Потоки в Python: threading и concurrent.futures — простые примеры

Потоки (threading) в Python помогают ускорять программы с операциями ввода‑вывода, выполняя несколько задач одновременно. В статье показаны простые примеры с модулем threading и с concurrent.futures, объяснены ограничения (GIL) и даны практические рекомендации по внедрению многопоточности.
Время выполнения — один из простых показателей эффективности программы: чем короче время, тем быстрее программа. Потоки позволяют программе выполнять несколько задач одновременно, что сокращает общее ожидание выполнения.
В этой статье вы увидите практические примеры с встроенным модулем threading и с concurrent.futures. Оба модуля дают простой способ создать и управлять потоками.
Зачем нужны потоки
Потоки уменьшают общее время выполнения, когда задача состоит из нескольких независимых операций. Вместо того чтобы ждать завершения одной операции перед запуском следующей, можно запустить несколько операций параллельно и сократить суммарное ожидание.
Пример: загрузка множества изображений из интернета. В последовательном варианте программа скачивает файлы по одному, а в многопоточном — параллельно, что сокращает время ожидания сетевых операций.
Программа до применения потоков
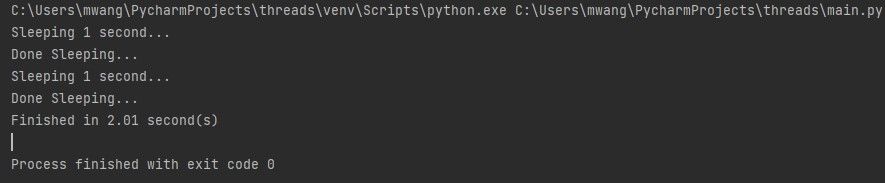
Ниже — простая функция, которая приостанавливает выполнение на одну секунду. Программа вызывает её дважды и затем измеряет общее время выполнения.
import time
start_time = time.perf_counter()
def pause():
print('Sleeping 1 second...')
time.sleep(1)
print('Done Sleeping...')
pause()
pause()
finish_time = time.perf_counter()
print(f'Finished in {round(finish_time - start_time, 2)} second(s)')
Вывод показывает около 2.01 секунды — каждая пауза по 1 секунде и небольшой оверхед на запуск/печать.
Применение threading
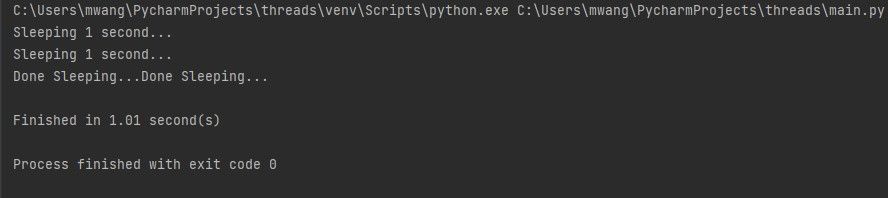
Чтобы переписать код с потоками, импортируйте модуль threading и создайте экземпляры Thread. Запустите потоки методом start(), а затем дождитесь их завершения с помощью join().
import time
import threading
start_time = time.perf_counter()
def pause():
print('Sleeping 1 second...')
time.sleep(1)
print('Done Sleeping...')
thread_1 = threading.Thread(target=pause)
thread_2 = threading.Thread(target=pause)
thread_1.start()
thread_2.start()
thread_1.join()
thread_2.join()
finish_time = time.perf_counter()
print(f'Finished in {round(finish_time - start_time, 2)} second(s)')
В этом варианте оба потока выполняются параллельно, и общее время будет примерно 1 секунда плюс небольшой оверхед.
concurrent.futures: более высокий уровень
Начиная с Python 3.2 появился модуль concurrent.futures, который даёт удобный высокоуровневый API для запуска асинхронных задач с помощью пулов потоков или процессов. Он упрощает старт и ожидание задач.
import time
import concurrent.futures
start_time = time.perf_counter()
def pause():
print('Sleeping 1 second...')
time.sleep(1)
return 'Done Sleeping...'
with concurrent.futures.ThreadPoolExecutor() as executor:
results = [executor.submit(pause) for _ in range(2)]
for f in concurrent.futures.as_completed(results):
print(f.result())
finish_time = time.perf_counter()
print(f'Finished in {round(finish_time - start_time, 2)} second(s)')
concurrent.futures сам запускает и ждёт завершения потоков, что делает код чище и удобнее для масштабирования на большее число задач.
Пример реального использования: параллельная загрузка изображений
В реальном мире выигрыш от потоков больше, чем в синтетическом примере с time.sleep(). Ниже — последовательная загрузка изображений (понадобится библиотека requests).
Установите requests в виртуальном окружении:
pip install requestsПоследовательный вариант:
import requests
import time
img_urls = [
'https://images.unsplash.com/photo-1524429656589-6633a470097c',
'https://images.unsplash.com/photo-1530224264768-7ff8c1789d79',
'https://images.unsplash.com/photo-1564135624576-c5c88640f235',
'https://images.unsplash.com/photo-1541698444083-023c97d3f4b6',
'https://images.unsplash.com/photo-1522364723953-452d3431c267',
'https://images.unsplash.com/photo-1513938709626-033611b8cc03',
'https://images.unsplash.com/photo-1507143550189-fed454f93097',
'https://images.unsplash.com/photo-1493976040374-85c8e12f0c0e',
'https://images.unsplash.com/photo-1504198453319-5ce911bafcde',
'https://images.unsplash.com/photo-1530122037265-a5f1f91d3b99',
'https://images.unsplash.com/photo-1516972810927-80185027ca84',
'https://images.unsplash.com/photo-1550439062-609e1531270e',
]
start_time = time.perf_counter()
for img_url in img_urls:
img_bytes = requests.get(img_url).content
img_name = img_url.split('/')[3]
img_name = f'{img_name}.jpg'
with open(img_name, 'wb') as img_file:
img_file.write(img_bytes)
print(f'{img_name} was downloaded...')
finish_time = time.perf_counter()
print(f'Finished in {finish_time - start_time} seconds')Такой код может занять десятки секунд — время зависит от скорости сети и удалённого хоста.
Асинхронный через ThreadPoolExecutor:
import requests
import time
import concurrent.futures
img_urls = [
'https://images.unsplash.com/photo-1524429656589-6633a470097c',
'https://images.unsplash.com/photo-1530224264768-7ff8c1789d79',
'https://images.unsplash.com/photo-1564135624576-c5c88640f235',
'https://images.unsplash.com/photo-1541698444083-023c97d3f4b6',
'https://images.unsplash.com/photo-1522364723953-452d3431c267',
'https://images.unsplash.com/photo-1513938709626-033611b8cc03',
'https://images.unsplash.com/photo-1507143550189-fed454f93097',
'https://images.unsplash.com/photo-1493976040374-85c8e12f0c0e',
'https://images.unsplash.com/photo-1504198453319-5ce911bafcde',
'https://images.unsplash.com/photo-1530122037265-a5f1f91d3b99',
'https://images.unsplash.com/photo-1516972810927-80185027ca84',
'https://images.unsplash.com/photo-1550439062-609e1531270e',
]
start_time = time.perf_counter()
def download_image(img_url):
img_bytes = requests.get(img_url).content
img_name = img_url.split('/')[3]
img_name = f'{img_name}.jpg'
with open(img_name, 'wb') as img_file:
img_file.write(img_bytes)
print(f'{img_name} was downloaded...')
with concurrent.futures.ThreadPoolExecutor() as executor:
executor.map(download_image, img_urls)
finish_time = time.perf_counter()
print(f'Finished in {finish_time-start_time} seconds')В этом примере общий тайминг заметно уменьшается, потому что сетевые операции выполняются параллельно.

Сценарии, где потоки полезны
- I/O‑bound задачи: сетевые запросы, чтение/запись файлов, взаимодействие с базой данных. Потоки дают выигрыш, потому что в ожидании ввода/вывода можно выполнять другие задачи.
- Веб‑скрейпинг: параллельные HTTP‑запросы сокращают общее время сбора.
Важно: CPU‑bound задачи в CPython обычно не выигрывают от потоков из‑за GIL (Global Interpreter Lock). Для вычислительно тяжёлых задач лучше смотреть в сторону multiprocessing или C‑расширений.
Когда потоки не помогают и ограничения
- GIL: в стандартной реализации CPython единовременно выполняется только один поток в байт‑коде Python. Потоки не дают параллелизма для CPU‑интенсивных операций.
- Порядок итогов: поток‑безопасность, гонки, состояние и дедлоки — нужно проектировать синхронизацию (Lock, RLock, Queue и т. п.).
- Блокирующие C‑расширения или драйверы могут блокировать GIL и приводить к неожиданным задержкам.
Important: перед добавлением потоков убедитесь, что узким местом действительно являются ожидания ввода/вывода.
Альтернативы и когда их выбирать
- multiprocessing — для CPU‑bound задач; запускает отдельные процессы и обходит GIL. Подходит для параллельных вычислений.
- asyncio — для большого числа коротких сетевых операций и событийно‑ориентированной логики. Экономит память и контекст переключения по сравнению с тысячами потоков.
- Внешние очереди и воркеры (Celery, RQ) — для распределённых задач и отложенной обработки.
Эвристики и модели принятия решений
- Если >50% времени затрачивается на ожидание сети/файла — подумайте о потоках.
- Если задача упирается в CPU и вы используете CPython — сначала попробуйте multiprocessing.
- Для сотен и тысяч параллельных соединений лучше смотреть в сторону asyncio + aiohttp.
Пошаговый план внедрения многопоточности (мини‑SOP)
- Измерьте время выполнения и найдите узкое место (профайлинг, логирование).
- Определите тип узкого места: I/O или CPU.
- Для I/O: добавьте ThreadPoolExecutor или Thread и проверьте улучшение.
- Управляйте исключениями и ресурсами (таймауты, retries).
- Напишите тесты на корректность работы при параллельном запуске (unit + интеграционные).
- Протестируйте нагрузку на staging и мониторьте (latency, error rate, CPU, память).
Чеклист ролей
Разработчик:
- Выбрал правильный инструмент (threading / asyncio / multiprocessing).
- Добавил таймауты и обработку ошибок при сетевых вызовах.
- Обработал доступ к общему состоянию (Lock/Queue).
Код‑ревьюер:
- Проверил thread‑safety и возможные гонки.
- Убедился в тестах на конкурентный доступ.
Опер‑инженер:
- Настроил мониторинг (latency, CPU, память).
- Проверил поведение при неожиданных отказах сети.
Критерии приёмки
- Функциональность: все изображения скачиваются корректно и без повреждений.
- Производительность: время выполнения уменьшилось по сравнению с последовательной версией.
- Надёжность: при падении одного из запросов система корректно логирует ошибку и продолжает работу.
Тестовые случаи
- Успешное скачивание 12 изображений.
- Один из URL возвращает 404 — остальные успешно сохраняются.
- Имитация длительной задержки на одном URL — остальные не блокируются.
Примечания по безопасности и приватности
- Проверяйте и валидируйте URL перед загрузкой.
- Сохраняйте файлы в безопасную директорию и избегайте перезаписи важных файлов.
- Учитывайте лицензионные и авторские права при скачивании и хранении изображений.
Короткий словарь
- Поток (thread): лёгкая единица выполнения внутри процесса.
- GIL: Global Interpreter Lock — глобальная блокировка интерпретатора CPython.
- ThreadPoolExecutor: пул потоков в concurrent.futures.
Когда стоит выбирать asyncio вместо потоков
- Много тысяч одновременных сетевых соединений: asyncio обычно экономит ресурсы и даёт меньший overhead на переключение контекста.
- Логика сильно событийно‑ориентирована и нет блокирующих функций — тогда асинхронный подход предпочтительнее.
Простая эвристическая таблица выбора
- Небольшое число потоков для простых параллельных задач: threading / ThreadPoolExecutor.
- CPU‑интенсивные задачи: multiprocessing.
- Очень большое число сетевых соединений: asyncio.
Диаграмма принятия решения
flowchart TD
A[Узкое место: I/O или CPU?] -->|I/O| B[Небольшое число задач?]
A -->|CPU| C[Использовать multiprocessing]
B -->|Да| D[ThreadPoolExecutor]
B -->|Нет, сотни/тысячи| E[asyncio]
D --> F[Добавить таймауты и обработку ошибок]
E --> F
C --> FИтог
Потоки в Python — эффективный инструмент для ускорения I/O‑bound задач. Для простых параллельных операций достаточно threading или ThreadPoolExecutor, а для масштабных сетевых сценариев пригодится asyncio. Для CPU‑интенсивных задач предпочтительнее multiprocessing. Всегда измеряйте и тестируйте до и после внедрения многопоточности.
Summary
- Потоки ускоряют I/O‑bound операции и упрощают параллельную загрузку данных.
- GIL ограничивает параллелизм для CPU‑bound задач в CPython — используйте multiprocessing.
- concurrent.futures даёт удобный и масштабируемый API для пулов потоков.
Notes
Важно: прежде чем добавлять многопоточность, убедитесь, что именно ожидание I/O является узким местом. Тестируйте и мониторьте поведение в условиях, близких к реальному трафику.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
