Установка Apache Spark на Ubuntu 20.04

Apache Spark — это открытая платформа для кластерных вычислений общего назначения. Она предоставляет высокоуровневые API на Java, Scala, Python и R, поддерживает потоковую обработку, SQL-запросы, машинное обучение и обработку графов. Spark способен распределять объёмы данных по узлам кластера и обрабатывать их параллельно.
Ниже приводится пошаговое руководство по установке Apache Spark на сервер с Ubuntu 20.04.
Требования
- Сервер с Ubuntu 20.04.
- Доступ root или пользователь с sudo-привилегиями.
Начало
Сначала обновите пакеты системы до последних версий:
apt-get update -yПосле обновления можно переходить к установке зависимостей.
Установка Java
Apache Spark написан на Java, поэтому необходимо установить JDK:
apt-get install default-jdk -yПроверьте установленную версию Java:
java --versionОжидаемый вывод (пример):
openjdk 11.0.8 2020-07-14
OpenJDK Runtime Environment (build 11.0.8+10-post-Ubuntu-0ubuntu120.04)
OpenJDK 64-Bit Server VM (build 11.0.8+10-post-Ubuntu-0ubuntu120.04, mixed mode, sharing)Важно: Spark 2.4.x корректно работает с Java 8–11, но некоторые предупреждения об отражённом доступе (reflective access) могут появляться при использовании Java 11. Это предупреждение не обязательно критично, но стоит учитывать при планировании обновлений Java.
Установка Scala
Spark разработан на Scala, поэтому установите Scala:
apt-get install scala -yПроверьте версию Scala:
scala -versionОжидаемый вывод (пример):
Scala code runner version 2.11.12 -- Copyright 2002-2017, LAMP/EPFLЧтобы войти в REPL Scala:
scalaПример приветственного сообщения:
Welcome to Scala 2.11.12 (OpenJDK 64-Bit Server VM, Java 11.0.8).
Type in expressions for evaluation. Or try :help.Пример теста внутри Scala REPL:
scala> println("Hitesh Jethva")Вывод:
Hitesh JethvaУстановка Apache Spark
Скачайте готовый бинарный пакет Spark. В этом руководстве используется Spark 2.4.6 (prebuilt для Hadoop 2.7). Скачайте в /opt:
cd /opt
wget https://archive.apache.org/dist/spark/spark-2.4.6/spark-2.4.6-bin-hadoop2.7.tgzРаспакуйте архив:
tar -xvzf spark-2.4.6-bin-hadoop2.7.tgzПереименуйте каталог для удобства:
mv spark-2.4.6-bin-hadoop2.7 sparkПримечание: при необходимости можно проверить контрольную сумму архива на официальном зеркале Apache.
Настройка окружения для Spark
Добавьте переменные окружения в ~/.bashrc, чтобы команды Spark были в PATH:
nano ~/.bashrcДобавьте в конец файла:
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbinСохраните изменения и активируйте их:
source ~/.bashrcАльтернативно можно настроить переменные в /etc/profile.d/spark.sh для глобального доступа.
Запуск Spark Master
После установки запустите мастер:
start-master.shОжидаемый вывод:
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-ubuntu2004.outПо умолчанию веб-интерфейс мастера доступен на порту 8080. Проверьте открытые порты:
ss -tpln | grep 8080Пример вывода:
LISTEN 0 1 *:8080 *:* users:(("java",pid=4930,fd=249)) Откройте в браузере http://your-server-ip:8080 и убедитесь, что веб-интерфейс доступен.
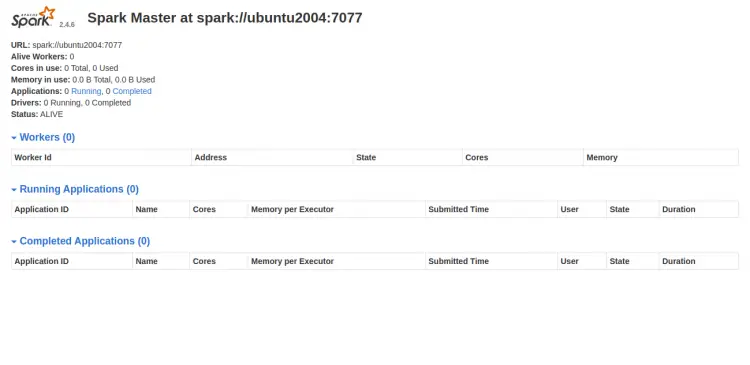
Запуск Spark Worker
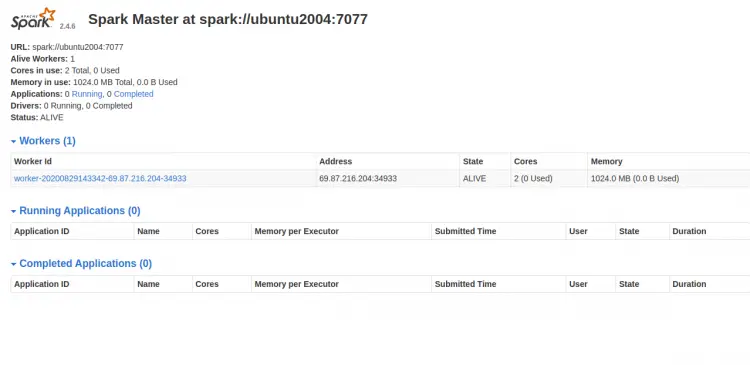
Адрес мастера будет вида spark://your-server-ip:7077. Запустите worker, указав этот адрес:
start-slave.sh spark://your-server-ip:7077Ожидаемый вывод при запуске worker:
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-ubuntu2004.outОбновите веб-интерфейс мастера — вы должны увидеть подключённый worker.
Работа со spark-shell и pyspark
Для запуска интерактивной Scala-сессии используйте:
spark-shellВ консоли вы увидите предупреждения и информацию о Spark context. Пример начала сессии:
Spark context Web UI available at http://ubuntu2004:4040
Spark context available as 'sc' (master = local[*], app id = local-1598711719335).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.6
/_/Если хотите использовать Python, запустите pyspark. Сначала установите Python (в примере использована версия 2):
apt-get install python -yЗатем:
pysparkВнимание: Spark 2.4.x часто поставляется с поддержкой Python 2 по умолчанию в старых сборках; на современных системах лучше использовать Python 3 и соответствующие сборки Spark.
Остановка сервисов
Чтобы остановить worker и мастер, выполните:
stop-slave.sh
stop-master.shКритерии приёмки
- Веб-интерфейс мастера доступен по http://your-server-ip:8080.
- При запуске start-slave worker появляется в списке мастера.
- spark-shell успешно запускается и предоставляет sc и spark.
- pyspark запускается для выбранной версии Python (проверить версию интерпретатора).
Частые ошибки и способы устранения
- Java not found или неправильная версия Java: убедитесь, что java –version показывает поддерживаемую версию (8–11 при использовании Spark 2.4.x).
- Порт 8080 занят: проверьте, какой процесс использует порт и при необходимости измените порт в конфигурации Spark.
- Предупреждения об illegal reflective access: это предупреждение связано с Java 9+ и не всегда критично, но в будущих версиях Java доступ может быть запрещён — планируйте обновление Spark/Java.
- Невозможность загрузки native-hadoop library: чаще всего информативно, Spark будет использовать встроенные Java-классы.
Важно: сохраняйте логи /opt/spark/logs при разборе проблем — там будет подробная информация о старте процессов.
Альтернативные подходы и масштабирование
- Docker: запуск Spark через официальные или кастомные Docker-образы удобен для изоляции и быстрого развертывания.
- Менеджеры кластеров: для продакшн-развёртываний рассмотрите YARN, Mesos или Kubernetes в качестве менеджеров ресурсов.
- Облачные сервисы: Amazon EMR, Google Dataproc и другие предлагают управляемые кластеры Spark и облегчают масштабирование.
Базовая методология развертывания
- Подготовьте ОС и сеть (firewall, доступ по SSH).
- Установите JDK и Scala.
- Скачайте и распакуйте Spark в фиксированную директорию (/opt/spark).
- Настройте SPARK_HOME и PATH.
- Запустите master, затем worker(ы).
- Протестируйте spark-shell и веб-интерфейс.
- Автоматизируйте запуск через systemd или Docker Compose для устойчивости.
Чек-лист по ролям
- Администратор:
- Установил JDK и Scala.
- Настроил сетевую доступность портов 7077 и 8080.
- Настроил systemd unit или Docker для автозапуска.
- Разработчик:
- Проверил spark-shell и pyspark.
- Запустил тестовое приложение и проверил веб-UI.
- Инженер данных:
- Настроил параметры памяти и CPU в spark-env.sh.
- Убедился, что данные и точки монтирования доступны всем узлам.
Краткий глоссарий
- Spark: платформа для распределённых вычислений.
- Master: управляющий узел кластера Spark.
- Worker: рабочий узел, выполняющий задачи.
- Driver: процесс приложения, управляющий выполнением задач.
- Executor: JVM-процесс, выполняющий задачи приложения на worker.
Безопасность и производительность
- Защитите веб-интерфейс мастера с помощью брандмауэра или прокси с аутентификацией.
- Настройте параметры памяти (spark.executor.memory, spark.driver.memory) в spark-defaults.conf или через конфигурацию приложения.
- Рассмотрите запуск Spark под выделенным системным пользователем и настройку прав доступа к каталогам в /opt/spark и логам.
Итог
Вы установили Apache Spark на Ubuntu 20.04, настроили окружение, запустили master и worker, протестировали spark-shell и pyspark. Для продакшна рекомендуем автоматизировать запуск, настраивать параметры памяти и контролировать доступ к веб-интерфейсу.
Если нужны systemd-юниты, примеры конфигураций spark-env.sh или подсказки по настройке памяти — сообщите, какая цель развертывания и сколько узлов планируется.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
