Как создать детектор плагиата на Python с Tkinter и Difflib

Краткое руководство по созданию простого детектора плагиата на Python с графическим интерфейсом на Tkinter и сравнением текста через модуль Difflib. В статье показаны готовые фрагменты кода, пояснения к работе SequenceMatcher, подсветка совпадающих фрагментов и советы по интеграции методов NLP для более глубокого семантического анализа.
Важно: этот пример подходит для локального анализа строк и небольших файлов. Для промышленного применения нужны дополнительные шаги по предобработке, масштабированию и защите данных.
Введение
С ростом цифрового контента защита от копирования и неправомерного заимствования становится критичной. Детектор плагиата помогает преподавателям, исследователям и авторам быстро находить совпадения в текстах. Небольшой проект с Tkinter и Difflib одновременно служит учебной задачей и рабочим инструментом: вы изучаете сравнение последовательностей, работу с файлами и UI.
Далее мы разберём весь код по шагам, объясним, что делает каждый блок, и дадим рекомендации по улучшению с помощью методов NLP и встраивания в реальную систему.
Краткое описание используемых библиотек
- Tkinter — стандартная библиотека Python для простых графических интерфейсов. Лёгкая, кросс-платформенная и удобная для быстрых прототипов.
- Difflib — модуль стандартной библиотеки Python для сравнения последовательностей (строки, списки, файлы). SequenceMatcher вычисляет коэффициент сходства и возвращает операции (опкоды) для выделения различий и совпадений.
Ключевой термин: SequenceMatcher — алгоритм сравнения двух последовательностей; возвращает ratio (число от 0.0 до 1.0) и opcodes для подсветки изменений.
Пошаговая реализация детектора плагиата
Ниже — полные фрагменты кода из примера. Они оставлены в исходном виде для простоты копирования и запуска. После каждого фрагмента даётся пояснение и варианты доработки.
Загрузка файла и отображение содержимого
Функция load_file_or_display_contents отвечает за получение пути к файлу из поля ввода или открытия диалога выбора файла, затем чтение файла и вставку текста в виджет.
import tkinter as tk
from tkinter import filedialog
from difflib import SequenceMatcher
def load_file_or_display_contents(entry, text_widget):
file_path = entry.get()
if not file_path:
file_path = filedialog.askopenfilename()
if file_path:
entry.delete(0, tk.END)
entry.insert(tk.END, file_path)Пояснение и советы:
- Используйте кодировку при открытии файла: open(file_path, ‘r’, encoding=’utf-8’) чтобы избежать проблем с кириллицей.
- Контролируйте исключения (FileNotFoundError, UnicodeDecodeError) и показывайте ошибки пользователю через messagebox.
Пример с открытием и вставкой текста:
with open(file_path, 'r') as file:
text = file.read()
text_widget.delete(1.0, tk.END)
text_widget.insert(tk.END, text)Рекомендация: для больших файлов вы можете считывать и вставлять порциями или показывать прогресс загрузки.
Сравнение текстов: SequenceMatcher и opcodes
Функция compare_text использует SequenceMatcher для расчёта процентного сходства и получения опкодов для подсветки.
def compare_text(text1, text2):
d = SequenceMatcher(None, text1, text2)
similarity_ratio = d.ratio()
similarity_percentage = int(similarity_ratio * 100)
diff = list(d.get_opcodes())
return similarity_percentage, diffПояснение:
- ratio() возвращает значение от 0.0 до 1.0. Это простая оценка сходства последовательностей символов.
- get_opcodes() возвращает список операций: (‘replace’|’delete’|’insert’|’equal’, start1, end1, start2, end2).
Ограничения этого подхода: чувствительность к перестановкам слов, форматированию, пунктуации и небольшим изменениям. Для семантического сравнения лучше применять NLP.
Отображение результата и подсветка совпадающих фрагментов
Функция show_similarity извлекает тексты из виджетов, вызывает compare_text и отображает процент совпадения. Также она снимает прежние теги подсветки и добавляет их заново.
def show_similarity():
text1 = text_textbox1.get(1.0, tk.END)
text2 = text_textbox2.get(1.0, tk.END)
similarity_percentage, diff = compare_text(text1, text2)
text_textbox_diff.delete(1.0, tk.END)
text_textbox_diff.insert(tk.END, f"Similarity: {similarity_percentage}%")
text_textbox1.tag_remove("same", "1.0", tk.END)
text_textbox2.tag_remove("same", "1.0", tk.END)Далее цикл по diff и добавление тега “same” для равных фрагментов:
for opcode in diff:
tag = opcode[0]
start1 = opcode[1]
end1 = opcode[2]
start2 = opcode[3]
end2 = opcode[4]
if tag == "equal":
text_textbox1.tag_add("same", f"1.0+{start1}c", f"1.0+{end1}c")
text_textbox2.tag_add("same", f"1.0+{start2}c", f"1.0+{end2}c")Советы по подсветке:
- Для корректной работы индексы опкодов интерпретируются как смещения символов (символы, не слова).
- Для подсветки на уровне слов нужно предварительно токенизировать текст и сравнивать списки токенов.
Интерфейс на Tkinter: создание окна и виджетов
Ниже — минимальная сборка интерфейса: метки, текстовые поля, кнопки и поля ввода путей к файлам.
root = tk.Tk()
root.title("Text Comparison Tool")
frame = tk.Frame(root)
frame.pack(padx=10, pady=10)
text_label1 = tk.Label(frame, text="Text 1:")
text_label1.grid(row=0, column=0, padx=5, pady=5)
text_textbox1 = tk.Text(frame, wrap=tk.WORD, width=40, height=10)
text_textbox1.grid(row=0, column=1, padx=5, pady=5)
text_label2 = tk.Label(frame, text="Text 2:")
text_label2.grid(row=0, column=2, padx=5, pady=5)
text_textbox2 = tk.Text(frame, wrap=tk.WORD, width=40, height=10)
text_textbox2.grid(row=0, column=3, padx=5, pady=5)Кнопки для загрузки и сравнения:
file_entry1 = tk.Entry(frame, width=50)
file_entry1.grid(row=1, column=2, columnspan=2, padx=5, pady=5)
load_button1 = tk.Button(frame, text="Load File 1", command=lambda: load_file_or_display_contents(file_entry1, text_textbox1))
load_button1.grid(row=1, column=0, padx=5, pady=5, columnspan=2)
file_entry2 = tk.Entry(frame, width=50)
file_entry2.grid(row=2, column=2, columnspan=2, padx=5, pady=5)
load_button2 = tk.Button(frame, text="Load File 2", command=lambda: load_file_or_display_contents(file_entry2, text_textbox2))
load_button2.grid(row=2, column=0, padx=5, pady=5, columnspan=2)
compare_button = tk.Button(root, text="Compare", command=show_similarity)
compare_button.pack(pady=5)
text_textbox_diff = tk.Text(root, wrap=tk.WORD, width=80, height=1)
text_textbox_diff.pack(padx=10, pady=10)Подсветка совпадающих фрагментов оформляется так:
text_textbox1.tag_configure("same", foreground="red", background="lightyellow")
text_textbox2.tag_configure("same", foreground="red", background="lightyellow")И запуск цикла событий:
root.mainloop()Пример работы и скриншоты
При запуске приложения откроется окно. Кнопка Load File 1 открывает диалог выбора файла и заполняет первое поле. Аналогично для Load File 2. Кнопка Compare показывает процент сходства и подсвечивает совпадающие символы/фрагменты.
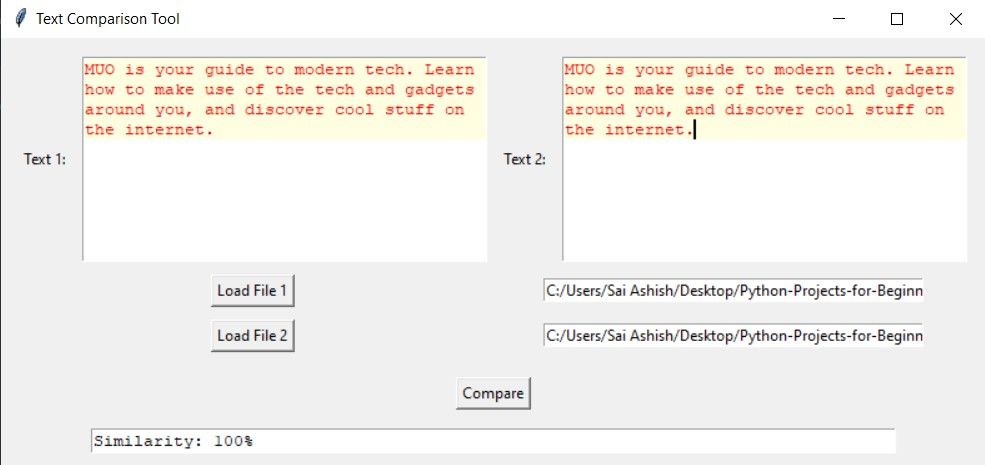
Если тексты полностью совпадают, вы увидите 100% и подсветку всего текста.
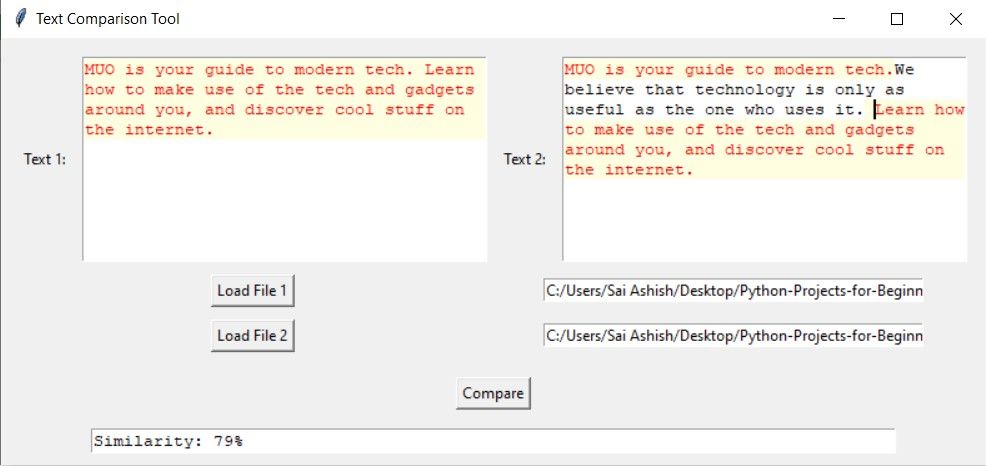
При частичном совпадении подсвечиваются только общие фрагменты.
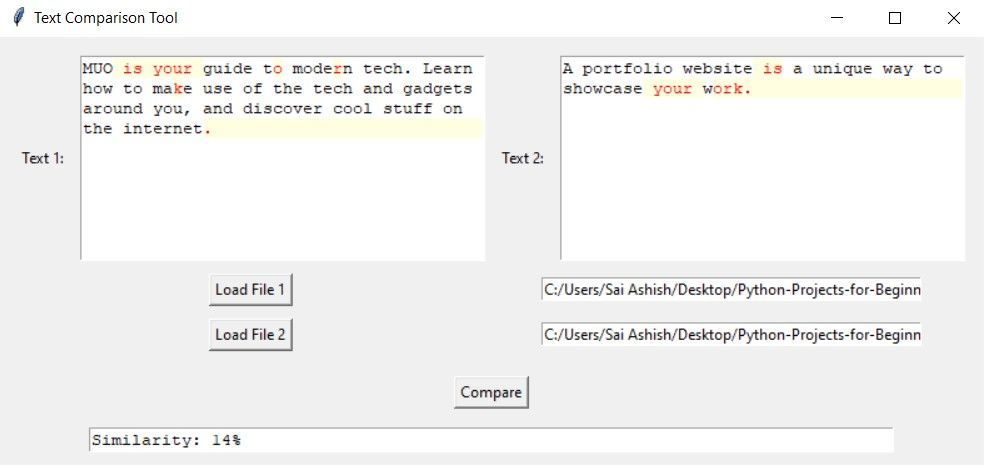
При минимальной схожести подсвечиваются отдельные слова или буквы; процент небольшой.
Ограничения Difflib и когда он не подойдёт
- Чувствителен к форматированию: разбиение на строки, пробелы, переносы влияют на результат.
- Не понимает семантику: перефразировка при сохранении смысла часто дает низкий процент сходства.
- Масштаб: работа с очень большими текстами (десятки мегабайт) требует оптимизации памяти и скорости.
Контрпример: если студент заменил слова синонимами и переставил части текста, Difflib может не определить плагиат — здесь нужен семантический анализ.
Улучшение детектора: методы NLP и альтернативы
Ниже — набор техник, которые применяют для более надёжного обнаружения плагиата:
- Токенизация + нормализация: удаление пунктуации, приведение к нижнему регистру, лемматизация.
- Jaccard similarity: сравнение множеств n-грам (подходит для обнаружения доли общих фрагментов).
- Cosine similarity на векторных представлениях TF-IDF: хорошо работает при перефразировании и разных порядках слов.
- Векторные эмбеддинги (word2vec, FastText, Sentence-BERT): позволяют оценивать семантическую близость на уровне предложений/абзацев.
- Пороговые и многослойные проверки: сначала быстрый фильтр (difflib/jaccard), затем более дорогая семантическая проверка.
- Модели seq2seq и специальные архитектуры для выявления перефразирования.
Практическая схема: сначала быстрый pre-filter (hashing или n-грам Jaccard), затем для подозрительных пар — TF-IDF/cosine или эмбеддинги.
Мини-методология внедрения (шаги)
- Сбор и предобработка текстов: нормализация, токенизация и очистка.
- Быстрый фильтр: Jaccard по 3- или 5-граммам или MinHash/LSH для снижения числа кандидатов.
- Точная проверка: TF-IDF + cosine или Sentence-BERT для семантики.
- Ручная ревизия и отчёт: выкладывайте отрывки, процент и метаданные (источник, дата).
- Логирование и хранение метрик для аудита.
Рольовые чек-листы
Для разработчика:
- Обработать варианты кодировок.
- Добавить обработку ошибок при чтении файлов.
- Обеспечить юнит-тесты для функций сравнения.
Для преподавателя/рецензента:
- Настроить пороги тревоги (напр., >70% — ручная проверка).
- Сохранять текстовую цитату и ссылку на источник.
Для администратора системы:
- Ограничить размер загружаемых файлов.
- Обеспечить конфиденциальность хранимых текстов.
Критерии приёмки
- Программа корректно загружает и отображает текстовые файлы в UTF-8.
- Кнопка Compare возвращает значение от 0 до 100 и подсвечивает одинаковые фрагменты.
- Обработка ошибок: приложение не падает при отсутствии файла или при ошибке чтения.
- При больших текстах время отклика укладывается в SLA (если задано).
Тестовые случаи и приёмочные сценарии
- Пустые поля → сообщение об ошибке.
- Полное совпадение двух текстов → 100% и полная подсветка.
- Небольшое изменение (одна добавленная строка) → подсветка общих частей и процент < 100.
- Файлы в разной кодировке (например, CP1251) → проверка корректного чтения или корректное сообщение об ошибке.
Примеры альтернатив и когда их выбрать
- Если нужно находить заимствования с перефразировкой — используйте эмбеддинги предложений (Sentence-BERT).
- Для массы документов и быстрого поиска похожих — применяйте MinHash/LSH.
- Для академических систем с обвинениями в плагиате — комбинируйте автоматическую оценку с ручной проверкой и хранением доказательств.
Безопасность и приватность
- Не храните пользовательские тексты дольше, чем нужно. Если храните — шифруйте данные в покое.
- При интеграции в облако проверьте соответствие локальным законам о персональных данных (например, GDPR при работе с данными европейских граждан).
- Логи должны исключать содержимое текстов, если это не требуется для расследования.
Модель зрелости (мини-матрица)
- Уровень 0 — прототип: локальное приложение, ручная проверка результатов.
- Уровень 1 — продуктив: предобработка, базовые метрики, стабильность загрузки.
- Уровень 2 — продвинутый: многослойные проверки (Jaccard → TF-IDF → EMB), масштабирование.
- Уровень 3 — корпоративный: распределённый поиск по репозиториям, аудит, интеграция с LMS и политиками конфиденциальности.
Быстрые рекомендации (чек-лист оптимизаций)
- Используйте ленивую загрузку больших файлов.
- Применяйте предварительное хеширование блоков для быстрого отсечения явно различных документов.
- Кешируйте векторы для часто сравниваемых документов.
Decision flow (упрощённая диаграмма)
flowchart TD
A[Новая пара документов] --> B{Размеры < порога?}
B -- Да --> C[Быстрый фильтр: Jaccard/MinHash]
B -- Нет --> D[Шардирование / потоковая обработка]
C --> E{Прошёл фильтр?}
E -- Нет --> F[Отчёт: низкая схожесть]
E -- Да --> G[Семантическая проверка 'TF-IDF / Embeddings']
G --> H{Процент > порога?}
H -- Да --> I[Отчёт: подозрительное совпадение -> ручная проверка]
H -- Нет --> FСравнение подходов (кратко)
- Difflib: +быстро, прост; −чувствителен к форматированию и синтаксису.
- Jaccard/n-граммы: +устойчивее к перестановкам; −не учитывает семантику.
- TF-IDF + cosine: +учитывает вес терминов; −не всегда ловит перефразирование.
- Embeddings: +семантика; −трудоёмкость и требования к ресурсам.
Локальные альтернативы и советы для русскоязычного контента
- При работе с русским языком используйте лемматизацию (pymorphy2, Mystem) и корректную токенизацию.
- FastText учитывает морфологию и может быть полезен для русского.
- Проверяйте кодировки и нормализуйте кавычки и дефисы.
Заключение
Простой детектор плагиата на Tkinter и Difflib — отличный старт для понимания задач сравнения текстов. Для реального применения рекомендую комбинировать быструю символьную проверку с методами NLP: предобработка → быстрый фильтр → семантическая проверка. Не забывайте про безопасность данных и тестирование на реальных сценариях.
Ключевые шаги для дальнейшего развития: добавить поддержку нескольких кодировок, обработку больших корпусов через MinHash/LSH и интеграцию эмбеддингов для понимания смысла. После этого система станет гораздо устойчивее к перефразированию и форматированию.
Краткое резюме
- Difflib хорош для простых, символьных сравнений.
- NLP-методы дают семантику и лучше работают с перефразированием.
- Комбинация быстрых фильтров и точных моделей — оптимальный путь.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
