Распознавание автомобильных номерных знаков на Python
https://static0.makeuseofimages.com/wordpress/wp-content/uploads/2023/01/license-plate-detection-featured-image.jpegLicense plate detection and recognition technology has many applications. It can be used in road systems, ticketless parking lots, vehicle access control residences, and more. This technology combines computer vision and Artificial Intelligence.You will use Python to create a license plate detection and recognition program. The program will take the input image, process it to detect and recognize the license plate, and finally display the characters of the license plate as the output.
Краткое описание задачи
Задача состоит из трёх этапов: 1) детекция области с номерным знаком на изображении, 2) предобработка и выделение этой области, 3) оптическое распознавание символов (OCR). Здесь используется классический подход: OpenCV для детекции и предобработки, Tesseract (через pytesseract) для распознавания.
Определения в одну строку:
- Детекция — нахождение региона изображения, где находится номер.
- OCR — преобразование изображения символов в текст.
Что вам понадобится
- Python (3.6+ рекомендовано).
- pip для установки пакетов.
- Библиотеки: OpenCV (cv2), imutils, pytesseract.
- Установленный движок Tesseract OCR на машине.
Выполните в терминале:
pip install opencv-python imutils pytesseractВажно: pytesseract — это только обёртка. Нужен установленный Tesseract OCR.
Как установить Tesseract OCR
Коротко:
- Windows: скачайте установщик Tesseract и установите (по умолчанию путь “C:\Program Files\Tesseract-OCR\tesseract.exe”).
- Linux (Debian/Ubuntu): установите пакет tesseract-ocr через apt: sudo apt install tesseract-ocr.
- macOS: используйте Homebrew: brew install tesseract.
После установки убедитесь, что tesseract доступен из командной строки (tesseract –version) или укажите путь в коде (см. ниже).
Important: если вы будете распознавать неанглийские символы, установите соответствующие языковые пакеты (tessdata).
1. Импорт библиотек
Импортируем нужные модули и укажем путь к движку Tesseract (если требуется на Windows):
import cv2
import imutils
import pytesseract
# Для Windows укажите путь к исполняемому файлу Tesseract:
# pytesseract.pytesseract.tesseract_cmd = 'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'2. Загрузка входного изображения
Загрузите изображение автомобиля в ту же папку проекта или укажите полный путь.
original_image = cv2.imread('image3.jpeg')Проверьте, что original_image не равен None — иначе путь к файлу указан неверно.
3. Предобработка изображения
Нормальная последовательность действий:
- Изменить размер изображения для единообразия.
- Перевести в оттенки серого.
- Применить фильтрацию, чтобы снизить шум.
- Выполнить детектор границ Canny.
original_image = imutils.resize(original_image, width=500)
gray_image = cv2.cvtColor(original_image, cv2.COLOR_BGR2GRAY)
gray_image = cv2.bilateralFilter(gray_image, 11, 17, 17)
edged_image = cv2.Canny(gray_image, 30, 200)Пояснение: bilateralFilter хорошо сохраняет края при удалении шума, что помогает при последующей детекции контуров.
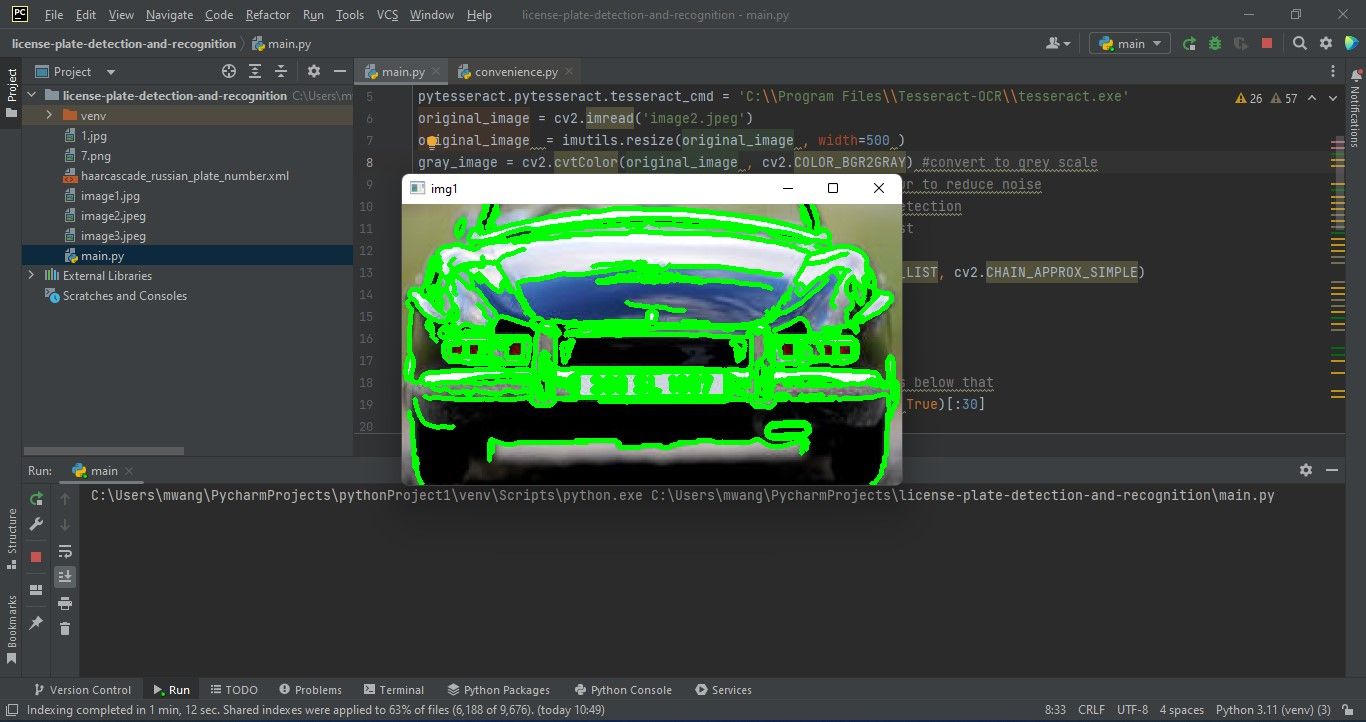
4. Поиск контуров и выделение кандидатов
- Найдём все контуры на изображении и нарисуем их для отладки.
contours, _ = cv2.findContours(edged_image.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
img1 = original_image.copy()
cv2.drawContours(img1, contours, -1, (0, 255, 0), 3)
cv2.imshow('img1', img1)- Отсортируем контуры по площади и оставим топ-30 кандидатов — это уменьшит набор для анализа.
contours = sorted(contours, key=cv2.contourArea, reverse=True)[:30]
img2 = original_image.copy()
cv2.drawContours(img2, contours, -1, (0, 255, 0), 3)
cv2.imshow('img2', img2)- В цикле ищем контур с четырьмя вершинами — прямоугольная форма часто соответствует номерному знаку.
screenCnt = None
idx = 7
for c in contours:
contour_perimeter = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.018 * contour_perimeter, True)
if len(approx) == 4:
screenCnt = approx
x, y, w, h = cv2.boundingRect(c)
new_img = original_image[y:y+h, x:x+w]
cv2.imwrite('./'+str(idx)+'.png', new_img)
idx += 1
break
cv2.drawContours(original_image, [screenCnt], -1, (0, 255, 0), 3)
cv2.imshow('detected license plate', original_image)Пояснение: порог 0.018 для approxPolyDP — эмпирическое значение. Его можно менять в зависимости от качества изображения.
5. Распознавание символов (OCR)
Загрузите сохранённый фрагмент номерного знака и передайте его в pytesseract.
cropped_License_Plate = './7.png'
cv2.imshow('cropped license plate', cv2.imread(cropped_License_Plate))
# Язык распознавания: 'eng' — английский. Для других языков укажите соответствующий код.
text = pytesseract.image_to_string(cropped_License_Plate, lang='eng')Дополнительные полезные параметры для pytesseract:
- config=’–psm 7’ — указать режим сегментации страницы, подходящий для одного слова/строки.
- config=’-c tessedit_char_whitelist=ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789’ — задать список допустимых символов.
Пример вызова с конфигом:
custom_config = r"--oem 3 --psm 7 -c tessedit_char_whitelist=ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
text = pytesseract.image_to_string(cv2.imread(cropped_License_Plate), config=custom_config)6. Вывод результата
Печать распознанного текста и завершение GUI-окон:
print('License plate is:', text)
cv2.waitKey(0)
cv2.destroyAllWindows()Распознанный текст будет выведен в терминал. Часто потребуется постобработка (фильтрация лишних символов, нормализация формата номера).
Отладка и типичные проблемы
- Ничего не распознаётся: проверьте путь к файлу, убедитесь, что Tesseract установлен и pytesseract знает путь.
- Неверные символы: используйте whitelist (разрешённые символы) и подходящий режим PSM.
- Размытые и мелкие номера: увеличьте разрешение исходного изображения или используйте алгоритмы супер-резолюции.
- Нестандартные шрифты и символы: потребуется дополнительная подготовка данных и, возможно, обучение модели.
Important: всегда добавляйте визуальную проверку (показывайте обрезанный фрагмент) — это помогает быстро понять, на каком этапе ошибка.
Альтернативные подходы и когда их использовать
- Обученные детекторы объектов (рекомендовано для промышленного применения):
- YOLOv5/YOLOv8, Faster R-CNN, SSD — надёжно обнаруживают номерные знаки в разных условиях. После детекции применяйте OCR.
- Текстовые детекторы + детекторы символов: EAST + CRNN для энд-ту-энд распознавания.
- Готовые сервисы и библиотеки: OpenALPR, commercial APIs — удобны, если не хотите заниматься моделью.
Когда классический OpenCV+Tesseract работает плохо:
- экстремальные углы съёмки;
- сильная засветка или дождь/снег;
- частичное закрытие номера.
В этих случаях лучше использовать нейросетевой детектор и/или данные аугментации при обучении.
Мини-методология (шаг за шагом для повторения и тестирования)
- Подготовьте набор фотографий с разными углами, освещением и разрешениями.
- Напишите pipeline: resize -> gray -> denoise -> edges -> findContours -> select -> crop -> enhance -> OCR.
- Для каждой стадии сохраняйте промежуточные изображения для отладки.
- Применяйте постобработку OCR-строк: удалить недопустимые символы и привести к формату.
- Сверьте результаты с эталоном и составьте матрицу ошибок (FP, FN, неправильные символы).
Критерии приёмки
- Детекция: >= 90% корректных привязок области номерного знака в тестовом наборе (визуальная проверка).
- Распознавание: средняя корректность распознавания символов >= 95% для хорошо читаемых снимков.
- Производительность: обработка одного изображения в пределах допустимого времени (зависит от требований проекта).
- Логи: система не хранит лишние персональные данные дольше, чем требуется.
(Примечание: конкретные пороги согласуйте с бизнес-требованиями и законодательством.)
Тестовые сценарии
- Классический дневной снимок, фронтально — должен распознать номер полностью.
- Наклонный снимок около 30° — проверить стабильность детекции.
- Малое разрешение (например, номер занимает <5% кадра) — протестировать отказ или частичное распознавание.
- Ночь и искусственное освещение — проверить чувствительность к отражениям.
- Частичное перекрытие (лист бумаги, грязь) — система должна пометить результат как ненадёжный.
Чек-листы по ролям
Разработчик:
- Установил зависимости и Tesseract.
- Создал пайплайн и проверил промежуточные изображения.
- Добавил конфиг для pytesseract с whitelist и psm.
Тестировщик:
- Подготовил набор тестовых изображений разных условий.
- Проверил метрики детекции и распознавания.
- Задокументировал кейсы провала.
DevOps / эксплуатация:
- Убедился, что двоичный файл tesseract доступен в контейнере или на сервере.
- Настроил ротацию логов и политику хранения распознанных номеров.
- Настроил мониторинг ошибок и времени обработки.
Шпаргалка и сниппеты
- Быстрые команды установки:
pip install opencv-python imutils pytesseract
# Linux: sudo apt install tesseract-ocr
# macOS: brew install tesseract- Настройка pytesseract в Windows:
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract.exe"- Частые опции:
- –oem 3 — нейросетевой движок Tesseract.
- –psm 7 — распознавание как одной строки.
- tessedit_char_whitelist — задать допустимые символы.
Конфиденциальность и правовые аспекты
Номерной знак — персональная информация в ряде юрисдикций. Рекомендации:
- Храните распознанные номера шифрованными.
- Ограничьте доступ к логам и результатам.
- Установите срок хранения и автоматическую очистку.
- Получите юридическую консультацию по требованиям локального законодательства.
Notes: сбор данных с видеонаблюдения и их хранение регулируются по-разному в разных странах. Следуйте действующим нормам.
Когда подход не сработает и что делать
- Если номера сильно деформированы или скрыты — примените нейросети для реконструкции или запросите лучшую камеру.
- При большом разнообразии форматов и шрифтов — соберите датасет и дообучите OCR-модель или используйте специализированные решения.
- Для реального времени на видеопотоках — используйте быстрые детекторы (YOLO) и оптимизированные OCR-пайплайны.
Короткий глоссарий
- OCR — оптическое распознавание символов.
- PSM — режим сегментации страницы в Tesseract.
- OEM — режим движка распознавания в Tesseract.
Резюме
- Классический pipeline OpenCV + Tesseract даёт рабочее решение для многих случаев и хорош для обучения.
- Для промышленного применения рассмотрите нейросетевые детекторы и специализированные OCR-решения.
- Тестируйте на репрезентативном наборе изображений и внедряйте меры безопасности и конфиденциальности.
Summary:
- Настройте окружение и установите Tesseract.
- Следуйте pipeline: resize → gray → denoise → edges → contours → crop → OCR.
- Используйте whitelist и psm для повышения качества OCR.
- Проверьте альтернативы, если классический подход не даёт нужной точности.
Спасибо за внимание. Практика и тестирование на реальных данных — ключ к стабильному решению.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
