Как использовать регулярные выражения для поиска и экономии времени

TL;DR
Регулярные выражения (regex) — компактный способ описать шаблоны для поиска, фильтрации и переименования файлов. Они экономят время при массовых операциях, но требуют аккуратного тестирования и экранирования в командной оболочке. В статье — объяснение синтаксиса, примеры для grep, контрольные списки, методика разработки и набор готовых шаблонов.
Быстрые ссылки
- Что такое регулярные выражения?
- Об экранировании символов
- Как строятся шаблоны
- Границы и якоря
- Краткий справочник синтаксиса
- Готовые шаблоны и примеры
- Когда регулярные выражения не подходят
- Альтернативные подходы
- Методика разработки и тестирования
Что такое регулярные выражения?
Регулярные выражения — это компактный текстовый язык для описания шаблонов строк. Коротко: regex (или regexp) — это шаблон, который сопоставляется с текстом и позволяет найти, извлечь или заменить соответствующие фрагменты. Примеры применения:
- Поиск строк в логах и исходниках кода.
- Фильтрация результатов при grep/ack/rg (ripgrep).
- Массовое переименование файлов в батч-утилитах.
- Валидация полей в формах (email, телефон) в приложениях.
Ключевая идея: один компактный шаблон описывает множество возможных строк, которые программа при обработке будет рассматривать как совпадения.
Термины в одной строке
- Символы: конкретные буквы/цифры.
- Классы символов: наборы в [ ] — один символ из набора.
- Квантификаторы: *, +, ?, {m,n} — сколько повторений.
- Якоря: ^, $, \b, \<, > — границы строки/слова.
- Группы: ( … ) — группа для захвата или логики.
- Альтернация: | — логическое «или».
Об экранировании символов
Некоторые символы имеют специальный смысл в regex и/или в вашей оболочке (bash, PowerShell). При комбинировании нужно учитывать оба уровня интерпретации.
- Внутри регулярного выражения специальные символы: . ^ $ * + ? ( ) [ ] { } | \ — их иногда нужно экранировать слэшем:
\.. - В командной строке bash обратный слэш и кавычки тоже интерпретируются, поэтому часто используют одинарные кавычки, чтобы передать строку как есть.
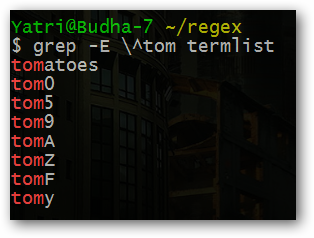
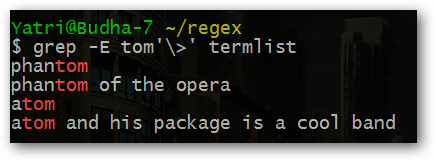
Пример (показано намеренно подробно): если вы хотите искать литерал символа < с помощью grep, демонстрация сравнения:
Короткое объяснение: bash попытается обработать слэши, поэтому в командной строке вам иногда нужны дополнительные слэши или кавычки.
Пример 1 — без оболочечного вмешательства (используйте одинарные кавычки):
grep '\<' file.txtПример 2 — если вы записываете строку без одинарных кавычек и вручную эскейпите:
grep \\\< file.txtПояснение: в примере выше каждая дополнительная оболочечная интерпретация требует дополнительно удвоенного слэша. Чтобы не путаться — ставьте выражение в одинарные кавычки.
Важно: GUI-приложения (редакторы, инструменты для переименования) часто не требуют оболочечного экранирования и принимают «чистое» регулярное выражение.
Как строятся шаблоны: основные примеры
Простейший пример расширения шаблона:
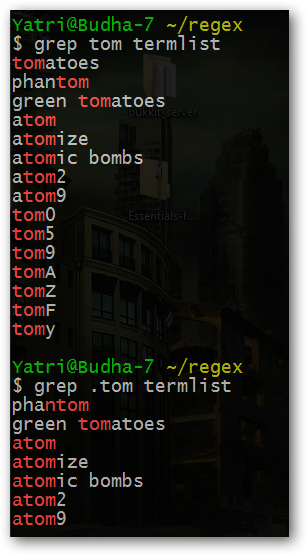
tom[0123456789]Смысл: квадратные скобки задают набор символов (character class). В данном случае шаблон найдет «tom0», «tom1», … «tom9». Обратите внимание на кейс: большинство реализаций чувствительны к регистру (case-sensitive). Чтобы найти оба варианта, используйте флаги или явно указанный набор: [Tt]om.
Если требуется любой символ на месте одного символа, используйте точку:
.tomЗдесь точка соответствует ровно одному любому символу, включая пробел. Шаблон .tom найдет «aTom», « tom», «@tom», но не «tom» (потому что перед «tom» должен быть еще один символ).
Альтернация (логическое «или»):
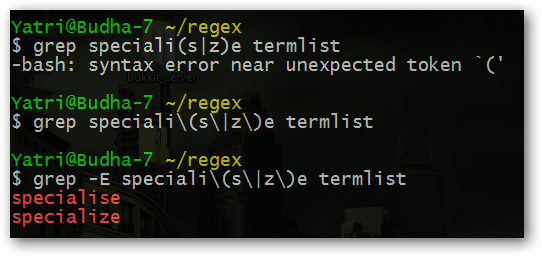
speciali(s|z)eНайдет specialise и specialize.
Если используете grep в bash, включите расширенные регулярные выражения (-E) и экранируйте специальные символы оболочки при необходимости:
grep -E 'speciali(s|z)e' file.txtИсключение через отрицание в классе символов:
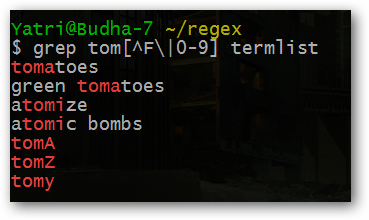
tom[^F0-9]Здесь [^...] означает «любой символ, не входящий в набор». Важно: внутри квадратных скобок дефисы, точки и другие символы меняют семантику, поэтому внимательно расставляйте экранирование.
Границы и якоря
Для задания положения совпадения используют якоря — они не захватывают символы, а указывают, где совпадение должно начинаться или заканчиваться.
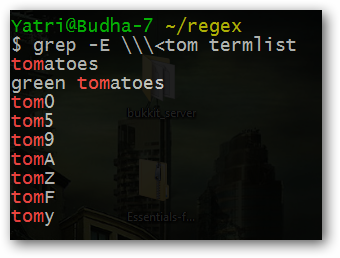
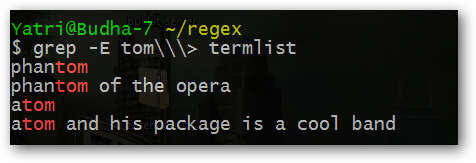
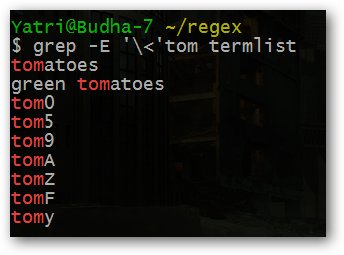
^— начало строки:^tomнайдет строки, начинающиеся с «tom».$— конец строки:tom$найдет строки, заканчивающиеся на «tom».\b— граница слова в большинстве диалектов (word boundary).\<и\>— начало/конец слова в некоторых реализациях grep; в bash их часто экранируют или держат в одинарных кавычках:grep '\
Примеры:
grep '^tom' file.txt # строки, где tom в начале
grep 'tom$' file.txt # строки, где tom в конце
grep '\' file.txt # слово tom как отдельный токен Обратите внимание на экранирование против оболочки и самой регулярной системы. В GUI-редакторах часто достаточно \b.
Краткий справочник синтаксиса (cheat sheet)
- . — любой символ (кроме перевода строки, в зависимости от режима).
- \d — цифра (в некоторых диалектах эквивалент [0-9]).
- \D — не цифра.
- \w — буквенно-цифровой символ или подчеркивание.
- \W — не буквенно-цифровой.
- \s — пробельный символ.
- \S — не пробельный.
- [abc] — любой символ a, b или c.
- [a-z] — диапазон символов (латинские буквы).
- [^…] — отрицание внутри класса.
- (?:…) — негруппирующая скобка (если не нужен захват).
- (…) — группирует и захватывает.
- a|b — альтернация.
- — 0 или более повторений.
- — 1 или более.
- ? — 0 или 1.
- {m} — ровно m повторений.
- {m,} — m или более.
- {m,n} — от m до n.
Совет: при сложных выражениях используйте именованные группы, если диалект их поддерживает: (? — это облегчает чтение и доступ к частям совпадения в коде.
Готовые шаблоны и примеры
Ниже подборка типичных задач и соответствующих шаблонов (универсальные, требуют проверки в вашем диалекте):
- Найти все email-подобные строки (упрощённо):
[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}- Найти даты в формате YYYY-MM-DD:
\b\d{4}-\d{2}-\d{2}\b- Найти IP-адрес (упрощённо, для чисел 0-255 используйте более сложное выражение):
\b(?:\d{1,3}\.){3}\d{1,3}\b- Переименование файлов с номером: заменить
file_123.txtнаfile-00123.txt(с использованием инструмента переименования с поддержкой регулярных групп):
По шагам: захватите имя и номер, затем используйте подстановку $1-0$2 или аналог в GUI-инструменте.
- В grep: вывести только совпадения, а не всю строку:
grep -o 'pattern' file.txt- Игнорировать регистр:
grep -i 'pattern' file.txtПримеры проверки и тест-кейсы
Тестируйте каждый шаблон на наборе «положительных» и «отрицательных» примеров:
- Положительные: строки, которые обязательно должны матчиться.
- Отрицательные: похожие строки, которые не должны матчиться.
Пример для шаблона ^tom[0-9]$:
Положительные:
- tom1
- tom9
Отрицательные:
- tomato
- Tom1 (из-за регистра)
- atom1 (не с начала строки)
Критерии приёмки:
- Все положительные примеры возвращают совпадение.
- Все отрицательные примеры не возвращают совпадение.
Когда регулярные выражения не подходят
Регулярные выражения мощные, но не универсальные. Одна фраза: regex хорош для регулярных языков, но плохо подходит для вложенных или рекурсивных структур (например, корректное парсирование HTML/XML с произвольной вложенностью). Примеры случаев, когда лучше выбрать другой инструмент:
- Парсинг грамматик с вложенной рекурсией — используйте парсеры (ANTLR, парсинг на основе дерева).
- Валидация сложных форматов (например, полная проверка URL/URI) — лучше пользоваться специализированными библиотеками.
- Сложная логика замены, требующая контекстной информации — лучше написать маленькую программу.
Важно: не пытайтесь брать на себя тот код, который проще выразить явно — читаемость и поддерживаемость важнее компактности шаблона.
Альтернативы
- Парсеры и генераторы грамматик (когда нужен синтаксический анализ).
- Библиотеки формата/валидации (email-validator, url-parse).
- Комбинация простых строковых операций + фильтров в языке (например, Python: split/startswith/endswith).
- Инструменты быстрого поиска: ripgrep (rg) — быстрее и удобнее в некоторых сценариях, чем классический grep.
Методика: как создавать и тестировать regex — пошагово
- Определите цель: что именно нужно найти/заменить.
- Сформируйте «плюс» и «минус» наборы примеров.
- Начинайте с простого шаблона и постепенно добавляйте ограничения.
- Тестируйте каждое изменение на наборах.
- Проверяйте крайние случаи (пустые строки, очень длинные строки, символы Unicode).
- Документируйте шаблон: добавьте короткий комментарий и примеры использования.
- Если доступно, используйте флаги (i, m, s) вместо костыля с классами символов.
Мини-правило: «Сначала написать простое, потом добавить ограничения» — помогает избежать чрезмерно сложных нерегулярных выражений.
Контрольный список ролей (что проверяют разработчик, тестировщик, администратор)
Разработчик:
- Есть ли юнит-тесты для ключевых шаблонов?
- Используются ли именованные группы для читаемости?
- Зафиксирован ли диалект regex и флаги?
Тестировщик:
- Проведены ли тесты с положительными и отрицательными примерами?
- Проверены ли пограничные случаи и Unicode?
Системный администратор / DevOps:
- Корректно ли экранируются шаблоны при запуске в оболочке?
- Есть ли ограничения по длине строки для утилит (grep/awk)?
Примеры использования в разных средах
- Bash + grep:
grep -E 'pattern' file.txtилиgrep -P(Perl-совместимый) на некоторых системах. - Python:
reмодуль,re.compile(pattern)и методыmatch,search,findall,sub. - JavaScript:
/pattern/gmi— литерал регулярного выражения с флагами. - Tools: Sublime Text, VS Code, Notepad++ — все поддерживают regex в поиске.
Безопасность и производительность
- Некоторые выражения могут вызывать «catastrophic backtracking», что приводит к сильной задержке или DoS при больших входных данных. Избегайте чрезмерно амбивалентных шаблонов с вложенными квантификаторами:
^(a+)+$— потенциально опасно. - При обработке больших файлов предпочитайте потоковую обработку и инструменты с хорошей производительностью (ripgrep).
Полезные ресурсы
- Zytrax — разбор конкретных примеров и тонкостей.
- Regular-Expressions.info — исчерпывающий справочник и объяснения.
- GNU grep — документация по regex в grep.
- RegExr (онлайн) — интерактивный тестер, подсветка и объяснение компонентов шаблона.
Решение: использовать ли regex или нет? (decision tree)
flowchart TD
A[Нужно ли найти/заменить текст по шаблону?] --> B{Структура вложенная или рекурсивная?}
B -- Да --> C[Использовать парсер или специализированную библиотеку]
B -- Нет --> D{Нужно ли очень высокая производительность?}
D -- Да --> E[Использовать optimized tool 'rg' или писать на языке с быстрым regex движком]
D -- Нет --> F[Использовать регулярные выражения, тестировать наборы]
E --> F
C --> FМного практики: набор готовых примеров и сниппетов
- Поиск слов, начинающихся с
preи заканчивающихся цифрой:\bpre\w*\d\b. - Удаление лишних пробелов (в Python):
re.sub('\s+', ' ', text). - Захват имени и номера:
^(.*?)[-_](\d+)\.(txt|log)$— группы $1 и $2 можно использовать для переименования.
Когда всё ещё нужно больше — советы по отладке
- Разбивайте большое выражение на более мелкие и тестируйте по частям.
- Используйте онлайновые тестеры, чтобы визуализировать группы и совпадения.
- Добавляйте комментарии в длинные выражения (в диалектах, поддерживающих
xфлаг) для читаемости.
Итог и рекомендации
- Начинайте с простых шаблонов и постепенно добавляйте ограничения.
- Всегда тестируйте на реальных примерах (положительных и отрицательных).
- Документируйте диалект regex и используемые флаги в проекте.
- Для массовых операций используйте инструменты с поддержкой regex (grep, rg, утилиты переименования), но не забывайте про оболочечное экранирование.
Если у вас есть интересный случай использования регулярных выражений, любимая утилита для массового переименования или хитрость с grep — поделитесь в комментариях.
Коротко: регулярные выражения — мощный инструмент, но требуют дисциплины, тестирования и понимания ограничений. Правильный выбор инструмента и аккуратная отладка дают огромную экономию времени.
Похожие материалы

Как сайты отслеживают вас и как защитить приватность

Где iTunes хранит резервные копии iOS — найти, удалить, перенести

Удаление истории поиска Google за 15 минут
Google Keep: советы и шаблоны для продуктивности

Пакеты Snap в Ubuntu 20.04 — обзор и руководство