Совпадения через несколько строк: grep, pcre2grep и альтернативы
Быстрая навигация
- Совпадения через несколько строк с grep
- Использование pcre2grep (Perl-совместимый grep)
- Быстрый чек-лист и руководство по выбору инструмента
Зачем это нужно
Иногда в логах, конфигурациях или текстовых данных нужно найти фрагмент, который начинается в одной строке и заканчивается в другой. Обычный grep по умолчанию ищет совпадения в рамках одной строки, поэтому для многолинейных совпадений нужны приёмы или другие инструменты.
Важно: термин «мультилайн» здесь — это совпадение, которое охватывает хотя бы одну переведённую строку (\n).
Совпадения через несколько строк с awk и sed
awk и sed обрабатывают поток как набор записей и естественно могут работать с несколькими строками. Простейший подход — задать диапазон между двумя шаблонами.
Пример с awk:
awk '/from/,/to/' fileПример с sed:
sed -n '/from/,/to/p' fileЭти команды выведут все строки начиная с той, где найдено “from”, и до строки с “to” включительно. Подходит, когда нужно захватить блоки по границам.
Почему grep затрудняется и как его заставить работать
grep изначально ориентирован на поиск внутри строки. Всё же возможно собрать мультилайн-совпадение с помощью сочетания флагов и PCRE:
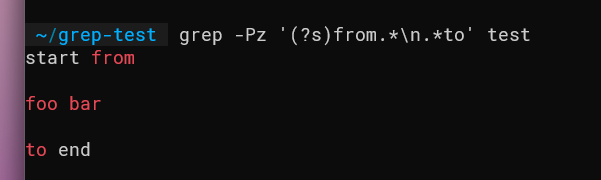
grep -Pz '(?s)from.*\n.*to' test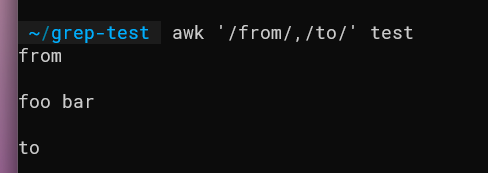
Что делает каждая часть:
- -P — включает Perl-совместимые регулярные выражения (PCRE).
- -z — заставляет grep читать файл как один большой поток, где разделителем считается нулевой байт вместо новой строки. В результате grep «видит» весь файл как одну строку.
- (?s) — включение флага PCRE_DOTALL, чтобы точка совпадала и с символом новой строки.
- from и to — начальный и конечный шаблоны.
Замечания и подводные камни:
- Использование -z и -o (печать только совпадений) может привести к появлению завершающего нулевого байта в выводе, что усложнит последующую обработку. Лучше пост-обработать вывод tr -d ‘\0’ или использовать другие инструменты.
- grep -Pz становится тяжёлым для чтения при сложных шаблонах. Поддержка PCRE у grep различается по платформам.
Использование pcre2grep (Perl-Compatible grep)
pcre2grep — специализированный инструмент с поддержкой PCRE2 и встроенной опцией для мультилайн. Обычно пакеты называются pcre2-utils или схожим образом.
Установка (Debian/Ubuntu):
sudo apt install pcre2-utilsБазовый пример:
pcre2grep -M 'from(\n|.)*to' fileОпция -M включает мультистрочный режим, позволяющий шаблону охватывать переводы строки. Альтернативно можно включить DOTALL:
pcre2grep -M '(?s)from.*to' fileПримеры использования и преимущества:
- Короче и выразительнее, чем grep -Pz.
- PCRE2 поддерживает расширенные конструкции и флаги.
- Лучше подходит для сложных регулярных выражений, где нужно учитывать границы или ленивые квантификаторы.
Недостатки:
- В некоторых системах pcre2grep может отсутствовать по умолчанию.
- Для очень больших файлов режим -M может потребовать больше памяти.
Как выбрать инструмент — методология
- Небольшие блоки по границам (start/end): используйте sed или awk.
- Сложные шаблоны с группами, lookaround: используйте pcre2grep.
- Скрипты/однострочные команды без дополнительных утилит: grep -Pz с осторожностью.
- Очень большие файлы → предпочтение потоковым инструментам (awk/sed) или разбивка файла на части.
Критерии приёмки
- Команда должна корректно находить блоки, начинающиеся с «from» и заканчивающиеся «to», даже если между ними есть переводы строк.
- Вывод не должен содержать лишних нулевых байтов или управляющих символов (после пост-обработки).
- Память и время выполнения должны оставаться приемлемыми для целевого объёма данных.
Чек-лист по ролям
Разработчик:
- Проверить шаблон на тестовых файлах с разными переводами строки.
- Отладить с опцией вывода совпадений (-o / pcre2grep -o) и пост-обработкой.
Системный администратор:
- Оценить размер файлов и нагрузку перед массовым запуском pcre2grep -M.
- Предпочесть sed/awk для потоковой обработки больших логов.
Оператор скриптов/CI:
- Стабильно проигнорировать завершающие нулевые байты (tr -d ‘\0’) при использовании grep -z.
- Добавить тесты на регрессию для разных платформ.
Справочный набор команд (cheat sheet)
- Захват блока между шаблонами, простое решение:
awk '/from/,/to/' file- sed, печать только найденных диапазонов:
sed -n '/from/,/to/p' file- grep с PCRE и чтением как один поток (громоздко):
grep -Pz '(?s)from.*\n.*to' test- pcre2grep, мультилайн удобнее:
pcre2grep -M '(?s)from.*to' fileКогда такие приёмы не подходят (контрпримеры)
- Если файл бинарный или содержит много нулевых байтов, -z может нарушить корректность анализа.
- Очень большие файлы: pcre2grep -M может потребовать большого объёма памяти; лучше потоковая обработка.
- Если границы совпадений не выражены явно («from»/«to» нет), диапазон по паттернам не сработает — нужно использовать контекстную логику или парсер.
Краткий глоссарий
- PCRE / PCRE2 — Perl-совместимые регулярные выражения (двух поколений); PCRE2 — более новая и предпочтительная библиотека.
- DOTALL — режим, при котором “.” совпадает и с переводом строки.
- -z (grep) — читать ввод как одну строку, где разделителем служит нулевой байт.
Рекомендации по безопасности и производительности
- Не применяйте сложные жадные квантификаторы без необходимости — они могут вызвать трэповку производительности (catastrophic backtracking).
- Тестируйте выражения на реальных данных и контролируйте использование памяти.
Итог
Для большинства задач мультилайн-совпадений проще и надёжнее использовать awk или sed. Если нужны мощные PCRE-конструкции — установите pcre2grep и применяйте -M или (?s). Использование grep -Pz возможно, но менее удобно и порождает нюансы вывода.
Важно: выберите инструмент, исходя из объёма данных, требуемой функциональности регулярных выражений и ограничений среды выполнения.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
