Как профилировать память в Python: инструменты, приёмы и шаблоны

Кратко
Python предоставляет несколько способов измерить и оптимизировать использование памяти. В статье объяснено, когда применять sys.getsizeof, memory_profiler, psutil и mprof, приведены практические сценарии, пошаговые методики и чек-листы для разработчиков и SRE.
Введение
Из-за принципа «есть более одного способа сделать это» в Python иногда трудно выбрать самый экономный по памяти подход. Профилировщик памяти помогает оценить потребление, найти утечки и определить, какие участки кода требуют оптимизации.
Это полезно как для задач машинного обучения с большими объёмами данных, так и для веб-приложений: можно оценивать память для скриптов, отдельных строк кода или функций.
Основная цель статьи
Показать практические инструменты и приёмы для оценки и улучшения использования оперативной памяти в Python-проектах. В тексте — инструменты, примеры кода, рекомендации по методике профилирования, чек-листы, сценарии отказа и альтернативы.
Некоторые инструменты для оценки профиля памяти в Python
Оценивать профиль памяти для всего кода целиком часто непрактично: профилирование замедляет приложение. Чаще профилируют выборочно — функции или методы, которые кажутся подозрительно «жадными» по памяти. При необходимости можно выделить отдельный модуль для профилирования.
Популярные библиотеки: memory_profiler, psutil, tracemalloc и pympler. В этом руководстве используются memory_profiler и psutil.
- psutil — удобно измерять общее потребление процесса во время выполнения метода или функции.
- memory_profiler — даёт подробную разбивку по строкам и позволяет видеть, какие строки увеличивают или уменьшают использование памяти.
Установка (в виртуальном окружении):
pip install memory_profilerПри установке memory_profiler часто подтягивается psutil.
Узнать размер объекта в памяти (sys.getsizeof)
В начале разработки полезно сравнивать размеры типов объектов, чтобы выбрать более лёгкий вариант для вашей задачи. Для этого используйте встроенную функцию sys.getsizeof — она возвращает размер самого объекта в байтах, но не учитывает объекты, на которые он ссылается.
Пример кода:
import sys
print(f"list size: {sys.getsizeof([])} bytes")
print(f"dictionary size: {sys.getsizeof(dict)} bytes")
print(f"tuple size: {sys.getsizeof(())} bytes")
print(f"set size: {sys.getsizeof({})} bytes")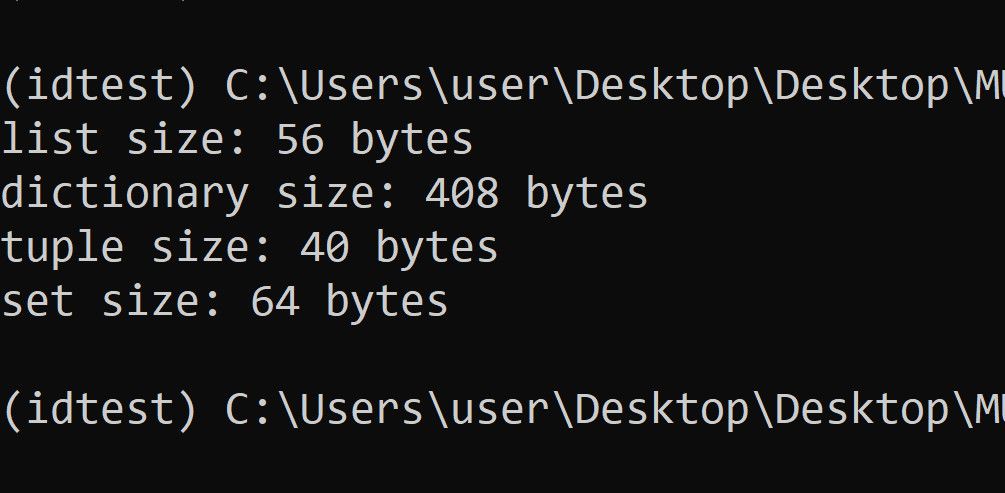
sys.getsizeof применим и для сравнения функций (объект функции тоже занимает место):
import sys
def getLength(iterable):
count = 0
for i in iterable:
count +=1
return count
print(f"Built-in length function: {sys.getsizeof(len)} bytes")
print(f"Custom length function: {sys.getsizeof(getLength)} bytes")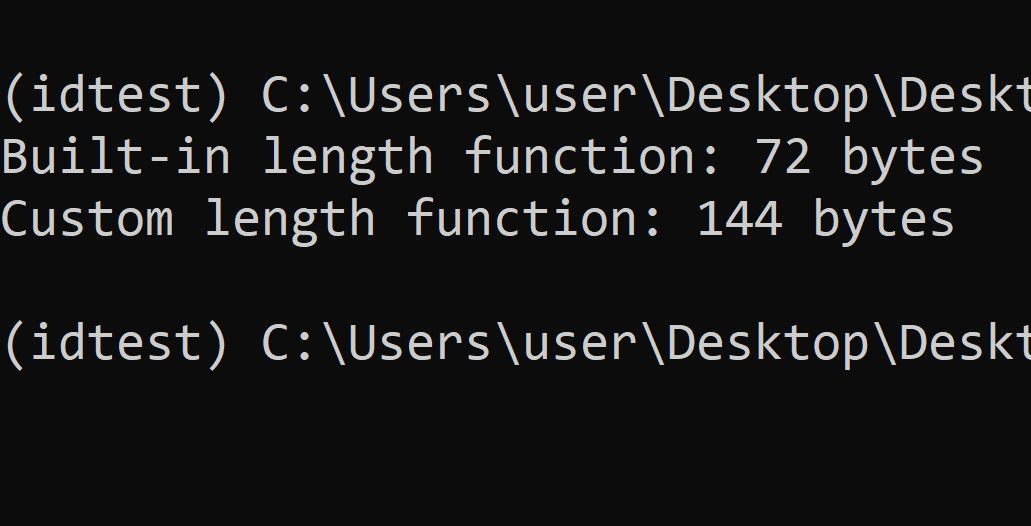
Важно: sys.getsizeof возвращает размер только самого объекта. Если объект содержит ссылки на другие объекты (например, список с элементами), их объём в общий результат не включается. Для более полной картины используйте профайлеры, которые анализируют граф ссылок.
Подсказки: когда sys.getsizeof не подходит
- Для контейнеров с вложенными объектами (список списков, объекты с атрибутами) — не отражает все вложенные объекты.
- Для оценки оперативной памяти процесса в целом — нужен psutil или tracemalloc.
Профилирование функции по строкам с memory_profiler
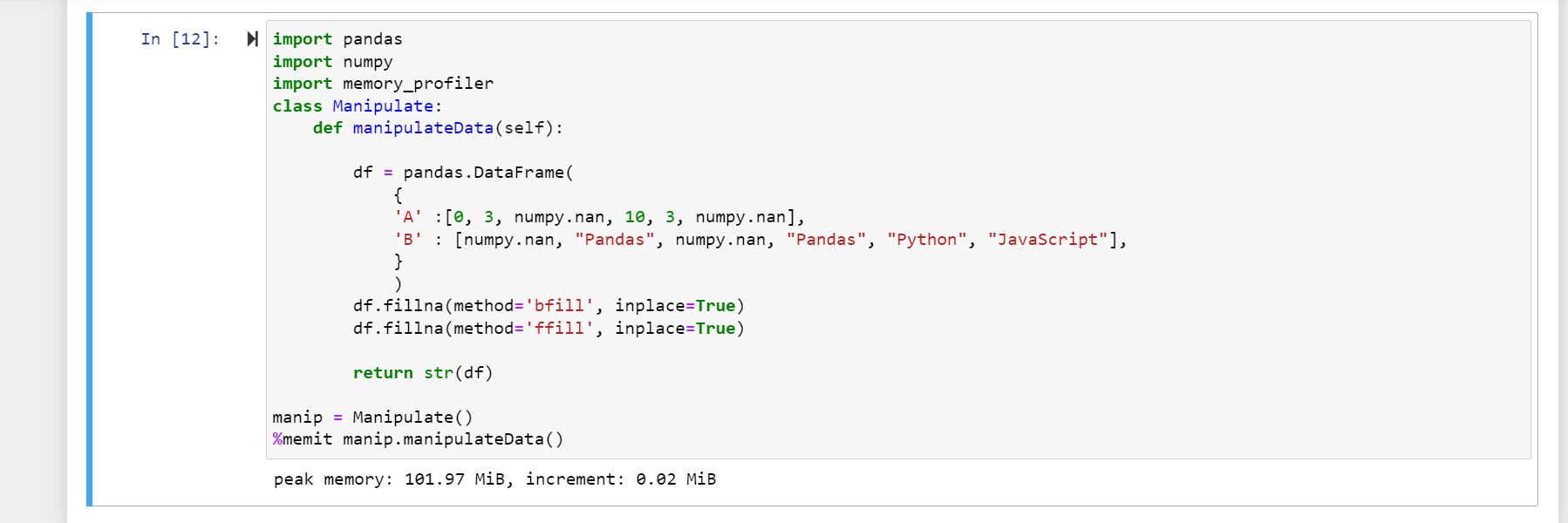
memory_profiler даёт подробный отчёт по каждой строке функции при декорировании её профайлером @profile.
Пример (сохраните в файл и запустите через python, если используете декоратор @profile, требуется запуск через python -m memory_profiler или использование mprof):
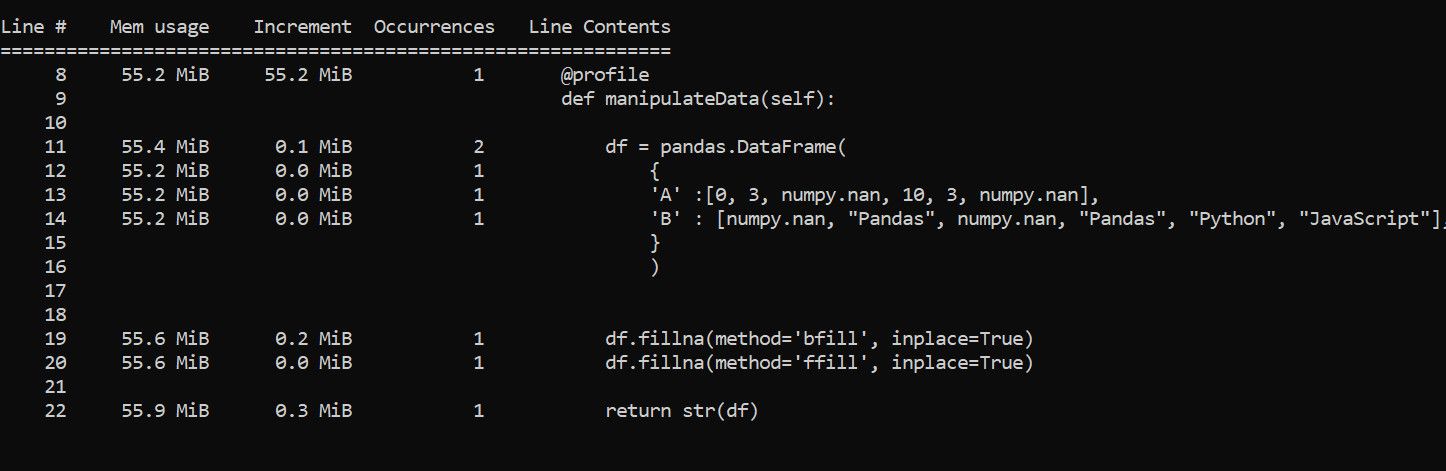
import pandas
import numpy
from memory_profiler import profile
class Manipulate:
@profile
def manipulateData(self):
df = pandas.DataFrame({
'A' :[0, 3, numpy.nan, 10, 3, numpy.nan],
'B' : [numpy.nan, "Pandas", numpy.nan, "Pandas", "Python", "JavaScript"],
})
df.fillna(method='bfill', inplace=True)
df.fillna(method='ffill', inplace=True)
return str(df)
manip = Manipulate()
print(manip.manipulateData())В отчёте столбец Mem usage показывает значение памяти в конкретный момент, Increment — вклад строки, Occurrence — сколько раз строка выделяла или освобождала память.
Совет по использованию: профилируйте небольшие фрагменты — иначе вывод будет громоздким.
Профилирование скрипта по времени: mprof
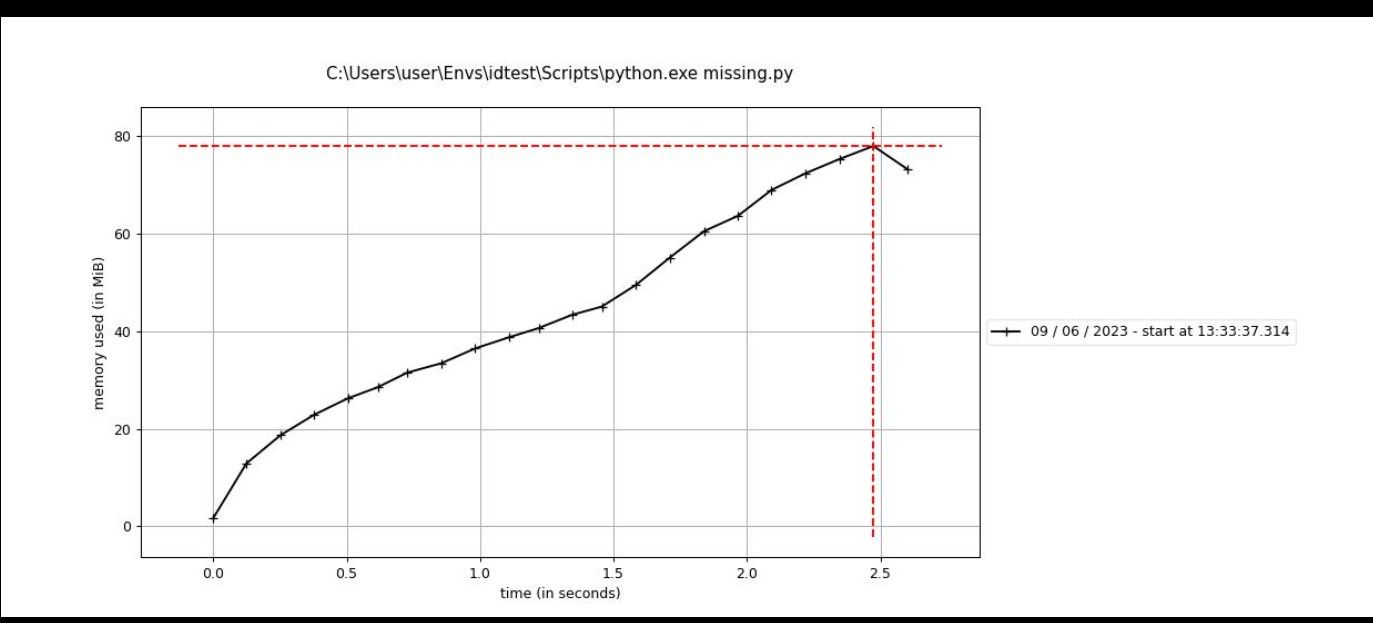
mprof (часть memory_profiler) запускает скрипт и снимает замеры в заданный интервал (по умолчанию 0.1 с). Команда:
mprof run script_name.pyПосле запуска создаётся файл .dat с выборками памяти. Вы можете построить график — для этого потребуется matplotlib:
pip install matplotlib
mprof plot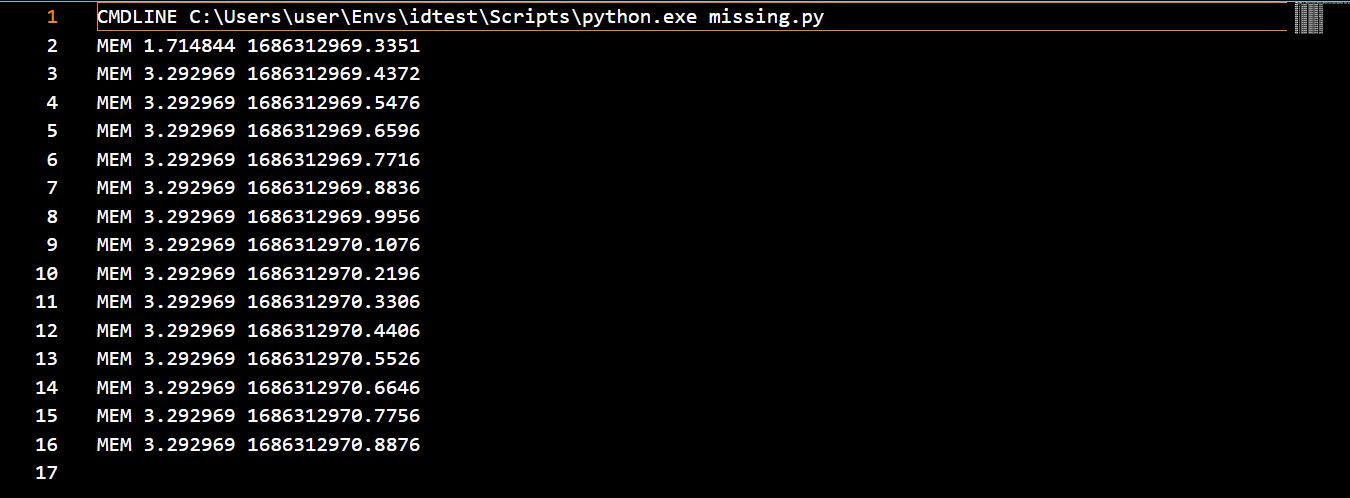
График показывает профиль использования памяти по времени; ось X — время, справа отображены метки времени снятия замеров.
Запуск профилирования скрипта из отдельного Python-файла
Если вы хотите отделить профайлер от основной кодовой базы и сохранять графики локально:
import subprocess
subprocess.run([
'mprof', 'run', '--include-children', 'missing.py'
])
# save the plot output locally
subprocess.run(['mprof', 'plot', '--output=output.jpg'])Это полезно, когда нужно профилировать разнообразные скрипты автоматически, собирать результаты и архивировать графики.
Измерить объём памяти, использованный во время выполнения функции (psutil)
psutil позволяет измерять реальное использование памяти процессом до и после выполнения функции.
import psutil
import sys
import os
sys.path.append(sys.path[0] + "/..")
# import the class containing your method
from somecode.missing import Manipulate
# instantiate the class
manip = Manipulate()
process = psutil.Process(os.getpid())
initial_memory = process.memory_info().rss
# run the target method:
manip.manipulateData()
# get the memory information after execution
final_memory = process.memory_info().rss
memory_consumed = final_memory - initial_memory
memory_consumed_mb = memory_consumed / (1024 * 1024)
print(f"Memory consumed by the function: {memory_consumed_mb:.2f} MB")Этот подход оценивает совокупный прирост RSS процесса, связанный с выполнением метода.
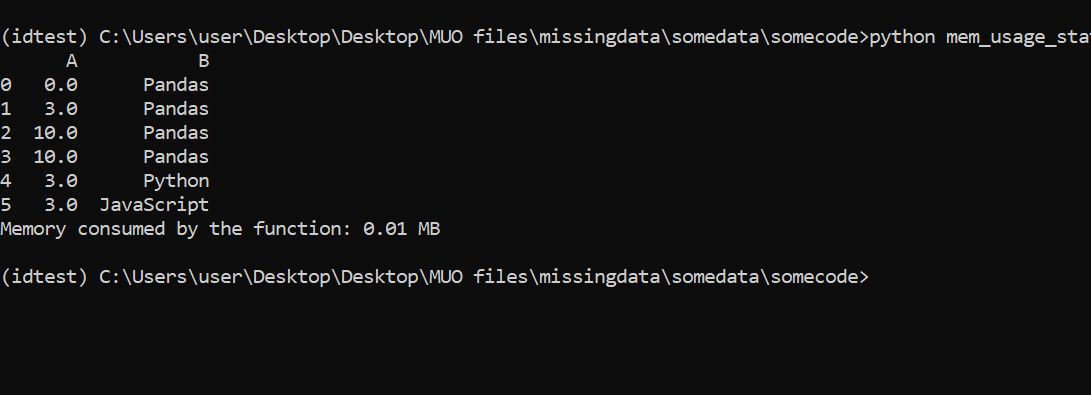
Примечание: если внутри метода создаются побочные фоновые процессы или потоки, используйте параметр include_children для mprof или дополнительно измеряйте дочерние процессы в psutil.
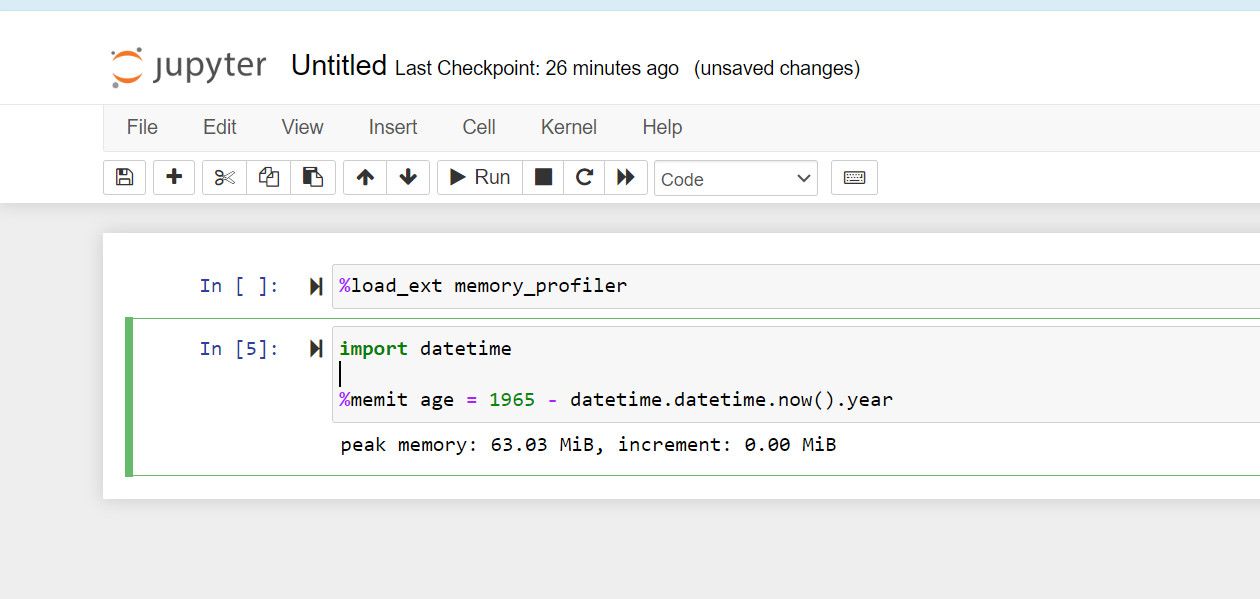
Профилирование отдельной строки в Jupyter (магия %memit)
В Jupyter/IPython можно применять расширение memory_profiler и магию %memit для быстрого измерения пика памяти и увеличения объёма для одной строки:
- Загрузите расширение в отдельной ячейке (например,
%load_ext memory_profiler). - В последующих ячейках используйте
%memit some_expression.
Этот способ удобен для интерактивного анализа, но не работает в обычных скриптах вне iPython.
Практические рекомендации по повышению эффективности памяти в Python
Оптимизация памяти — это системная работа: как при проектировании алгоритма, так и при отладке:
- Избегайте ненужных копий больших структур (np.copy, list(slice) и т. п.).
- Используйте генераторы и итераторы вместо списков там, где возможно (range, generator expressions).
- Для больших табличных данных рассматривайте dtype в pandas (категориальные колонки, downcasting чисел).
- Освобождайте ресурсы явно (close, del, context managers) и контролируйте ссылки — циклические ссылки усложняют своевременную сборку мусора.
- Для временных больших объектов используйте модуль gc для отладки (gc.collect(), gc.get_referrers).
Важно: не все «оптимизации ради памяти» оправданы — иногда стоимость CPU или читаемости важнее небольшой экономии RAM.
Методика профилирования: быстрый чек-лист (мини-SOP)
- Определите подозрительные участки: большие входные данные, долгие операции, всплески использования памяти в графиках.
- Локализуйте проблему: профилируйте конкретные функции по строкам (memory_profiler) или снимите общий график (mprof).
- Повторяйте тесты с различными размерами входных данных (малый, средний, большой).
- Сравните варианты реализации (например, list vs generator, object dtype vs category).
- Внедрите мониторинг в окружение (процесс-метрики) и установите SLI/SLO на использование памяти для production.
Чек-листы по ролям
Для разработчика
- Профилируй локально функции с @profile.
- Используй %memit для быстрых проверок в Jupyter.
- Сравни варианты типов данных и структур.
- Добавь unit-тесты, проверяющие, что peak memory не растёт при фиксированном объёме входа.
Для SRE/инженера по наблюдаемости
- Мониторь RSS и OOM-кандидатов на проде.
- Автоматически собирай mprof-дампы для долгоживущих инцидентов.
- Настрой алерты по аномалиям использования памяти.
Шаблон критериев приёмки для оптимизации по памяти
- Функция с тестовыми входными данными размера X использует максимум не более Y MB (график mprof показывает стабильную линию).
- Внедрённый вариант не ухудшил время выполнения более чем на Z% (если затраты CPU критичны).
- Нет регрессий в функциональности по существующим тестам.
(Задайте X, Y, Z согласно требованиям продукта и доступной инфраструктуре.)
Ментальные модели и эвристики
- «Большой объект — подозрительно»: чаще всего проблема именно в крупных контейнерах.
- «Копировать — дорого»: если вы создаёте копию данных при каждой итерации, это сигнал к рефакторингу.
- «Профилировать реальное поведение»: синтетические микротесты полезны, но проблемы часто проявляются на продовых объёмах.
Когда предложенные инструменты не подойдут (контрпримеры)
- Встроенные средства не покажут детальную картину в многопроцессном окружении без include-children.
- Если код сильно асинхронен и использует C-расширения, memory_profiler может не увидеть выделения в C-слое — нужен tracemalloc или инструменты для нативной части.
Альтернативные подходы
- tracemalloc — для отслеживания распределений памяти и стек-трейсов распределений (хорош для поиска «кто» выделил память).
- pympler — для детального анализа объектов в памяти и графа ссылок.
- Профайлеры нативного слоя (valgrind massif, tools для C/C++) — если проблема в C-расширениях.
Decision tree: как выбрать инструмент (Mermaid)
flowchart TD
A[Нужно измерить память?] --> B{Проблема локальна или глобальна?}
B -->|Локальна: одна функция/строка| C[memory_profiler / %memit]
B -->|Глобальна: процесс/скрипт| D[psutil или mprof]
D --> E{Есть C-расширения?}
E -->|Да| F[tracemalloc или нативные инструменты]
E -->|Нет| G[mprof + matplotlib]
C --> H[Использовать @profile и анализировать increment]
G --> I[Сохранить .dat, построить plot]Факты и числа (коротко)
- mprof по умолчанию снимает замеры каждые 0.1 секунды.
- psutil предоставляет RSS (Resident Set Size) и другие метрики процесса.
- sys.getsizeof измеряет размер объекта в байтах, не включая объекты по ссылке.
Тестовые сценарии и критерии приёмки
- Тест 1: Малые данные — функция должна потреблять < 50 MB.
- Тест 2: Увеличение данных в 10× не должно увеличивать память более чем пропорционально (проверка линейности).
- Тест 3: Отсутствие утечки при многократных вызовах (память возвращается к базовому уровню).
(Конкретные пороговые значения задаёт команда в зависимости от окружения.)
Безопасность и приватность
При профилировании убедитесь, что логи и дампы памяти не содержат чувствительных данных (PII). Если профилирование собирается автоматически, примените маскирование и ограничьте доступ к результатам.
Глоссарий (1 строка каждая)
- RSS — объём физической памяти, занимаемой процессом.
- Heap — область памяти для динамически выделяемых объектов.
- Garbage collector — механизм сборки неиспользуемых объектов.
Заключение и практические шаги
- Начинайте с локального профилирования подозрительных функций (memory_profiler, %memit).
- Для оценки эффекта на весь процесс используйте psutil и mprof.
- Сравнивайте варианты реализации и проверяйте изменения на наборах данных разного размера.
- Автоматизируйте сбор метрик и интегрируйте базовые SLI по памяти на проде.
Важно: оптимизация памяти — это компромисс между памятью, CPU и читаемостью кода. Оценивайте эффект комплексно.
Сводка
- Профилируйте выборочно и по очереди: строка → функция → процесс.
- memory_profiler и mprof хороши для анализа Python-кода; psutil — для измерения процесса.
- sys.getsizeof полезен для быстрой оценки, но не отражает вложенные объекты.
Спасибо за внимание — используйте профиль памяти как часть стандартного цикла разработки и мониторинга.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
