Как диагностировать и устранить заторы в сети

Введение
Технологии сделали доступ в Интернет массовым. Но без управления сеть может стать перегруженной. Представьте сеть как город, а подключённые устройства — как автомобили. Если улицы узкие или контроль трафика отсутствует, образуются пробки.
Сетевые заторы — одна из самых сложных проблем для администратора сети. Простого «волшебного» решения нет: нужна системная диагностика и управление.
Этот материал даёт практическое руководство для пользователей и администраторов: как распознать перегрузку, как её проверить и устранить, какие инструменты и методики применять, а также чек‑листы и план действий при инциденте.
Что такое сетевой затор
Сетевой затор — это состояние, при котором входящий и исходящий трафик превышает доступные ресурсы канала, интерфейса или оборудования в узле сети. Обычно проявляется как:
- высокая задержка (latency);
- потеря пакетов (packet loss);
- тайм‑ауты соединений;
- колебания пропускной способности (jitter).
Коротко: когда число активных потоков или их объём превышают возможности сети, пакеты откладываются в очереди и часть из них отбрасывается.
Важно: затор может быть временным (например, «час пик») или постоянным при неправильном проектировании сети.
Частые признаки перегрузки
- Увеличение ping и нестабильность времени отклика.
- Тайм‑ауты при загрузке веб‑страниц, стримов или во время звонков.
- Высокий CPU на маршрутизаторах/коммутаторах.
- «Штормы» широковещательного трафика.
- Необычная активность — возможные атаки или несанкционированный трафик.
- Ограничение со стороны провайдера (throttling).
Основные причины заторов
- Слишком много подключённых устройств на одном сегменте.
- Отдельные устройства потребляют чрезмерный объём трафика (torrent, массовые загрузки, резервное копирование).
- Старое или медленное оборудование (сетевые адаптеры, роутеры, кабели).
- Неправильно спроектированные подсети и VLAN.
- Оверхэд подписок и перегрузка магистралей (oversubscription).
- Злонамеренные действия: DDoS, ботнеты, сканирование портов.
- Тариф провайдера, не соответствующий требованиям нагрузки.
Как понять, что именно перегружено
Ключ — разделить проблему по уровням: пользовательский узел, локальная сеть (LAN), абонентский канал у провайдера или удалённый сервер. Диагностика начинается локально и идёт к внешним точкам.
Быстрая проверка от пользователя
- Перезагрузите клиентское устройство и домашний роутер — иногда это освобождает очереди.
- Отключите устройства, которые активно грузят сеть (торренты, облачные бэкапы).
- Попробуйте подключиться по кабелю, а не по Wi‑Fi, чтобы исключить радиопомехи.
- Выполните базовые команды диагностики (см. ниже).
Как проверить сеть на наличие заторов
Ниже — набор команд и инструментов с описанием, интерпретацией результатов и советами.
Windows: базовый сценарий
- Нажмите клавишу Win.
- Введите CMD, правой кнопкой мыши откройте Командную строку и выберите Запуск от имени администратора.
- В окне CMD выполните:
tracert google.com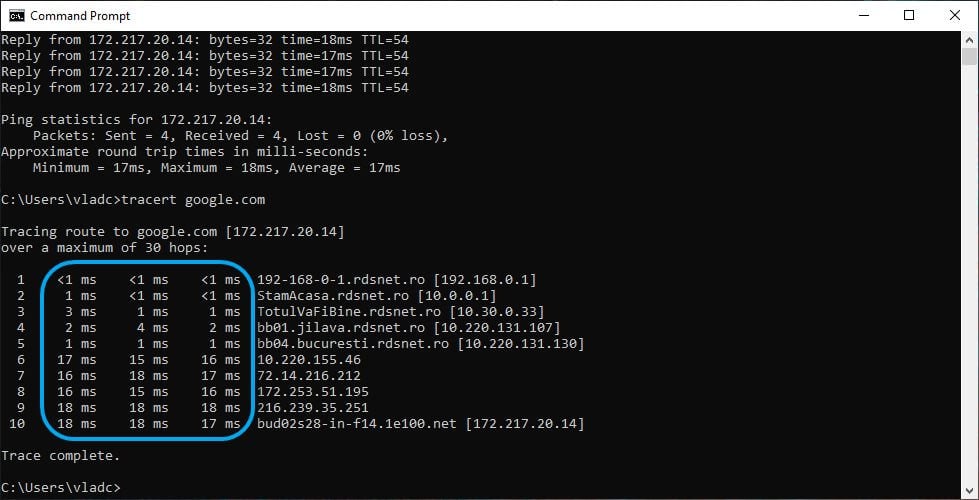
- Посмотрите число хопов и задержки для каждого промежуточного узла.
- Обратите внимание на сегмент, где задержка резко возрастает или появляются звёздочки (пакеты не возвращаются).
Интерпретация: если задержка резко увеличивается на первом‑втором хопе — проблема локальная. Если на другом узле по пути — проблема у провайдера или в дальнем сегменте.
Ping
ping -n 50 8.8.8.8Проверяйте процент потерь и среднее время отклика. Регулярные потери >1% и скачки RTT свидетельствуют о проблемах.
pathping и mtr
- Windows: pathping <адрес> — комбинирует tracert и ping, показывает потерю пакетов на каждом хопе.
- Linux/macOS: mtr <адрес> — интерактивный инструмент, объединяющий трассировку и измерение потерь.
Эти инструменты помогают локализовать сегмент с потерями.
Netstat, ss, iftop, nload
- netstat / ss — показывают активные соединения и порты.
- iftop, nload — в реальном времени показывают потоковую загрузку интерфейсов.
Сниффер: Wireshark
Wireshark помогает поймать паттерны трафика: широковещательные пакеты, повторные передачи (retransmissions), высокие RTT для TCP. Анализируйте по времени и источнику.
Интерпретация результатов
- Если потеря пакетов и задержка наблюдаются только на локальном интерфейсе — проверьте кабели, порт коммутатора, дровера NIC.
- Если проблемы начинаются на граничном роутере/модеме — проверьте конфигурацию, CPU/память на устройстве и очереди (queue lengths).
- Если хопы провайдера показывают высокую потерю — обратитесь к провайдеру и приложите результаты pathping/mtr.
Алгоритм поиска и устранения (мини‑методология)
- Собираем данные: ping/tracert/pathping/mtr, мониторинг интерфейсов, логи.
- Локализуем сегмент с проблемой.
- Выявляем причину: перегрузка устройств, устаревшее оборудование, некорректные настройки, атака.
- Применяем временную меру: приоритезация, отключение «тяжёлого» трафика, фильтры.
- Внедряем устойчивое решение: QoS, апгрейд, сегментация, смена тарифа, работа с провайдером.
- Верифицируем: повторный запуск измерений, тесты нагрузки.
Практические способы устранения заторов
- Мониторинг трафика и оповещения о порогах.
- Сегментация сети на VLAN и подсети.
- Настройка QoS: приоритезируйте голоса (VoIP), критичные сервисы.
- Использование очередей (queuing) и алгоритмов планирования (CBWFQ, HTB, fq_codel).
- Ограничение скорости (traffic shaping) и политика полицейинга.
- Использование CDN для контента с высокой нагрузкой.
- Апгрейд канала у провайдера и сетевого оборудования.
- Замена кабелей и сетевых карт на более производительные.
- Регулярное обновление прошивок и исправление уязвимостей.
- При DDoS — включение фильтрации, blackholing, работа с провайдером и специализированными сервисами.
Важно: VPN может помочь, если провайдер целенаправленно ограничивает трафик по портам/сервисам. VPN шифрует трафик и скрывает конечные порты, но не увеличивает физическую пропускную способность канала.
Когда VPN не поможет
- Если канал физически перегружен (полоса пропускания исчерпана), VPN не увеличит доступную ёмкость.
- Если задержки происходят за пределами туннеля (например, на пути к удалённому серверу), VPN может даже добавить оверхед.
- При DDoS на локальный маршрутизатор VPN не защитит ваш граничный интерфейс.
Практические приёмы и команды для продвинутых администраторов
- На маршрутизаторах Cisco/Juniper: анализ queue‑length, buffer usage, CPU/Memory, NetFlow/sFlow для долгосрочного анализа трафика.
- Используйте NetFlow/IPFIX или sFlow для сбора потоковых данных и определения «тяжёлых» источников.
- Применяйте ACL и фильтры на границе сети для блокировки нежелательного трафика.
- Для Wi‑Fi: проверьте уровень помех, перекрытие каналов, и переключитесь на 5 GHz, если возможно.
Чек‑лист для разных ролей
Чек‑лист для обычного пользователя:
- Перезагрузите устройства и роутер.
- Подключитесь по кабелю.
- Отключите приложения, активно использующие сеть.
- Выполните ping и tracert к публичным адресам.
- Свяжитесь с администратором/провайдером, если проблема повторяется.
Чек‑лист для домашнего администратора:
- Проверьте загрузку интерфейсов (iftop, nload).
- Обновите прошивку роутера.
- Ограничьте скорость отдельных устройств (если роутер поддерживает).
- Внедрите VLAN для IoT и гостевых устройств.
Чек‑лист для корпоративного администратора:
- Проанализируйте NetFlow/sFlow за 7–30 дней.
- Настройте QoS для критичных сервисов.
- Пересмотрите топологию и oversubscription на агрегационных линках.
- Внедрите мониторинг и оповещения (SLI/SLO для критичных сервисов).
SOP — стандартный план действий при инциденте перегрузки
- Идентификация: сбор метрик (ping, tracert, pathping, NetFlow).
- Локализация: определить узел/хоп с повышенной потерей.
- Митигирование: временно ограничить тяжёлые потоки, включить фильтры, приоритезировать голос.
- Исправление: апгрейд каналов, пересечение подсетей, изменение политик QoS.
- Верификация: повторный мониторинг и отчёт.
- Пост‑инцидентный разбор: запись причин, план улучшений.
Критерии приёмки
- RTT стабильно в пределах допустимых значений для сервиса (зависит от SLA).
- Потеря пакетов сведена к минимуму (обычно <1% для стабильных сервисов).
- Нет массовых рестартов сетевого оборудования.
- Нагрузка CPU на маршрутизаторах/коммутаторах в норме.
Тест‑кейсы и критерии приёма
Тест кейс 1 — Базовая нагрузка
- Действие: запустить 10 одновременных загрузок с серверов CDN и измерить RTT и packet loss.
- Критерий приёма: без существенной деградации для приоритетных приложений.
Тест кейс 2 — Имитировать пиковую нагрузку
- Действие: смоделировать одновременные резервные копирования и видеоконференции.
- Критерий приёма: голос должен иметь приоритет и оставаться качественным.
Факт‑бокс — ориентиры и эвристики
- Потеря пакетов от 0.5–1% может уже заметно влиять на интерактивные приложения.
- Jitter выше 30 ms влияет на качество VoIP.
- RTT для локальных сервисов обычно <20 ms; для межрегиональных — зависит от географии.
(Это общие эвристики; точные пороги зависят от требований конкретного приложения.)
Модели мышления и практические правила
- Разделяйте уровни ответственности: устройство — LAN — абонентский канал — внешний путь.
- Думайте «узкое место» — у какого ресурса ограничена ёмкость.
- Прежде чем апгрейдить канал, убедитесь, что оборудование и конфигурация не являются причиной.
Когда методы не сработают — частые контрпримерые ситуации
- Если у провайдера физический дефект магистрали — локальные настройки не помогут.
- При целевых DDoS атаках без поддержки провайдера и анти‑DDoS сервиса — локальные решения ограничены.
- Если источником проблем является внешний сервис (его перегрузка) — вы мало что можете сделать, кроме обходных путей.
Безопасность и конфиденциальность
- При использовании VPN учтите: VPN скрывает содержимое, но не увеличивает физическую пропускную способность.
- Применяйте правильные политики аутентификации и сегментации, чтобы ограничивать доступ заражённых устройств.
Пример инцидентного плана для DDoS
- Обнаружение: резкий рост трафика, много SYN/UDP пакетов.
- Включение фильтров на граничных ACL; перенаправление трафика к провайдеру.
- Связь с провайдером и включение гео/сервис‑фильтров.
- В долгосрочной перспективе — использование анти‑DDoS сервиса и планы эластичности.
Инструменты и ресурсы
- ping, tracert/pathping, mtr
- NetFlow/IPFIX, sFlow
- iftop, nload, bmon
- Wireshark
- Системы мониторинга (Prometheus, Grafana, Zabbix и др.)
- CDN и анти‑DDoS сервисы
Примеры реальных настроек (шаблон)
Таблица базовых настроек для QoS (пример для домашнего роутера):
- Высокий приоритет: VoIP, видеоконференции
- Средний приоритет: веб‑сёрфинг, облачные приложения
- Низкий приоритет: торренты, P2P, PVR backups
Рекомендуется реализовать rate‑limit для устройств, которые регулярно создают пик нагрузки.
Решение типичных проблем: пошагово
- Проверьте локальные устройства. Отключите «тяжёлые» клиенты.
- Соберите данные (ping, tracert, iftop, NetFlow).
- Найдите узел с высокой потерей/задержкой.
- Если узел внутри вашей сети — проверьте порт, кабель, скорость интерфейса.
- Если узел у провайдера — свяжитесь с техподдержкой, приложите логи и результаты pathping/mtr.
- Внедрите изменения: QoS, сегментация, апгрейд линии.
- Мониторьте и автоматизируйте оповещения.
Краткая сводка и рекомендации
- Начинайте с простых проверок: кабели, перезагрузки, отключение тяжёлых клиентов.
- Используйте pathping/mtr для локализации проблем на пути.
- Внедряйте QoS и сегментацию, прежде чем сразу покупать более дорогой канал.
- При DDoS и проблемах на уровне провайдера — действуйте совместно с провайдером.
Важно: системный подход и мониторинг — ключ к тому, чтобы заторы были предсказуемыми и управляемыми.
Короткий словарь терминов
- Задержка (latency): время, за которое пакет достигает получателя.
- Потеря пакетов (packet loss): пакеты, не доставленные в конечную точку.
- QoS: приоритезация сетевого трафика.
- Oversubscription: ситуация, когда общая подписанная пропускная способность превышает физическую.
Если вам нужно, я подготовлю:
- диаграмму действий (Mermaid) для быстрой маршрутизации диагностики;
- готовые команды для Cisco/Juniper;
- шаблон отчёта для обращения к провайдеру.
Похожие материалы

RDP: полный гид по настройке и безопасности

Android как клавиатура и трекпад для Windows

Советы и приёмы для работы с PDF

Calibration в Lightroom Classic: как и когда использовать

Отключить Siri Suggestions на iPhone
