Как использовать диаграмму разброса в Microsoft Excel для прогнозирования поведения данных

Диаграмма разброса в Excel показывает связь между двумя величинами и позволяет добавить линию тренда для получения приближённого уравнения. Это даёт возможность экстраполировать значения впёред и назад и даже выделять зависимость от нескольких независимых переменных путём поэтапного построения трендовых линий.
Эффективный анализ данных начинается с понимания взаимоотношений между величинами. Хорошие наблюдения позволяют не только описать поведение данных — их можно предсказать. Создать точную математическую модель вручную сложно. Но Microsoft Excel делает процесс доступным: достаточно построить диаграмму разброса и добавить линию тренда.
Важно: диаграмма разброса пригодна для двухмерного анализа (независимая переменная X и зависимая Y). Для многомерного анализа её используют пошагово, удерживая часть переменных фиксированными.
Что такое точечная (scatter) диаграмма — коротко
Точечная диаграмма отображает пары значений (X, Y) на координатной сетке. X обычно независимая переменная (горизонтальная ось), Y — зависимая (вертикальная ось). Линия тренда показывает приближённую связь между ними.
Краткое определение: диаграмма разброса — визуализация парных зависимостей, удобная для регрессии и обнаружения трендов.
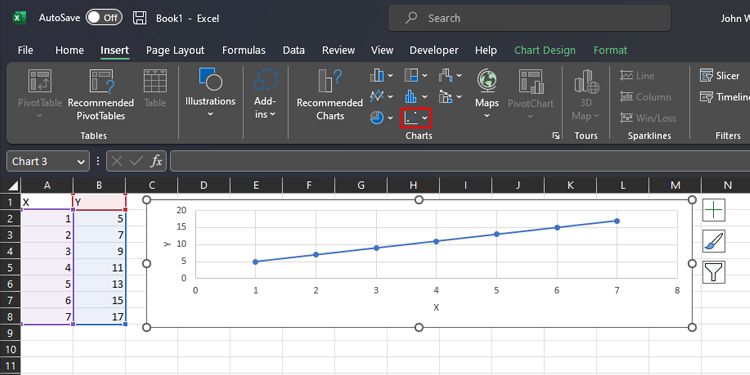
Создание точечной диаграммы в Microsoft Excel
Шаги по созданию диаграммы разброса:
- Откройте таблицу с данными.
- Поместите независимую переменную в левый столбец, зависимую — в следующий столбец справа.
- Выделите диапазон обеих колонок, которые хотите отобразить.
- Перейдите на вкладку Вставка и в группе Диаграммы выберите Вставить точечную (X, Y) или пузырьковую диаграмму.
- Выберите подходящий стиль из доступных вариантов.
- После вставки подпишите оси и измените заголовок диаграммы по смыслу.
Примечание: для удобства подпишите единицы измерения на осях (например, «время, ч» или «давление, кПа»).
Добавление линии тренда на диаграмме разброса
Линия тренда (trendline) служит для визуализации зависимости. Чтобы её добавить:
- Щёлкните правой кнопкой по любой точке данных на диаграмме.
- В появившемся меню выберите Добавить линию тренда.
- Справа появится панель Формат линии тренда, где по умолчанию стоит Линейная опция.
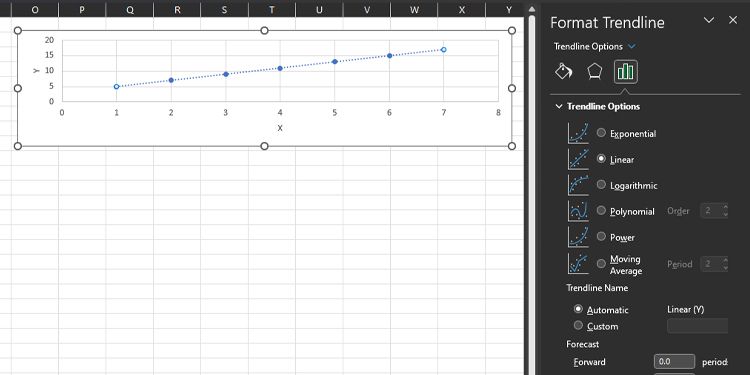
По умолчанию Excel рисует прямую. Часто этого достаточно, но для кривых зависимостей выберите другой тип аппроксимации.
Параметры линии тренда, полезные для прогнозирования
- Линейная — прямая; удобна, когда связь примерно пропорциональна.
- Полиномиальная — подходит для кривых с изгибами (укажите степень полинома).
- Экспоненциальная — для экспоненциального роста или убывания.
- Логарифмическая — когда прирост замедляется.
- Скользящая средняя — для сглаживания шума.
Отметьте Display Equation on chart (Показать уравнение на диаграмме) и Display R-squared чтобы оценить качество аппроксимации (коэффициент детерминации).
Подгонка кривой и отображение уравнения
Чтобы линия тренда лучше соответствовала точкам данных:
- В панели Формат линии тренда в разделе Параметры линии тренда пробуйте разные типы: полиномиальная, экспоненциальная, логарифмическая.
- Увеличивайте степень полинома, но остерегайтесь переобучения: слишком высокий порядок будет совпадать с шумом.
- Включите Показать уравнение на диаграмме для дальнейшего использования в вычислениях.
Важно: уравнение, показанное Excel, даёт приближённую модель. Перед экстраполяцией проверьте его осмысленность и область применимости.
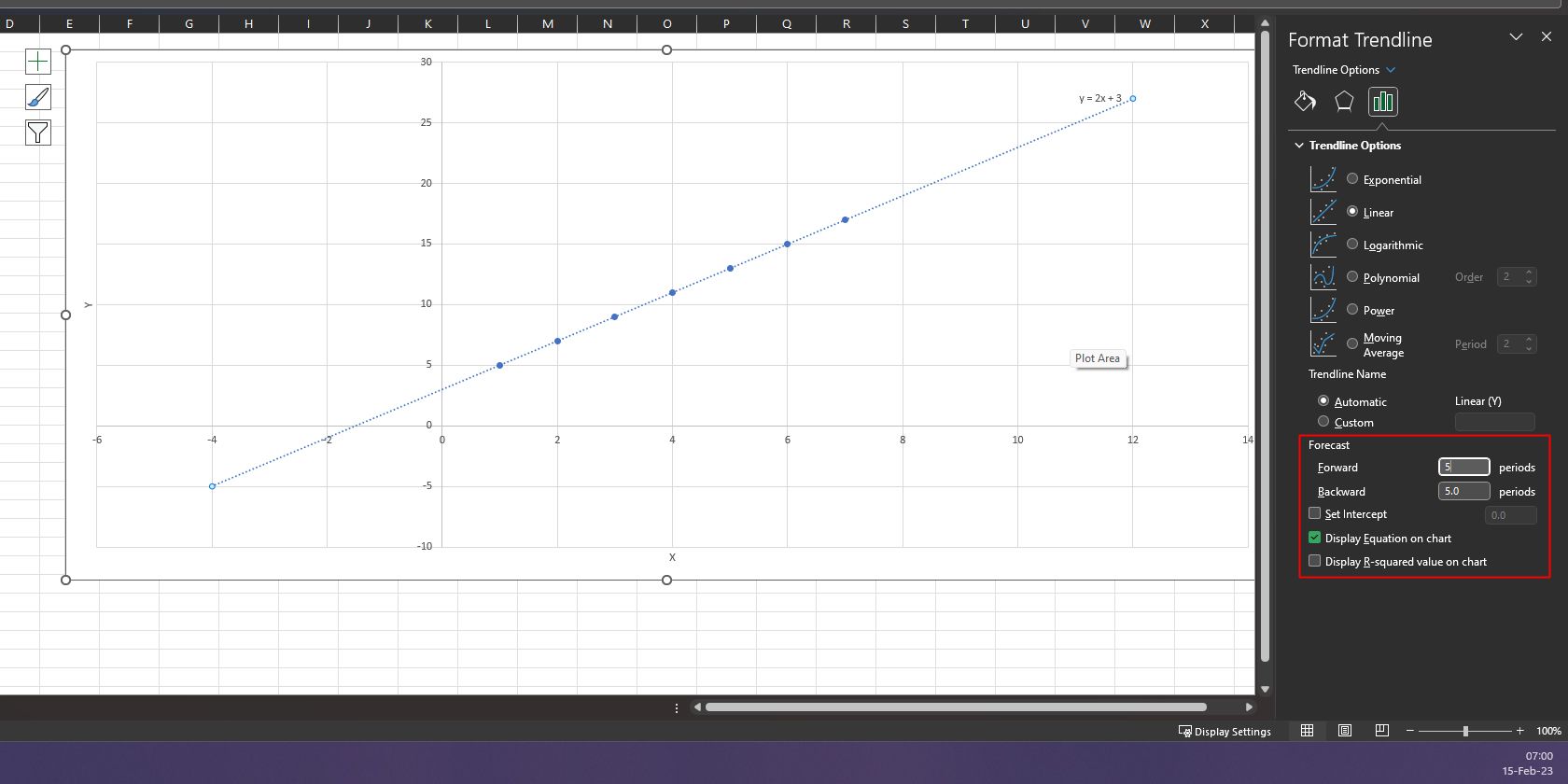
Прогнозирование вперёд и назад по тренду
После подгонки линии тренда можно прогнозировать значения за пределами исходного интервала:
- В панели Формат линии тренда найдите секцию Прогноз.
- Укажите количество периодов Вперёд и Назад (Forward/Backward).
- Excel визуализирует экстраполяцию линии тренда на диаграмме.
Примечание: экстраполяция надёжна лишь вблизи имеющихся данных. Дальние прогнозы несут большие риски.
Определение формулы при нескольких независимых переменных (пошагово)
Данные иногда зависят от нескольких независимых величин. Excel не строит трёхмерные линии тренда на двухмерной диаграмме, поэтому применяют поэтапный метод: зафиксировать часть переменных и найти зависимость по другой.
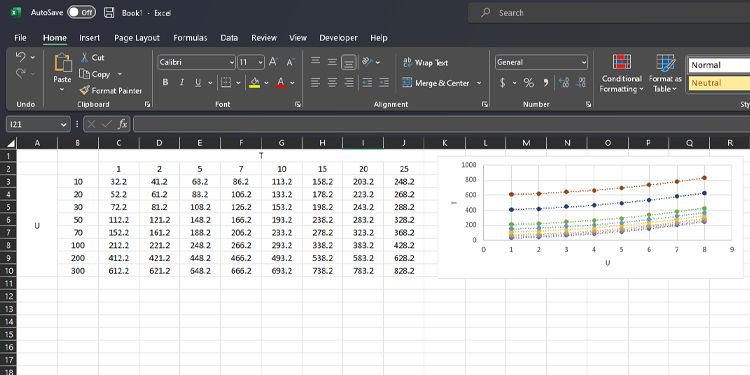
Дано: зависимая величина Y(U,T) и две независимые переменные U и T. Цель — получить приближённую формулу Y(U,T).
Пошаговая методика:
- Зафиксируйте одно значение T и постройте scatter диаграмму для U против Y (только столбцы с выбранным T).
- Добавьте линию тренда и покажите уравнение на диаграмме.
- Повторите для всех выбранных значений T.
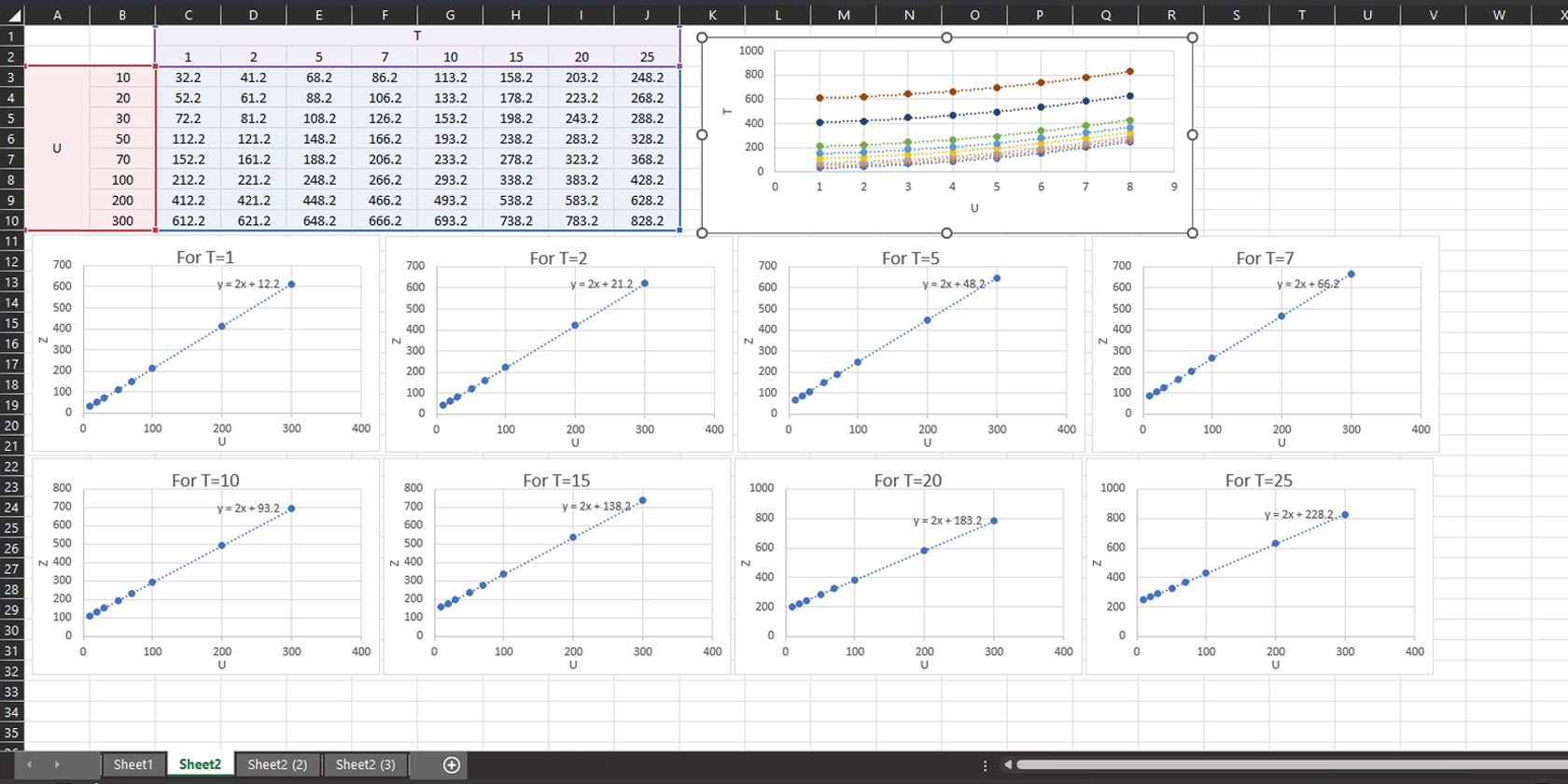
- Сравните полученные уравнения: если коэффициент при U стабилен, вы получите Y(U,T) = a*U + Z(T), где a — общий коэффициент, Z(T) — зависимость свободного члена от T.
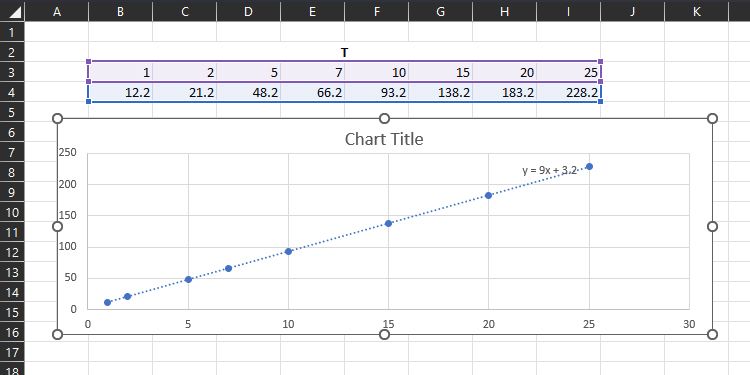
- Составьте таблицу свободных членов Z для всех T и постройте их зависимость от T. Найдите уравнение Z(T).
- Объедините результаты: Y(U,T) = a*U + Z(T).
Пример из набора данных (упрощённо): получились уравнения
| T | Y |
|---|---|
| T=1 | Y=2U+12.2 |
| T=2 | Y=2U+21.2 |
| T=5 | Y=2U+48.2 |
| T=7 | Y=2U+66.2 |
| T=10 | Y=2U+93.2 |
| T=15 | Y=2U+138.2 |
| T=20 | Y=2U+183.2 |
| T=25 | Y=2U+228.2 |
Так как коэффициент при U везде равен 2, можно записать Y(U,T) = 2U + Z(T). Построив Z(T) по точкам [12.2 при T=1, 21.2 при T=2, …], мы получили аппроксимацию
Y(U,T) = 2U + 9T + 3.2Этот вывод проверяют, построив поверх полученной формулы точки для разных U и T и сравнив с исходными данными.
Когда метод не сработает или даст плохие результаты
Важно понимать ограничения метода:
- Нелинейные взаимосвязи высокой сложности могут потребовать многомерной регрессии или специализированных моделей (машинное обучение).
- Сильный шум в данных приводит к плохой подгонке и нестабильным коэффициентам.
- Малое число наблюдений даёт ненадёжные оценки и переобучение при высокой степени полинома.
- Взаимная корреляция независимых переменных (мультиколлинеарность) может исказить интерпретацию коэффициентов.
Когда вы сомневаетесь, проверьте модель на контрольной выборке и используйте метрики качества (R², средняя абсолютная ошибка).
Альтернативные подходы и инструменты
Если задача выходит за рамки простой 2D-подгонки:
- Используйте функцию LINEST в Excel для множественной линейной регрессии в табличном виде.
- Установите надстройку Анализ данных (Data Analysis ToolPak) и примените множественную регрессию.
- Экспорт данных в Python (pandas/statsmodels, scikit-learn) или R для продвинутых моделей и кросс-валидации.
- Для временных рядов применяйте специальные модели ARIMA или современные методы Prophet.
Совет: сохраняйте и документируйте шаги подгонки, чтобы легко воспроизвести анализ.
Ментальные модели и эвристики при выборе линии тренда
- Посмотрите на распределение точек: если они стелятся вдоль прямой — используйте линейную.
- Если есть заметный изгиб — начните с полинома 2-й степени.
- Для нарастания с постоянным процентным ростом пробуйте экспоненциальную модель.
- Используйте принцип Occam’s razor: выбирайте наименьшую по сложности модель, которая описывает данные.
Мини‑методология: чеклист для получения формулы из набора данных
- Подготовьте данные: удалите выбросы или отметьте их, заполните пропуски.
- Визуализируйте: scatter для каждой пары переменных.
- Подберите тип линии тренда и получите уравнение.
- Оцените качество (R², остатки).
- При многовариативности фиксируйте часть переменных и повторяйте анализ.
- Объедините полученные уравнения в итоговую формулу.
- Проверьте модель на независимой выборке.
Ролевые чеклисты
Для аналитика данных:
- Подготовить датасет с метаданными и единицами измерения.
- Построить диаграммы для каждой пары переменных.
- Записать уравнения и значения R².
- Сохранить итоговые формулы и графики.
Для бизнес‑пользователя:
- Убедиться, что данные отражают реальные процессы.
- Проверить адекватность прогнозов на простых сценариях.
- Согласовать область применимости модели.
Для разработчика/инженера отчётов:
- Автоматизировать построение диаграмм и экспорт уравнений.
- Убедиться в совместимости версий Excel у конечных пользователей.
Шаблон размещения данных в таблице
Рекомендуемая структура для двух независимых переменных:
| U | Y (T=1) | Y (T=2) | Y (T=5) | … |
|---|---|---|---|---|
| 1.0 | 14.2 | 23.2 | 50.2 | |
| 2.0 | 16.0 | 25.0 | 52.0 |
Пояснение: столбец U — значения независимой переменной, последующие колонки — Y при разных фиксированных T. Это упрощает поэтапный анализ.
Практические советы и подводные камни
- Всегда подписывайте оси и указывайте единицы измерения.
- Не экстраполируйте слишком далеко за границы данных без дополнительной проверки.
- Для полиномиальной подгонки убедитесь, что степень полинома оправдана физически или логически.
- Проверяйте остатки: случайная структура остатков указывает на хорошую модель.
Совместимость Excel и миграция к другим инструментам
- Основные возможности линий тренда присутствуют в большинстве современных версий Excel (Excel 2013, 2016, 2019, Microsoft 365). Интерфейс может незначительно отличаться.
- Для автоматизированного анализа и множества регрессий лучше использовать Python/R. Экспортируйте данные в CSV и переносите вычисления в специализированные библиотеки.
- Если диаграммы необходимо публиковать в вебе, экспорт изображений в SVG/PNG сохраняет оформление.
Контроль качества результатов и критерии приёмки
Критерии приёмки модели:
- Наличие визуального соответствия линии тренда точкам данных.
- R² выше разумного порога для предметной области (например, >0.7 для многих бизнес-задач, но зависит от контекста).
- Отсутствие систематической структуры в остатках.
- Устойчивость коэффициентов при малых изменениях в данных.
Короткая проверка (test cases)
- Проверьте линейность: создайте тестовые данные Y=3X+5 с шумом и убедитесь, что Excel возвращает близкое к 3 значение коэффициента.
- Проверьте полиномиальную подгонку: синтетические данные Y=X^2 должны вернуть полиномиальный коэффициент, доминирующий на X^2.
- Для многомерного сценария используйте известную формулу Y=2U+9T+3.2 и проверьте восстановление коэффициентов по шагам.
Краткое резюме
- Диаграмма разброса — простой и мощный инструмент для обнаружения зависимостей.
- Линия тренда и отображаемое уравнение дают возможность быстро получить приближенную модель и делать прогнозы.
- Для нескольких независимых переменных применяют поэтапную стратегию: фиксируют часть переменных и выделяют закономерности.
- Всегда проверяйте область применимости модели и качество подгонки.
Важно: вы не обязаны быть профессиональным математиком, чтобы извлечь полезные прогнозы из данных. Excel даёт все необходимые базовые инструменты.
Дополнительные ресурсы и следующий шаг
Если вам нужно более точное моделирование, изучите:
- LINEST и регрессию в Excel.
- Анализ данных в Python (pandas, statsmodels, scikit-learn).
- Пакет R и библиотеки для визуализации (ggplot2) и моделирования.
Удачных эксперимент ов с вашими данными — начните с визуализации, затем уточняйте модель шаг за шагом.
Похожие материалы

Конвертация MP4 в MP3 — способы и советы

Как настроить сетевой домен — полное руководство

Как добавить рамку к фото — инструменты и методы

Как подключить Fitbit к iPhone — полное руководство

Проверка совместимости игр Steam с Steam Deck