Сбор логов и аналитика с Elasticsearch и Kibana
Elasticsearch — это масштабируемый движок поиска и аналитики для хранения, индексации и поиска временных и логовых данных. Kibana предоставляет графический веб-интерфейс для визуализации и исследования этих данных. Вы можете собирать логи с помощью Beats (Filebeat, Metricbeat и др.) или отправлять JSON напрямую в API. Важно закрыть порты и настроить аутентификацию, иначе данные могут стать публичными. В статье — пошаговая установка, рекомендации по безопасности, примеры конфигураций и практический набор чеклистов и процедур для запуска и эксплуатации.
Почему сбор данных полезен
Сбор данных помогает понять поведение пользователей, выявлять сбои и оптимизировать инфраструктуру. Даже простые метрики — трафик, коды ответов, загрузка CPU и память — дают представление о здоровье сервиса и помогают принимать решения о масштабировании и приоритизации работы.
Определение: лог — это структурированная или неструктурированная запись события с отметкой времени. Индекс — логическая коллекция документов в Elasticsearch, сопоставимая с базой данных.
Важно: решайте заранее, какие данные действительно важны. Логи занимают место и требуют хранения, поэтому спланируйте ротацию и политики удержания.
Что такое Elasticsearch и Kibana
Elasticsearch — это движок поиска и аналитики, ориентированный на документы с временными метками. Он индексирует поля документов, чтобы обеспечить быстрый поиск и агрегации. Kibana — это веб-интерфейс для создания дашбордов, визуализаций и управления индексами.
Короткое объяснение: Elasticsearch хранит JSON-документы в индексах; Kibana читает эти индексы и рисует графики.
Преимущества Elasticsearch:
- Гибкая схема: можно отправлять разные структуры документов.
- Высокая скорость поиска и агрегаций по масштабируемым кластерам.
- Экосистема (Beats, Logstash, X-Pack и т. п.).
Ограничения и когда стоит искать альтернативы:
- Если вам нужен полностью управляемый сервис — рассмотрите Elastic Cloud или другие SaaS-решения.
- Если важна строгая целевая аналитика сайта — Google Analytics может быть проще.
- Для очень ограниченного бюджета с минимальными требованиями к поиску можно использовать базовые решения на базе лог-файлов и простых агрегаторов.
Установка Elasticsearch (Debian/Ubuntu)
Пример для Debian-подобных систем. Если у вас другая ОС, следуйте официальной инструкции Elastic.
Добавьте GPG-ключ и репозиторий:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -sudo apt-get install apt-transport-httpsecho "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-7.x.listУстановите Elasticsearch:
sudo apt-get update && sudo apt-get install elasticsearchПо умолчанию Elasticsearch слушает на порту 9200 и не защищён. Не оставляйте этот порт открытым в интернет. В простых случаях достаточно закрыть порт на фаерволе и пробросить доступ только из доверенной сети.
Совет: для продакшена планируйте кластер из нескольких нод, настройку heap-памяти и мониторинг дискового пространства.
Важная заметка о безопасности
Оставлять 9200 и панель Kibana открытыми — распространённая ошибка. Без аутентификации любой может читать или удалять индексы. Закрывайте порты, используйте обратный прокси с аутентификацией и шифрование, либо включайте встроенные механизмы безопасности Elastic (X-Pack / Security) если используете коммерческие возможности.
Установка и защита Kibana
Установите Kibana:
sudo apt-get update && sudo apt-get install kibanaВключите сервис, чтобы он стартовал при загрузке:
sudo /bin/systemctl daemon-reloadsudo /bin/systemctl enable kibana.serviceПо умолчанию Kibana слушает на порту 5601. Закройте его публичный доступ и либо белый список IP, либо проксируйте через NGINX с базовой аутентификацией.
Разрешение доступа по IP (UFW):
sudo ufw allow from x.x.x.x to any port 5601Рекомендация: настройте NGINX reverse proxy и Basic Auth. Это простой способ добавить пароль без сложной интеграции.
Установите apache2-utils и создайте файл паролей:
sudo apt-get install apache2-utilssudo htpasswd -c /etc/nginx/.htpasswd adminСоздайте конфигурацию NGINX для проксирования (пример):
sudo nano /etc/nginx/sites-enabled/kibanaВставьте конфигурацию:
upstream elasticsearch {
server 127.0.0.1:9200;
keepalive 15;
}
upstream kibana {
server 127.0.0.1:5601;
keepalive 15;
}
server {
listen 9201;
server_name elastic.example.com;
location / {
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/.htpasswd;
proxy_pass http://elasticsearch;
proxy_redirect off;
proxy_buffering off;
proxy_http_version 1.1;
proxy_set_header Connection "Keep-Alive";
proxy_set_header Proxy-Connection "Keep-Alive";
}
}
server {
listen 80;
server_name elastic.example.com;
location / {
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/.htpasswd;
proxy_pass http://kibana;
proxy_redirect off;
proxy_buffering off;
proxy_http_version 1.1;
proxy_set_header Connection "Keep-Alive";
proxy_set_header Proxy-Connection "Keep-Alive";
}
}Замените elastic.example.com на ваш домен и перезапустите NGINX:
sudo service nginx restartИзображение панели Kibana
Теперь настраиваем источники логов.
Подключение поставщиков логов (Beats)
Beats — компактные агенты для отправки разных типов данных в Elasticsearch или Logstash. Основные варианты:
- Filebeat — для файлов журналов (access.log, error.log и т. п.).
- Metricbeat — системные метрики (CPU, память, диски).
- Packetbeat — сетевые пакеты и транзакции.
- Heartbeat — проверка доступности URL (uptime).
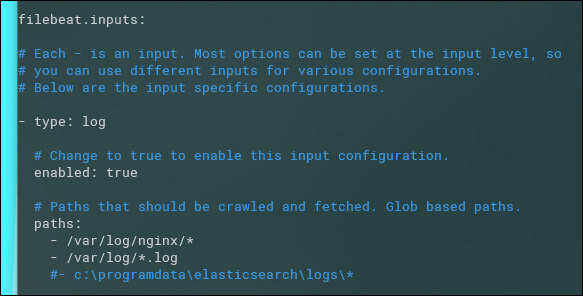
Установка Filebeat (пример):
sudo apt-get install filebeatФайл конфигурации:
sudo nano /etc/filebeat/filebeat.ymlВ разделе filebeat.inputs включите нужные входы и укажите пути к логам. В разделе output.elasticsearch укажите адрес, и если не localhost — задайте username и password:
username: "filebeat_writer"password: “YOUR_PASSWORD”
После настройки запустите сервис:
sudo service filebeat startВажно: Filebeat по умолчанию отправит все существующие строки файлов — если у вас старые логи, подготовьте ротацию, чтобы случайно не залить несколько гигабайт исторических данных.
Изображение: редактирование конфигурации Filebeat
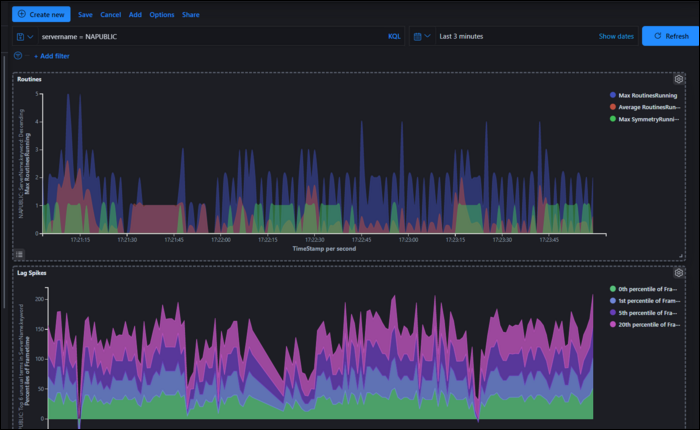
Как работать в Kibana и строить дашборды
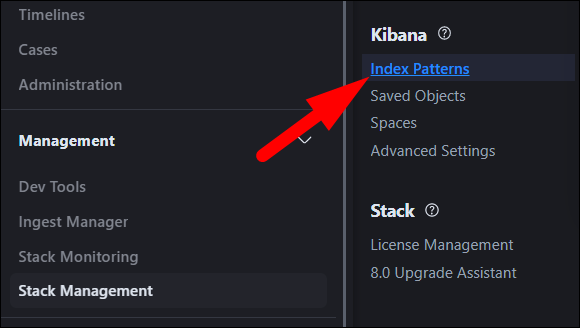
Elasticsearch хранит данные в индексах. Kibana использует «шаблоны индексов» (Index Patterns) для работы с ними. Создайте шаблон в Stack Management > Index Patterns.
Пример шаблона для Filebeat, индексирующего ежедневно:
filebeat-*Вы можете разделять индексы по хостам или типам логов, если хотите упростить управление и хранение.
Вкладка Discover позволяет просматривать сырые документы и делать быстрые поиски. Visualize — для создания графиков. Dashboard объединяет визуализации для мониторинга в реальном времени.
Типы агрегаций и визуализаций:
- Metrics (Метрики) — агрегируют значения (avg, sum, min, max, percentiles).
- Buckets (Группы) — группируют данные (date histogram, terms и т. п.).
Пример: график по времени (date histogram) на оси X и среднее время ответа на оси Y.
Изображение: создание паттерна и визуализации
Практическая подсказка: создайте дашборд для инцидентов с основными графиками — количество ошибок 5xx, среднее время ответа, загрузка CPU, свободное место на диске.
Прямое логирование в API Elasticsearch
Если вы пишете собственное приложение, имеет смысл отправлять JSON напрямую в Elasticsearch.
URL для одиночного документа:
http://example.com:9200/indexname/_docДля высокого трафика используйте Bulk API:
http://example.com:9200/_bulkФормат bulk — пары строк: первая строка указывает действие/индекс, вторая — документ. Пример:
{ "index" : { "_index" : "test"} }
{ "field1" : "value1" }
{ "index" : { "_index" : "test2"} }
{ "field1" : "value1" }
{ "index" : { "_index" : "test3"} }
{ "field1" : "value1" }Если вы собираете тысячи событий в секунду, буферизуйте их и отправляйте пакетами, чтобы снизить нагрузку и экономить время работы сети.
Пример компактной сборки bulk-строки в C# (фрагмент):
private string GetESBulkString(List list, string index)
{
var builder = new StringBuilder(40 * list.Count);
foreach (var item in list)
{
builder.Append(@"{""index"":{""_index"":""");
builder.Append(index);
builder.Append(@"""}}\n");
builder.Append(JsonConvert.SerializeObject(item));
builder.Append("\n");
}
return builder.ToString();
} Изображение: пример отправки JSON-документа напрямую в Elasticsearch

Стратегия хранения и ротации
Планируйте политики удержания (retention). Хранимые индексы занимают место — укажите сколько хранить: несколько дней для подробных логов, несколько месяцев для агрегированных данных. Используйте ILM (Index Lifecycle Management) для автоматизации:
- Hot — хранение свежих данных на быстрых дисках.
- Warm — старые данные на медленном хранилище.
- Cold/Deleted — архивирование или удаление.
Это помогает оптимизировать расходы на хранение и ускорить запросы по свежим данным.
Контроль доступа и безопасность
Рекомендации:
- Отключите публичный доступ к 9200 и 5601.
- Используйте TLS (HTTPS) для защиты трафика между узлами и клиентами.
- Включите аутентификацию и разграничение прав (role-based access control) при необходимости.
- Логируйте и мониторьте доступ к панели управления.
Если вы используете Elastic Cloud, многие механизмы безопасности доступны из коробки.
Отказоустойчивость и резервные копии
Создавайте регулярные снапшоты индексов в репозитории (S3, NFS и т. п.). Тестируйте восстановление. План аварийного восстановления должен включать порядок восстановления кластеров и проверку целостности данных.
Частые ошибки:
- Хранение снапшотов только локально на той же машине — это риск.
- Отсутствие тестов восстановления — вы можете не заметить повреждение архива до инцидента.
Метрики и SLI/SLO (качественные рекомендации)
Полезные метрики для мониторинга:
- Время ответа основных поисковых запросов (latency).
- Процент ошибок (5xx) в API Elasticsearch и Kibana.
- Использование heap-памяти JVM и частота сбора мусора.
- Утилизация диска (использование, I/O wait).
- Уровень репликации индексов (количество реплик в кластере).
Пример целевых уровней (ориентиры):
- Среднее время ответа поискового запроса < 200–500 ms (зависит от нагрузки).
- Процент ошибок < 1%.
- Использование heap < 75% во избежание OOM.
Не придумывайте точные SLA без тестирования в вашей среде — эти цифры служат только начальной точкой.
Роли и чек-листы
DevOps / SRE
- Установить и настроить Elasticsearch и Kibana.
- Закрыть порты 9200 и 5601 или настроить обратный прокси.
- Настроить репликацию и кластер.
- Создать политику ILM и тестировать ротацию.
- Настроить мониторинг и алерты (heap, disk, ricerca latency).
Разработчик приложения
- Решить, какие события логировать.
- Форматировать логи в структурированный JSON по возможности.
- Буферизовать и отправлять данные пакетами (bulk) для высокой нагрузки.
Аналитик / BI
- Создать шаблоны индексов и типы полей.
- Построить ключевые визуализации и дашборды.
- Согласовать политики хранения с командой DevOps.
SOP: быстрый план запуска (Playbook)
- Подготовить сервер(ы), выделить дисковое пространство и настройку сети.
- Установить Elasticsearch и проверить, что сервис отвечает на localhost:9200.
- Установить Kibana и убедиться, что она работает на localhost:5601.
- Закрыть внешние порты, настроить NGINX с Basic Auth или включить Security в Elastic.
- Установить Filebeat на источники логов, настроить пути и output.
- Импортировать шаблон индекса в Kibana, создать Index Pattern.
- Создать базовый дашборд: ошибки, latency, CPU, диск.
- Настроить ILM и регулярные снапшоты.
- Настроить алерты и их канал уведомлений (Slack, Email).
- Документировать процессы и провести учения по восстановлению.
Инцидентный план и откат
При обнаружении утечки или повреждения данных:
- Немедленно закрыть публичный доступ (заблокировать IP/порт).
- Сменить пароли/ключи доступа и обновить файлы аутентификации.
- Отключить ноды, на которых обнаружено нарушение, и изолировать кластер.
- Восстановить данные из последнего корректного снапшота.
- Провести постмортем и внедрить меры предотвращения.
Критерии приёмки
- Kibana доступна только через авторизованный прокси.
- Filebeat корректно отправляет логовые события в индекс.
- ILM применяет ротацию и удаление старых индексов.
- Регулярные снапшоты выполняются и проверены на восстановление.
Тестовые случаи и критерии приёма
- Проверка подключения: при отправке тестового документа он появляется в Discover в течение N секунд.
- Bulk-тест: отправка 10 000 записей группами по 500 не вызывает исключений и индексирует все записи.
- Нагрузочный тест: при росте запросов время ответа < 1s в целевой среде (зависит от железа).
- Тест восстановления: восстановление из снапшота до рабочего индекса прошло успешно.
Когда Elasticsearch не подойдёт (контрпримеры)
- Нужна аналитика веб-сайта без собственного бэкенда: Google Analytics проще и бесплатен.
- Полностью управляемый SaaS предпочтительнее, если команда не хочет поддерживать инфраструктуру.
- Если ваши данные строго соответствуют реляционной модели с транзакциями — лучше СУБД.
Альтернативы и сочетания
- Splunk — коммерческое решение с мощной аналитикой логов.
- Graylog — open-source решение для централизованного логирования.
- Loki (Grafana) — оптимизирован для журналов и дешевле в хранении.
- Elastic Cloud — управляемая версия Elasticsearch от Elastic.
Модель принятия решений (Mermaid)
flowchart TD
A[Нужна ли вам гибкая аналитика и поиск?] -->|Да| B{Есть ли ресурсы на поддержку кластера?}
A -->|Нет| C[Используйте простые SaaS 'Google Analytics или облачные логгер']
B -->|Да| D[Разверните Elasticsearch + Kibana]
B -->|Нет| E[Рассмотрите Elastic Cloud или Splunk]
D --> F[Настройка безопасности, ILM, резервное копирование]
E --> FМини-методология для внедрения логирования
- Определите цели аналитики (мониторинг, безопасность, продуктовые метрики).
- Выберите источники данных и приоритеты (системы, приложения, сети).
- Унифицируйте формат логов (структурированный JSON по возможности).
- Настройте отправку (Filebeat/Metricbeat или прямой Bulk API).
- Создайте базовые дашборды и алерты.
- Автоматизируйте ротацию и резервное копирование.
- Регулярно пересматривайте поля и стоимость хранения.
Короткий глоссарий
- Документ: JSON-объект, хранимый в индексе.
- Индекс: коллекция документов.
- Узел (нод): инстанс Elasticsearch.
- Шаблон индекса: правило сопоставления имени индекса и маппинга полей.
Локальные особенности и советы для России/Европы
- Законодательство о персональных данных: убедитесь, что вы не храните персональные данные без юридического основания. При обработке персональных данных используйте шифрование и минимизацию.
- Хранение в облаке: провайдеры предлагают регионы (RU/ЕU). Выберите регион с учётом требований соответствия.
Итог и ключевые выводы
- Elasticsearch + Kibana дают гибкость для поиска и аналитики логов.
- Beats упрощают сбор данных; Bulk API — для высоких нагрузок.
- Безопасность и политика хранения критичны: закройте порты, включите аутентификацию и настройте ILM.
- Начинайте с минимального набора дашбордов и постепенно расширяйте метрики.
Изображение аналитической панели

Важное
- Не храните необработанные персональные данные без необходимости.
- Тестируйте восстановление из снапшотов.
Краткое резюме
Собирайте только те данные, которые приносит ценность. Настройте безопасность и автоматизацию хранения с самого начала. Начните с Filebeat и базовых дашбордов, затем расширяйте систему в зависимости от задач.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
