Как использовать команду split в Linux

Что такое команда split?
Команда split — это стандартная утилита командной строки в Unix-подобных системах. Как следует из названия, она предназначена для разделения одного файла на несколько более мелких файлов. Идея проста: вместо работы с единственным большим файлом вы получаете набор частей, которые легче хранить, пересылать и обрабатывать.
Короткое определение: split — разделяет файл на подфайлы по заданным критериям.
Кому полезна: системным администраторам, разработчикам, обработчикам данных и всем, кто работает с большими текстовыми или бинарными файлами.
Историческая справка: авторы оригинальной реализации включают Торбьорна Гранлунда и Ричарда М. Столлмана; современная реализация присутствует в GNU coreutils.
Синтаксис команды split
split [OPTION]... [FILE] [PREFIX]- OPTION — опции, задающие способ разделения (по строкам, по байтам, количество частей и т.д.).
- FILE — исходный файл. Если не указан, split читает из stdin.
- PREFIX — префикс для имён выходных частей; по умолчанию ‘x’.
Популярные опции:
- -l N — разделить по N строк в каждом фрагменте;
- -b SIZE — разделить по SIZE байт (поддерживает суффиксы K, M, G);
- -n K — разделить на K частей (равномерно по содержимому);
- -a N — длина суффикса (по умолчанию 2);
- -d — использовать цифровые суффиксы вместо буквенных;
- –numeric-suffixes — то же, что и -d (в новых версиях coreutils).
Ниже — практические примеры и важные советы.
Разделение по числу строк
Иногда удобнее разделять по строкам, например при обработке логов или CSV.
Синтаксис:
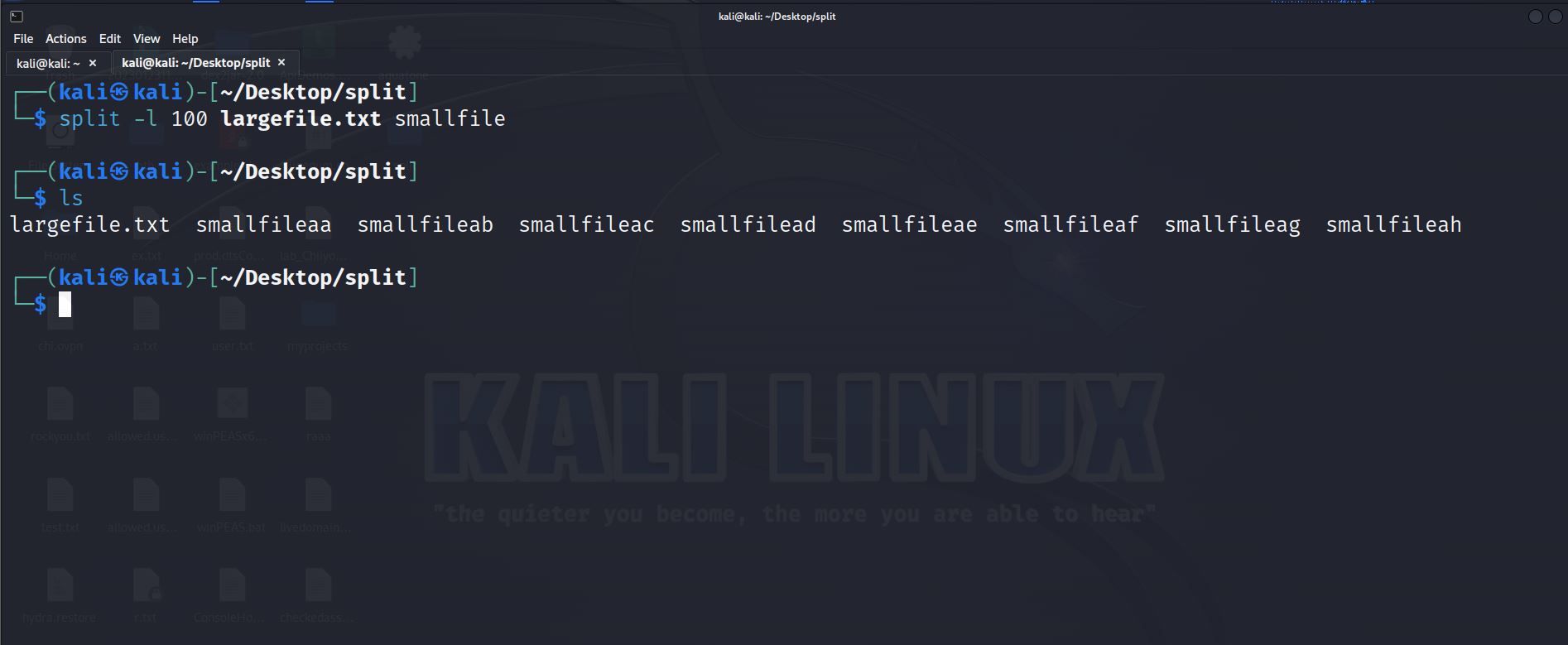
split -l <число_строк> <входной_файл> <префикс>Пример: разделить файл largefile.txt на части по 100 строк:
split -l 100 largefile.txt smallfileПосле выполнения вы получите файлы smallfileaa, smallfileab и т.д. (если не использовать -d).
Советы:
- Для текстовых файлов с CRLF (Windows) учитывайте перевод строк при подсчёте.
- Если вход идёт из конвейера, omit аргумент FILE и используйте: some_command | split -l 100 - output_prefix
Разделение по размеру
Разделение по байтам удобно, когда нужно уложиться в лимит носителя или пересылки.
Синтаксис:
split -b <размер> <входной_файл> <префикс>Размер можно указывать с суффиксами: K=1024, M=1024K, G=1024M.
Пример: разбить на части по 300 байт:
split -b 300 largefile.txt smallfile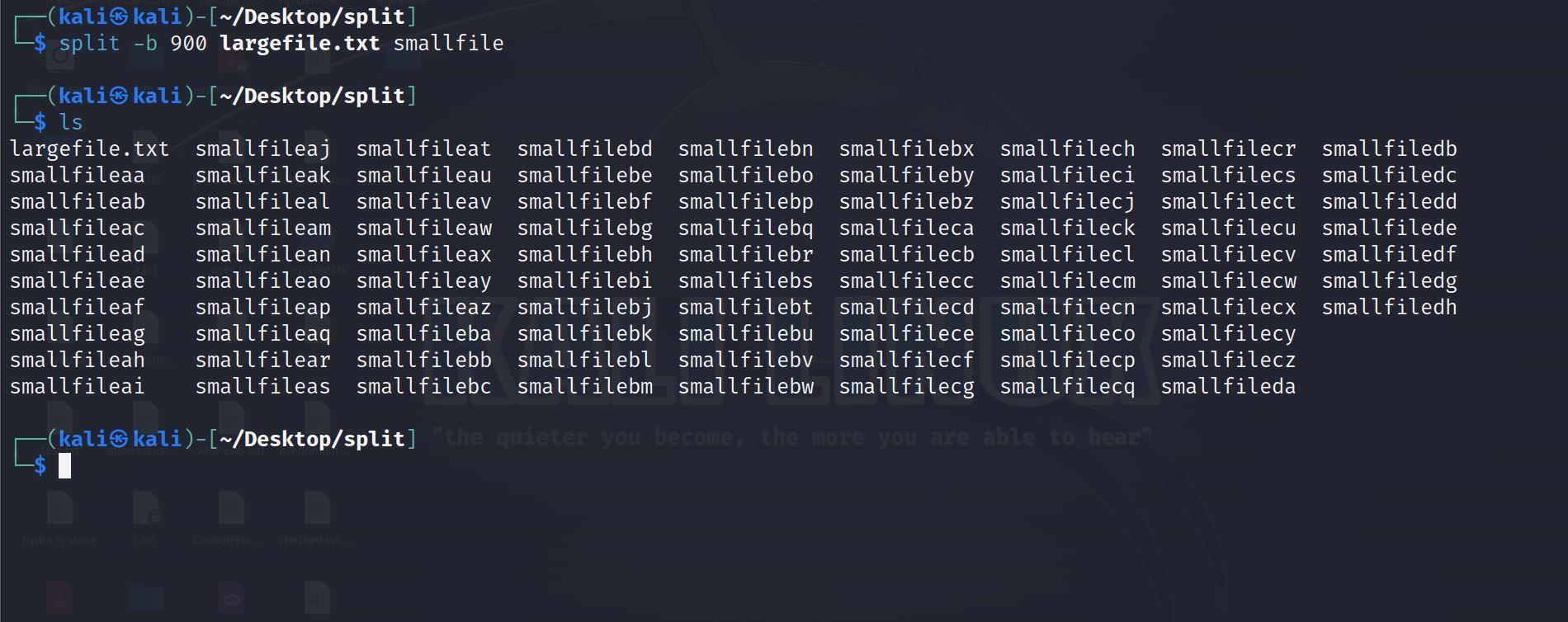
Замечание по бинарным файлам: split не заботится о границах форматов (например, целые записи в БД или изображения). Для «безопасного» разбиения записей используйте инструменты, понимающие формат (awk, csplit, специализированные конвертеры).
Разделение на заданное количество частей
Иногда важнее получить ровно K частей, нежели части определённого размера.
Синтаксис:
split -n <число_частей> <входной_файл> <префикс>Пример: разделить на 5 частей:
split -n 5 largefile.txt smallfile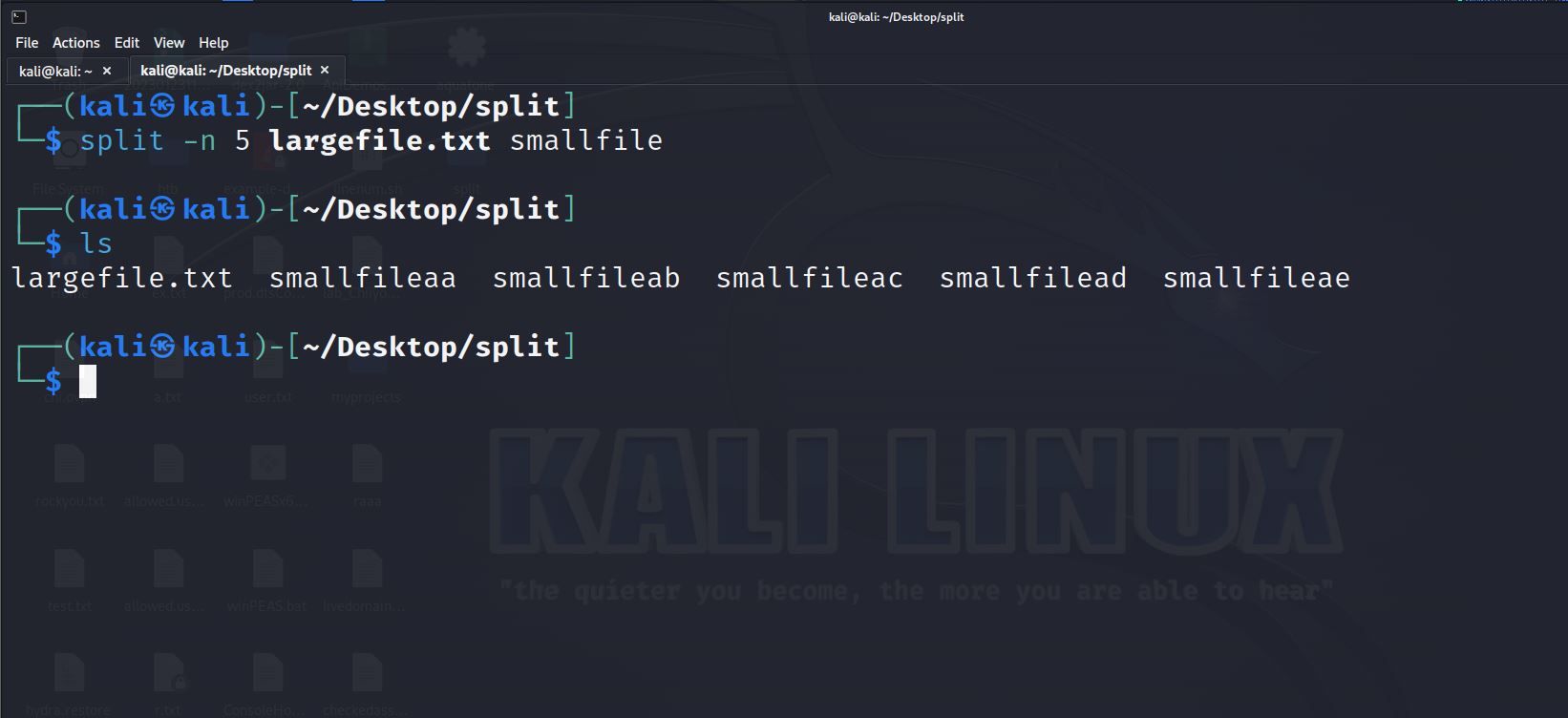
- По умолчанию split старается распределить строки равномерно; для побайтного распределения используйте дополнительные опции.
Управление длиной суффикса и цифровые суффиксы
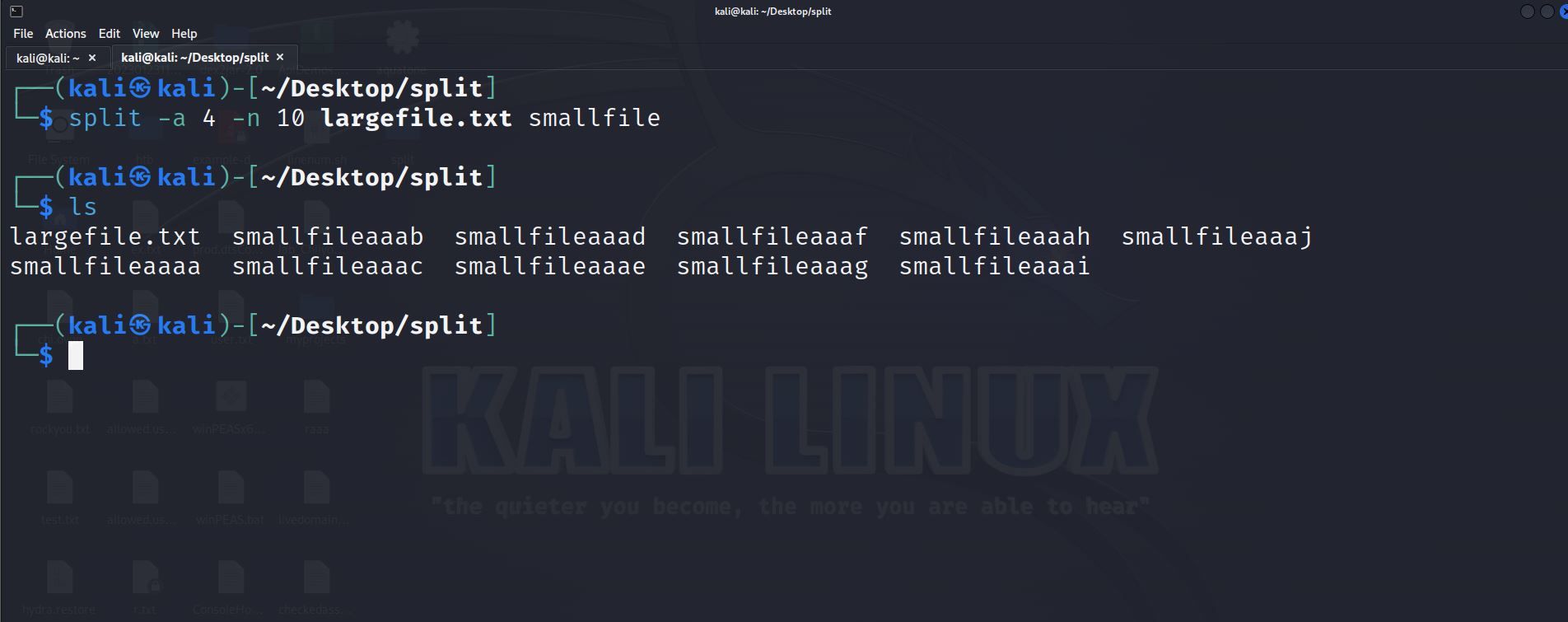
По умолчанию суффикс длиной 2 (aa, ab…) может закончиться при большом числе частей. Для увеличения длины суффикса используйте -a:
split -a 4 -n 10 largefile.txt smallfileДля цифровых суффиксов используйте -d — получится smallfile00, smallfile01 и т.д. Это удобно для сортировки и автоматизации.
Объединение частей с помощью cat
Чтобы восстановить исходный файл, используйте команду cat:
cat <части> > <выходной_файл>Если префикс — smallfile и суффиксы идут в естественном порядке, простая маска работает:
cat smallfile* > bigfile.txtВажно: порядок файлов при использовании шаблонов (globs) зависит от имени. Для корректного порядка используйте либо цифровые суффиксы (-d), либо сортировку по версии:
cat $(ls -v smallfile*) > bigfile.txtДля очень большого числа частей лучше генерировать список файлов с помощью printf/seq, чтобы избежать проблем с длинной командной строки:
printf "%s\n" smallfile* | sort -V | xargs cat > bigfile.txtДля бинарных файлов соединение через cat обычно безопасно, если вы уверены, что фрагменты не повреждены.
Когда split не подходит (контрпримеры)
- Если файл содержит записи фиксированного размера и разрез может нарушить границу записи — используйте инструмент, понимающий формат, например csplit для текстовых разделителей или специализированный парсер для бинарных форматов.
- Если нужно параллельно загружать части в облако с проверкой контрольных сумм и возобновлением — лучше применять rsync, rclone или утилиты с поддержкой разделения и продолжения.
- Для очень больших данных, где требуется распределённая обработка и контроль версий — используйте инструменты ETL или распределённые файловые системы.
Альтернативные подходы и инструменты
- csplit — разделяет по шаблонам в содержимом (удобно для логов и текстовых форматов).
- awk/sed — позволяет гибко резать по содержимому (заголовки, маркеры).
- Python/Perl скрипты — дают полный контроль над логикой разделения и обработкой.
- archiving (tar/gzip + split) — если нужно передать архив, сначала упакуйте, затем разделите: tar czf - largefile | split -b 100M - archivepart
Пример: упаковать и разделить поток:
tar czf - folder/ | split -b 50M - archive-part-Чтобы восстановить: cat archive-part-* | tar xzf -
Шпаргалка (cheat sheet)
| Задача | Команда |
|---|---|
| Разбить по 100 строк | split -l 100 largefile.txt smallfile |
| Разбить по 10 МБ | split -b 10M largefile.bin part_ |
| Разбить на 8 частей | split -n 8 largefile.txt p_ |
| Использовать цифровые суффиксы | split -d -a 3 -b 1M file out_ |
| Слияние всех частей | cat out_* > restored.file |
Чек-лист для ролей
Для разработчика:
- Убедиться, что части нумеруются предсказуемо (-d или -a с достаточной длиной).
- Проверять границы записей при обработке форматов.
- Писать тесты на восстановление данных после split+cat.
Для системного администратора:
- Контролировать права доступа на создаваемые части.
- Если передаёте части по сети — применять контрольные суммы (sha256sum).
- Удалять временные части после проверки целостности.
Для инженера данных:
- При разделении CSV не ломать заголовки: можно скопировать заголовок в каждую часть.
- Использовать awk или Python для сохранения заголовка в частях.
Краткая методика (минимальный SOP)
- Оцените формат исходного файла (текст/бинарный, наличие заголовков).
- Выберите критерий разделения (строки, байты, число частей).
- Выполните split с опциями -a и -d при необходимости.
- Проверьте первые и последние байты/строки нескольких частей.
- Объедините части в тестовой среде и сравните контрольные суммы с оригиналом.
- Удалите или архивируйте части после успешной проверки.
Критерии приёмки
- Файл после объединения идентичен исходному (сравнить sha256sum).
- Число созданных частей соответствует ожидаемому.
- Имена частей упорядочиваются естественно для удобного объединения.
- Нет утечек прав доступа или жизненно важных данных в временных файлах.
Глоссарий (1 строка)
- Префикс — начальная часть имени файла, к которой добавляется суффикс при split.
- Суффикс — окончание имени файла (aa, 00 и т.д.), генерируемое split.
Заключение
Команда split — простой, но мощный инструмент для разбиения файлов в Linux. Она экономит время при передаче и обработке больших файлов и легко комбинируется с другими утилитами (cat, tar, awk, Python). Выбирайте режим разделения, соответствующий формату данных, и всегда проверяйте целостность при объединении.
Резюме:
- split подходит для большинства задач по разделению файлов;
- используйте цифровые суффиксы и увеличенную длину суффикса для большого числа частей;
- при работе с форматами записей применяйте инструменты, понимающие структуру файла;
- всегда проверяйте контрольные суммы после объединения.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
