Data Deduplication в Windows 11 и Windows Server — как включить, настроить и отладить
О чём эта статья
- Что такое Data Deduplication и как она работает в Windows
- Как включить и настроить Dedup на Windows Server и как вручную найти дубликаты в Windows 11
- Команды PowerShell и пошаговые инструкции для администраторов
- Когда Dedup не поможет и альтернативы
- Практические чек-листы, SOP, план тестирования и runbook при сбоях
Основные понятия (в одной строке)
- Dedup (Data Deduplication): процесс выявления одинаковых фрагментов данных и хранения только одной копии этих фрагментов.
- Chunk (чанк): фрагмент файла, на который система разбивает контент для поиска повторов.
- Chunk store (хранилище чанков): место на диске, где Dedup сохраняет уникальные чанки.
- Reparse point (точка перенаправления): метаданные файловой системы, указывающие на место оригинального чанка в chunk store.
Как работает Data Deduplication
Data Deduplication анализирует файлы на том томе, который включён в её работу, и выполняет следующие шаги:
- Сканирование: служба просматривает файлы в пределах выбранного тома и выбирает файлы подходящего возраста/типа для анализа (в соответствии с политикой).
- Разбиение на чанки: каждый файл логически разбивается на фрагменты фиксированного или адаптивного размера.
- Поиск повторов: вычисляются хэши чанков (контентные отпечатки) и сравниваются, чтобы найти идентичные фрагменты.
- Перемещение уникальных чанков: повторяющиеся чанки заменяются ссылками (reparse points), а один экземпляр фрагмента сохраняется в chunk store.
- Отчёты и сбережения: система фиксирует сжатие и экономию в пространстве (Deduplication Savings).
Важно: операции записи регистрируются как «неоптимизированные» и будут обработаны при следующем запуске задачи оптимизации. Обычно задачи оптимизации запускаются по расписанию; они выполняются в фоновом режиме и не требуют вмешательства.
Преимущества и ценность Dedup
- Экономия пространства на диске: устраняются повторяющиеся фрагменты данных, что освобождает место для новых данных.
- Снижение затрат на хранение: меньше требований к физическим накопителям и репликации, экономия на масштабировании хранилища.
- Упрощение восстановления: при корректной настройке резервные копии и репликация могут занимать меньше места.
- Снижение сетевого трафика при репликации: меньше данных требуется передавать между хранилищами.
Важно: описанные преимущества зависят от характера данных — эффективность сильно различается по типам контента.
Когда Dedup эффективна и когда нет
Кейс, когда Dedup работает хорошо:
- Большое количество одинаковых или похожих файлов (виртуальные диски виртуальных машин, шаблоны, архивы документов компании).
Кейс, когда эффекта мало:
- Уникальные данные без повторов (наборы сжатых медиафайлов, шифрованные файлы, специфичные двоичные файлы).
Примечание: шифрованные данные и многие формы сжатия мешают дедупликации — если данные зашифрованы или уже сжаты на уровне приложений, Dedup обычно не даёт выгоды.
Ограничения и риски
- Зависимость от типа данных: для некоторых наборов данных выгоды не будет.
- Возможное влияние на I/O: при высоких нагрузках на дисковую подсистему оптимизация может влиять на производительность.
- Риск ошибок конфигурации: некорректная настройка может привести к проблемам с доступом к файлам или повреждению данных.
- Ограничения по зашифрованным данным: dedup не работает с зашифрованными файлами (шифрование и дедупликация конфликтуют).
В следующем разделе — практические инструкции по включению и использованию Dedup в Windows 11 (ручные способы) и в Windows Server (встроенная служба).
Как найти и удалить дубликаты в Windows 11 (ручные способы)
Примечание: встроенной службы Data Deduplication в клиентских версиях Windows нет. В Windows 11 доступен ручной поиск дубликатов и сторонние инструменты.
Поиск по имени через Проводник
- Нажмите Windows + E, откройте Проводник и перейдите в папку или корень диска, где хотите искать дубликаты.
- В поле поиска в правом верхнем углу введите имя файла или шаблон (например, *.docx) и дождитесь результатов.
- Среди результатов выберите файлы с одинаковым именем и нажмите Delete или правой кнопкой — Удалить.
- Подтвердите удаление, если появится диалог.
Совет: для больших наборов данных это неудобно; используйте сортировку и фильтры (см. ниже) или сторонние утилиты.
Сортировка по имени и подробный просмотр
- Откройте Проводник и перейдите в нужную папку.
- В меню «Вид» выберите «Таблица» или «Подробности», чтобы отображать столбцы.
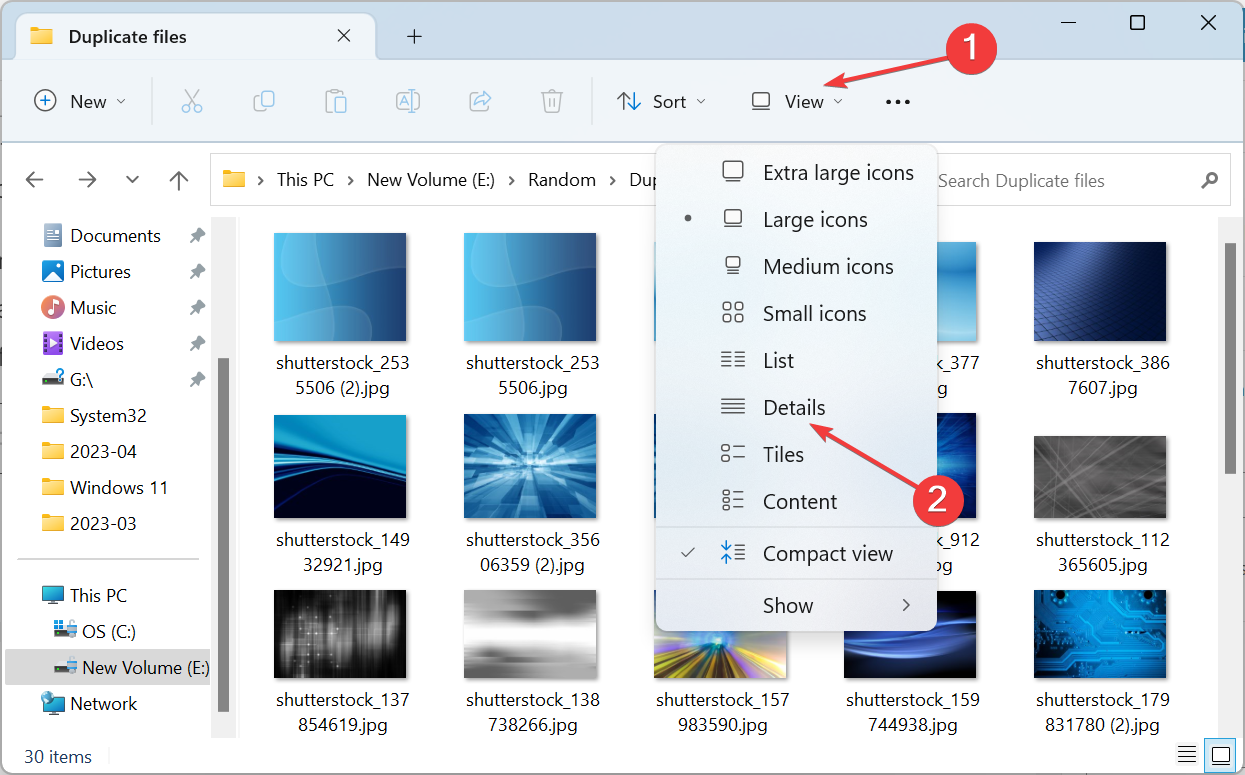
- Отсортируйте по столбцу «Имя». Дубликаты, как правило, окажутся рядом.
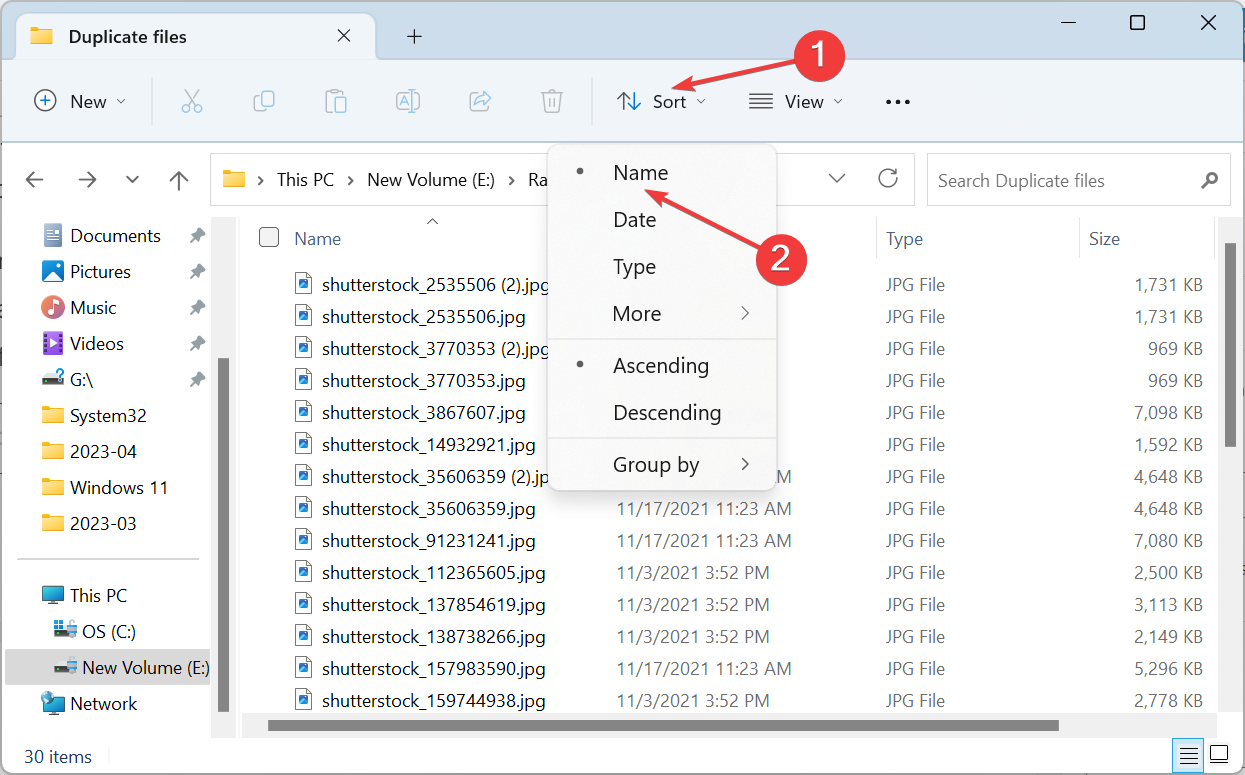
- Выделите лишние копии и удалите их.
Примечание: сортировка по размеру и дате изменения также помогает отличить настоящие дубликаты от похожих файлов.
Использование сторонних инструментов (пример: CCleaner)
- Скачайте и установите CCleaner или другой проверенный инструмент для поиска дубликатов.
- В CCleaner откройте Tools → Duplicate Finder.
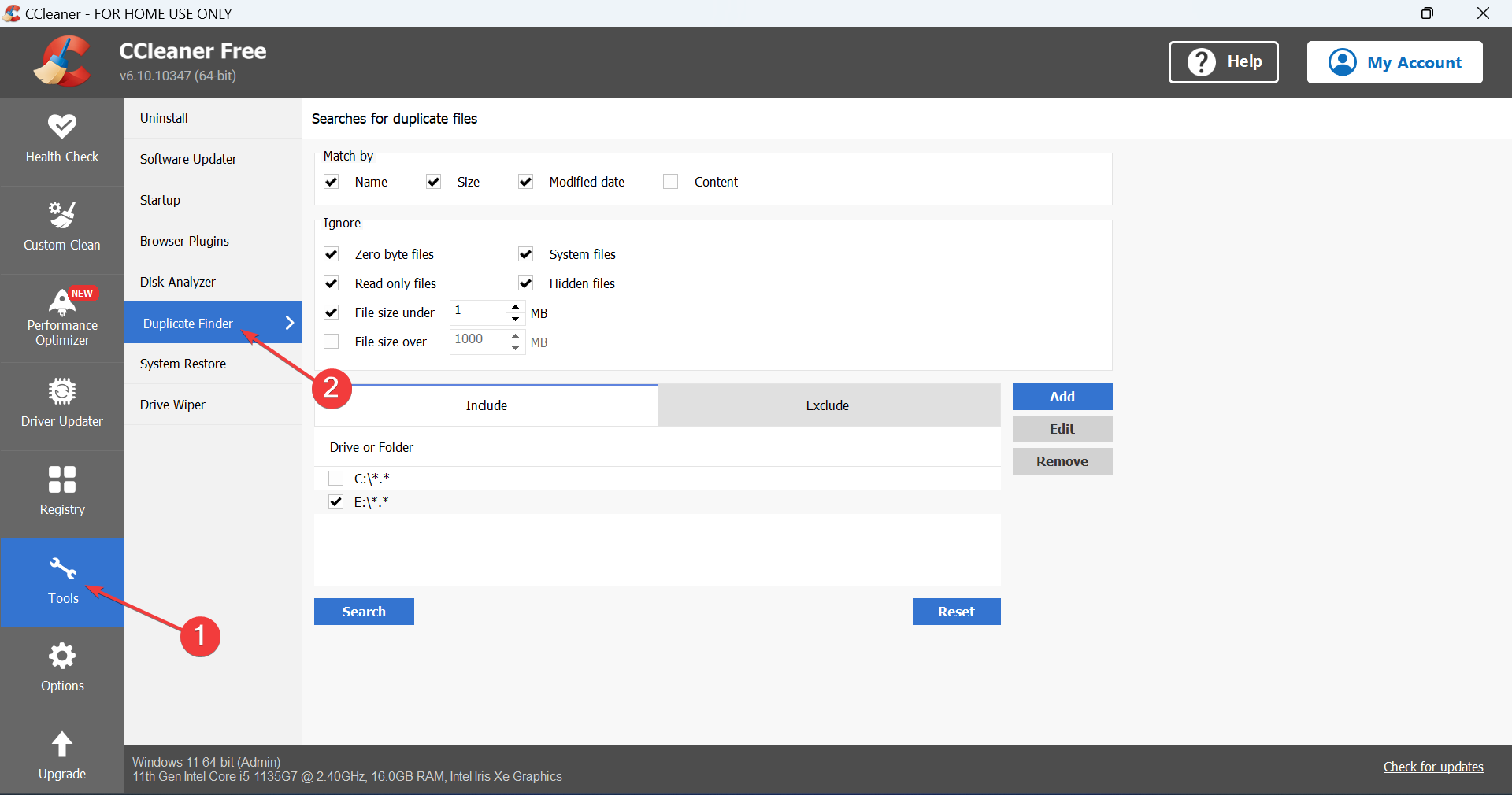
- Выберите диск или папку, задайте критерии поиска (имя, размер, дата, содержимое) и запустите поиск.
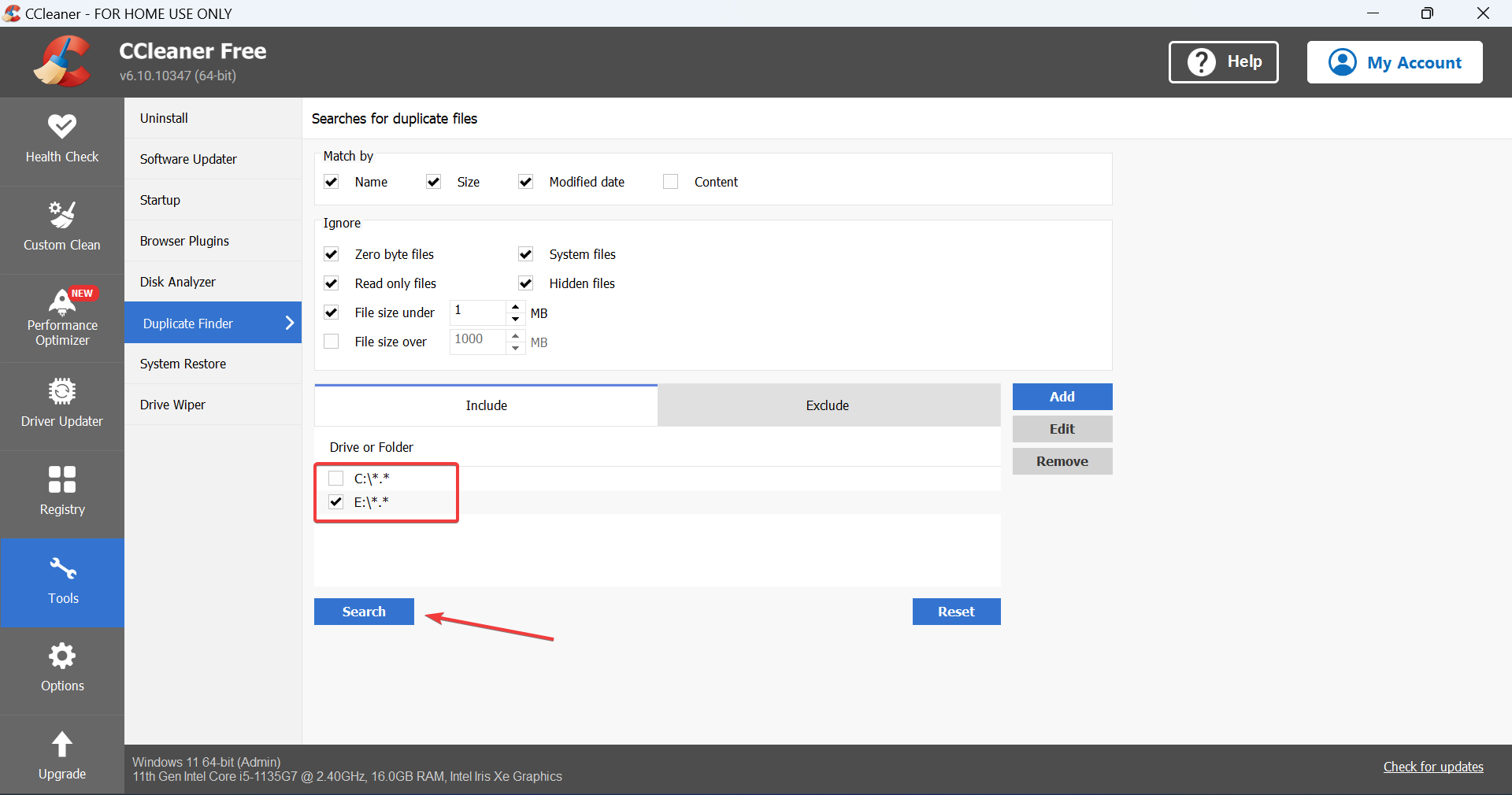
- Выберите файлы для удаления и нажмите Delete Selected. Подтвердите удаление.
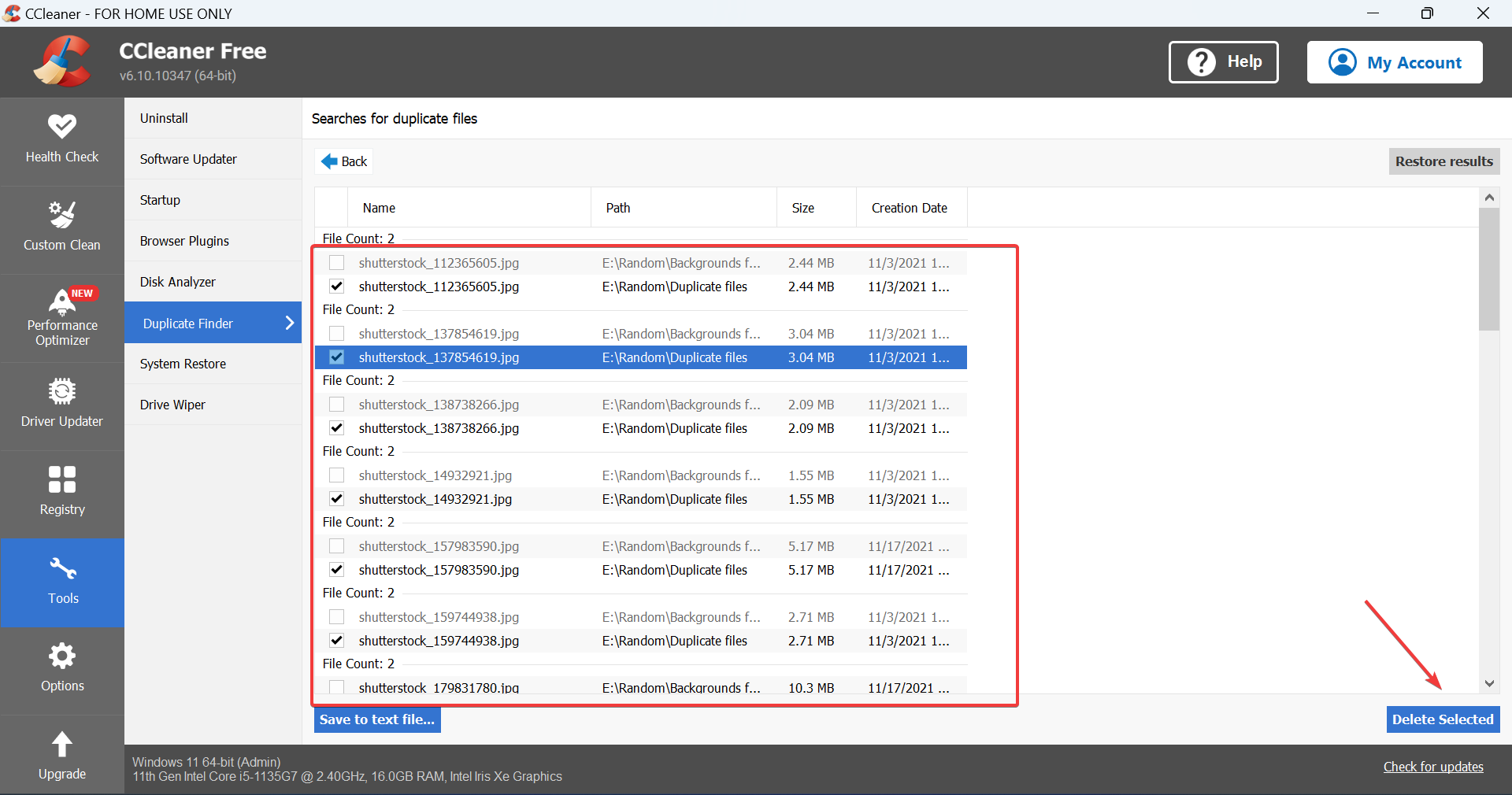
Преимущество: инструменты быстрее находят дубликаты по содержимому, а не только по имени.
Встроенная Data Deduplication в Windows Server — установка и настройка
Data Deduplication доступна в редакциях Windows Server. Включается как роль/функция через Server Manager или PowerShell.
1) Установка через Server Manager
- Откройте Server Manager → Add roles and features.
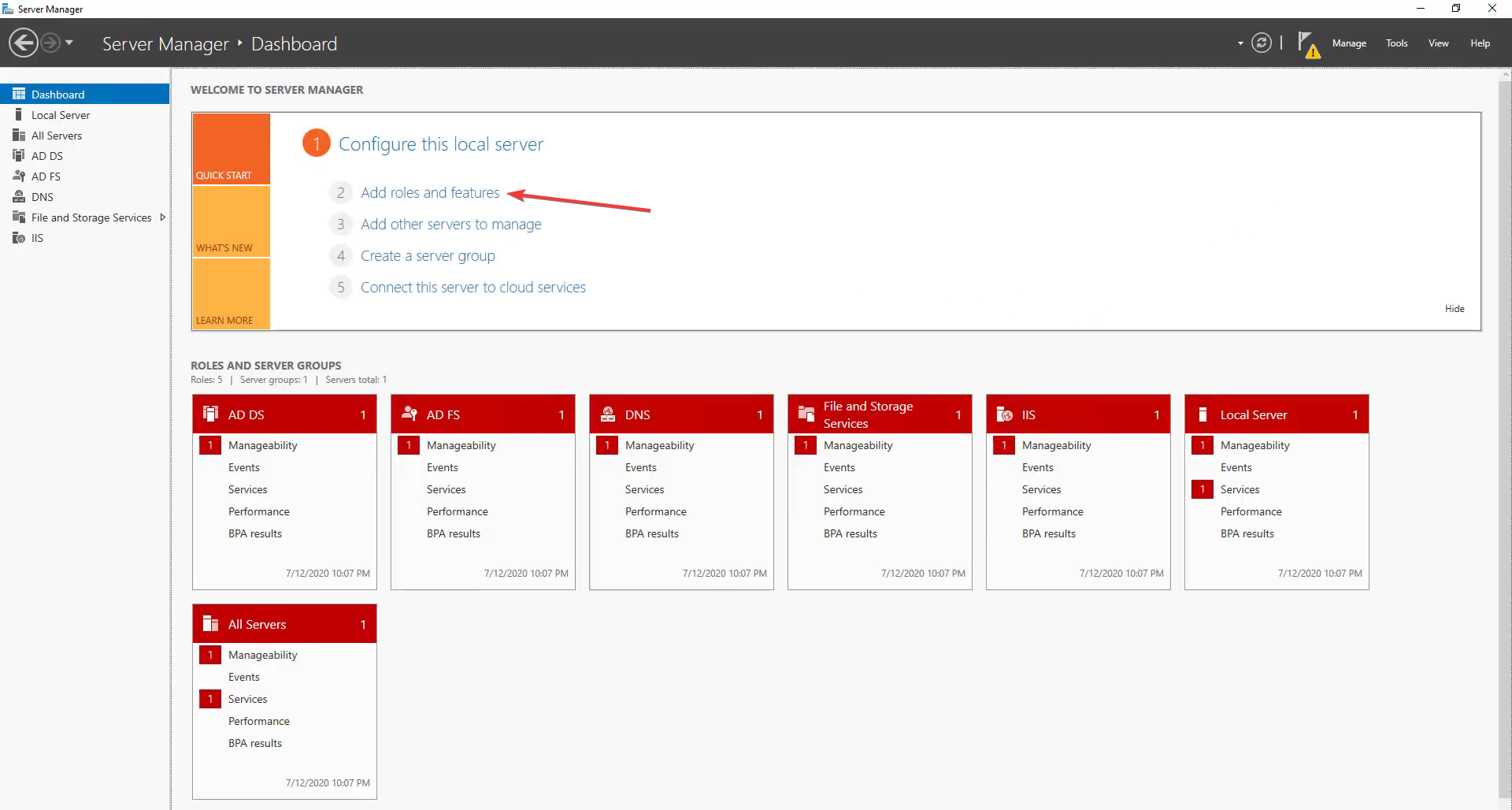
- Нажимайте Next до выбора типа установки. Выберите Role-based or feature-based installation.
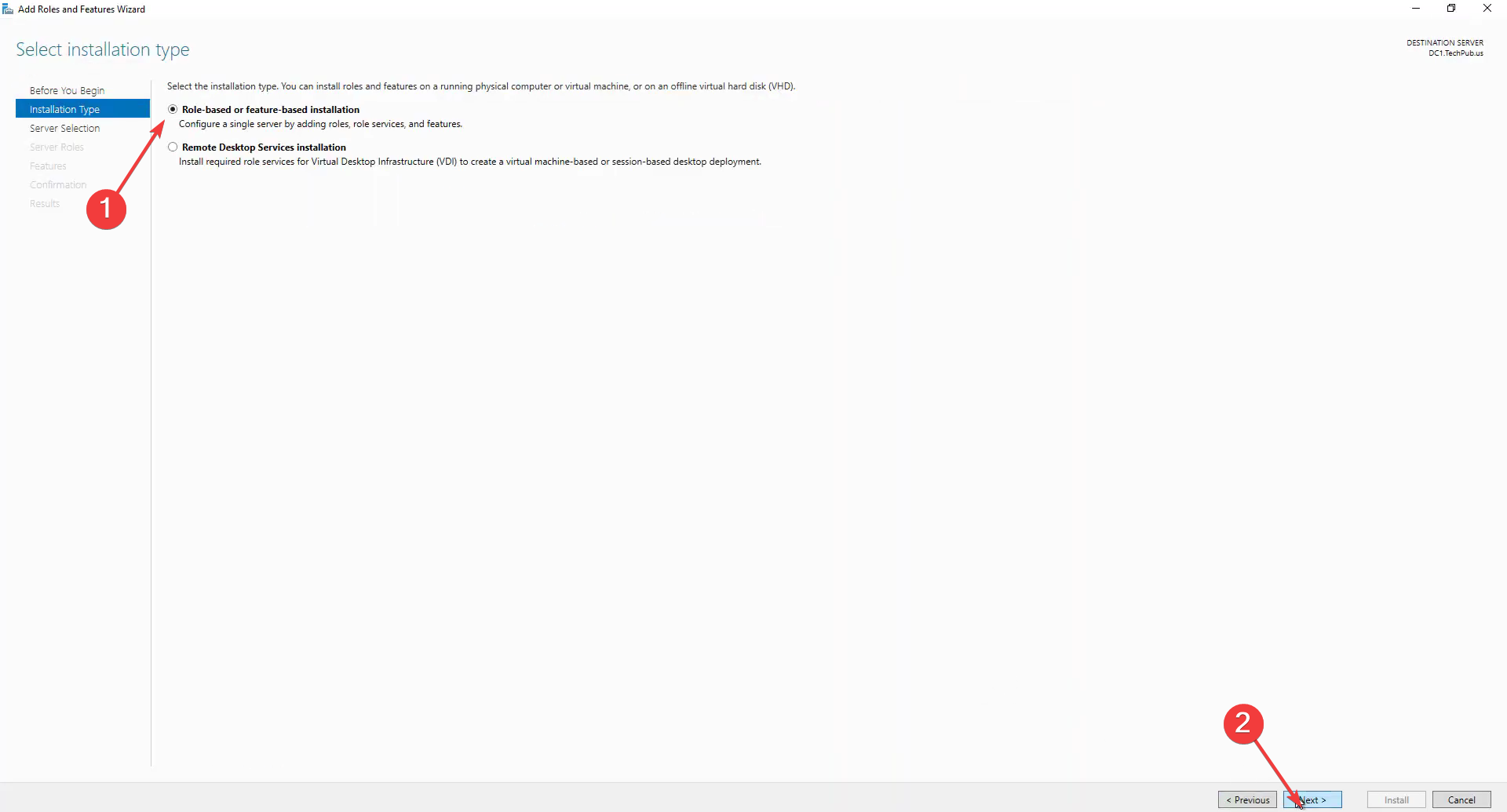
- В Features найдите File and Storage Services → File and iSCSI Services → Data Deduplication и отметьте для установки.
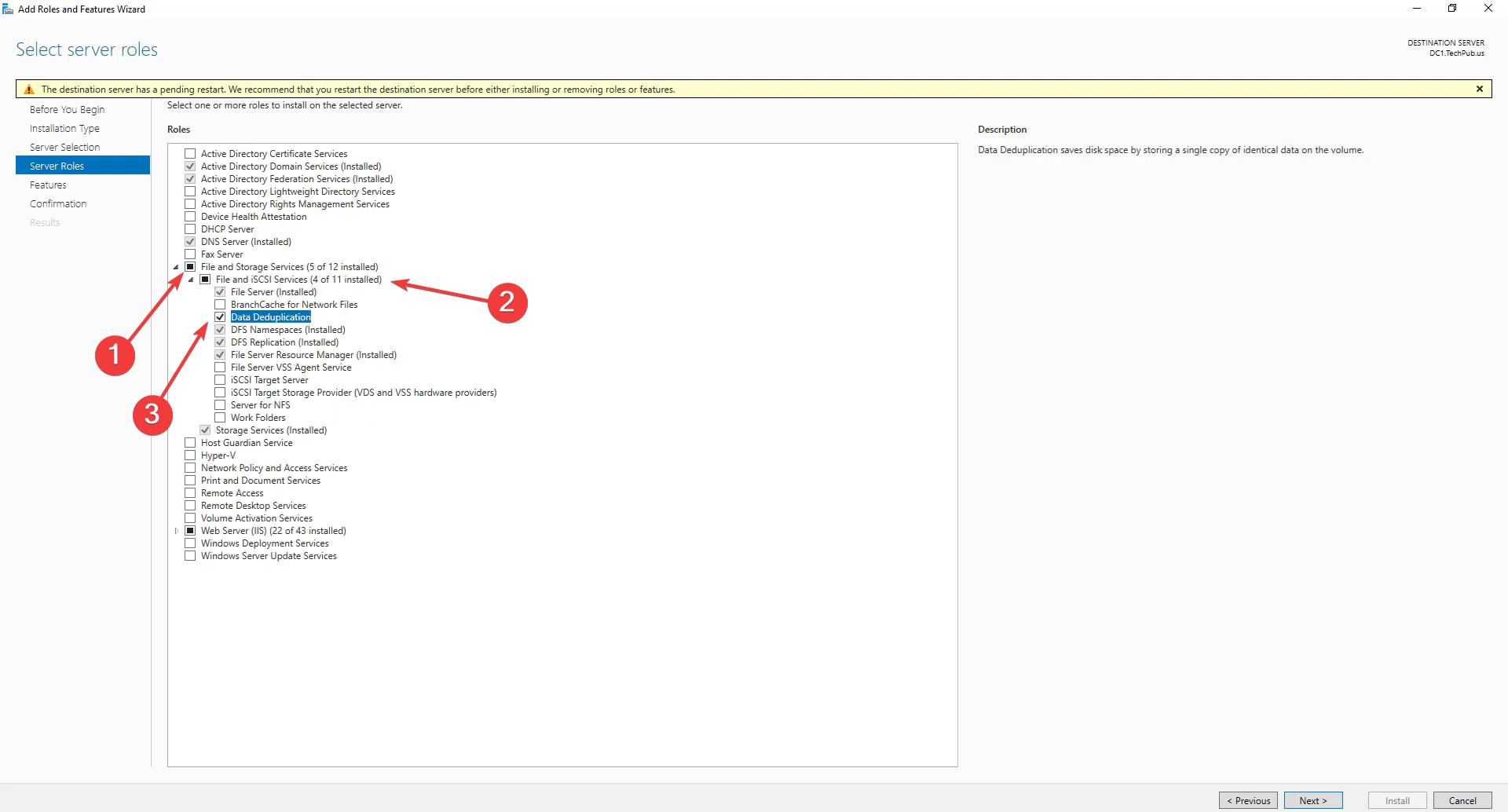
- Подтвердите и нажмите Install. Дождитесь завершения установки.
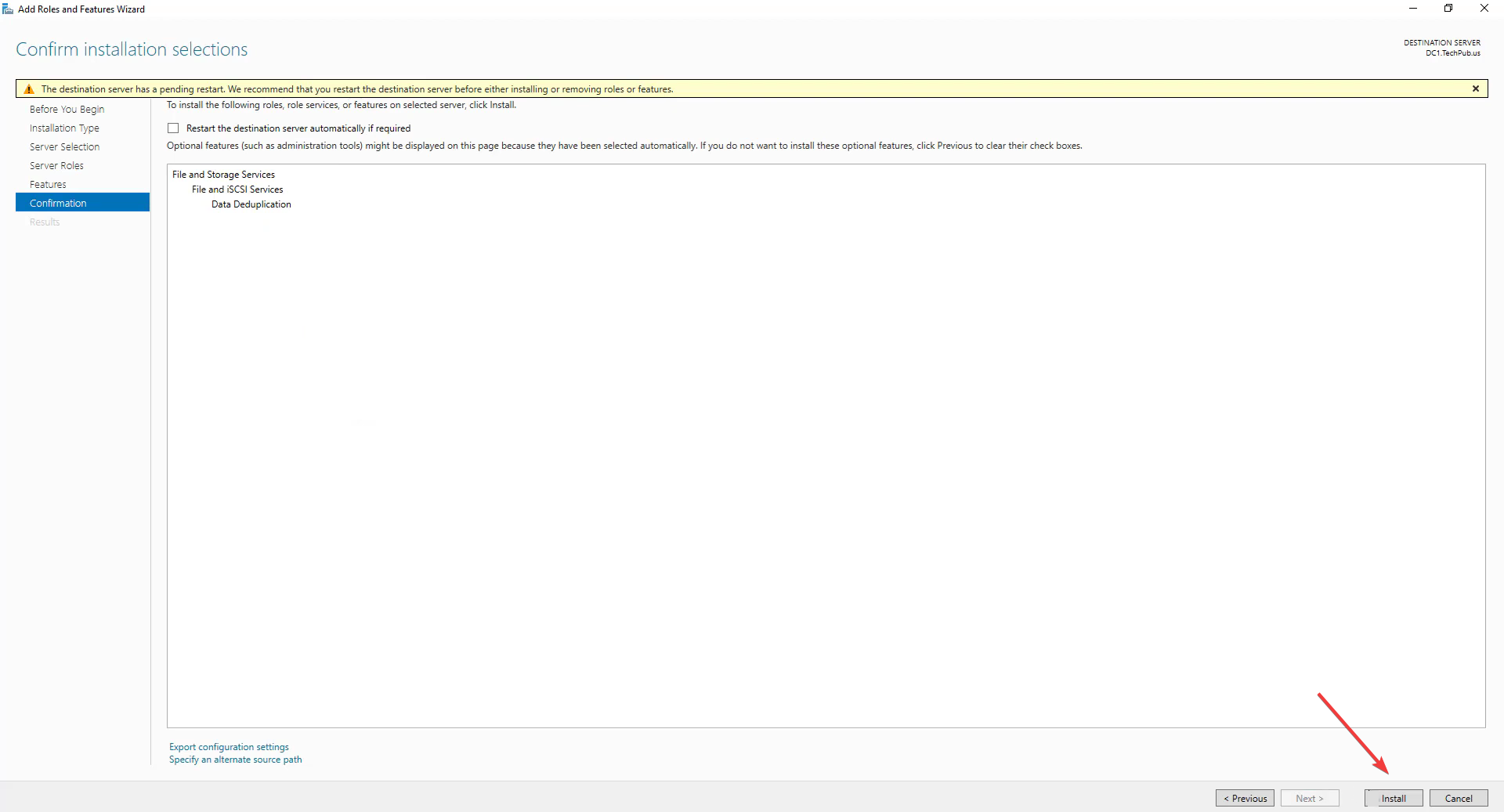
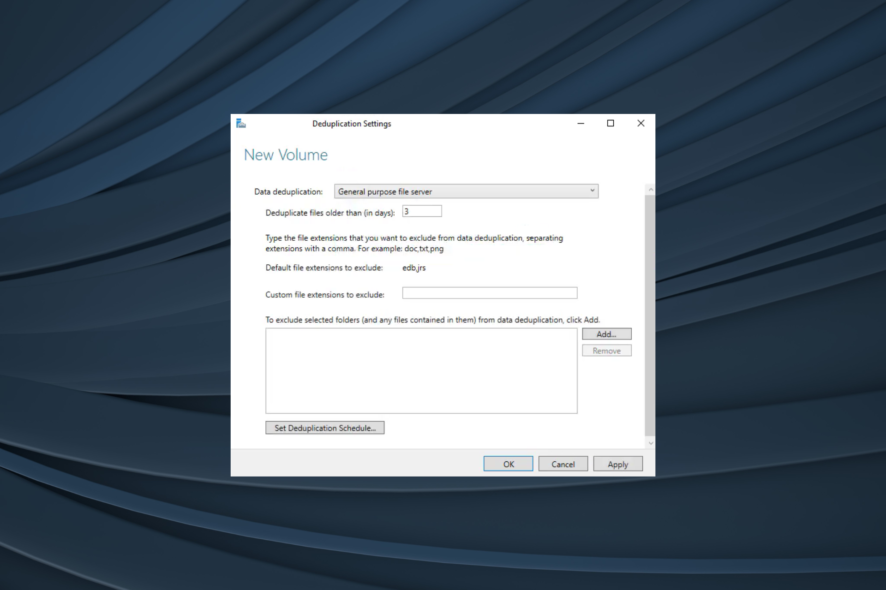
2) Настройка Data Deduplication для тома через Server Manager
- В Server Manager перейдите в File and Storage Services → Volumes.
- Если диск не инициализирован, сначала создайте том: Disks → правый клик на диске → New Volume.
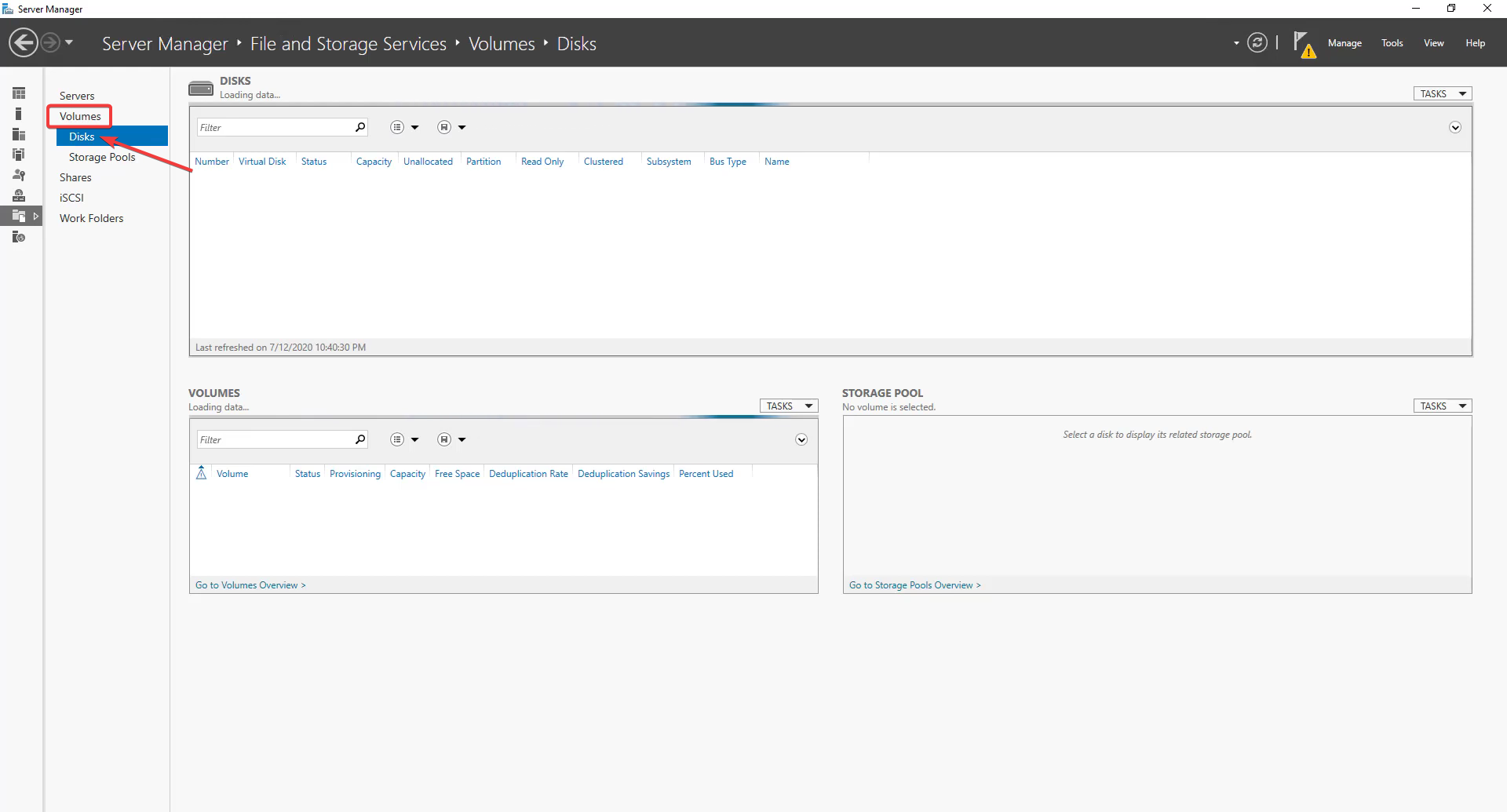
- Для уже существующего тома правой кнопкой мыши выберите Configure Data Deduplication.
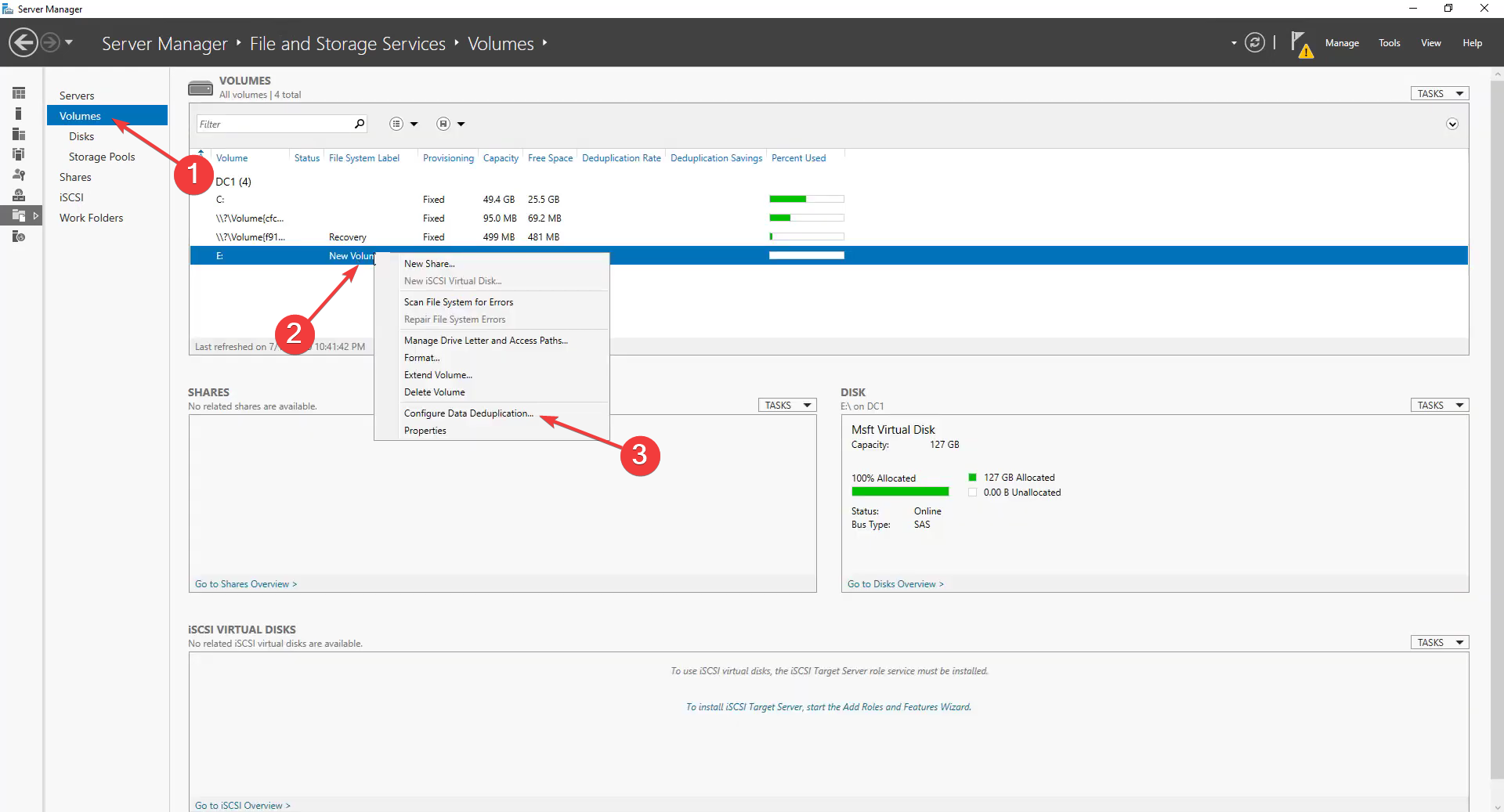
- В диалоге выберите профиль использования (Default, Hyper-V, Virtual Desktop и т. п.), назначьте время ожидания для файлов (например, не трогать недавно созданные файлы), добавьте исключения по расширениям или папкам, настройте расписание задач оптимизации и нажмите OK.
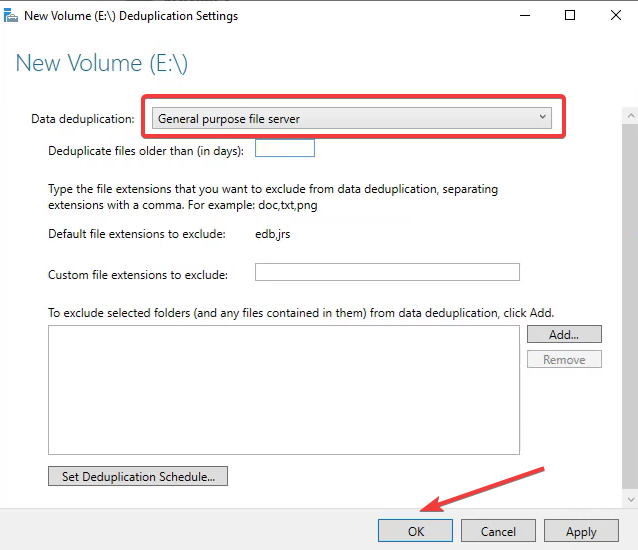
Замечание: нельзя включить Dedup на системном диске (обычно C:). Если опция серого цвета — проверьте выбранный том.
3) Быстрый запуск Dedup и команды PowerShell
Операции с Dedup можно автоматизировать и запускать вручную через PowerShell. Откройте PowerShell с правами администратора.
Примеры команд:
# Установка роли Data Deduplication
Install-WindowsFeature -Name FS-Data-Deduplication -IncludeManagementTools
# Включение дедупликации на томе D:
Enable-DedupVolume -Volume D:
# Запуск задачи оптимизации вручную для тома D:
Start-DedupJob -Volume D: -Type Optimization
# Просмотр статуса для тома D:
Get-DedupStatus -Volume D:
# Просмотр свойств дедупликации для тома
Get-DedupVolume -Volume D:Примечание: в командах подставляйте букву тома, например D:, E: и т.д. В GUI Server Manager вы также увидите индикаторы прогресса.
Практическое руководство: SOP для включения Dedup (пошагово)
Перед началом: выполните полную резервную копию тома и тест на небольшом non-production томе.
Шаги:
- Оценка набора данных: определите типы файлов и ожидаемую степень дублирования (виртуальные диски, резервные копии, документы).
- Тестовый запуск: на отдельном томе/виртуальной машине включите Dedup с профильными настройками (Default/Hyper-V).
- Мониторинг производительности: замерьте IOPS и задержки до и после включения. Если время доступа увеличивается, откатите изменения.
- Конфигурация расписания: настройте оптимизацию в «нечасы пик» и установите правила для файлов в возрасте > X дней.
- Добавление исключений: исключите критичные приложения, базы данных, зашифрованные папки.
- Постепенный ввод в эксплуатацию: включайте Dedup по томам, отслеживайте метрики и оценки выгоды (Deduplication Savings).
- Документирование: сохраните конфигурацию и процедуры отката.
Чек-листы по ролям
Для системного администратора:
- Провёл аудит данных и определил подходящие тома.
- Настроил тестовый том и проверил влияние на I/O.
- Настроил резервное копирование перед включением.
- Настроил и протестировал уведомления и мониторинг.
Для инженера по резервному копированию:
- Проверил совместимость dedup с текущим решением бэкапа.
- Оценил, как изменилась скорость создания и восстановления резервных копий.
- Обновил политики инкрементального/директивного бэкапа.
Для менеджера хранилища:
- Оценил потенциальную экономию места и влияние на TCO.
- Согласовал окно обслуживания и план отката.
Критерии приёмки (acceptance)
- Deduplication отмечает положительную экономию места на тестовом томе без значимого ухудшения латентности (по SLA).
- Нет ошибок доступа к файлам и нарушений приложений при тестовом наборе.
- Резервные копии и процесс восстановления работают корректно.
Тестовые сценарии и критерии
- Функциональный тест: включить Dedup на тестовом томе, запустить Start-DedupJob, проверить, что Get-DedupStatus отображает прогресс и запись экономии.
- Производительность: замерить среднюю задержку чтения/записи до и после Dedup при нагрузке, сравнить с допустимыми порогами.
- Восстановление: выполнить восстановление файла из резервной копии и проверить целостность.
- Исключения: убедиться, что перечисленные в исключениях расширения действительно не дедуплицируются.
Runbook при проблемах (быстрый план действий)
Симптом: файлы не открываются или появляются ошибки доступа после включения Dedup.
Шаги:
- Проверить журнал событий Windows (Event Viewer) на события Dedup (Dedup-Management).
- Запустить Get-DedupStatus и Get-DedupJob для проверки текущих задач и ошибок.
- Если задачa зависла — остановить её: Stop-DedupJob -Volume D: -Type Optimization.
- Если проблема сохраняется — временно отключить Dedup на затронутом томе: Disable-DedupVolume -Volume D: (предварительно убедиться в резервной копии).
- Обратиться к резервной копии и выполнить восстановление повреждённых файлов.
- Проанализировать причины: аппаратные ошибки диска, повреждённые метаданные или несовместимость приложений.
Матрица рисков и меры смягчения
- Низкий риск выгоды (низкая дубликация): провести предварительный анализ и тестирование на подмножестве данных.
- Средний риск производительности: запускать оптимизацию в «не-пик» и включать лимиты на использование CPU/IO для задач Dedup.
- Высокий риск повреждения данных: обязательное резервное копирование до включения, тест восстановления.
Совместимость и ограничения
- Дедупликация не поддерживается на системном разделе (C:).
- Не совместима с зашифрованными данными; данные, зашифрованные на уровне файловой системы или приложений, обычно не дедуплицируются.
- Некоторые специализированные приложения (например, базы данных, использующие собственные механизмы хранения) могут конфликтовать — исключайте такие каталоги.
Альтернативы и дополняющие методы
- Компрессия на уровне файловой системы или архивов (если данные высоко сжимаемы).
- Сторонние инструменты дедупликации на уровне агент/сервер (если требуется кросс-платформенная поддержка).
- Хранилищe с встроенной дедупликацией (NAS/SAAS провайдеры), если нужна аппаратная или облачная дедупликация.
- Таргетирование на уровне приложений: убирать дубликаты в источнике (версионирование, контроль дублирования при загрузке).
Лучшие практики и эвристики
- Тестируйте прежде, чем включать на продуктивных томах.
- Исключайте базы данных и системные каталоги.
- Настройте расписание оптимизаций в периоды низкой загрузки.
- Документируйте исключения и правила — это уменьшит риск ошибок при поддержке.
Примеры команд и сценариев автоматизации
Автоматический скрипт проверки и запуска оптимизации по расписанию (для планировщика задач):
# Проверка статуса и запуск оптимизации если не выполняется
$volume = 'D:'
$status = Get-DedupStatus -Volume $volume
if ($status -ne $null) {
$jobs = Get-DedupJob | Where-Object Volume -eq $volume
if ($jobs -eq $null) {
Start-DedupJob -Volume $volume -Type Optimization
}
}Mermaid: решение «включать ли Dedup?»
flowchart TD
A[Начать: Оценка данных] --> B{Тип данных}
B -->|Виртуальные диски, шаблоны| C[Скорее всего: включить Dedup]
B -->|Зашифрованные/сжатые| D[Не включать Dedup]
B -->|Документы/архивы| E[Провести тест на подмножестве]
E -->|Экономия > приемлемого порога| C
E -->|Экономия низкая| D
C --> F[Настроить расписание, исключения, бэкап]
D --> G[Рассмотреть альтернативы: компрессия/сторонние инструменты]Краткий глоссарий (1 строка на термин)
- Deduplication: удаление дубликатов на уровне фрагментов данных.
- Chunk: фрагмент файла для сравнения.
- Reparse point: файловая ссылка на единый фрагмент в хранилище чанков.
- Chunk store: место хранения уникальных фрагментов.
Советы по миграции и масштабированию
- Если планируете масштабировать инфраструктуру, тестируйте Dedup на шаблоне данных каждого класса (VM-образа, документов, медиа).
- Для больших сред используйте мониторинг и метрики (IOPS, latency, %CPU) и интегрируйте оповещения при превышении порогов.
Приватность и соответствие требованиям (GDPR и подобные)
Dedup сам по себе не меняет права доступа или шифрование. Если в среде применяется шифрование данных для соответствия (например, персональные данные), учитывайте, что шифрование мешает дедупликации. Перед внедрением сверяйтесь с политиками безопасности и требованиями по защите данных.
Частые вопросы (кратко)
Q: Можно ли включить Dedup на системном диске C:? A: Нет — системный том обычно не поддерживается для Dedup.
Q: Работает ли Dedup с Azure Files или другими облачными томами? A: Встроенная Windows Data Deduplication предназначена для локальных томов в Windows Server. Для облачных служб проверьте возможности провайдера или применяйте облачные механизмы дедупликации.
Q: Как проверить реальную экономию? A: Используйте Get-DedupStatus и отчёты в Server Manager — там отображается Deduplication Savings.
Итог и рекомендации
Data Deduplication — мощный инструмент для экономии дискового пространства в сценариях с высокой степенью дублирования (виртуальные образы, массивные репозитории документов). Перед массовым развёртыванием обязательно тестируйте на отдельном томе, настройте расписание и исключения, сделайте резервные копии и следите за производительностью.
Если вы используете Windows 11 в клиентских системах, встроенной Dedup нет — используйте ручной поиск дубликатов или проверенные сторонние инструменты (например, CCleaner). Для серверной инфраструктуры — применяйте встроенную службу и автоматизируйте задачи через PowerShell.
Если нужно, могу подготовить готовый скрипт для автоматического развёртывания Dedup по заданным томам и шаблонам исключений, а также чек-лист для приёмки после внедрения.
Источник изображений и скриншотов оставлены без изменений. Все команды PowerShell в статье рассчитаны на запуск с правами администратора.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
