
- Тестируйте шаг за шагом: сначала класс символов, затем квантификатор, затем группа.
- Подсвечивайте совпадения в онлайн-песочнице (regex101) — там видно, какие группы и какие части строки совпали.
- Для сложных выражений разбивайте их на части и проверяйте каждую по отдельности.
Совместимость и миграция между утилитами
- grep: для PCRE используйте -P (если поддерживается). Без -P grep использует POSIX-совместимый синтаксис.
- find: используйте -regextype posix-extended для повсеместной совместимости с выражениями без сложных PCRE-фич.
- sed: GNU sed поддерживает -E (ERE). Для сложности используйте Perl или awk.
- fd и ripgrep: используют Rust regex crate — большинство PCRE-конструкций работают, но некоторые расширенные фичи (сложные lookbehind) могут не поддерживаться.
Совет: храните критичные выражения в репозитории с описанием, где и как их применять, а также с набором тестов.
Примеры задач и тесты приёмки
Задача: найти все пути к .jpg и .png, где имя состоит только из букв f и o.
- Тест: набор примеров (позитивные и негативные) — все позитивные должны совпасть, негативные — не совпадать.
Задача: заменить все такие пути на /images/placeholder.jpg
- Тест: sed -E ‘s|^.+/[fo]+.(jpg|png)$|/images/placeholder.jpg|’ корректно заменяет только нужные строки.
1-строчный глоссарий
- Regex: язык описания шаблонов для строк.
- Класс символов: [abc] — любой из перечисленных.
- Группа: (foo) — подвыражение, возможно с захватом.
- Квантификатор: +, *, ?, {n,m} — управляет количеством повторов.
- Якорь: ^ и $ — начало и конец строки.
- Флаг: i, g, m, s — меняют поведение шаблона.
Короткая дорожная карта для изучения
- Понять базовые метасимволы и классы.
- Попрактиковаться в grep, ripgrep, fd и sed.
- Освоить флаги и разницу между диалектами.
- Научиться отлаживать и тестировать выражения на реальных данных.
Локальные советы для русскоязычной среды
- При работе с путями в Windows учитывайте обратный слэш \ и экранирование внутри выражения.
- В названиях файлов на русском языке используйте классы символов Unicode, если инструмент их поддерживает (\p{Cyrillic} и т. п.), либо используйте явные диапазоны.
Ресурсы для практики
- regex101 — онлайн-песочница с подсветкой групп и объяснением.
- Официальная документация grep, sed, find, fd, ripgrep.
- Книги и статьи по теме: вводные и продвинутые руководства.
Короткое резюме
Регулярные выражения — это мощный инструмент для поиска и трансформации текста. Изучите классы символов, группы, квантификаторы, якоря и модификаторы — и комбинируйте их по необходимости. Всегда проверяйте диалект regex в используемом инструменте и тестируйте выражения на реальных данных.
Важно: для сложных вложенных структур используйте парсеры, а регулярные выражения применяйте там, где они дают простое и предсказуемое решение.
Для начала практики используйте набор примеров в разделе выше и попробуйте выполнить те же команды на своих данных.
Похожие материалы

RDP: полный гид по настройке и безопасности

Android как клавиатура и трекпад для Windows

Советы и приёмы для работы с PDF

Calibration в Lightroom Classic: как и когда использовать

Отключить Siri Suggestions на iPhone
