Простая структура сайта на PHP

Если вы получите базовое понимание того, как строить сайт на PHP, вы научитесь работать с подключаемыми файлами и выводом — основам кастомизации веб-страницы. Возможно, вы не знаете, с чего начать, или какие следующие шаги предпринять, чтобы добавить функциональность сайту.
В этом руководстве представлена простая структура сайта, удобная для поддержки и обновлений. Одновременно показаны полезные функции на PHP, которые добавляют ценность и делают код гибче.
О чём этот примерный сайт
Примерный сайт (репозиторий доступен на GitHub) — это простой сайт о птицах. На нём есть несколько разделов, информационные страницы и главная страница. Важно не столько содержание, сколько используемые приёмы и идеи, которые могут вас вдохновить.
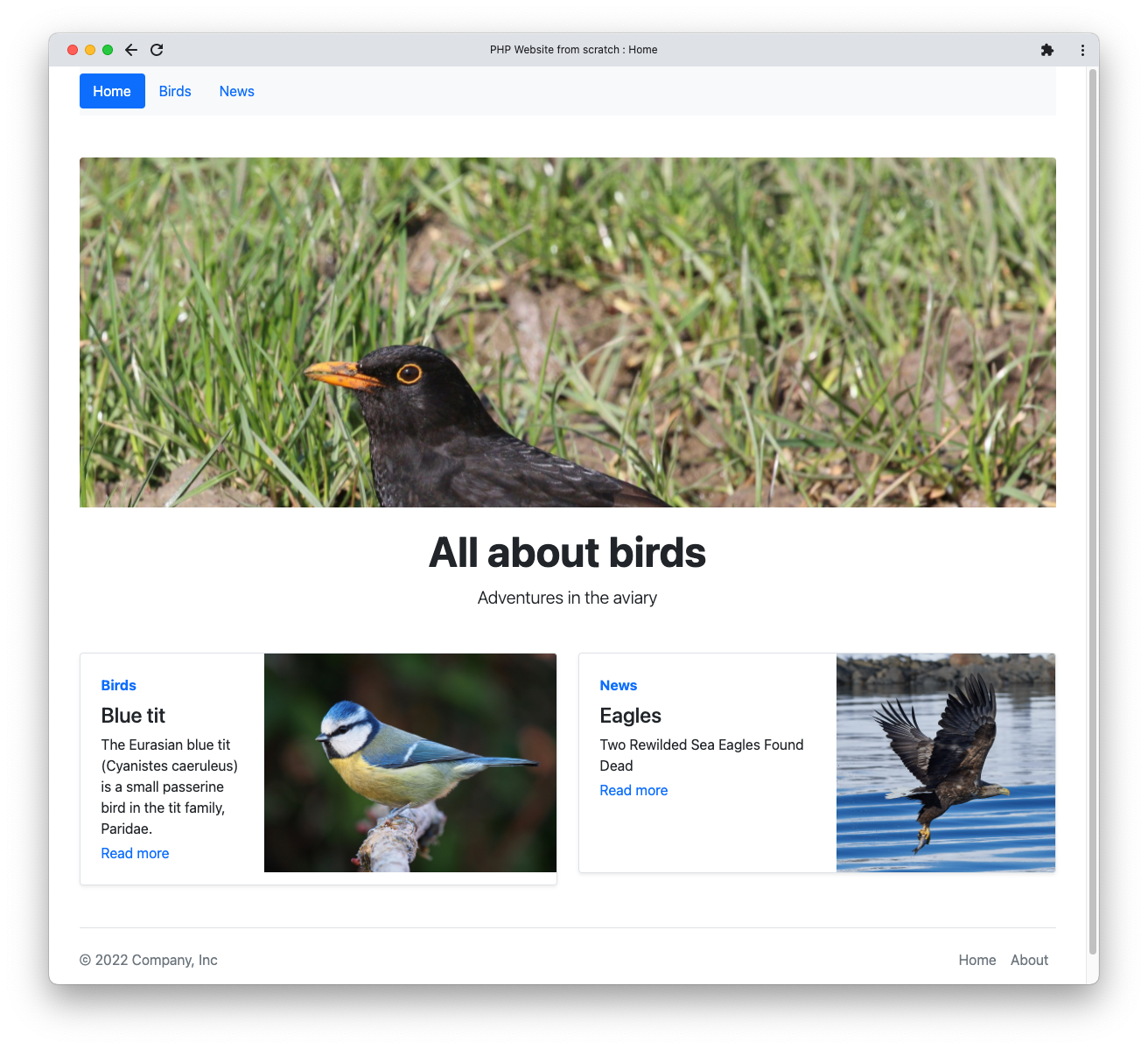
Если можете, скачайте проект с GitHub и запустите его локально перед чтением дальше.
Общая структура проекта
Ниже перечислены ключевые файлы и каталоги, которые стоит изучить:
composer.json
data/
funcs.php
md/
site/
index.php
tpl/- Каждая страница представлена PHP-скриптом в каталоге site. Такое решение даёт небольшую дубликацию, но упрощает понимание и развёртывание. При настройке веб-сервера укажите DOCROOT на директорию site.
- В каталоге md хранятся исходники в Markdown для контента отдельных страниц.
- В tpl находятся шаблоны и фрагменты HTML, которые разделяют общую структуру между страницами.
- Основная логика — в funcs.php.
Связанная публикация: Как настроить собственный WAMP-сервер
Как работает сайт
Bootstrap
Bootstrap — фронтенд-фреймворк для быстрого создания сайтов. Он содержит набор стилей и JavaScript для большинства распространённых задач. Это быстрый способ привести сайт в рабочее состояние, прежде чем тратить время на тонкую настройку дизайна.
Можно хранить файлы Bootstrap локально или подключать их с CDN для ускорения. В файле tpl/head.php приведён пример подключения через CDN:
Важно: CDN ускоряет доставку, но требует доверия к сторонним узлам. Для внутренних сетей или проектов с повышенными требованиями к приватности стоит хранить ресурсы локально.
Базовое шаблонирование
Начните с site/index.php — файл представляет собой домашнюю страницу. В зависимости от настроек сервера её можно открыть по адресу http://yoursite.example.org/ или http://yoursite.example.org/index.php.
В начале файла встречаются два include: funcs.php и TPL_DIR.”/home.php”. В funcs.php определяется константа TPL_DIR как абсолютный путь к каталогу tpl.
Посмотрите на tpl/home.php — это внешний каркас HTML-документа: он включает doctype и открывающий элемент HTML, а внутри подключает шаблоны для head и body.
Для раздела птиц используется другой body-шаблон — tpl/birds/body.tpl, который имеет иной макет со sidebar для страниц раздела.
Парсинг Markdown
В файле composer.json подключается библиотека erusev/parsedown — это парсер Markdown в HTML. Он позволяет конвертировать Markdown в HTML очень просто.
Многие статические сайты строятся из документов в Markdown: это удобный и читаемый формат для авторов. В проекте есть функция show_content() в funcs.php:
function show_content() {
$file = MD_DIR.PAGE.'.md';
if (file_exists($file)) {
$Parsedown = new Parsedown();
echo $Parsedown->text(file_get_contents($file));
} else if (function_exists("content")) {
echo content();
}
}Если для запрошенной страницы есть файл Markdown, Parsedown конвертирует его в HTML и выводит. Если файла нет — функция ищет определение content(), которое может вернуть динамический контент. Это позволяет сочетать статический Markdown и кастомную логику там, где это нужно.
Загрузка метаданных
Функция get_json в funcs.php читает и парсит JSON-файлы с валидацией ошибок:
function get_json($file) {
$data_file = DATA_DIR."/".$file;
if (!file_exists($data_file)) {
return array();
}
if (($json = file_get_contents($data_file)) === false) {
return array();
}
if (($out = json_decode($json, true)) === null) {
return array();
}
return $out;
}Функция возвращает ассоциативный массив (при использовании json_decode с флагом true), что удобно для быстрой работы с данными. Для простых задач это позволяет обойтись без базы данных.
Сайт использует два файла метаданных: data/titles.json и data/featured.json. В первом хранятся заголовки страниц:
{
"/": "Home",
"/about": "About",
"/birds": "Bird profiles",
...
}Хранение заголовков в одном месте упрощает обновление навигации, хлебных крошек и боковых панелей.
Функция для получения заголовка страницы выглядит так:
function page_title($page = PAGE) {
$titles = get_titles();
return array_key_exists($page, $titles) ? $titles[$page] : basename($page);
}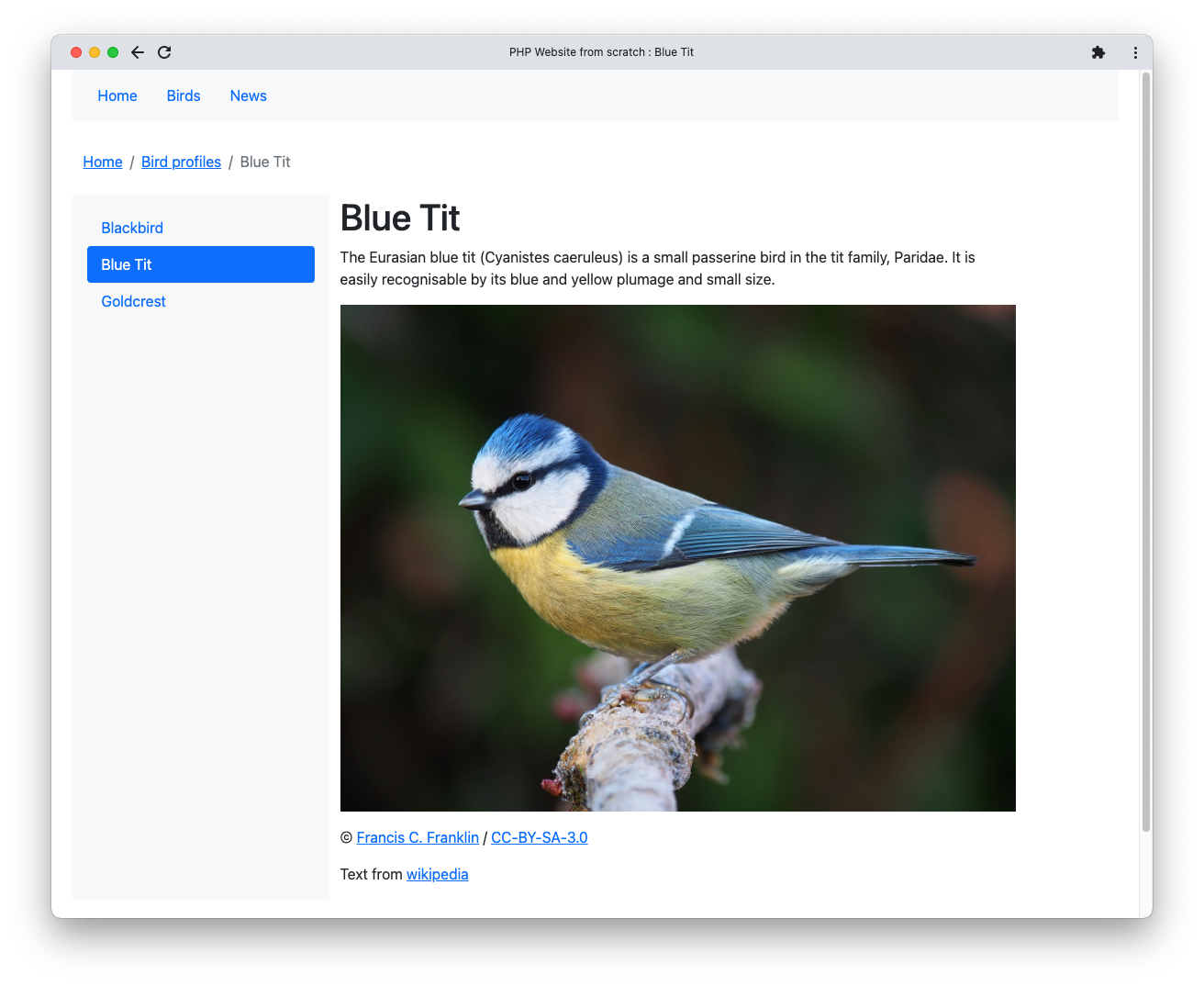
Фрагмент функции breadcrumbs() строит массив заголовков для частей URL. Для страницы /birds/blue-tit он извлечёт заголовки для /, /birds и /birds/blue-tit, чтобы отобразить цепочку навигации:
function breadcrumbs() {
$items = array();
$titles = get_titles();
$parts = explode("/", PAGE);
$href = "";
foreach ($parts as $part) {
$href .= ($href == "/" ? "" : "/").$part;
$items[$href] = $titles[$href];
}
...
}Получение метаданных из файловой системы
В footer сайта выводится сообщение «Last updated», которое берёт время изменения самого Markdown-файла. В tpl/footer.php это делается так:
if (file_exists($file = MD_DIR.PAGE.'.md')) {
echo 'Last updated: '.date('r', filemtime(MD_DIR.PAGE.'.md'));
}Функция filemtime возвращает время последнего изменения файла. Это простой и удобный приём, но у него есть ограничения: серверное время, операции копирования/развёртывания, и VCS-метаданные могут влиять на реальную полезность такого значения.
Извлечение данных регулярными выражениями
Иногда нужно переиспользовать часть контента — например, показывать список новостей с заголовками и анонсами. На этом сайте новости хранятся как Markdown-файлы, поэтому можно читать их как строки и извлекать части через регулярные выражения.
В news/index.php содержимое каждого файла читается и анализируется. Название новости берётся как строка, начинающаяся с символа # (Markdown). Регулярное выражение ^#\s+(.+) матчит строку заголовка, а preg_match() возвращает захваченную группу — сам текст заголовка.
if (preg_match("/^#\s+(.+)/", $contents, $matches)) {
$title = $matches[1];
}Далее применяются регулярные выражения для извлечения изображения и первой фразы. Недостаток этого подхода — жёсткая зависимость от формата. Нужно следить, чтобы Markdown-файлы соответствовали ожидаемой структуре.
Выбор случайного контента
Страница /birds использует случайное изображение, чтобы оживить раздел. В site/birds/index.php это реализовано так:
function content() {
$files = scandir(SITE_DIR."/img");
$files = array_filter($files, function($file) { return $file[0] != '.'; });
$file = $files[array_rand($files)];
echo 'Birds
';
echo ' ';
}
';
}Приём основан на хранении всех подходящих изображений в одной директории. scandir читает файлы в массив, array_rand возвращает случайный ключ, по которому выбирается файл для вывода.
Резюме работы с PHP для простых сайтов
Главная мысль: простая структура с файлами Markdown, парой JSON-файлов метаданных и небольшими шаблонами делает сайт удобным в поддержке и понимании. По мере роста проекта вы сможете заменить отдельные части — например, перейти с плоских файлов на базу данных — не ломая архитектуру целиком.
Когда такой подход не подходит
- Если ожидается большой объём контента и высокая частота обновлений с конкурентными правками, файловая система станет узким местом.
- Для сложной многопользовательской модерации, учёта прав доступа и аудита лучше использовать CMS или реляционную БД.
- При необходимости сложных запросов (фильтры, сортировки по нескольким полям, полнотекстовый поиск) flat-file структура оказывается ограниченной.
Важно: никогда не используйте пользовательский ввод напрямую в include/require без валидации — это серьёзная угроза безопасности.
Альтернативные подходы
- Использовать простую CMS (WordPress, Grav, Pico) если важна быстрая готовая панель управления.
- Применить статический сайт-генератор (Jekyll, Hugo) если контент преимущественно статичен и требуется максимальная скорость доставки.
- Для проектов с динамикой и масштабом — MVC-фреймворк (Laravel, Symfony) и реляционная или NoSQL БД.
Каждый подход имеет компромиссы: простые flat-file сайты легче понять, но они редко подходят для масштабируемых приложений.
Модель мышления — зачем разделять шаблоны и контент
Правило: разделяй то, что меняется по-разному. Шаблоны (html-обёртка, навигация, footer) меняются реже, контент — чаще. Разделение:
- Уменьшает дублирование.
- Упрощает локализацию (переводы).
- Делает автоматические обновления и CI/CD проще.
Хорошая эвристика: если вы редактируете одинаковую часть в нескольких файлах — вынесите это в шаблон.
Уровни зрелости проекта (микро-уровни)
- Начальный: сайт состоит из нескольких .php файлов и пары шаблонов. Markdown и JSON — локальные.
- Организованный: всё разделено на md/, tpl/, data/, funcs.php. Есть простое тестовое окружение.
- Поддерживаемый: добавлены CI для синтакс-проверки и деплоя, резервное копирование данных, автоматические проверки формата Markdown.
- Масштабируемый: миграция на БД для больших наборов данных, кеширование, CDN для статики.
Перемещайтесь по уровням по мере роста проекта и реальных потребностей.
Фактбокс — ключевые идеи
- Хранение контента в Markdown ускоряет написание и чтение.
- JSON-файлы удобны для небольшой метаинформации (навигация, выделенный контент).
- Parsedown — простое решение для конвертации Markdown в HTML.
- Регулярные выражения мощные, но требовательны к формату исходников.
Мини-методология для внедрения такого подхода
- Создайте каталоги: site/, tpl/, md/, data/, img/.
- Сделайте базовый tpl/head.php и tpl/footer.php.
- Напишите funcs.php с константами TPL_DIR, MD_DIR, DATA_DIR и вспомогательными функциями (get_json, show_content, page_title, breadcrumbs).
- Подготовьте несколько Markdown-страниц и titles.json.
- Тестируйте локально через встроенный PHP-сервер: php -S localhost:8000 -t site
- Настройте простой CI для проверки синтаксиса PHP и валидности JSON.
Чеклист для ролей
Разработчик:
- Проверить, что TPL_DIR и MD_DIR правильно определены.
- Убедиться, что include() не принимает пользовательский ввод без фильтра.
- Добавить unit-тесты для функций в funcs.php (при возможности).
Контент-менеджер:
- Следовать правилам оформления Markdown (заголовок в первой строке, формат изображений).
- Обновлять data/titles.json при добавлении страниц.
Оператор/админ:
- Настроить права на запись только для тех директорий, где это необходимо (.md при удалённой редактуре).
- Настроить резервное копирование md/ и data/.
Критерии приёмки
- Все страницы, описанные в data/titles.json, доступны и отображают корректный заголовок.
- show_content() успешно рендерит Markdown и fallback на content() работает.
- breadcrumbs() показывает корректную цепочку навигации для вложенных страниц.
- Footer выводит “Last updated” корректно для Markdown-страниц.
Руководство по развертыванию (короткий SOP)
- Клонировать репозиторий.
- Установить зависимости Composer (если используются Parsedown): composer install
- Настроить веб-сервер: DOCROOT указывает на директорию site/.
- Проверить права доступа к md/ и data/ (только чтение, если нет необходимости в записи).
- Выполнить smoke-test: открыть несколько страниц и убедиться в корректном отображении.
Набор приёмок/тест-кейсов
- Открыть / — должна показаться главная страница.
- Открыть /birds — должна показаться страница раздела с изображением (ранжируемо случайным).
- Открыть страницу новости — должна отображаться заголовок, превью и дата изменения.
- Некорректный маршрут — показать 404-шаблон или корректный fallback.
Шаблоны и сниппеты (cheat sheet)
Подключение Parsedown (пример в funcs.php):
$Parsedown = new Parsedown();
echo $Parsedown->text(file_get_contents($file));Безопасный include шаблона (валидация имени):
$allowed = ['home', 'about', 'birds'];
$tpl = in_array($page, $allowed) ? $page : '404';
include TPL_DIR.'/'.basename($tpl).'.php';Пример запуска встроенного сервера для локальной проверки:
php -S localhost:8000 -t siteРиски и простые способы их снизить
- RCE через неконтролируемые include — фильтруйте и бельте имена файлов.
- Утечка конфиденциальных данных — храните секреты вне репозитория (env-файлы, переменные окружения).
- Проблемы с одновременными изменениями файлов — для совместной работы используйте VCS (Git) и процессы ревью.
Примеры миграции при росте проекта
- Перенести metadata JSON → таблицы в БД, сохраняя прежний формат для совместимости API.
- Поставить кеш (filesystem, Redis) для рендеринга Markdown и кусков меню.
- Вынести статику на CDN.
Если вы дочитали до конца, вы получили не только перевод структуры и кода, но и практический набор руководств и шаблонов, которые можно применить прямо сейчас. Начните с малого: выделите шаблоны и контент в отдельные папки, добавьте Parsedown и простую JSON-метадату — и вы уже на пути к удобному, поддерживаемому сайту.
Экспертная цитата: “Хорошая структура проекта — это инвестиция: сначала тратится немного времени на организацию, затем экономится очень много часов при поддержке.”
Ключевые ссылки и дальнейшие шаги:
- Репозиторий примера на GitHub — скачайте и экспериментируйте.
- Документация Parsedown — для расширенных настроек парсинга Markdown.
- Руководства по безопасности PHP — для защиты include и работы с пользовательскими данными.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
