Руководство: запуск Docker-контейнеров в AWS ECS

TL;DR
ECS — это управляемый движок для запуска Docker-контейнеров в AWS: выбирайте запуск на Fargate (серверless) для простоты и быстрой масштабируемости или EC2 для полного контроля над инстансами. Загрузите образ в ECR, создайте Task Definition и Service, включите авто‑масштабирование и, при необходимости, добавьте балансировщик нагрузки. Этот материал пошагово объясняет настройки, подводные камни и даёт практические чек‑листы.
Быстрые ссылки
Что такое ECS?
Настройка Docker и загрузка в ECR
Развёртывание в ECS
Что такое ECS?
AWS Elastic Container Service (ECS) — это вычислительный движок для Docker‑контейнеров. Он позволяет запускать контейнеры либо на управляемых вами EC2‑инстансах, либо в серверless‑окружении Fargate, где AWS самостоятельно управляет инфраструктурой.
Пояснение в одну строку: ECS принимает Docker‑образ, выделяет ресурсы и запускает контейнеры, освобождая вас от рутины управления серверами.
Основные преимущества:
- Управляемая оркестрация контейнеров без необходимости вручную настраивать кластеры.
- Поддержка двух моделей запуска: Fargate (серверless) и EC2 (управляемые инстансы).
- Интеграция с другими сервисами AWS: ECR для образов, CloudWatch для логов и метрик, ALB/NLB для балансировки.
Как это работает в общем:
- Вы создаёте Docker‑образ и загружаете его в реестр (ECR или другой).
- В ECS вы описываете Task Definition — «рецепт» контейнера: образ, порты, лимиты памяти/CPU и т.д.
- Сервис (Service) разворачивает экземпляры Task Definition и следит за их здоровьем и масштабированием.
Авто‑масштабирование: ECS умеет автоматически добавлять и удалять задачи (tasks) по метрикам CPU/памяти или по CloudWatch‑сигналам, что упрощает управление пиковой нагрузкой и экономит бюджет в простое.
Стоимость: для EC2 вы платите только за используемые инстансы; Fargate тарифицируется по vCPU и памяти. На бумаге Fargate часто выглядит примерно на 20% дороже, но экономия приходит за счёт точного потребления ресурсов и возможности использования Spot, что уменьшает общую стоимость в реальных сценариях.
Настройка Docker и загрузка в ECR
Чтобы доставить образ до ECS, его нужно поместить в реестр. Можно использовать Docker Hub или собственный реестр, но AWS предлагает Elastic Container Registry (ECR) — приватный реестр, интегрированный с AWS‑аккаунтом.
- Перейдите в консоль ECR и создайте новый репозиторий. В списке будет колонка “URI” — скопируйте значение для вашего репозитория (оно содержит ID аккаунта и регион).
Сохраните следующий скрипт рядом с вашим Dockerfile под именем
updateECR.shзамените переменные
TAGи
REPOна актуальные значения.
TAG="docker-test"REPO=”ACCOUNT_ID.dkr.ecr.REGION.amazonaws.com/“$TAG”:latest”
aws ecr get-login-password | docker login –username AWS –password-stdin $REPO
docker build -t $TAG .
docker tag $TAG:latest $REPO
docker push $REPO
Running this script will login to ECR, build your container, tag it, and push it to your repository. If you refresh the list, you should see your container:
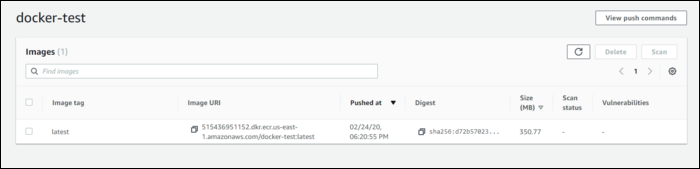
Примечания по безопасности и доступу:
- Политики IAM: для автоматического push/pull задайте роль/пользователя с правами ecr:GetAuthorizationToken, ecr:BatchCheckLayerAvailability, ecr:PutImage, ecr:InitiateLayerUpload и т.д.
- Для CI/CD интеграции используйте сервисные роли и короткоживущие токены, а не статические ключи.
Развёртывание в ECS
Для запуска контейнера в ECS нужны две сущности:
- Task Definition — содержит метаданные контейнеров: образ, порты, лимиты памяти/CPU, переменные окружения и т.д. В одном Task Definition можно описать несколько контейнеров (sidecar, вспомогательные сервисы).
- Service — представляет развертывание Task Definition: сколько задач поддерживать, какое сетевое окружение использовать, настройки авто‑масштабирования. Сервисы группируются в Cluster.
Шаги развёртывания:
- Создайте Task Definition (Task Definitions в боковом меню).
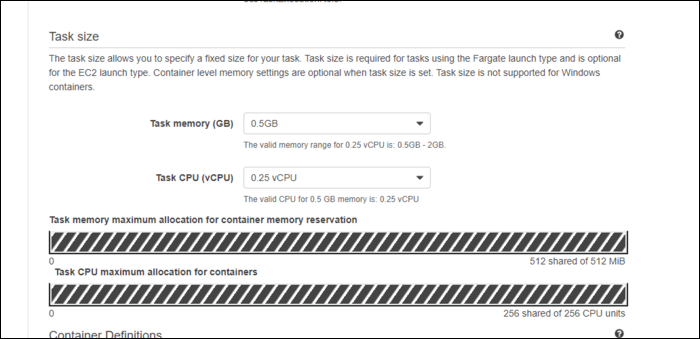
- Задайте имя, общую память задачи и vCPU. При планировании автоскейла думайте о единице развертки: вместо одного крупного контейнера с 16 vCPU логичнее развертывать несколько меньших, например 8 контейнеров по 2 vCPU.
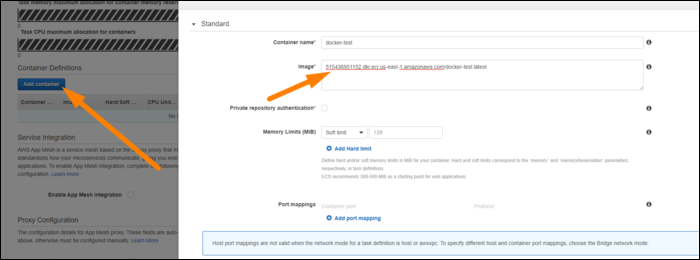
- Нажмите «Add Container» и укажите URI вашего образа в ECR, пределы памяти, переменные окружения и порты.
Создайте Cluster (Fargate или EC2), при необходимости создайте VPC или используйте дефолтную.
Из Cluster создайте Service, укажите launch type, Task Definition, желаемое количество задач и количество здоровых инстансов.
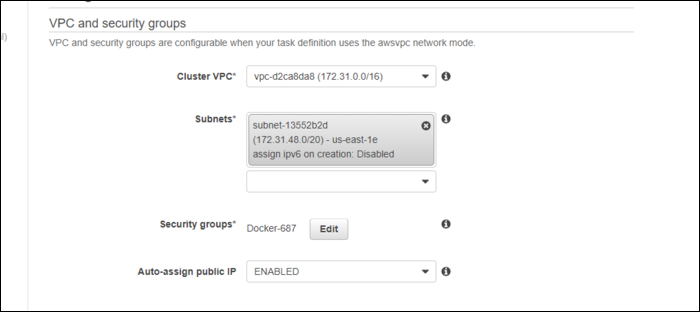
- На экране конфигурации сервиса укажите VPC, подсеть и Security Group. Не забудьте открыть нужные порты в Security Group.
При добавлении балансировщика нагрузки установите адекватный Health Check Grace Period, чтобы контейнеры не помечались как нездоровые во время старта.
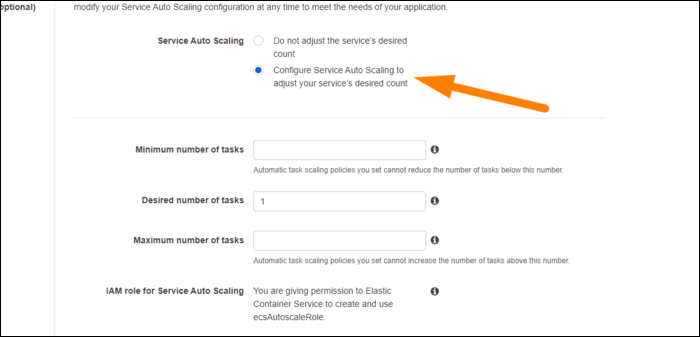
Включите авто‑масштабирование: укажите желаемое количество задач, минимум и максимум.
Рекомендация по политике масштабирования: используйте TargetTrackingPolicy по CPU (ECSServiceAverageCPUUtilization) с порогом 75–80% или комбинируйте с метриками памяти и задержек ответа. Если не используете target tracking, настройте ручные политики на основе CloudWatch‑аларм.
После запуска сервису потребуется пару минут для старта задач. Сервис будет доступен по ENI интерфейсу контейнера или через балансировщик нагрузки. Если нужен постоянный публичный адрес — привяжите Elastic IP к ENI и настройте DNS.
Когда ECS не подходит
- Требуется тонкий контроль над ядром хоста или модификация уровня ядра — лучше EC2 с вручную настроенными инстансами или bare‑metal.
- Очень низкая латентность между контейнерами на одном хосте и требуются специфичные оптимизации сети — возможно, подойдёт Kubernetes с node‑affinity или bare‑metal.
- Если вы уже имеете зрелую Kubernetes‑экосистему и зависите от специфичных CRD/operator’ов — миграция на ECS может потребовать значительных изменений.
Альтернативные подходы
- Amazon EKS (Kubernetes) — больше гибкости и экосистемы, но выше сложность управления.
- ECS + EC2 — если нужен контроль за инстансами, слой AMI и кастомные драйверы.
- Serverless (AWS Lambda) — для коротких задач, не требующих постоянного процесса.
Ментальные модели и эвристики
- Единица масштабирования — думайте не о суммарных vCPU, а о количестве задач одинакового размера; проще масштабировать множество маленьких задач.
- Отказоустойчивость — ставьте минимум 2 задачи в разных AZ для сервиса, критичного к доступности.
- Cost vs Control — Fargate экономит время и снижает риск, EC2 даёт контроль и может быть дешевле при постоянной загрузке.
Мини‑методология: быстрый путь в прод
- Собрать минимальный Docker‑образ, прогнать локально.
- Создать приватный ECR и загрузить образ.
- Описать Task Definition с одной контейнерной службой, минимальными ресурсами.
- Развернуть Service в Fargate с 2 задачами в двух AZ.
- Настроить ALB и Health Check Grace Period 60–120 с, чтобы избежать ложных провалов.
- Включить TargetTracking по CPU с порогом ~75%.
- Наблюдать и корректировать лимиты памяти/CPU по реальным метрикам.
Чек‑лист ролей
DevOps:
- Создан ECR‑репозиторий и настроены политики доступа.
- Написан и протестирован скрипт сборки и push.
- Создан Task Definition и Service.
- Настроено логирование в CloudWatch и мониторинг.
Разработчик:
- Образ проходит локальные тесты и health endpoints.
- Контейнер корректно читает переменные окружения и настройки конфигурации.
Инженер по безопасности:
- Проверены политики IAM и минимальные привилегии.
- Security Group и Network ACL настроены по принципу минимально необходимых портов.
- Логи и метрики собираются и доступны для анализа.
Критерии приёмки
- Контейнер успешно развёрнут и отвечает на health checks в течение заданного grace period.
- Авто‑масштабирование увеличивает/уменьшает число задач при изменении нагрузки.
- Логи появляются в CloudWatch и содержат ключевые события старта/ошибок.
- Время восстановления при падении задачи соответствует SLA проекта.
План отката и инцидентное руководство
- При падении новых задач — откатите Service на предыдущую рабочую Task Definition через консоль или CLI.
- Если проблемы связаны с образом — пометьте проблемный тег и восстановите предыдущий тег образа в ECR.
- При сетевых проблемах проверьте Security Groups, NACL и маршрутизацию VPC.
- Если служба недоступна из‑за ALB — проверьте target group, health checks и listener rules.
Критические шаги при инциденте:
- Отключить автодеплой из CI.
- Откатить Task Definition на стабильную версию.
- Поднять временный масштаб под текущую нагрузку вручную.
- Собирать логи и профили для пост‑mortem.
Риски и способы смягчения
- Неправильные лимиты памяти — контейнеры могут быть убиты; устанавливайте мягкие и жёсткие лимиты и тестируйте под нагрузкой.
- Неправильно настроенные health checks — ложные перезапуски; увеличьте grace period и адаптируйте endpoint.
- Избыточные привилегии IAM — минимизируйте права и используйте временные креды для CI.
Примечания по безопасности и конфиденциальности
- Храните секреты в AWS Secrets Manager или SSM Parameter Store и не встраивайте их в образы.
- Для хранения персональных данных соблюдайте правила локального законодательства и GDPR: используйте шифрование в покое и в транзите, настройте аудит доступа.
Decision flow для выбора модели запуска
flowchart TD
A[Нужен полный контроль над хостами?] -->|Да| B[EC2]
A -->|Нет| C[Fargate]
B --> D{Зависит от Kubernetes?}
D -->|Да| E[EKS]
D -->|Нет| F[Останьтесь на ECS + EC2]
C --> G{Нужны низкие затраты и резервирование?}
G -->|Да, можно Spot| H[Fargate Spot]
G -->|Нет| CТипичные ошибки и как их избежать
- Разворачивание контейнера с отсутствующим health endpoint — тестируйте локально и добавляйте probe.
- Неправильные теги образов — используйте CI, который помечает и хранит релизные теги.
- Недостаточное тестирование автоскейла — имитируйте нагрузку и проверяйте поведение при росте/падении трафика.
Локальные рекомендации и совместимость для России
- Выбирайте регион AWS ближе к целевой аудитории для снижения задержки.
- Проверьте ограничения на экспорт/импорт данных и требования к хранению персональных данных в вашем регионе.
Короткое объявление для команды (100–200 слов)
Мы внедряем AWS ECS для запуска контейнеров: образы храним в ECR, разворачиваем через Task Definition и Service, предпочитаем Fargate для большинства сценариев из‑за простоты управления и автоматического масштабирования. DevOps подготовят CI‑pipeline для сборки и push образов в ECR; команда разработки проверит health endpoints и поведение приложений при рестартах. Для критичных сервисов настроим ALB, Health Check Grace Period и Target Tracking по CPU. Безопасность обеспечим с помощью минимальных IAM‑прав и хранения секретов в Secrets Manager. План отката и инструкция на случай инцидентов готовы — откат через предыдущую Task Definition.
Итог
ECS даёт простой путь вывести Docker‑приложение в AWS: ECR как приватный реестр, Task Definition для описания контейнеров и Service для управления жизненным циклом. Fargate уменьшает операционные затраты и ускоряет выход в прод, EC2 даёт полный контроль при специфичных требованиях. Планируйте единицы масштабирования, тестируйте health checks и используйте CI для автоматической сборки и развертывания.
Важно: перед продакшен‑релизом проведите нагрузочное тестирование, настройте мониторинг и убедитесь, что политики безопасности минимальны и корректны.
Похожие материалы

RDP: полный гид по настройке и безопасности

Android как клавиатура и трекпад для Windows

Советы и приёмы для работы с PDF

Calibration в Lightroom Classic: как и когда использовать

Отключить Siri Suggestions на iPhone
