Установка Apache Spark на Debian 10

Введение
Apache Spark — свободный фреймворк для кластерных вычислений, применяемый для аналитики, машинного обучения и обработки графов на больших объёмах данных. Spark предоставляет более 80 высокоуровневых операторов для параллельной обработки и интерактивной работы из оболочек Scala, Python, R и SQL. Это быстрый in-memory движок для задач data science с поддержкой потоковой обработки, отказоустойчивости и расширенной аналитики.
Пререквизиты
- Сервер с Debian 10 и минимум 2 ГБ оперативной памяти.
- Настроен root-пароль или доступ через sudo от пользователя с правами администратора.
Важно: для рабочих кластеров в продакшн рекомендуется минимум 8–16 ГБ RAM на узел — для тестовой установки 2 ГБ достаточно начать.
Обновление системы
Перед установкой обновите пакеты:
apt-get update -y
apt-get upgrade -yПосле обновления рекомендуется перезагрузить сервер, чтобы применить обновления ядра и сервисов.
Установка Java
Spark реализован на Java/Scala, поэтому потребуется JDK. В репозитории Debian 10 доступен default-jdk:
apt-get install default-jdk -yПроверьте версию Java:
java --versionОжидаемый пример вывода (пример из источника):
openjdk 11.0.5 2019-10-15
OpenJDK Runtime Environment (build 11.0.5+10-post-Debian-1deb10u1)
OpenJDK 64-Bit Server VM (build 11.0.5+10-post-Debian-1deb10u1, mixed mode, sharing)Скачивание и установка Apache Spark
В каталоге /opt загрузите бинарный архив Spark. В исходном руководстве использовалась версия 3.0.0-preview2 с Hadoop 2.7:
cd /opt
wget http://apachemirror.wuchna.com/spark/spark-3.0.0-preview2/spark-3.0.0-preview2-bin-hadoop2.7.tgzРаспакуйте архив и переименуйте папку:
tar -xvzf spark-3.0.0-preview2-bin-hadoop2.7.tgz
mv spark-3.0.0-preview2-bin-hadoop2.7 sparkНастройка переменных окружения
Добавьте переменные в ~/.bashrc (или /etc/profile.d/spark.sh для глобальной настройки):
nano ~/.bashrcВ конец файла добавьте:
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbinАктивируйте изменения:
source ~/.bashrcПримечание: если вы разворачиваете кластер, лучше настроить эти переменные централизованно для всех пользователей, или использовать менеджер конфигурации (Ansible, Puppet).
Запуск Master
Запустите мастер-контроллер:
start-master.shОжидаемый вывод (пример):
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-debian10.outПо умолчанию Web UI мастера слушает порт 8080. Проверьте прослушиваемые порты:
netstat -ant | grep 8080Пример вывода:
tcp6 0 0 :::8080 :::* LISTENОткройте в браузере http://server-ip-address:8080 и найдите URL мастера (например, spark://debian10:7077):
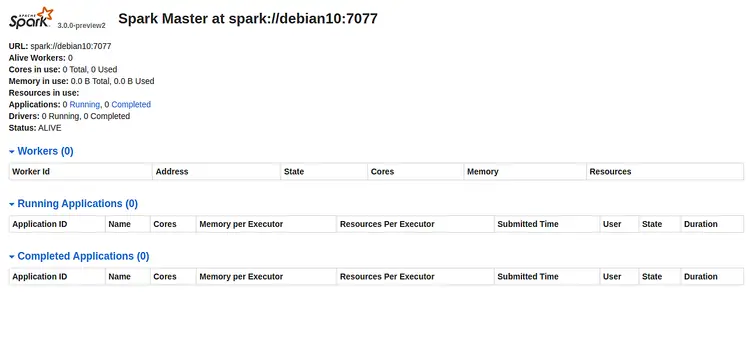
Запомните URL вида spark://
Запуск Spark Worker
Запустите воркер и укажите URL мастера:
start-slave.sh spark://debian10:7077Ожидаемый вывод:
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-debian10.outДоступ к Spark Shell
Интерактивная оболочка Spark Shell позволяет изучать API и выполнять быстрые проверки:
spark-shellПример вывода (сокращённо):
WARNING: An illegal reflective access operation has occurred
... (предупреждения JVM)
Spark context Web UI available at http://debian10:4040
Spark context available as 'sc' (master = local[*], app id = local-1577634806690).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
... version 3.0.0-preview2
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.5)
scala>Откройте http://debian10:4040 для просмотра UI приложения (локальный порт мониторинга).
Остановка Master и Worker
Чтобы остановить сервисы, выполните:
stop-slave.sh
stop-master.shОтладка и распространённые ошибки
- Если master не запускается, проверьте логи в /opt/spark/logs и права на файлы.
- Предупреждения об “illegal reflective access” связаны с библиотеками, использующими небезопасный доступ к JVM; в большинстве случаев это предупреждения, но их стоит отслеживать при обновлении JVM.
- Если worker не присоединяется к master, убедитесь, что указали корректный URL spark://host:7077 и что межсетевой экран (firewall) не блокирует порт 7077.
Важно: в продакшне не рекомендуется запускать Spark от root-пользователя. Создайте отдельного системного пользователя для Spark и запустите процессы под ним.
Альтернативные подходы
- Установка из пакетов/репозиториев: некоторые дистрибутивы или сторонние репозитории предлагают готовые пакеты spark, но они могут отставать по версии.
- Docker-контейнеры: удобны для изоляции и воспроизводимости; официальные и community-образы часто содержат готовую конфигурацию.
- Менеджеры ресурсов: для production часто используют YARN, Mesos или Kubernetes в качестве менеджера ресурсов вместо самостоятельного мастера Spark.
Мини-методология развертывания (шаги)
- Подготовка ОС: обновить пакеты, настроить SSH и время.
- Установка JDK и зависимостей.
- Загрузка и верификация бинарников Spark.
- Настройка переменных окружения и прав доступа.
- Запуск master и подключение worker(ов).
- Тестирование с помощью spark-shell и просмотра UI.
- Настройка логирования и мониторинга (Prometheus/Grafana при надобности).
Чек-листы по ролям
Администратор:
- Обновить пакеты и настроить пользователя spark.
- Открыть нужные порты: 8080 (master UI), 7077 (master RPC), 4040 (app UI, динамический).
Data Engineer:
- Проверить доступность Spark Shell и выполнение простых job.
- Настроить конфигурации spark-defaults.conf и spark-env.sh.
Разработчик:
- Подключиться к spark-shell, протестировать код локально.
- Убедиться в совместимости версий библиотек (Scala, Hadoop).
Оператор (SRE):
- Настроить ротацию логов и мониторинг.
- Планировать ресурсные лимиты и SLI/SLO для задач.
Часто используемые команды (cheat sheet)
- Обновление ОС: apt-get update && apt-get upgrade
- Установка JDK: apt-get install default-jdk -y
- Запуск master: start-master.sh
- Запуск worker: start-slave.sh spark://
:7077 - Остановка: stop-slave.sh && stop-master.sh
- Spark Shell: spark-shell
Совместимость и миграция
Файл, который вы скачиваете, содержит в имени информацию о целевой версии Hadoop (например, hadoop2.7). Подбирайте сборку Spark, совместимую с вашей версией Hadoop/экосистемы. Версия из исходного руководства — preview (предрелизная), поэтому для продакшна лучше использовать стабильный релиз Spark.
Безопасность и сетевые рекомендации
- Запускайте Spark-процессы под непривилегированным пользователем.
- Ограничьте доступ к UI и RPC портам через брандмауэр или VPN.
- Используйте TLS и аутентификацию для межузлового взаимодействия в продуктивных кластерах.
Короткий глоссарий
- Master — координатор кластера Spark.
- Worker (slave) — узел, который выполняет задачи (executor).
- spark-shell — интерактивная оболочка на базе Scala.
- SPARK_HOME — корневая папка установки Spark.
Критерии приёмки
- Master и хотя бы один worker успешно зарегистрированы и видны в Web UI.
- spark-shell запускается и выполняет простую задачу (напр., подсчёт слов).
- Логи не содержат критических ошибок и процессы запущены под непривилегированным пользователем.
Итог
Вы установили Apache Spark на Debian 10: обновили систему, поставили Java, загрузили и настроили Spark, запустили мастер и воркера, а также получили доступ к spark-shell и Web UI. Для продакшн-развёртывания дополнительно настройте безопасность, мониторинг и автоматизированное развертывание.
Короткие рекомендации для продолжения: протестируйте работу с небольшими джобами в spark-shell, настройте конфигурации в $SPARK_HOME/conf и рассмотрите использование Docker или систем управления кластерами для упрощения эксплуатации.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
