Извлечение текста из изображений на Linux с помощью Tesseract OCR
Tesseract — бесплатный OCR-движок для Linux, который позволяет извлекать редактируемый текст из изображений и страниц PDF. В статье показаны установка, базовые команды, работа с языками и PDF, советы по предобработке изображений и готовые сценарии для пакетной обработки.
Быстрые ссылки
- Оптическое распознавание текста
- Установка Tesseract OCR
- Использование Tesseract OCR
- Работа с разными языками
- Работа с PDF
- Практические советы и проверки
Что такое OCR
Optical Character Recognition (OCR) — это технология, которая находит и преобразует текст на изображениях в редактируемый текст. Коротко: OCR считывает символы как текстовые данные. Для людей это простая задача. Для компьютеров — сложная: меняются шрифты, размеры и качество изображения.
Важно: OCR даёт лучший результат на качественных, чётких изображениях. Если исходное изображение размытое или имеет артефакты, потребуется предобработка.
Краткая история Tesseract
Tesseract появился в 1980‑х как коммерческое решение Hewlett Packard. В 2005 году проект был открыт с исходным кодом, а позднее получил поддержку от Google. Сегодня Tesseract — один из самых популярных и широко используемых OCR‑движков с поддержкой около 100 языков.
Установка Tesseract OCR
Примеры для популярных дистрибутивов Linux.
Ubuntu / Debian:
sudo apt-get install tesseract-ocrFedora:
sudo dnf install tesseractManjaro / Arch:
sudo pacman -Syu tesseractПримечание: в некоторых дистрибутивах пакет называется просто tesseract, в других — tesseract-ocr. Если нужна GUI‑оболочка или дополнительные инструменты (ocrmypdf, tessdata), установите их отдельно.
Базовое использование Tesseract
Tesseract — командная утилита. Общая форма команды:
tesseract <входной-файл> <имя-выходного-файла> [опции]Параметры, которые часто используются:
- имя входного файла с изображением (png, jpg и т. д.)
- имя выходного файла без расширения (создаст .txt)
- –dpi N — явно указать разрешение изображения в dpi
- -l <аббревиатура> — выбрать язык (например, eng, rus, fre)
Пример: у нас есть файл recital-63.png с разрешением 150 dpi. Создадим файл recital.txt:
tesseract recital-63.png recital --dpi 150Пример: распознавание непростой страницы

Эта страница сложна: предложения начинаются с бледных надстрочных цифр. Tesseract хорошо извлёк основной текст, но надстрочные символы были неверно интерпретированы как кавычки или символы степени. Качество исходника критично.

Работа с различными размерами шрифта и стилями

Файл bold-italic.png распознался корректно:
tesseract bold-italic.png bold --dpi 150
Работа с несколькими языками
Tesseract поддерживает множество языков. Сначала установите нужный языковой пакет. В Ubuntu пакеты имеют формат tesseract-ocr-
Пример: валлийский (Cymraeg), код cym:
sudo apt-get install tesseract-ocr-cymДля распознавания укажите параметр -l:
tesseract hen-wlad-fy-nhadau.png anthem -l cym --dpi 150Если документ двуязычный, перечислите языки через +:
tesseract image.png textfile -l eng+cym+fraПримечание: комбинирование языков увеличивает объём данных и может повысить число ошибочных сопоставлений, если языки имеют сильно пересекающиеся словари.

Распознавание текста из PDF
Tesseract работает с изображениями. Для PDF сначала переведите каждую страницу в изображение. Утилита pdftoppm (часть пакета poppler) создаёт отдельный PNG для каждой страницы.
pdftoppm -png turing.pdf turingПосле этого вы получите turing-01.png, turing-02.png и т. д. Для пакетного запуска используйте цикл:
for i in turing-??.png; do tesseract "$i" "text-$i" -l eng; done;Объединение результатов:
cat text-turing* > complete.txt
На практике Tesseract хорошо справился с основной текстовой частью, но потерял форматирование, пропустил одиночные буквы «Q»/«A» в списках, и некоторая мелкая печать или вертикальные штампы стали «шумом».
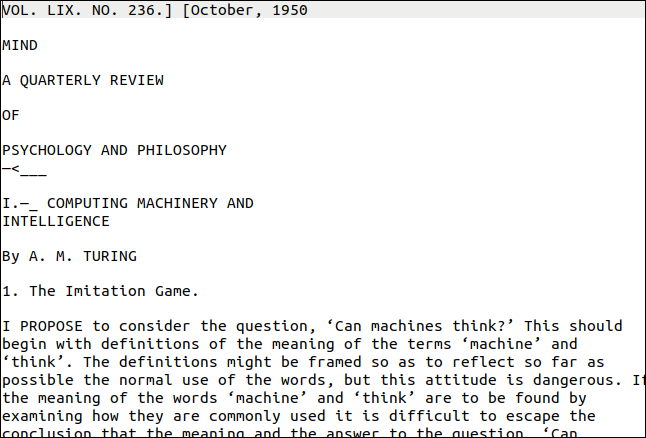


Диаграммы и таблицы обычно теряют формат. Tesseract извлекает символы, но не умеет восстанавливать макет и взаимное расположение элементов.


Предобработка изображений для лучшего результата
Качество распознавания напрямую зависит от качества изображения. Рекомендуемые шаги:
- Обрезка полей и удаление водяных знаков, если это возможно без потери данных.
- Увеличение разрешения (например, до 300 dpi) при помощи масштабирования перед распознаванием.
- Приведение к градациям серого и улучшение контрастности.
- Бинаризация (порог) для сканов текстовых документов.
- Устранение наклона страницы (deskew).
- Удаление шума и мелких точек.
Примеры инструментов предобработки: ImageMagick, Pillow, OpenCV.
Команда ImageMagick для повышения контраста и увеличения dpi:
convert input.png -resize 200% -density 300 -colorspace Gray -contrast-stretch 0.5% preprocessed.pngЗатем запускаете tesseract на preprocessed.png.
Постобработка: очистка и выравнивание текста
После OCR обычно нужен ручной или автоматизированный цикл очистки:
- Используйте spellcheck (aspell, hunspell) для исправления опечаток.
- Регулярные выражения для коррекции типичных ошибок (например, кавычки, надстрочные номера).
- Нормализация пробелов и переносов строк.
- Если важна разметка, сохраните исходный PDF и вручную восстановите форматирование.
Пример простого скрипта для исправления надстрочных символов:
# Пример POS‑обработки (bash + sed)
sed -e 's/["°]/ /g' complete.txt > cleaned.txtКогда Tesseract даёт плохой результат
Тессеракт может ошибаться, если:
- Исходник низкого качества: размытие, пикселизация, низкое разрешение.
- Шрифт художественный или рукописный — Tesseract ориентирован на печатный текст.
- Присутствуют графики, таблицы или сложное форматирование.
- Язык не установлен или выбран неверно.
В таких случаях рассмотрите альтернативы: коммерческие OCR‑сервисы (Google Cloud Vision, AWS Textract, ABBYY) или гибридные рабочие процессы с ручной верификацией.
Альтернативные подходы и инструменты
- ocrmypdf — удобный инструмент для создания поисковых PDF: добавляет слой текста поверх изображений и умеет пакетно обрабатывать документы.
- OCRmyPDF + Tesseract — хорошо подходит для автоматизации пайплайнов.
- Cloud OCR (Google Vision, Azure, AWS) — часто лучше работают с плохими сканами и рукописью, но платные.
- Коммерческие решения (ABBYY FineReader) — сильны в точности и восстановлении разметки.
Пошаговая методика для пакетной обработки PDF большого объёма
- Создайте рабочую папку и положите туда все PDF.
- Для каждого PDF используйте pdftoppm, чтобы создать PNG‑страницы.
- Предобработайте изображения (масштабирование, повышение контраста, исправление наклона).
- Запустите tesseract в цикле, сохраняя результаты в отдельные .txt.
- Соберите все .txt в единый файл и прогоните через spellcheck.
- Сравните полученный текст с контрольным образцом (если есть) и выполните ручную проверку по выборке.
Пример скрипта (bash):
for pdf in *.pdf; do
base="${pdf%.pdf}"
pdftoppm -png "$pdf" "$base"
for img in ${base}-*.png; do
convert "$img" -resize 200% -density 300 tmp-"$img"
tesseract tmp-"$img" "out-${img%.*}" -l eng
done
cat out-${base}-*.txt > "${base}.txt"
rm tmp-${base}-*.png
doneРолевые чек‑листы
Для разработчика:
- Проверить наличие tessdata и нужных языков.
- Создать тестовый набор изображений разных типов.
- Автоматизировать предобработку.
- Настроить логирование ошибок распознавания.
Для сисадмина:
- Установить зависимости (poppler, ImageMagick).
- Настроить пакетную обработку и расписание задач.
- Мониторить место на диске и использование CPU.
Для контент‑редактора:
- Оценить качество сканов.
- Подготовить инструкции по проверке текста.
- Установить критерии приёмки (см. ниже).
Критерии приёмки
- Основной текст распознан с точностью визуально не менее приемлемой для чтения.
- Ключевые термины и имена сохранены без ошибок.
- Входные и выходные файлы корректно сопоставляются и хранятся.
- Для юридических документов установлена ручная проверка после OCR.
Тонкости и ограничения
- Tesseract не восстанавливает макет, таблицы и сложные диаграммы. Для таблиц лучше использовать специализированные конвертеры или ручную разметку.
- Для рукописного текста результат обычно ненадёжен.
- OCR автоматически не учитывает контекст правовых терминов; для критичных документов нужна экспертиза.
Советы по повышению точности
- Работайте с разрешением не менее 300 dpi для типографских текстов.
- Приводите изображения к оттенкам серого и повышайте контраст.
- Избегайте многоцветных фонов и тиснения.
- Устанавливайте правильный язык через -l.
- По возможности указывайте –psm (Page Segmentation Mode) для предсказания структуры страницы.
Пример использования psm:
tesseract page.png out -l eng --psm 1Список важных режимов psm: 3 (полная страница), 6 (один блок текста), 11 (одно слово), 13 (single raw line).
Конфигурационные настройки и пользовательские словари
Tesseract позволяет подключать пользовательские словари и изменять конфигурацию через параметр –user-words и –user-patterns. Это полезно, если текст содержит специфические термины или имена.
tesseract img.png out -l eng --user-words words.txtБезопасность и приватность
Если документы contain персональные данные (например, GDPR в примерах), учитывайте требования конфиденциальности. Работайте локально, если данные чувствительны, или используйте сертифицированные облачные сервисы с соглашением об обработке данных. Для юридических документов рекомендуется ручная верификация и контроль доступа к результатам распознавания.
Тесты и приёмочные критерии
Минимальные тесты:
- Распознать страницу с печатным текстом A4 300 dpi и получить корректный текст без потерь слов.
- Распознать страницу со смешанными языками, указав оба языка, и оценить число ошибок.
- Обработать PDF на 10 страниц и собрать единый текстовый файл.
Критерии успеха: читаемость > визуально приемлема, ключевые термины сохранены.
Примеры типичных ошибок и как их исправлять
- Ошибочные кавычки / знаки степени вместо надстрочных цифр — обрабатывать sed/regex.
- Мелкие символы и сноски — увеличить dpi и повторить распознавание.
- Пропуски букв в начале строк (Q/A) — возможно, Tesseract проигнорировал одиночные символы; можно восстановить по образцу с помощью регулярных выражений.
Короткий чеклист для запуска OCR
- Установите tesseract и языковые пакеты.
- Подготовьте изображения (300 dpi, серый, контраст).
- Запустите tesseract с нужными опциями: -l, –dpi, –psm.
- Выполните автоматическую очистку и spellcheck.
- Выполните выборочную ручную проверку.
Короткое объявление для команды (для рассылки)
Tesseract OCR теперь доступен на сервере обработки документов. Используйте его для создания редактируемого текста из PDF и сканов. Для массовой обработки применяйте предварительную обработку и проверку качества по описанным в инструкции шагам.
Заключение
Tesseract — мощный бесплатный инструмент для извлечения текста из изображений и PDF. Он не идеален: теряет форматирование, может ошибаться с мелкими символами и рисунками. Но при правильной предобработке и постобработке он даёт высокую практическую пользу и подходит для большинства задач автоматизации.
Важное примечание:
- Для критичных юридических или финансовых документов всегда планируйте ручную проверку после OCR.
Дополнительные ресурсы
- Официальная документация Tesseract: https://github.com/tesseract-ocr/tesseract
- ocrmypdf: https://github.com/ocrmypdf/ocrmypdf
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
