Мониторинг Droplet на DigitalOcean: графики и оповещения

Быстрые ссылки
Графики метрик Droplet
Как собираются метрики?
Углублённый мониторинг с помощью Linux‑инструментов
Создание автоматизированных политик оповещений
Ограничения мониторинга DigitalOcean
Заключение
Графики метрик Droplet
Самый простой способ следить за состоянием Droplet — использовать графики в Cloud Control Panel. Войдите в свою учётную запись DigitalOcean и выберите нужный Droplet. Вы попадёте на экран “Graphs”.
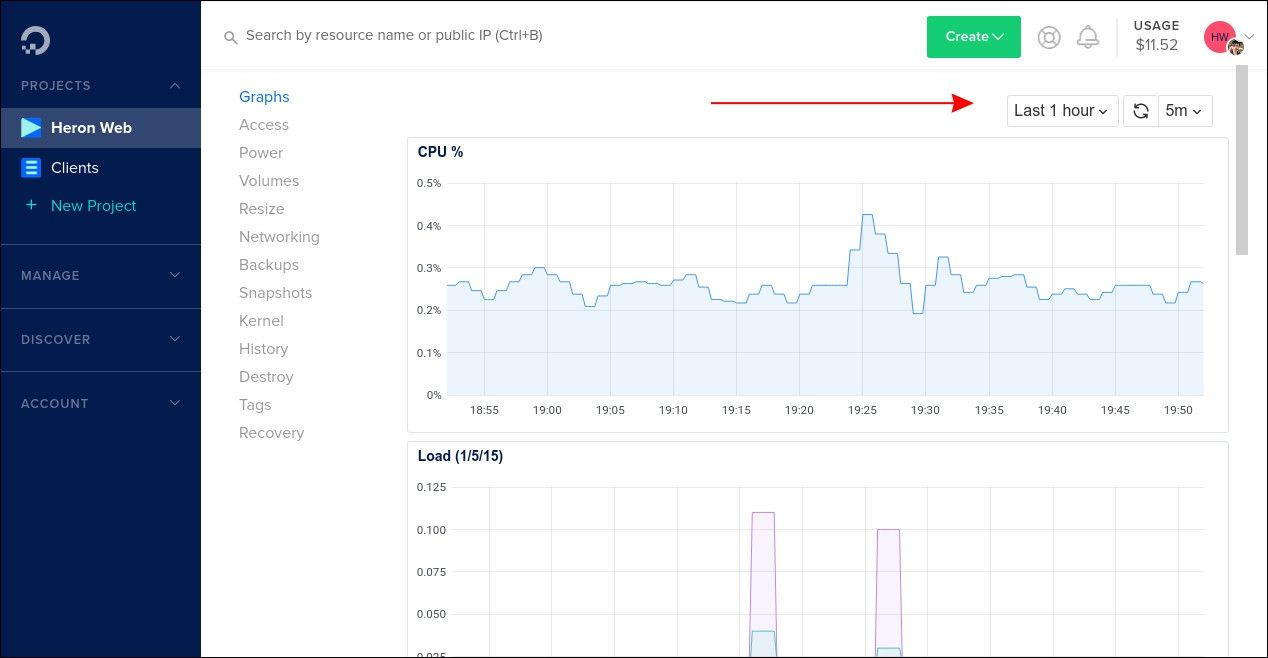
Графики показывают основные показатели: загрузку CPU, использование оперативной памяти, диск и сетевую активность. В правом верхнем углу можно выбрать временной интервал и интервал автоматического обновления. Доступные окна данных: от последнего часа до 14 дней.
Важное: графики дают обзор «что происходит», но не объясняют причины. Для корневого анализа нужны дополнительные инструменты и логи.
Как собираются метрики?
DigitalOcean использует open-source утилиту do-agent для сбора метрик с Droplet. Агент поддерживается на Ubuntu, CentOS, Debian и Fedora. Другие дистрибутивы или устаревшие версии не могут использовать do-agent и вместо полного набора графиков показывают лишь базовые показатели.
Если на сервере — поддерживаемая ОС, но вы не видите полных графиков, возможно, агент не установлен или Droplet был обновлён с более ранней сборки.
Подключитесь по SSH и выполните установочный скрипт:
curl -sSL https://repos.insights.digitalocean.com/install.sh | sudo bashДанные начнут появляться в панели управления в течение нескольких минут.
Технически do-agent периодически читает данные из виртуальной файловой системы /proc и отправляет метрики через gRPC на ingest‑эндпоинт DigitalOcean. Агент аутентифицируется как принадлежащий вашему Droplet, поэтому данные попадают в соответствующую учётную запись.
Безопасность: do-agent только отправляет метрики и не получает конфигурацию; он использует порты 80 и 443, поэтому присутствие агента не мешает запуску веб‑сервера.
Углублённый мониторинг с помощью Linux‑инструментов
Графики дают быстрое представление, но для расследования всплесков нагрузки подключайтесь по SSH и используйте стандартные Linux‑утилиты.

Основные команды и короткое описание:
- top — интерактивный просмотр процессов. По умолчанию сортирует по CPU. Shift+M — сортировка по памяти. e и Shift+E переключают единицы отображения.
- htop — улучшенная версия top с удобной навигацией (если установлена).
- uptime — показывает время работы сервера, количество подключений пользователя и среднюю нагрузку (load average) за 1, 5 и 15 минут.
- vmstat — системные статистики по памяти, процессам, подкачке и I/O в реальном времени.
- iotop — отображает активность ввода‑вывода по процессам и процент времени ожидания I/O.
- iostat — статистики по дисковым устройствам; полезно для долгосрочной диагностики.
- ss / netstat — текущие сетевые соединения и порты.
- tcpdump — захват сетевого трафика для глубокой сетевой диагностики.
Пример использования iotop:
sudo iotop -oКлюч -o показывает только процессы, которые выполняют операции ввода‑вывода.
Пояснение load average: это среднее количество процессов, выполняющихся или ожидающих выполнения. Значение сравнивают с количеством vCPU: load average 4.0 на сервере с 4 vCPU означает, что система полностью загружена.

Рекомендация: при резких всплесках CPU сверяйте график CPU в панели DigitalOcean, список процессов через top/htop и затем логи приложения (systemd/journal, файлы логов приложения) для поиска корневой причины.
Создание автоматизированных политик оповещений
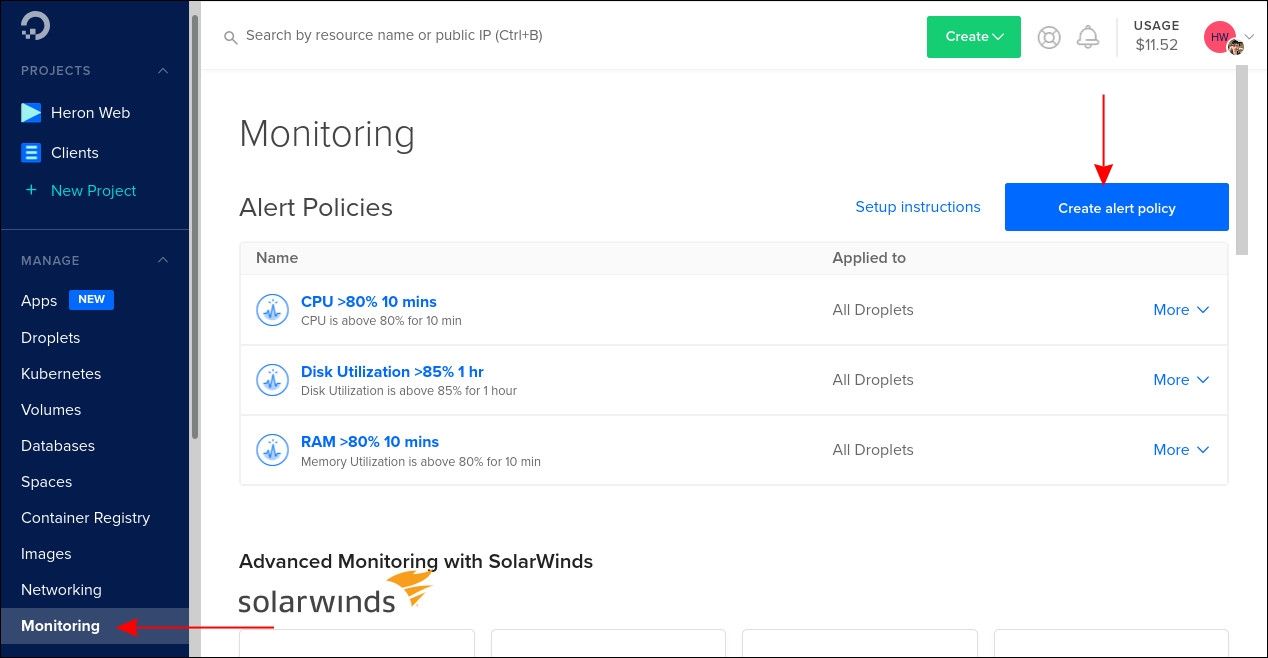
Вы можете подписаться на оповещения при превышении порога метрики. Оповещения приходят по электронной почте или в Slack.
- В панели управления нажмите ссылку Monitoring в боковой панели. Откроется список ваших оповещений. Нажмите Create alert policy.
Выберите метрику и окно агрегации: 5, 10, 30 или 60 минут. Аггрегация предотвращает шум от кратковременных всплесков. Пример: «оповещение при CPU > 70% более 5 минут».
Выберите цель: отдельные Droplet, тег (например, для Kubernetes‑нод) или All Droplets.
Укажите способ отправки: электронная почта по умолчанию и/или интеграция со Slack. Для Slack нажмите Connect Slack, авторизуйте workspace и выберите канал или личное сообщение.
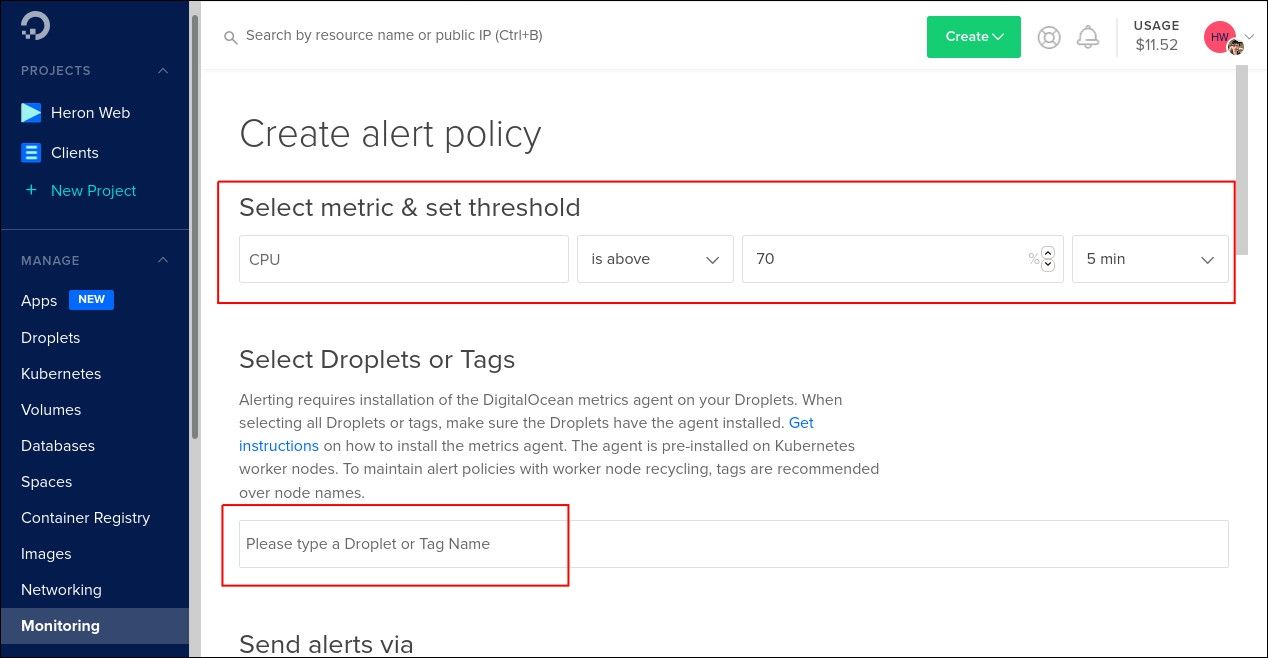
Важно: одна политика поддерживает только одну метрику. Для отслеживания нескольких показателей создавайте отдельные политики.
Критерии настройки порогов (руководство):
- Базовая нагрузка: измерьте средние значения в спокойное время и установите пороги на 2–3× эти значения для предупреждений раннего уровня.
- Критические пороги: ориентируйтесь на эксплуатационные границы вашего приложения (например, замедление выше X ms или ошибки > Y%).
- Аггрегация: выставляйте окно не менее 5 минут, чтобы фильтровать кратковременные пики.
Лучшие практики оповещений
- Минимизируйте шум: избегайте множества оповещений с низким приоритетом. Начните с 2–3 критичных метрик.
- Разделяйте уведомления: отдельные каналы — для on‑call и для команд разработки.
- Тестируйте уведомления: создавайте временные политики, эмулируйте условия и проверяйте доставку.
- Документируйте триггеры и действие в runbook.
Плейбук: быстрая проверка при получении оповещения
Ниже — практический список действий, который можно выполнить после получения оповещения.
- Получили оповещение: зафиксируйте время, канал и текст триггера.
- Откройте графики в панели DigitalOcean: CPU, RAM, диск, сеть — смотрите тренды за последний час.
- Подключитесь к Droplet по SSH.
- Выполните quick‑check: top/htop, uptime, dmesg | tail -n 50, sudo iotop -o, sudo ss -tunap | head.
- Откройте логи приложения и systemd: journalctl -u
-n 200. - Если очевиден процесс‑причина — рестарт сервиса с последующей проверкой логов; если нет — масштабирование/оркестрация/эскалация.
- После действий — документирование: причины, что предпринято, время восстановления.
SOP для восстановления:
- Если проблема — избыточная нагрузка CPU и процесс контролируем: перезапустить сервис, ограничить количество воркеров.
- Если проблема — дисковый I/O: найти процесс с высоким I/O, остановить бэкап/тяжёлую операцию, оценить необходимость увеличения IOPS/типа диска.
- Если сеть: проверить маршрутизацию/файрвол, выполнить tcpdump, эскалировать к сетевой команде.
Ограничения мониторинга DigitalOcean
DigitalOcean предоставляет метрики инфраструктуры и базовый набор оповещений. Но есть ограничения:
- Нет глубокого application‑level трейсинга по умолчанию — нужны APM/логирование.
- Невозможно включить несколько метрик в одну политику оповещений; правила просты и подходят для базовых сценариев.
- Для некоторых дистрибутивов или старых настроек агент может быть недоступен — в этом случае вы видите только базовые графики.
Когда DigitalOcean‑мониторинг недостаточен:
- Если вам нужны распределённые трейсики (distributed traces) — подключайте APM: OpenTelemetry, Jaeger, Datadog и т. д.
- Если важна длительная ретенция метрик с агрегированиями — используйте внешние TSDB (Prometheus, InfluxDB) или SaaS‑провайдеров.
Альтернативные подходы
- Prometheus + node_exporter: гибкая модель сбора метрик, локальный pull‑механизм, хорош для кластеров.
- OpenTelemetry + выбранный backend: приоритет для метрик, логов и трейсов в единой схеме.
- Экспорт логов в централизованную систему (ELK/EFK, LogDNA, Papertrail) для корреляции между логами и метриками.
Роль‑ориентированные чек‑листы
DevOps / SRE:
- Проверить do-agent и его статус.
- Сверить графики DigitalOcean с данными node_exporter/Prometheus.
- Убедиться в наличии runbook и канала оповещений on‑call.
Разработчик:
- Проверить метрики приложения: latency, error rate.
- Просмотреть последние деплои и изменения конфигурации.
- При необходимости откатить проблемный релиз.
Менеджер/Продукт‑владелец:
- Понять, влияет ли инцидент на SLA/UX.
- Назначить приоритеты и ресурсы для устранения.
Критерии приёмки
Чтобы считать систему мониторинга настроенной и рабочей:
- do-agent установлен и отправляет метрики (видны полные графики).
- Оповещения доставляются на почту и/или в Slack при тестовых триггерах.
- Документирован runbook для 3‑х критичных сценариев.
- Есть процесс пост‑инцидентного анализа.
Методика анализа инцидента (мини‑методология)
- Детектирование: алерт или автоматический контроль.
- Сбор данных: графики, top/htop, логи, трассы.
- Идентификация: изолировать компонент/процесс.
- Вмешательство: рестарт, ограничение нагрузки, масштабирование.
- Пост‑инцидент: RCA и меры предотвращения.
Диаграмма принятия решения
flowchart TD
A[Получено оповещение] --> B{Явная причина в графиках?}
B -- Да --> C[Подключиться к Droplet, выполнить top/htop]
B -- Нет --> D[Собрать логи и трассы]
C --> E{Процесс виновник?}
E -- Да --> F[Перезапустить/ограничить процесс]
E -- Нет --> D
D --> G{Сеть / Диск / CPU}
G -- Сеть --> H[Проверить ss/tcpdump]
G -- Диск --> I[Проверить iotop/iostat]
G -- CPU --> J[Проверить топ-процессы, профилировать]
H --> K[Эскалация на сетевую команду]
I --> L[Отключить тяжёлые I/O, оценить масштабирование диска]
J --> M[Эскалация на команду приложения]
F --> N[Мониторить восстановление, закрыть оповещение]
K --> N
L --> N
M --> NФакт‑бокс: ключевые параметры
- Поддерживаемые ОС: Ubuntu, CentOS, Debian, Fedora.
- Время появления данных в панели: в течение нескольких минут.
- Окна данных: от 1 часа до 14 дней.
- Возможные каналы оповещений: e‑mail, Slack.
Тесты и критерии приёмки для оповещений
Тестовый сценарий:
- Создать временную политику (CPU > 1% за 5 минут) и назначить на тестовый Droplet.
- Смоделировать нагрузку (например, stress-ng). Ожидаемый результат: получение оповещения в почту/Slack.
- Отключить политику и убедиться, что оповещения прекращаются.
Успех: уведомление пришло в течение агрегационного окна и включенное действие сработало.
Глоссарий (одна строка)
- Droplet — виртуальная машина в DigitalOcean.
- do-agent — агент сбора метрик DigitalOcean (open‑source).
- load average — среднее количество активных и ожидающих процессов за период.
Часто задаваемые вопросы
Как установить do-agent?
Подключитесь по SSH и выполните:
curl -sSL https://repos.insights.digitalocean.com/install.sh | sudo bashПосле установки данные появятся в панели через несколько минут.
Какие метрики доступны и как долго они хранятся?
Доступны CPU, память, диск и сетевые метрики. Данные в интерфейсе доступны в окнах от 1 часа до 14 дней.
Можно ли отправлять оповещения в Slack?
Да. Нажмите Connect Slack в настройках оповещений, авторизуйте workspace и укажите канал или прямое сообщение.
Заключение
Мониторинг DigitalOcean даёт быстрый обзор состояния Droplet и простые средства оповещений. Для расследования и устранения проблем используйте сочетание графиков Cloud Control Panel, do-agent и привычных Linux‑утилит. При необходимости дополняйте систему внешними APM и системами логирования для детального анализа.
Ключевые шаги для старта: установить do-agent на поддерживаемой ОС, определить 2–3 критичных оповещения, создать runbook и протестировать доставку уведомлений.
Краткое напоминание: графики показывают «что», а инструменты и логи — помогают найти «почему».
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
