Как извлечь все ссылки с веб‑страницы с помощью PowerShell
Важно: соблюдайте правила сайта (robots.txt) и не перегружайте сервер частыми запросами.
Быстрые ссылки
- Скрейпинг веба с PowerShell
Скрейпинг веба с PowerShell
Короткие определения:
- Invoke‑WebRequest — cmdlet для получения и парсинга HTML‑страниц.
- Invoke‑RestMethod — cmdlet для получения и парсинга JSON/XML API.
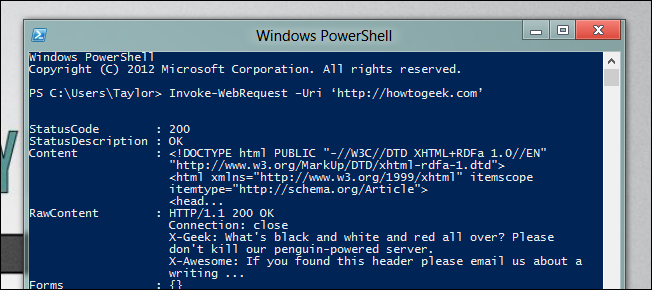
PowerShell 3 добавил удобные средства для автоматизации веб‑задач. Поскольку ссылки находятся в HTML, мы используем Invoke‑WebRequest. Простейшая команда для получения ответа от сайта выглядит так:
Invoke-WebRequest –Uri ‘http://howtogeek.com’
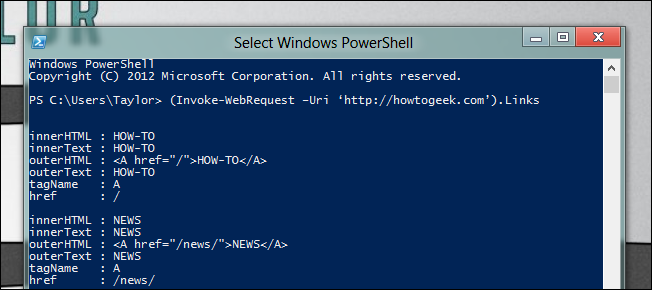
В результате вы получите объект ответа, у которого есть свойство Links — коллекция всех найденных ссылок (элементов a).
(Invoke-WebRequest –Uri ‘http://howtogeek.com’).Links
Эта коллекция содержит множество элементов. Используйте фильтры и перечисление членов для выбора нужных ссылок. Пример: получить все заголовки статей на главной странице:
((Invoke-WebRequest –Uri ‘http://howtogeek.com’).Links | Where-Object {$.href -like ‘http*’} | Where-Object {$.class -eq ‘title’}).Title
Пояснение шагов:
- Invoke‑WebRequest загружает HTML и парсит DOM.
- Свойство Links — уже разобранная коллекция тегов.
- Where‑Object позволяет фильтровать по href, class, innerHTML и другим свойствам.

Пример: автоматическая загрузка изображения дня с National Geographic
Ниже пример, где мы находим ссылку «Download Wallpaper» и скачиваем файл через Start‑BitsTransfer. Обратите внимание на корректный синтаксис PowerShell:
$IOTD = ((Invoke-WebRequest -Uri ‘http://photography.nationalgeographic.com/photography/photo-of-the-day/‘).Links | Where-Object {$_.innerHTML -like ‘Download Wallpaper‘}).href
Start-BitsTransfer -Source $IOTD -Destination C:\IOTD\
Этот фрагмент:
- ищет среди ссылок ту, где innerHTML содержит “Download Wallpaper”;
- получает атрибут href;
- скачивает файл в папку C:\IOTD\ через BITS.
Полезные приёмы и рекомендации
- Фильтрация по шаблонам: используйте -like и регулярные выражения (-match) для надежного отбора.
- Приведение относительных URL: если href начинается с “/“, дополняйте базовым URI (Uri.TryCreate или [System.Uri] для объединения).
- Параллельные загрузки: Start‑BitsTransfer поддерживает асинхронные операции; для массовых загрузок используйте лимит параллелизма.
- Заголовки и куки: передавайте заголовки (Headers) или куки (Session) при необходимости для авторизованных страниц.
Когда такой подход не сработает
- Контент формируется динамически JavaScript (SPA, AJAX) — Invoke‑WebRequest возвращает исходный HTML без отрисованного DOM.
- Сайты с защитой от ботов (CAPTCHA, hCaptcha, Cloudflare) блокируют запросы.
- Сложные клиентские взаимодействия (клики, ленивые загрузки) требуют браузерной автоматизации.
Альтернативные подходы
- Selenium / Playwright — полноценная автоматизация браузера, подходит для JS‑генерируемого контента.
- Headless браузеры (Chrome headless) — выполнить JavaScript и получить итоговый DOM.
- curl/wget — для простых скачиваний и тестов; не умеют парсить DOM.
- API сайта — предпочтительный вариант, если доступен официально.
Чек‑лист перед автоматизацией
- Проверить robots.txt и правила сайта.
- Оценить нагрузку и установить задержки между запросами.
- Логировать ошибки и статус загрузки.
- Обрабатывать относительные URL и ошибки 4xx/5xx.
- Обеспечить корректную обработку кодировок (UTF‑8/Windows‑1251).
Отладка: типичные ошибки и решения
- Пустой .Links — возможно, страница требует JS. Попробуйте Selenium.
- Значения href как “#” или пустые — фильтровать условием Where-Object {$.href -and $.href -ne ‘#’}.
- Ошибки сертификата — при необходимости укажите -SkipCertificateCheck для тестов (не рекомендуется в продакшене).
Критерии приёмки
- Скрипт корректно получает список ссылок с целевой страницы.
- Все целевые URL нормализованы (полные URL).
- Нет падений при 4xx/5xx; логируются ошибки и повторные попытки для временных сбоев.
- Размер и частота запросов не нарушают правила сайта.
Короткая методика (mini‑methodology)
- Оцените, доступен ли контент в исходном HTML.
- Напишите простой Invoke‑WebRequest и проверьте .Links.
- Отфильтруйте ссылки по href/class/innerHTML.
- Нормализуйте URL и скачайте ресурсы через Start‑BitsTransfer или Invoke‑WebRequest -OutFile.
- Добавьте логирование и обработку ошибок.
1‑строчный глоссарий
- DOM — структура документа HTML; Invoke‑WebRequest пытается распарсить её на сервере.
- BITS — Background Intelligent Transfer Service, удобен для надежных скачиваний.
Этические и юридические примечания
Важно: автоматизация должна уважать права владельцев контента и условия использования сайта. Если необходим доступ к большому объему данных, предпочтйтно запросить API или разрешение.
Итог
PowerShell делает базовый веб‑скрейпинг простым: Invoke‑WebRequest предоставляет разобранный DOM и коллекцию ссылок, которые можно фильтровать и обрабатывать стандартными средствами PowerShell. Для динамического контента используйте браузерную автоматизацию или официальные API.
Короткий список действий для начала:
- Попробуйте Invoke‑WebRequest и просмотрите .Links;
- Используйте Where‑Object для отбора по href/class/innerHTML;
- Для скачивания применяйте Start‑BitsTransfer или Invoke‑WebRequest -OutFile;
- При необходимости переходите на Selenium/Playwright для JS‑генерируемых страниц.
Задавайте вопросы или делитесь собственными трюками в комментариях.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
