TEXTSPLIT, TEXTBEFORE и TEXTAFTER в Excel


Excel предлагает большой набор функций для работы со строками: от простых LEFT/RIGHT до динамических массивов и новых текстовых функций. В этой статье подробно рассмотрим TEXTSPLIT, TEXTBEFORE и TEXTAFTER: синтаксис, параметры, практические примеры, частые ошибки и рекомендации по выбору инструмента.
Краткое определение
- TEXTSPLIT — разделяет текст по разделителям и возвращает массив, который «выливается» в соседние ячейки. Простая замена мастера «Текст по столбцам» с динамическими массивами.
- TEXTBEFORE — возвращает часть строки до указанного разделителя или до его N‑й вхождения.
- TEXTAFTER — возвращает часть строки после указанного разделителя или после его N‑й вхождения.
Содержание
- Что делает каждая функция
- Синтаксис и параметры
- Простые и продвинутые примеры
- Когда функции не подходят и альтернативы
- Чеклист для аналитика и тесты приёмки
- Краткая справка и рекомендации
Что делает функция TEXTSPLIT
TEXTSPLIT разбивает строку по одному или нескольким разделителям и возвращает двумерный массив (строки и/или столбцы). В итоге Excel автоматически разместит части в соседних ячейках (spill). Это удобно при импорте списков, CSV или данных с несколькими полями в одной ячейке.
Синтаксис:
=TEXTSPLIT(text, col_delimiter, [row_delimiter], [ignore_empty], [match_mode], [pad_with])Параметры (кратко):
- text — текст или ссылка на ячейку с текстом.
- col_delimiter — разделитель для столбцов (символ или текст).
- row_delimiter — необязательный разделитель для строк (например “\n”).
- ignore_empty — TRUE/1 чтобы игнорировать пустые элементы, FALSE/0 по умолчанию.
- match_mode — 0 чувствительный к регистру, 1 нечувствительный.
- pad_with — значение для заполнения отсутствующих элементов при двухмерном выводе (по умолчанию #N/A).
Важно: только text и col_delimiter обязательны; остальные параметры опциональны.
Пример простой задачи
Предположим, в ячейке B2 список SaaS-продуктов через запятую: “Notion, Slack, Zoom, Figma”. Разделить по запятой:
=TEXTSPLIT(B2, ",")Результат: диапозон ячеек вправо (spill) с отдельными названиями.
Несколько разделителей
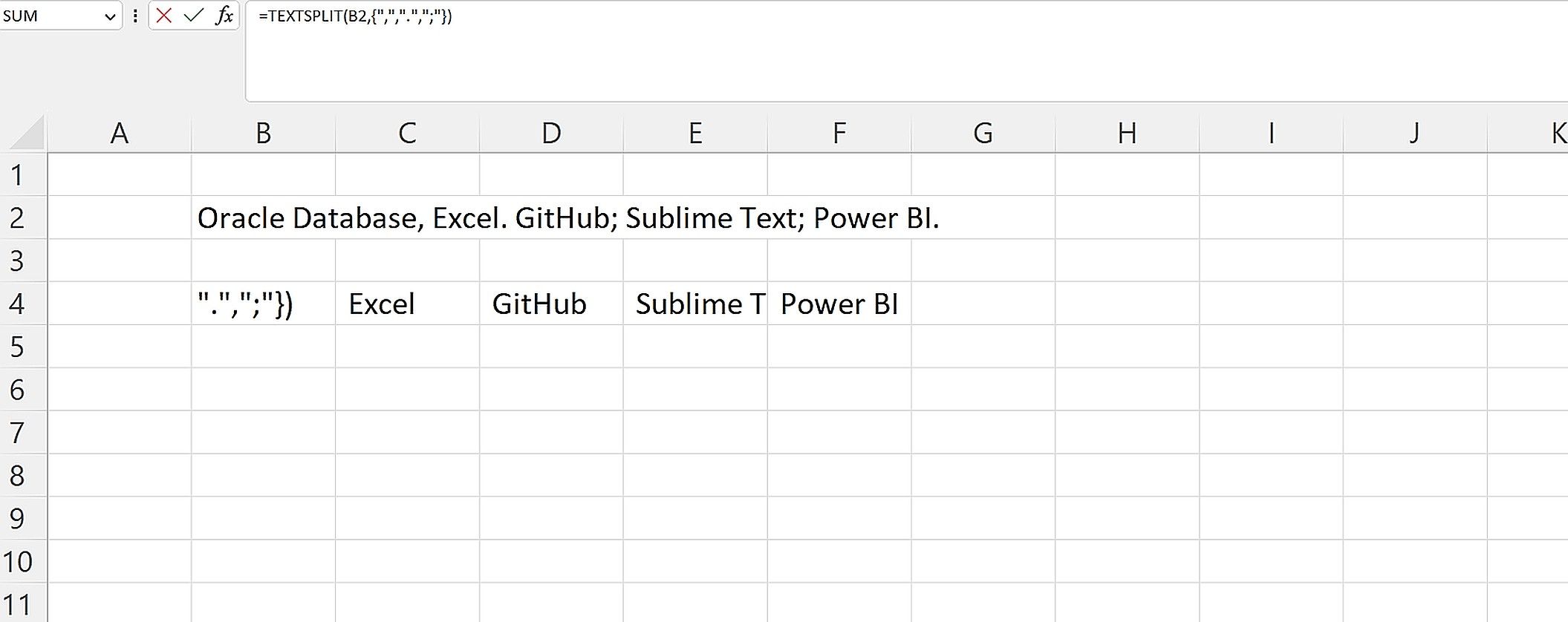
Если в данных используются разные разделители (запятая, точка с запятой, точка), перечислите их в массиве:
=TEXTSPLIT(B2, {",", ".", ";"})Заметка: массив разделителей указывайте в фигурных скобках. Это удобно при неконсистентных данных.
Продвинутый пример — двумерный вывод
Если строка содержит два уровня разделения, например “Категория|Подкатегория;Товар1,Товар2”, можно задать col_delimiter и row_delimiter одновременно, и функция вернёт двумерную матрицу.
Что делает функция TEXTBEFORE
TEXTBEFORE возвращает часть строки, расположенную слева от первого или N‑го вхождения разделителя. По сути — более гибкая альтернатива LEFT, когда разделитель известен.
Синтаксис:
=TEXTBEFORE(text, delimiter, [instance_num], [match_mode], [match_end], [if_not_found])Параметры:
- text — исходный текст.
- delimiter — разделитель (строка или символ).
- instance_num — какое по счёту вхождение разделителя использовать (по умолчанию 1).
- match_mode — 0 чувствительный к регистру, 1 нечувствительный.
- match_end — 0 обычное совпадение, 1 разрешает совпадение с концом строки.
- if_not_found — значение, возвращаемое при отсутствии разделителя (по умолчанию #N/A).
Ограничение: символы подстановки (wildcards) не поддерживаются.
Пример извлечения имени
В столбце B список имён вида “Ifeoma Sow”. Чтобы получить первое имя:
=TEXTBEFORE(B2, " ")Затем растяните формулу вниз.
Частые варианты
- Если имя двойное (“Анна-Мария Иванова”), можно использовать дополнительную логику для сохранения дефиса.
- Для извлечения фамилии используйте TEXTAFTER (см. ниже) или комбинируйте TEXTAFTER для последнего пробела.
Что делает функция TEXTAFTER
TEXTAFTER возвращает часть строки, расположенную справа от первого или N‑го вхождения разделителя — прямо противоположна TEXTBEFORE.
Синтаксис ровно такой же, как у TEXTBEFORE:
=TEXTAFTER(text, delimiter, [instance_num], [match_mode], [match_end], [if_not_found])Пример: список веб‑адресов в B2, нужно получить имя домена до точки:
=TEXTAFTER(B2, ".")Результат — часть строки после первой точки. Если требуется текст до первой точки (то есть имя сайта без subdomain), применяйте комбинацию TEXTBEFORE(TEXTAFTER(…)) или регулярную логику через Power Query.
Практические советы и паттерны использования
- Очистка CSV‑полей: TEXTSPLIT полезен при небольших наборах; для больших таблиц рассматривайте Power Query.
- Обработка e‑mail: чтобы получить логин используйте TEXTBEFORE(email, “@”), домен — TEXTAFTER(email, “@”).
- Извлечение расширения файла: TEXTAFTER(filename, “.”, -1) — но учтите, что instance_num поддерживает отрицательные номера не во всех версиях; предпочтительнее искать последнее вхождение через более сложные конструкции или Power Query.
- Игнорирование пустых: set ignore_empty=1 чтобы избавиться от последовательных разделителей.
- Чувствительность к регистру: задавайте match_mode, если разделитель может встречаться в разном регистре и это критично.
Важно: поведение функций зависит от версии Excel. Новые функции (TEXTSPLIT, TEXTBEFORE, TEXTAFTER) доступны в Microsoft 365 и некоторых свежих сборках Office. Если у вас старая версия Excel, они могут отсутствовать.
Когда эти функции не подходят и альтернативы
- Если нужна сложная логика разбора (регулярные выражения, вложенные шаблоны) — используйте Power Query или VBA.
- Для очень больших наборов данных Power Query часто быстрее и проще в поддержке, чем формулы в ячейках.
- В Google Sheets аналогичную задачу решают функции SPLIT, REGEXEXTRACT, REGEXREPLACE.
Альтернативные подходы:
- Text to Columns — быстрый интерактивный инструмент для разовых задач.
- Flash Fill — полезно при распознавании шаблонов по примерам.
- Power Query — для ETL: надёжно, повторяемо и масштабируемо.
Ментальные модели и эвристики
- Если задача одноразовая и простая — используйте TEXTSPLIT/TEXTBEFORE/TEXTAFTER в листе.
- Если нужна повторяемость и обработка десятков тысяч строк — Power Query.
- Если требуется поочерёдное извлечение N‑го фрагмента — TEXTSPLIT с массивом и индексами проще, чем многократные TEXTBEFORE/TEXTAFTER.
Decision tree для выбора функции
flowchart TD
A[Нужно разделить текст?] --> B{Есть несколько разделителей?}
B -- Да --> C[TEXTSPLIT с массивом разделителей]
B -- Нет --> D{Нужна часть до/после разделителя?}
D -- До --> E[TEXTBEFORE]
D -- После --> F[TEXTAFTER]
C --> G{Большой объём или повторяемость?}
G -- Да --> H[Power Query]
G -- Нет --> I[Оставить формулы]
E --> I
F --> IЧеклист для аналитика перед применением функций
- Убедиться, что версия Excel поддерживает функции.
- Проверить, какие разделители встречаются в данных.
- Решить: одноразовая очистка или повторяемая трансформация.
- Подумать о пустых значениях и параметре ignore_empty.
- Написать тестовые случаи (см. ниже).
Тесты приёмки и примеры кейсов
- Вход: “A,B,,C” при ignore_empty=0 — ожидание: пустой элемент между B и C.
- Вход: “A;B.C” с разделителями {“;”,”.”} — ожидание: три элемента A, B, C.
- Вход: “john.doe@example.com” — TEXTBEFORE(…, “@”) -> “john.doe”; TEXTAFTER(…, “@”) -> “example.com”.
- Отсутствие разделителя: TEXTBEFORE(“abc”,”;”) с if_not_found задано “-“ -> результат “-“.
Критерии приёмки:
- Функция корректно обрабатывает заданные разделители.
- Нет неожиданного смещения столбцов/строк (spill поведение).
- Обработаны пустые и краевые случаи (начало/конец строки).
Частые ошибки и как их избежать
- Ошибка: использование устаревшей версии Excel. Решение: проверить подписку Microsoft 365 или использовать Power Query/VBA.
- Ошибка: неправильный массив разделителей. Решение: тестировать на наборе примеров и ставить ignore_empty=1 при необходимости.
- Ошибка: предположение о последнем вхождении разделителя. Решение: явно указывать instance_num или комбинировать функции.
Мини‑руководство по быстрой задаче
Задача: из столбца B с адресами в формате “user@sub.domain.com” получить только основной домен (например, “domain”). Шаги:
- Получить часть после “@”: =TEXTAFTER(B2, “@”).
- Получить часть до первой точки из результата: =TEXTBEFORE(TEXTAFTER(B2, “@”), “.”).
Если нужен последний уровень (например, “com”), используйте =TEXTAFTER(B2, “.”, -1) если ваша версия поддерживает отрицательные индексы, иначе применяйте последовательные преобразования.
Краткий глоссарий
- Spill — автоматическое заполнение соседних ячеек массивом результатов.
- Разделитель — символ или текст, по которому разбивается строка.
- Power Query — ETL-инструмент в Excel для трансформации данных.
Резюме
- TEXTSPLIT, TEXTBEFORE и TEXTAFTER экономят время при обработке строк и подходят для большинства задач очистки и парсинга в листах.
- Для повторяемых, сложных или больших трансформаций предпочтительнее Power Query.
- Тестируйте на реальных образцах данных, учитывайте пустые элементы и регистр.
Важно: проверьте доступность этих функций в вашей сборке Excel перед массовым внедрением.
Краткие рекомендации:
- Начните с небольшого тестового диапазона.
- Сохраните исходные данные до применения массовых формул.
- Документируйте логику (какие разделители использованы, какие допущения сделаны).
Похожие материалы

Загрузить подкаст в Spotify for Podcasters
VC Runtime Minimum X86.msi: скачать и исправить ошибку

Удалить Bing из Chrome — инструкция

Восстановить удалённое приложение на iPhone

Как настроить заметку в Google Keep
