Установка и настройка GlusterFS на Rocky Linux — пошаговый гид

Введение
GlusterFS (Gluster File System) — это свободная распределённая файловая система от Red Hat. Она объединяет несколько серверов в единый логический том и подходит для крупных объёмов данных. GlusterFS поддерживает масштабирование, репликацию и простую установку.
Краткое определение: GlusterFS — распределённая сеть файловых кирпичей (bricks), объединённых в том (volume).
В этой инструкции показано, как установить GlusterFS 9 на две машины Rocky Linux, создать реплицируемый том и смонтировать его на клиенте. Приведён полный набор шагов: подготовка хостов, настройка дисков, добавление репозитория, установка, настройка брандмауэра, создание и проверка тома, а также рекомендации по следующим операциям и отладке.
Требования
- Две машины с Rocky Linux. У каждой должен быть дополнительный диск для данных.
- Настроен root-пароль или доступ через sudo.
- Статические IP-адреса и корректные записи в /etc/hosts.
Пример конфигурации, используемой в руководстве:
- server1.localdomain.lan — 192.168.10.15
- server2.localdomain.lan — 192.168.10.20
Содержание этой статьи
- Подготовка FQDN и /etc/hosts
- Настройка разделов и монтирование дисков
- Добавление репозитория GlusterFS для Rocky Linux
- Установка и запуск сервера GlusterFS
- Открытие портов в firewalld
- Инициализация кластера и проверка пиров
- Создание реплицируемого тома myvolume
- Монтирование тома на клиенте и проверка записи
- Тестирование отказоустойчивости
- Рекомендации по производительности, безопасности и резервированию
- Чек-листы, сценарии тестирования и план реагирования на инциденты
Настройка FQDN и /etc/hosts
Установите полные имена (FQDN) на каждой машине и добавьте соответствующие записи в /etc/hosts.
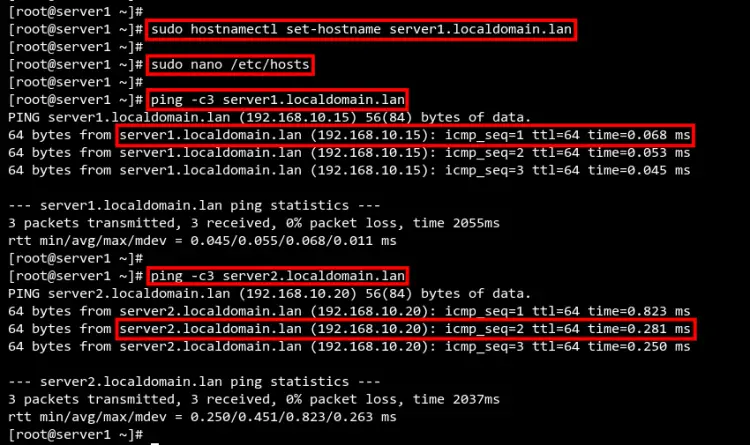
На server1:
sudo hostnamectl set-hostname server1.localdomain.lanНа server2:
sudo hostnamectl set-hostname server2.localdomain.lanОтредактируйте /etc/hosts на обеих машинах:
sudo nano /etc/hostsДобавьте строки:
192.168.10.15 server1.localdomain.lan
192.168.10.20 server2.localdomain.lanСохраните и проверьте связь:
ping -c3 server1.localdomain.lan
ping -c3 server2.localdomain.lanИзображение:
Важно: корректный DNS или /etc/hosts необходим для корректной работы peer probe и клиентского монтирования.
Настройка разделов и точек монтирования
Рекомендуется выделить отдельный диск или раздел для данных GlusterFS. В учебном примере на обеих машинах есть второй диск /dev/vdb1 размером ~5 ГБ.
Добавьте точки монтирования в /etc/fstab. На server1 используем /data/vol1, на server2 — /data/vol2.
На server1:
sudo nano /etc/fstab
# Добавьте строку
/dev/vda1 /data/vol1 ext4 defaults 0 0На server2:
sudo nano /etc/fstab
# Добавьте строку
/dev/vda1 /data/vol2 ext4 defaults 0 0Примените монтирование:
sudo mount -a
sudo df -hСоздайте директории для «кирпичей» (bricks):
На server1:
sudo mkdir -p /data/vol1/brick0На server2:
sudo mkdir -p /data/vol2/brick0Примечание: путь к brick должен указывать на пустую файловую систему или каталог, предназначенный только для GlusterFS.
Добавление репозитория GlusterFS для Rocky Linux
На момент написания Rocky Linux напрямую не поставлял GlusterFS 9 в основном репозитории. Мы используем пакет «centos-release-gluster9» и корректируем URL репозитория под Rocky Vault.
Установите пакет репозитория:
sudo dnf install centos-release-gluster9Отредактируйте файл /etc/yum.repos.d/CentOS-Gluster-9.repo и замените или добавьте baseurl на зеркало Rocky Vault. Пример содержимого:
# CentOS-Gluster-9.repo
[centos-gluster9]
name=CentOS-$releasever - Gluster 9
#mirrorlist=http://mirrorlist.centos.org?arch=$basearch&release=$releasever&repo=storage-gluster-9
baseurl=https://dl.rockylinux.org/vault/centos/8.5.2111/storage/x86_64/gluster-9/
gpgcheck=1
enabled=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-SIG-StorageЗатем обновите список репозиториев:
sudo dnf repolistИзображение: 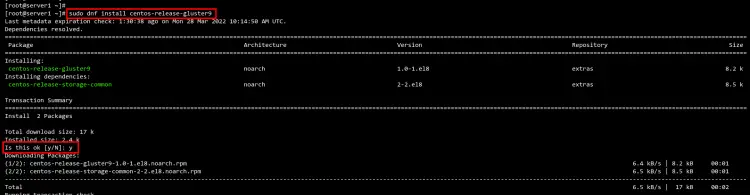
Совет: сохраняйте резервную копию оригинального .repo файла перед изменением.
Установка GlusterFS Server
Установите пакеты GlusterFS на обеих серверах:
sudo dnf install glusterfs glusterfs-libs glusterfs-serverПосле установки включите и запустите службу:
sudo systemctl enable glusterfsd.service
sudo systemctl start glusterfsd.service
sudo systemctl status glusterfsd.serviceОжидаемый статус: active (exited) — это нормальное поведение systemd для данного процесса: сервис доступен.

Открытие портов в firewalld
GlusterFS использует ряд портов; проще всего добавить сервис glusterfs в firewalld:
sudo firewall-cmd --add-service=glusterfs --permanent
sudo firewall-cmd --reload
sudo firewall-cmd --list-servicesПроверьте, что в списке присутствует glusterfs.
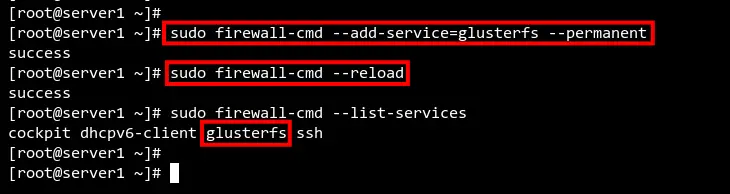
Если вы используете нестандартные сети — откройте порты вручную или настройте соответствующие интерфейсы.
Инициализация кластера GlusterFS (peer probe)
На server1 выполните peer probe для добавления server2 в кластер:
sudo gluster peer probe server2.localdomain.lanВы должны увидеть: peer probe: success
Проверьте статус пиров на server1 и server2:
sudo gluster peer statusОжидается состояние одного пира (server2). Повторите на второй ноде.
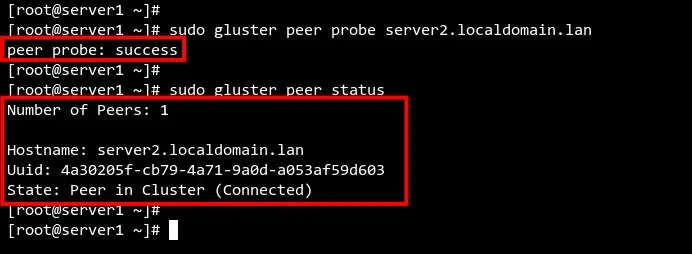
Пояснение: команда peer probe инициирует обмен ключами и настройку пиринга. Она должна выполняться только с одной ноды для добавления конкретного пира.
Создание реплицируемого тома (volume)
В примере создаём том myvolume с типом replica 2: по одному brick’у на каждой машине.
На одной из нод (обычно на server1) выполните:
sudo gluster volume create myvolume replica 2 server1.localdomain.lan:/data/vol1/brick0 server2.localdomain.lan:/data/vol2/brick0Если команда вернёт подтверждение, введите y и нажмите Enter. Затем запустите том:
sudo gluster volume start myvolume
sudo gluster volume status
sudo gluster volume infoПроверьте, что том в состоянии Started и Online.
Изображение: 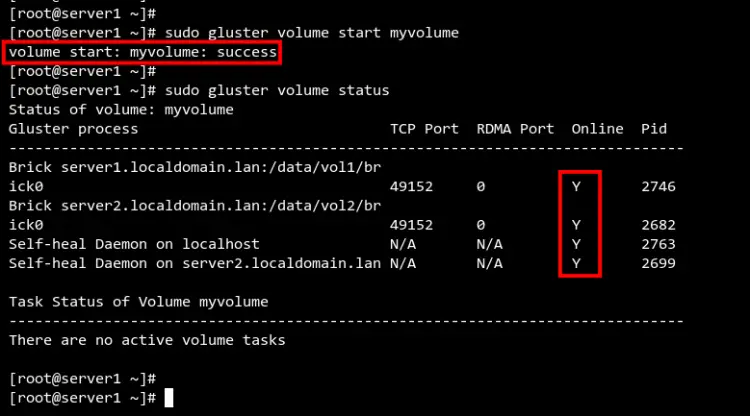
Важно: если вы используете репликацию, количество replica должно равняться количеству кирпичей в репликации и нечётному для quorum в больших кластерах.
Монтирование GlusterFS на клиенте
На клиентской машине (client) добавьте те же записи в /etc/hosts и проверьте связь:
sudo nano /etc/hosts
# Добавьте
192.168.10.15 server1.localdomain.lan
192.168.10.20 server2.localdomain.lan
ping -c3 server1.localdomain.lanУстановите клиентский пакет:
sudo dnf install glusterfs-clientСоздайте точку монтирования и смонтируйте том:
sudo mkdir /data
sudo mount.glusterfs server1.localdomain.lan:/myvolume /dataПроверьте монтирование:
df -h | grep myvolumeИзображение: 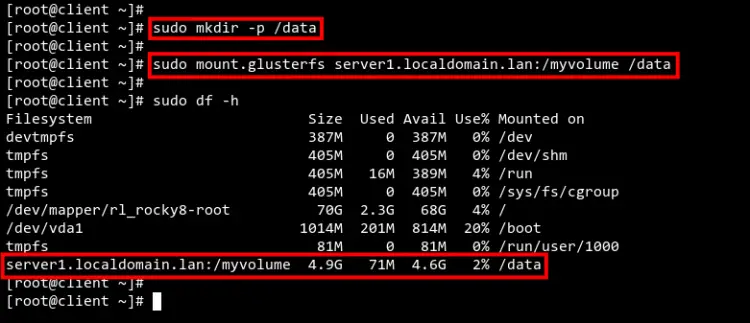
Совет: для автоподключения на перезагрузке используйте fstab с опцией netdev:
server1.localdomain.lan:/myvolume /data glusterfs defaults,_netdev 0 0Тестирование записи и отказоустойчивости
На клиенте создайте файлы:
cd /data
touch file{1..5}.mdНа server1 проверьте содержимое brick:
ls /data/vol1/brick0Затем перезагрузите server1:
sudo shutdown -r nowНа server2 проверьте статус пиров:
sudo gluster peer status# ожидаем состояние disconnected или peer downПроверьте наличие файлов на server2:
ls /data/vol2/brick0На клиенте доступ к томy сохраняется — это подтверждает репликацию и работу высокой доступности.
Изображение: 
Проверка целостности и синхронизации
После восстановления server1 запустите проверку status и при необходимости rebalance или heal.
Проверка информации о репликации и состоянии:
sudo gluster volume heal myvolume info
sudo gluster volume heal myvolume info split-brainЗапуск синхронизации и ребаланса (если нужно):
sudo gluster volume rebalance myvolume start
sudo gluster volume rebalance myvolume statusКороткое определение: heal — механизм самовосстановления реплик; rebalance — перераспределение хэшей и данных.
Частые проблемы и отладка
- Проблема: «peer probe: timed out» — проверьте /etc/hosts, firewall, SELinux и сетевую связность.
- Проблема: том не стартует — проверьте журналы systemd и /var/log/glusterfs/.
- split-brain — возникает при одновременной записи на обе ноды при сетевом разрыве; решается проверкой и ручным слиянием.
Полезные команды для дебага:
journalctl -u glusterfsd.service -b
sudo gluster volume status myvolume detail
sudo tail -n 200 /var/log/glusterfs/glusterd.logВажно: перед выполнением destructive операций (удаление тома, форматирование) сделайте резервную копию.
Производительность и оптимизация
Рекомендации:
- Используйте отдельные диски/тома для brick’ов.
- В продакшене применяйте RAID или LVM поверх физических дисков.
- Настройте network tuning (MTU, offloading) при необходимости.
- Отключайте nfs/other services на томах, если они не используются.
Параметры, влияющие на производительность:
- io-threading и quick-read/ write-behind — настраиваются через gluster volume set.
- Установка cache.size и performance.cache-size в зависимости от памяти.
Пример изменения опции:
sudo gluster volume set myvolume performance.cache-size 512MBЗамечание: тестируйте изменения на тестовой среде перед продакшеном.
Безопасность и SELinux
- Если у вас включён SELinux, убедитесь, что контексты файлов и точек монтирования корректны.
- Для межузловой аутентификации используйте защищённые сети или VPN.
- Ограничьте доступ к серверу по IP-адресам в брандмауэре.
Если SELinux блокирует операции, временно проверьте состояние:
sestatus
sudo setenforce 0 # только для теста, не рекомендуется в продакшенеДля постоянной работы лучше настроить соответствующие boolean и контексты.
Когда GlusterFS не подходит
- Если вам нужна тонкая POSIX-совместимая блок-ориентированная система с миллионами мелких файлов и крайне низкой задержкой — рассмотрите специализированные решения.
- Для очень больших распределённых хранилищ с огромной масштабируемостью (сотни нод) может подойти Ceph, а не GlusterFS.
Альтернативы
- Ceph — блок/объект/файловая система с высокой масштабируемостью.
- NFS с DRBD — простая репликация между двумя нодами, но менее гибкая на масштаб.
- S3-совместимые объектные хранилища — для приложений, ориентированных на объектный доступ.
Модель зрелости и рекомендации по развёртыванию
- Уровень 0 (POC): 2 ноды, репликация, тесты на отказ.
- Уровень 1 (Production small): 3 ноды, реплика 3, мониторинг, бэкапы.
- Уровень 2 (Enterprise): 3+ нод, гео-репликация, интеграция с LDAP/ACL, мониторинг и SLA.
Чек-лист перед вводом в эксплуатацию
Для системного администратора:
- Проверена сетевая связность между всеми нодами
- Диски выделены и смонтированы корректно
- Репозиторий и пакеты установлены одинаковых версий
- Firewalld открыл сервис glusterfs
- Создан и запущен том, проверен статус
- Настроено автоматическое монтирование на клиентах
- Выполнено тестирование записи и отказоустойчивости
Для DevOps / владельца приложения:
- Приложение протестировано на совместимость с сетевой файловой системой
- Выполнены тесты производительности и IO
- Составлен план бэкапа и восстановления
Критерии приёмки
- Том myvolume доступен с клиента и монтируется автоматически.
- Данные, записанные на клиенте, видны на обоих brick’ах.
- При отключении одного из серверов клиент продолжает работать без ошибок.
- После восстановления ноды выполняется heal и синхронизация данных.
План реагирования на инциденты (runbook)
Симптом: нода не отвечает (network timeout).
- Проверить состояние пиров: sudo gluster peer status
- Проверить сетевую доступность: ping, traceroute
- Проверить файервол: sudo firewall-cmd –list-all
Симптом: split-brain
- Выполнить: sudo gluster volume heal myvolume info split-brain
- Ручная проверка конфликтующих файлов и разрешение путём выбора корректной версии.
Симптом: данные отсутствуют на всех нодах
- Остановить запись клиентов
- Проверить логи glusterd и brick’ов
- Восстановить из резервной копии
Тестовые сценарии и критерии приёмки
- Создание файлов: создать 1000 файлов разного размера и проверить репликацию.
- Нагрузочный тест: запустить fio/bonnie++ с типичными профилями приложения.
- Отказ ноды: отключить server1 и проверить работу клиента.
- Восстановление: вернуть server1 онлайн и проверить heal и rebalance.
Критерии: все тесты проходят без потери данных и с приемлемой производительностью для вашего приложения.
Примеры полезных команд (cheat sheet)
- Добавление пира:
sudo gluster peer probe - Список пиров:
sudo gluster peer status- Создание тома:
sudo gluster volume create replica host1:/path host2:/path - Запуск тома:
sudo gluster volume start - Статус тома:
sudo gluster volume status
sudo gluster volume info- Heal и rebalance:
sudo gluster volume heal info
sudo gluster volume rebalance start Словарь — 1 строка каждое определение
- Brick: место хранения данных на конкретной ноде (обычно каталог или раздел).
- Volume: логический том GlusterFS, объединяющий несколько brick’ов.
- Peer: узел кластера GlusterFS.
- Heal: восстановление синхронизации реплик.
- Rebalance: перераспределение данных между brick’ами.
Рекомендации по обслуживанию
- Регулярно проверяйте состояние томов и пиров.
- Настройте мониторинг (Prometheus, Grafana) для ключевых метрик (latency, IOPS, network).
- Планируйте окно обслуживания для обновлений версий GlusterFS.
- Делайте регулярные бэкапы критичных данных и проверяйте процедуру восстановления.
Заключение
Поздравляем! Вы развернули кластер GlusterFS на двух серверах Rocky Linux. Вы настроили реплицируемый том myvolume, смонтировали его на клиенте, протестировали запись и отказоустойчивость. Дальше рекомендуется настроить мониторинг, регулярные бэкапы, протестировать производительность под нагрузкой и подготовить план обновления для production-среды.
Важно: перед переводом в промышленную эксплуатацию протестируйте сценарии восстановления, split-brain и обновлений на копии окружения.
Ключевые действия: поддерживайте одинаковые версии пакетов на всех узлах, контролируйте сеть и регулярно проверяйте heal/rebalance.
Контактные рекомендации
Если вы управляете несколькими кластерами, ведите реестр версий, конфигураций и заметки об инцидентах. Это значительно ускорит диагностику и восстановление в будущем.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
