AWS Transcribe — автоматическая транскрипция аудио в S3

Быстрые ссылки
- AWS Transcribe преобразует аудиофайлы в S3
Краткое определение: Transcribe — управляемый сервис AWS для преобразования речи в текст. Он берет аудиофайл из S3 и возвращает JSON с расшифровкой, оценками уверенности и альтернативами.
AWS Transcribe преобразует аудиофайлы в S3
Transcribe прост в использовании: укажите файл в S3, запустите задание — и получите результат. Оплата идёт по длительности аудио: примерная ставка в статье — $0.0004 за секунду. По этой ставке двухчасовая встреча (~7200 с) обойдётся примерно в $2.88, а двухминутное видео — примерно в $0.06.
Важно: Transcribe ориентирован на пакетную (после записи) обработку. Для задач с низкой задержкой и интерактивного распознавания речи стоит изучить AWS Lex или специализированные стриминг-решения.
Простой тест в консоли
- Перейдите в AWS Transcribe Console.
- Нажмите «Start Streaming», чтобы протестировать службу с микрофона устройства.
- Для реальной работы используйте «Transcription Jobs» → «Create Job».
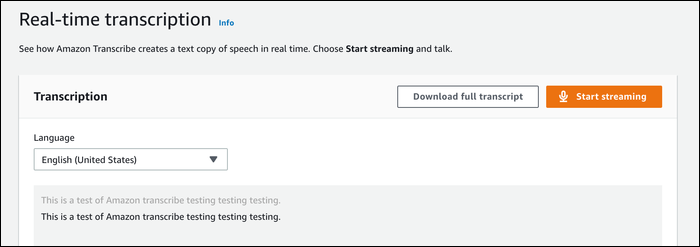
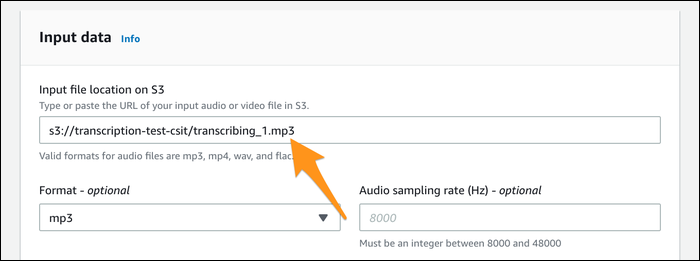
При создании задания вы указываете путь к файлу в S3, язык и (по желанию) параметры формата/частоты дискретизации. Сервис обычно автоматически определяет распространённые форматы.
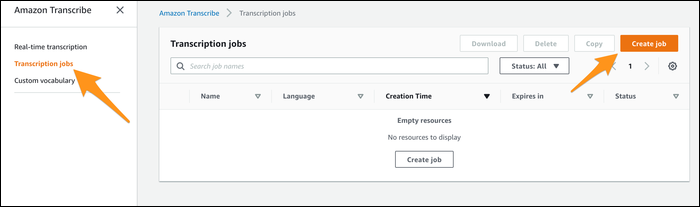
После создания задание появится в списке. Когда статус станет COMPLETED, вы сможете скачать JSON-транскрипт.
CLI: запуск и проверка заданий
Для автоматизации удобнее использовать AWS CLI. Пример запуска задания:
aws transcribe start-transcription-job \
--transcription-job-name NewJob \
--language-code en-US \
--media MediaFileUri=s3://bucket/file.mp3Проверка статуса задания:
aws transcribe get-transcription-job --transcription-job-name NewJobСкачивание результата (пример с использованием jq для извлечения URI и вывода транскрипта):
curl $(aws transcribe get-transcription-job --transcription-job-name NewJob \
| jq -r '.TranscriptionJob.Transcript.TranscriptFileUri') \
| jq '.results.transcripts'Примечание: итоговый файл — JSON. Он содержит полный текст, сегменты слов с оценкой уверенности и альтернативы. Если нужны только итоговые строки, оставьте запрос через jq ‘.results.transcripts’.
Автоматизация: S3 → Lambda → Transcribe
Lambda может запускать создание задания при событии загрузки в S3. Lambda не выполняет саму транскрипцию — она просто инициирует Transcribe Job, поэтому вычислительные расходы минимальны.
Если вы не хотите писать Lambda-функцию вручную, в репозитории serverless приложений AWS есть шаблон s3-lambda-transcribe-audio-to-text-s3. Он создаёт необходимые ресурсы и привязки; для его поиска может потребоваться опция «Show apps that create custom IAM roles».
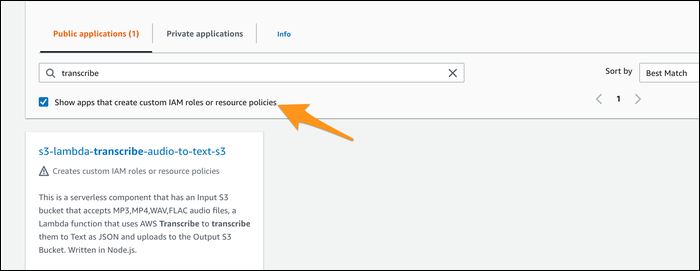
При развёртывании укажите входной и выходной бакеты. Учтите: приложение создаёт входной бакет, поэтому заранее подготовьте выходной бакет и убедитесь, что имена не конфликтуют.
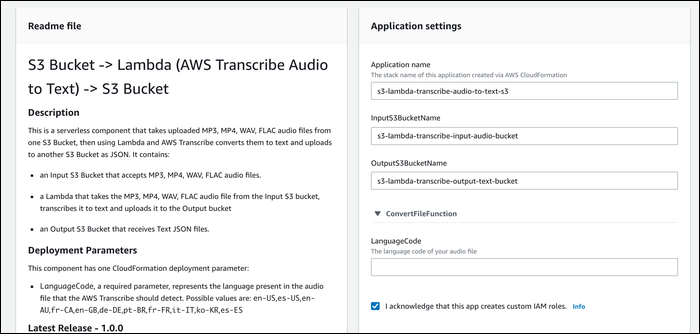
После деплоя киньте файл в входной бакет — Lambda создаст Transcribe Job и поместит результат в выходной бакет. Если приложение не работает — проверьте, создала ли оно роль IAM и есть ли у роли права на работу с Transcribe и S3.
Практические рекомендации и чеклисты
Что проверить перед запуском
- Формат и частота дискретизации аудио (обычно Transcribe распознаёт распространённые форматы).
- Корректный код языка (напр., en-US). Список кодов — в документации AWS.
- Права IAM: роль, создающая задания, должна иметь доступ к S3 и Transcribe.
- Наличие выходного бакета и настройка политики доступа для скачивания результатов.
Чеклист для разработчика (быстро)
- Проверил формат файла в S3.
- Запустил тестовую задачу через консоль.
- Настроил автоматический триггер Lambda.
- Добавил логгирование и мониторинг ошибок.
Чеклист для DevOps
- Ограничил IAM-права минимально возможными правами (least privilege).
- Настроил политики хранения и lifecycle для бакетов с результатами.
- Настроил полномасштабный мониторинг (CloudWatch)
Чеклист для менеджера продукта
- Оценил бизнес-цели: нужна пакетная или стримовая транскрипция?
- Проверил требования к задержке и точности.
- Согласовал бюджет (стоимость рассчитывается по аудиосекундам).
SOP: быстрое развертывание автоматизации
- Создать выходной S3-бакет и обозначить его в документации проекта.
- В консоли Serverless Apps найти шаблон s3-lambda-transcribe-audio-to-text-s3.
- При создании приложения дать ему права на создание роли (или предоставить заранее подготовленную роль).
- Указать выходной бакет и язык аудио.
- Деплойнуть приложение и загрузить тестовый аудиофайл в входной бакет.
- Проверить, что в выходном бакете появился JSON с транскриптом. Если нет — смотреть лог Lambda в CloudWatch.
Когда Transcribe подходит, а когда нет
Подходит когда:
- Нужна пакетная обработка уже записанных звонков или видео.
- Нужны автоматические транскрипты для субтитров, индексирования или аналитики.
Не подходит когда:
- Требуется реальное время и низкая задержка (используйте Lex или стриминговые сервисы).
- Нужна сверхвысокая точность в условиях шумного окружения (возможно, нужны постобработки или человек-аннотер).
Альтернативы и комбинации
- AWS Lex: для интерактивных голосовых интерфейсов и чат-ботов.
- Специализированные стриминговые провайдеры: если нужно минимальное время отклика.
- Гибрид: использовать Transcribe для пакетной аналитики и стриминг-решение для реального времени.
Ментальные модели и парадигмы
- Разделяйте «рекорд» и «распознавание»: чаще всего запись и распознавание работают асинхронно.
- «Инициация» vs «процессинг»: Lambda инициирует Transcribe Job; Transcribe выполняет тяжелую работу.
- «Сырой результат» vs «готовый продукт»: исходный JSON содержит слова с оценкой уверенности — его чаще нужно нормализовать и сопоставить с бизнес-логикой.
Мини-методология постобработки транскрипта
- Извлечь текст из JSON (jq или кастомный парсер).
- Очистить шумовые маркеры и артифакты (неразборчивые участки).
- Применить правило пунктуации и капитализации (если требуется).
- Сопоставить с временными метками для субтитров или поиска.
Примеры тестовых сценариев
- Загрузить 2-минутный аудиофайл с четкой речью, проверить, что итоговый текст совпадает на 95% с эталоном.
- Загрузить аудиофайл с фоновой музыкой и оценить падение уверенности в словах.
- Проверить, что при ошибках прав доступа Lambda логирует и не завершает процесс молча.
Критерии приёмки
- Транскрипт доступен в выходном бакете в течение ожидаемого временного окна.
- Статус задания в CLI или SDK — COMPLETED.
- Роль IAM не имеет лишних прав (проверка аудита).
Риски и меры смягчения
- Проблемы с правами IAM → проверить и ограничить политику.
- Некорректный формат аудио → добавить валидацию перед загрузкой.
- Высокие расходы при массовой обработке → внедрить квоты и мониторинг затрат.
Короткое руководство по миграции на прод
- Протестировать шаблон на dev-аккаунте с ограниченным набором файлов.
- Настроить алерты на превышение стоимости и ошибок Lambda.
- Перенести настройки в прод-аккаунт и задокументировать политики безопасности.
Итог
AWS Transcribe — удобный инструмент для автоматического преобразования аудио в текст из S3. Он прост в использовании как вручную через консоль, так и автоматизированно через CLI или Lambda. Подходит для пакетной транскрипции; для задач с реальным временем рассмотрите альтернативы. Внедряя автоматизацию, внимательно настройте IAM и мониторинг.
Сводка:
- Transcribe преобразует аудио в JSON с оценкой уверенности и альтернативами.
- Стоимость рассчитывается по секундам аудио; примеры в начале статьи.
- Для автоматизации можно использовать готовый шаблон Lambda: s3-lambda-transcribe-audio-to-text-s3.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
