Установка Apache Spark на Ubuntu 22.04

TL;DR
Кратко: на сервере Ubuntu 22.04 установите Java, скачайте сборку Spark, настройте переменные окружения, создайте системного пользователя и systemd‑сервисы для Master и Worker. Проверьте веб‑интерфейс на порту 8080 и запустите spark-shell или pyspark для проверки работоспособности.
Важно: используйте стабильную версию Spark, корректно указывайте IP мастер‑узла в конфигурации worker и не забывайте про брандмауэр/SELinux, если они активны.
Apache Spark — свободный, с открытым кодом движок общего назначения для обработки данных. Он выполняет быстрые распределённые запросы, используя хранилище в оперативной памяти кластерных узлов. Spark предоставляет высокоуровневые API для Java, Scala, Python и R, а также инструменты Spark SQL, MLlib, GraphX и Streaming.
В этой инструкции показано, как установить Apache Spark на Ubuntu 22.04 и запустить Master и Worker как сервисы systemd.
Что понадобится
- Сервер с Ubuntu 22.04.
- Доступ от root или sudo.
Шаг 1 — Установка Java
Spark основан на Java. Установите JDK, если он ещё не установлен:
apt-get install default-jdk curl -yПроверьте установку:
java -versionПример вывода (может отличаться по версии):
openjdk version "11.0.15" 2022-04-19
OpenJDK Runtime Environment (build 11.0.15+10-Ubuntu-0ubuntu0.22.04.1)
OpenJDK 64-Bit Server VM (build 11.0.15+10-Ubuntu-0ubuntu0.22.04.1, mixed mode, sharing)Шаг 2 — Скачивание и установка Apache Spark
На момент написания статья использует Spark 3.2.1. Скачайте архив:
wget https://dlcdn.apache.org/spark/spark-3.2.1/spark-3.2.1-bin-hadoop3.2.tgzРаспакуйте архив:
tar xvf spark-3.2.1-bin-hadoop3.2.tgzПереместите содержимое в /opt/spark:
mv spark-3.2.1-bin-hadoop3.2/ /opt/sparkДобавьте переменные окружения для текущего пользователя (или для системного пользователя spark, если настраиваете глобально):
nano ~/.bashrcВставьте в конец файла:
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbinАктивируйте изменения:
source ~/.bashrcСоздайте системного пользователя для запуска Spark:
useradd sparkСделайте владельцем каталога /opt/spark созданного пользователя:
chown -R spark:spark /opt/sparkПримечание: при продакшен‑развёртывании учитывайте разделение прав, назначайте отдельного пользователя и группы, ограничивайте доступ к логам и конфигам.
Шаг 3 — Systemd сервисы для Master и Worker
Создадим unit для Spark Master:
nano /etc/systemd/system/spark-master.serviceВставьте:
[Unit]
Description=Apache Spark Master
After=network.target
[Service]
Type=forking
User=spark
Group=spark
ExecStart=/opt/spark/sbin/start-master.sh
ExecStop=/opt/spark/sbin/stop-master.sh
[Install]
WantedBy=multi-user.targetСоздайте unit для Worker (в старой конфигураторе слово “slave” встречается в примере; в новых версиях рекомендуется использовать “worker”). В примере ниже оставлено имя файла spark-slave.service для совместимости с оригиналом:
nano /etc/systemd/system/spark-slave.serviceВставьте (замените your-server-ip на IP вашего Master):
[Unit]
Description=Apache Spark Slave
After=network.target
[Service]
Type=forking
User=spark
Group=spark
ExecStart=/opt/spark/sbin/start-slave.sh spark://your-server-ip:7077
ExecStop=/opt/spark/sbin/stop-slave.sh
[Install]
WantedBy=multi-user.targetПерезагрузите демон systemd, чтобы применить новые unit-файлы:
systemctl daemon-reloadЗапустите и включите Master:
systemctl start spark-master
systemctl enable spark-masterПроверьте статус Master:
systemctl status spark-masterПример вывода статуса Master:
? spark-master.service - Apache Spark Master
Loaded: loaded (/etc/systemd/system/spark-master.service; disabled; vendor preset: enabled)
Active: active (running) since Thu 2022-05-05 11:48:15 UTC; 2s ago
Process: 19924 ExecStart=/opt/spark/sbin/start-master.sh (code=exited, status=0/SUCCESS)
Main PID: 19934 (java)
Tasks: 32 (limit: 4630)
Memory: 162.8M
CPU: 6.264s
CGroup: /system.slice/spark-master.service
??19934 /usr/lib/jvm/java-11-openjdk-amd64/bin/java -cp "/opt/spark/conf/:/opt/spark/jars/*" -Xmx1g org.apache.spark.deploy.mast>
May 05 11:48:12 ubuntu2204 systemd[1]: Starting Apache Spark Master...
May 05 11:48:12 ubuntu2204 start-master.sh[19929]: starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-spark-org>
May 05 11:48:15 ubuntu2204 systemd[1]: Started Apache Spark Master.Шаг 4 — Доступ к веб‑интерфейсу и проверка портов
Master по умолчанию доступен на порту 8080, а для кластерного взаимодействия используется порт 7077. Проверьте прослушиваемые порты:
ss -antpl | grep javaПример вывода:
LISTEN 0 4096 [::ffff:69.28.88.159]:7077 *:* users:(("java",pid=19934,fd=256))
LISTEN 0 1 *:8080 *:* users:(("java",pid=19934,fd=258)) Откройте в браузере: http://your-server-ip:8080 — вы должны увидеть дашборд Master:
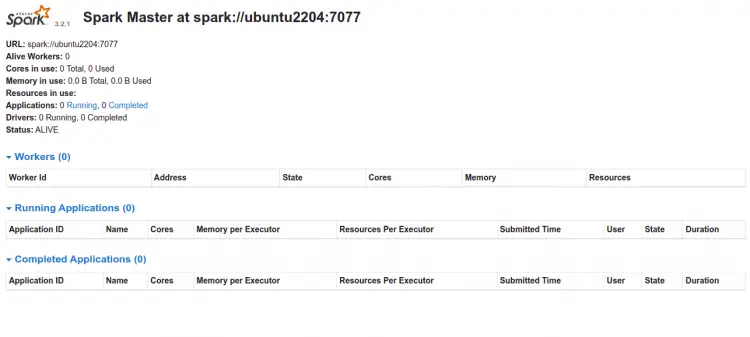
Шаг 5 — Запуск Worker
Запустите и включите Worker:
systemctl start spark-slave
systemctl enable spark-slaveПроверьте статус Worker:
systemctl status spark-slaveПример вывода статуса Worker:
? spark-slave.service - Apache Spark Slave
Loaded: loaded (/etc/systemd/system/spark-slave.service; disabled; vendor preset: enabled)
Active: active (running) since Thu 2022-05-05 11:49:32 UTC; 4s ago
Process: 20006 ExecStart=/opt/spark/sbin/start-slave.sh spark://69.28.88.159:7077 (code=exited, status=0/SUCCESS)
Main PID: 20017 (java)
Tasks: 35 (limit: 4630)
Memory: 185.9M
CPU: 7.513s
CGroup: /system.slice/spark-slave.service
??20017 /usr/lib/jvm/java-11-openjdk-amd64/bin/java -cp "/opt/spark/conf/:/opt/spark/jars/*" -Xmx1g org.apache.spark.deploy.work>
May 05 11:49:29 ubuntu2204 systemd[1]: Starting Apache Spark Slave...
May 05 11:49:29 ubuntu2204 start-slave.sh[20006]: This script is deprecated, use start-worker.sh
May 05 11:49:29 ubuntu2204 start-slave.sh[20012]: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-spark-org.>
May 05 11:49:32 ubuntu2204 systemd[1]: Started Apache Spark Slave.Обновите страницу веб‑интерфейса Master — вы увидите зарегистрированный Worker:
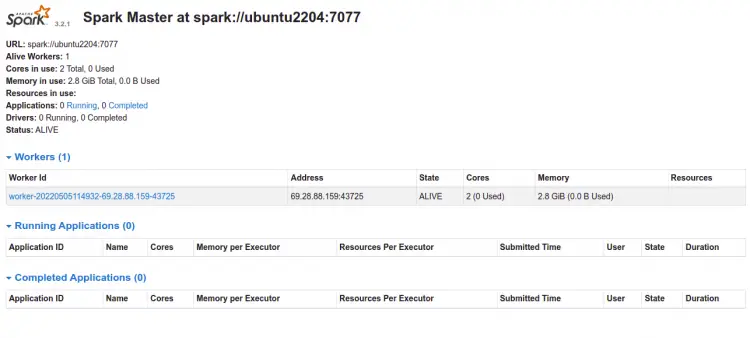
Нажмите на узел для подробной информации:
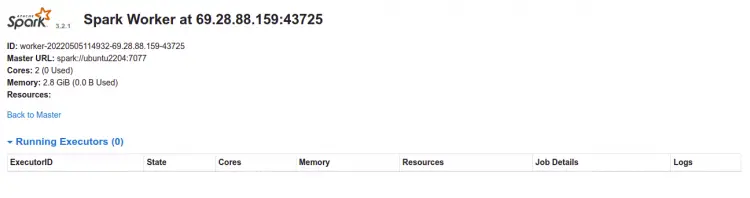
Как получить доступ к spark-shell и pyspark
Для запуска Scala REPL Spark используйте:
spark-shellОжидаемый фрагмент вывода при старте (вариант для Scala):
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.12-3.2.1.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
22/05/05 11:50:46 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://ubuntu2204:4040
Spark context available as 'sc' (master = local[*], app id = local-1651751448361).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.2.1
/_/
Using Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 11.0.15)
Type in expressions to have them evaluated.
Type :help for more information.
scala>Для Python используйте:
pysparkФрагмент вывода для pyspark:
Python 3.10.4 (main, Apr 2 2022, 09:04:19) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.12-3.2.1.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
22/05/05 11:53:17 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.2.1
/_/
Using Python version 3.10.4 (main, Apr 2 2022 09:04:19)
Spark context Web UI available at http://ubuntu2204:4040
Spark context available as 'sc' (master = local[*], app id = local-1651751598729).
SparkSession available as 'spark'.
>>> Выйдите из оболочки: в Scala выполните :quit, в Python — Ctrl+D.
Критерии приёмки
- systemctl status показывает Active: active (running) для spark-master и spark-slave.
- Веб‑интерфейс Master доступен по http://your-server-ip:8080 и отображает зарегистрированные Workers.
- Команда spark-shell или pyspark запускается и создаёт Spark контекст.
Чек‑лист администратора
- Установлен Java (JDK).
- /opt/spark принадлежит пользователю spark.
- systemd‑unit файлы созданы и перезагружены daemon‑ом.
- Порты 7077 и 8080 открыты в фаерволле или доступны внутри сети.
- Логи Spark находятся и доступны в /opt/spark/logs.
Распространённые ошибки и как их решать
- Worker не подключается к Master: проверьте, правильно ли указан адрес spark://your-server-ip:7077 в ExecStart для worker; проверьте сетевую доступность и DNS.
- Port 8080 недоступен: проверьте iptables/ufw и настройки хоста.
- “Illegal reflective access” — предупреждение Java; обычно его можно игнорировать, но обновление JDK/Spark или явное включение флагов JVM уменьшит количество предупреждений.
Альтернативные подходы
- Использовать пакетные менеджеры/контейнеры: разворачивать Spark в Docker или Kubernetes (операторы Spark) для упрощённого масштабирования.
- Установить Spark из репозиториев менеджера конфигурации (Ansible/Chef/Puppet) для централизованного управления.
- Использовать сборки Spark с другой версией Hadoop (если интегрируете с существующим HDFS).
Безопасность и сетевые заметки
- На продакшене используйте отдельные сети для управления и для данных.
- Ограничьте доступ к веб‑интерфейсу Master (напр., через VPN или reverse proxy с аутентификацией).
- Для критичных развертываний рассмотрите настройку логирования и ротации логов.
Итог
Вы успешно установили и запустили Apache Spark на Ubuntu 22.04. Далее можно интегрировать Spark с HDFS, настроить ресурсный менеджер (YARN или Kubernetes), а также автоматизировать развёртывание с помощью конфигурационных инструментов.
Важно: всегда проверяйте совместимость версий Spark, Java и Hadoop перед развёртыванием в продакшен.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
