Распознавание номерных знаков автомобиля на Python
{kind=link}
Распознавание и детекция номерных знаков применяется в дорожных системах, безбилетных парковках, контроле доступа на территорию и в других задачах. Эта технология сочетает методы компьютерного зрения и систем оптического распознавания символов (OCR). В примере ниже мы используем Python, OpenCV и Tesseract (через pytesseract) для обнаружения области номерного знака на изображении и последующего извлечения текста.
Важно: распознавание номерных знаков часто связано с персональными данными — в разделе “Конфиденциальность и права” приведены практические рекомендации.
Содержание
- Краткий обзор (TL;DR)
- Установка и подготовка окружения
- Поэтапный разбор кода
- Импорт библиотек
- Загрузка изображения и указание пути к Tesseract
- Предобработка изображения
- Детекция контуров и выделение номера
- Распознавание символов
- Вывод результата
- Практические советы по улучшению распознавания
- Альтернативные подходы (нейросети, EasyOCR, YOLO)
- Отладка: частые ошибки и их решения
- Критерии приёмки и тест-кейсы
- Чек-лист для развёртывания
- Конфиденциальность и безопасность
- Итог
Установка и подготовка окружения
Перед началом убедитесь, что у вас установлен Python и pip. Мы будем использовать три ключевые библиотеки:
- OpenCV (cv2) — для работы с изображениями и визуализации.
- imutils — вспомогательные функции, например для изменения размера.
- pytesseract — Python-обёртка над движком Tesseract OCR.
Установка (в терминале):
pip install opencv-python
pip install imutils
pip install pytesseractПримечание: pytesseract — это обёртка: сам движок Tesseract нужно установить отдельно (ниже — инструкции для Windows и Linux).
Установка Tesseract OCR
Коротко: Tesseract — это движок OCR с открытым исходным кодом. Чтобы pytesseract мог распознавать текст, необходимо установить сам Tesseract.
Windows:
- Откройте браузер и скачайте установщик Tesseract (например с официального репозитория или зеркал).
- Запустите установку и запомните путь установки (обычно: C:\Program Files\Tesseract-OCR\tesseract.exe).
Linux (Ubuntu/Debian):
sudo apt update
sudo apt install tesseract-ocrMac (Homebrew):
brew install tesseractПосле установки укажите путь к исполняемому файлу Tesseract в вашем скрипте (Windows):
# укажите фактический путь установки Tesseract в вашей системе
pytesseract.pytesseract.tesseract_cmd = 'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'Если вы не указали путь (и Tesseract доступен в PATH), pytesseract может работать без явной установки пути.
1. Импорт библиотек
Начинаем с импорта необходимых библиотек:
import cv2
import imutils
import pytesseractОпределение библиотек позволяет использовать их функции далее.
2. Загрузка изображения и настройка Tesseract
Укажите путь к Tesseract (если нужно) и загрузите изображение. Рекомендуется хранить тестовые изображения в той же папке проекта.
pytesseract.pytesseract.tesseract_cmd = 'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'
original_image = cv2.imread('image3.jpeg')Замените ‘image3.jpeg’ на имя вашего файла.
3. Предобработка изображения
Качество предобработки сильно влияет на результат OCR. Основные шаги:
- Изменить масштаб изображения (чёткий фиксированный размер по ширине упрощает пороги и контуры).
- Перевести в оттенки серого — многие алгоритмы работают с градациями.
- Применить фильтрацию для снижения шума (напр., bilateralFilter), который сохраняет границы.
Пример кода:
original_image = imutils.resize(original_image, width=500 )
gray_image = cv2.cvtColor(original_image, cv2.COLOR_BGR2GRAY)
gray_image = cv2.bilateralFilter(gray_image, 11, 17, 17)Пояснение: bilateralFilter уменьшает шум, сохраняя резкие границы — это полезно перед детекцией краёв.
4. Детекция номерного знака
Детекция — это поиск области на изображении, где находится номерной знак.
Выполнение детекции краёв
Используем Canny для выделения краёв:
edged_image = cv2.Canny(gray_image, 30, 200)Поиск контуров
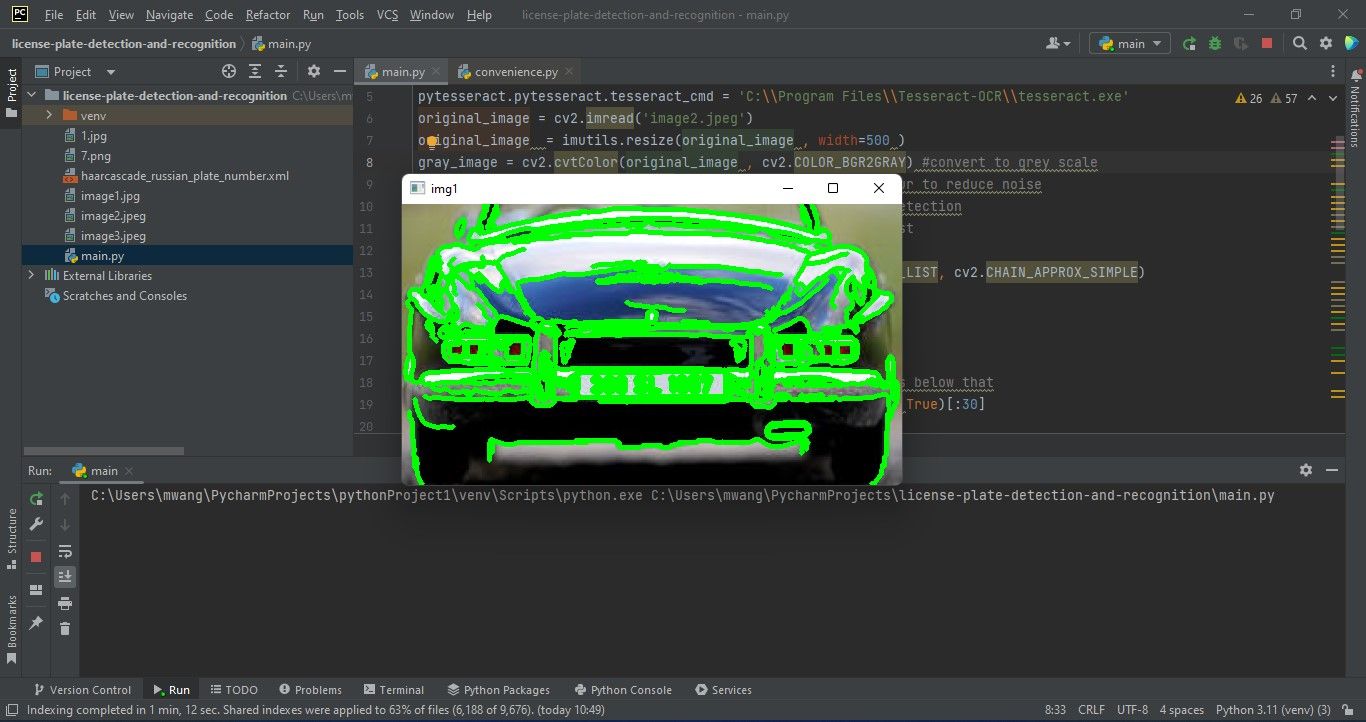
На основе карты краёв находим контуры и визуализируем их для отладки:
contours, new = cv2.findContours(edged_image.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
img1 = original_image.copy()
cv2.drawContours(img1, contours, -1, (0, 255, 0), 3)
cv2.imshow("img1", img1)Теперь сортируем контуры и выбираем наиболее перспективные (по площади).
Сортировка контуров
Оставляем, например, топ-30 по площади — в них с высокой вероятностью будет номерной знак:
contours = sorted(contours, key = cv2.contourArea, reverse = True)[:30]
# stores the license plate contour
screenCnt = None
img2 = original_image.copy()
# draws top 30 contours
cv2.drawContours(img2, contours, -1, (0, 255, 0), 3)
cv2.imshow("img2", img2)Поиск четырёхугольного контура (номерного знака)
Перебираем отобранные контуры и ищем аппроксимации с четырьмя вершинами — вероятная пластина:
count = 0
idx = 7
for c in contours:
# approximate the license plate contour
contour_perimeter = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.018 * contour_perimeter, True)
# Look for contours with 4 corners
if len(approx) == 4:
screenCnt = approx
# find the coordinates of the license plate contour
x, y, w, h = cv2.boundingRect(c)
new_img = original_image [ y: y + h, x: x + w]
# stores the new image
cv2.imwrite('./'+str(idx)+'.png',new_img)
idx += 1
break
# draws the license plate contour on original image
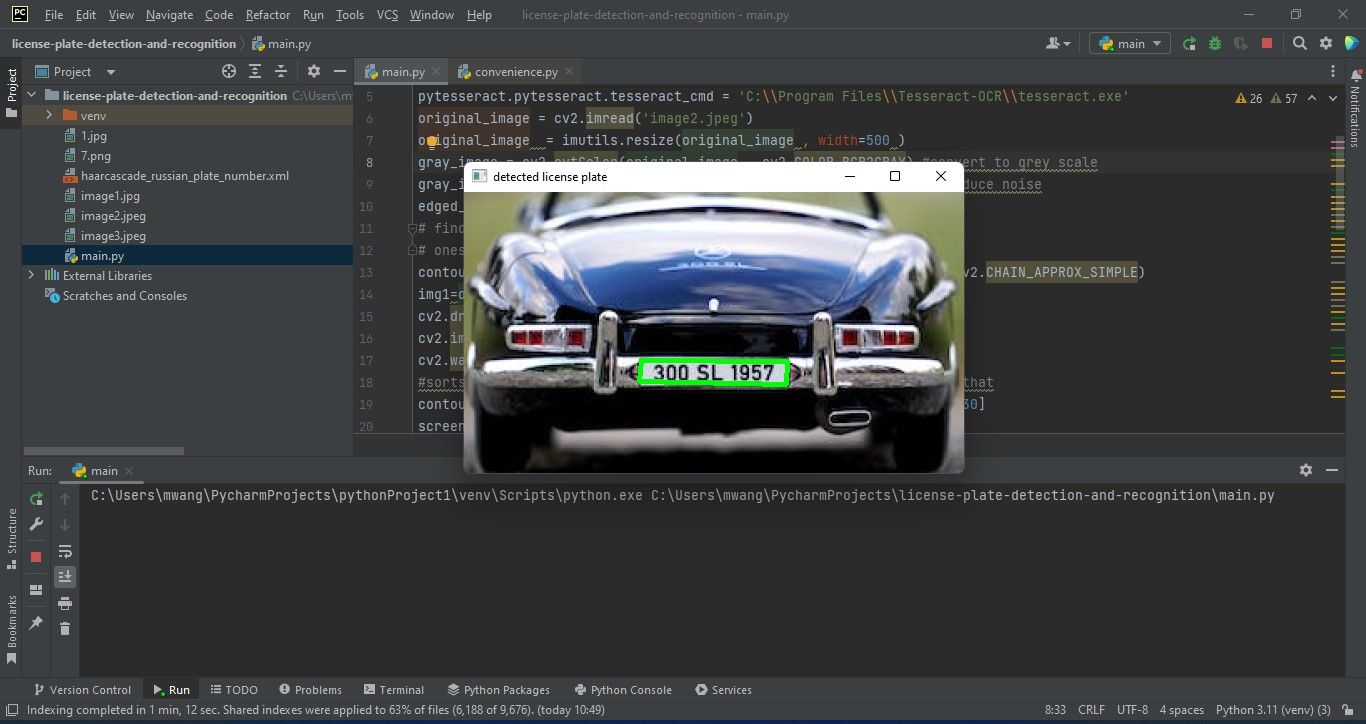
cv2.drawContours(original_image , [screenCnt], -1, (0, 255, 0), 3)
cv2.imshow("detected license plate", original_image )Результат: контур, обрамляющий предполагаемый номерной знак, выделяется на исходном изображении.
5. Распознавание символов на выделенной пластине
Теперь, когда пластина вырезана и сохранена в файл (например, ‘./7.png’), используем pytesseract для извлечения текста:
# filename of the cropped license plate image
cropped_License_Plate = './7.png'
cv2.imshow("cropped license plate", cv2.imread(cropped_License_Plate))
# converts the license plate characters to string
text = pytesseract.image_to_string(cropped_License_Plate, lang='eng')Замечания:
- lang=’eng’ — указывает языковой набор символов. Для локальных номеров может потребоваться другой язык или кастомный тренерованный набор.
- Часто полезно применить бинаризацию и морфологию к обрезанному изображению перед OCR.
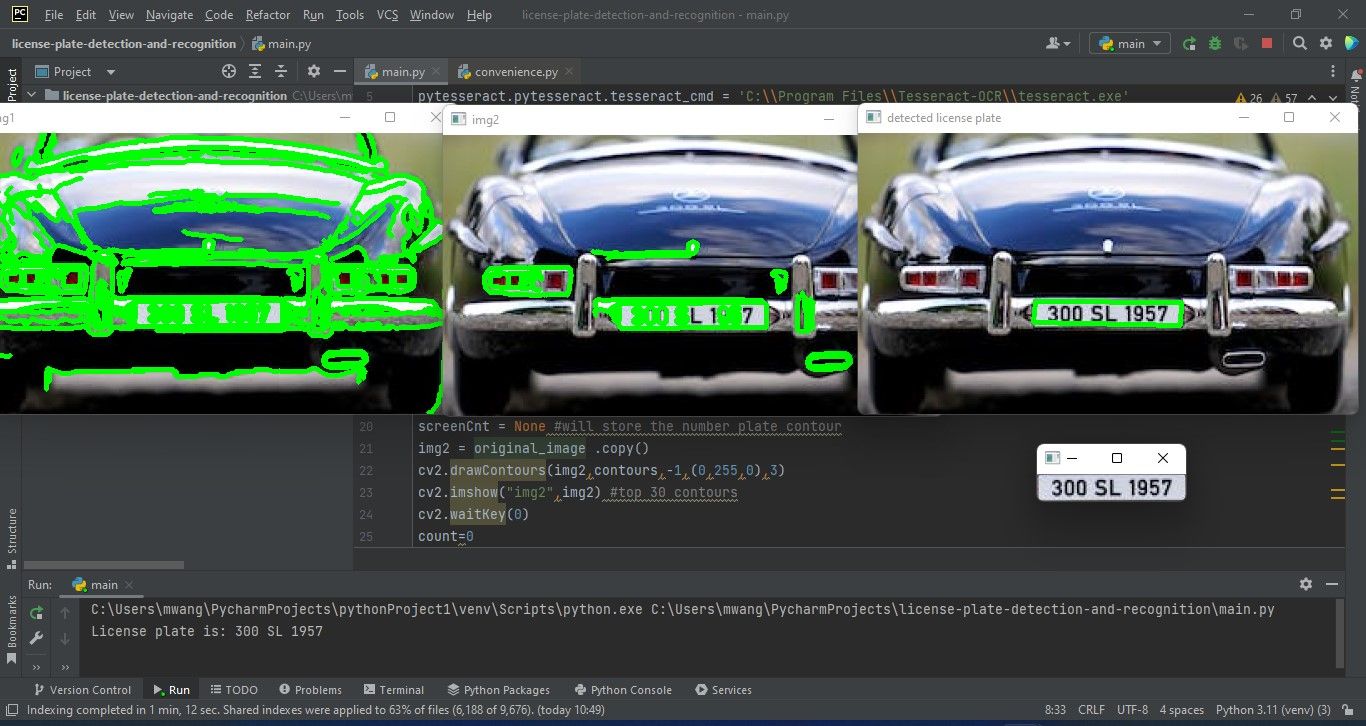
6. Вывод результата
Напечатайте распознанный текст и закройте окна:
print("License plate is:", text)
cv2.waitKey(0)
cv2.destroyAllWindows()Ожидаемый вывод: распознанные символы номерного знака появляются в терминале.
Практические советы по улучшению качества распознавания
- Масштаб и разрешение: увеличивайте размер вырезанной пластины перед OCR (например, умножьте ширину/высоту на 2), чтобы буквы были крупнее для Tesseract.
- Контраст и порог: применяйте адаптивную бинаризацию (cv2.adaptiveThreshold) или Otsu для лучшего отделения символов от фона.
- Морфология: операции открытия/закрытия удаляют шум и заполняют пробелы в символах.
- Обрезка полей: сохраняйте минимальные отступы вокруг символов, удаляя лишний фон.
- Конфигурация Tesseract: используйте параметры типа –psm (page segmentation mode) и –oem для настройки поведения OCR: например, pytesseract.image_to_string(image, config=’–psm 7’) для одиночной строки текста.
Пример улучшения перед OCR:
plate = cv2.imread('./7.png', 0)
plate = cv2.resize(plate, None, fx=2, fy=2, interpolation=cv2.INTER_CUBIC)
_, plate = cv2.threshold(plate, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
text = pytesseract.image_to_string(plate, config='--psm 7')Альтернативные подходы и когда они лучше работают
- Нейросети для детекции + распознавания (рекомендация для промышленного использования):
- YOLO/SSD/RetinaNet для детекции пластин, затем специализированный CRNN для распознавания символов.
- GPT-style модели не применимы; для задач OCR применяются CNN+RNN/CTC архитектуры.
- EasyOCR (вместо pytesseract): проще для мультиязычных наборов, часто даёт лучший результат на «сложных» фонах.
- Комбинированные пайплайны: детектор (область), выравнивание (перспектива) + классификатор символов по сегментам.
Когда использовать нейросеть:
- Сильно варьируются ракурсы, освещение и качество изображений.
- Требуется высокая точность в реальном времени на разных регионах.
Когда Tesseract подходит:
- Чёткие крупные изображения пластин, ограниченное разнообразие форматов.
- Быстрая прототипизация и отсутствие бюджета на обучение сетей.
Отладка и частые ошибки
- “TesseractNotFoundError” — проверьте путь к tesseract_cmd или наличие в PATH.
- Пустой результат OCR — вероятна слабая контрастность, мелкий масштаб или неверный psm.
- Неправильная регистрация букв и цифр — используйте whitelist (ограничение набора символов) через config: config=’-c tessedit_char_whitelist=ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789 –psm 7’
- Неправильное выделение контура — попробуйте другие параметры Canny и пороги в approxPolyDP (влияют на поиск четырёхугольников).
Критерии приёмки
- Система корректно выделяет область номерного знака в >= 90% тестовых изображений (в рамках заданного набора тестов).
- Распознавание текста совпадает с эталоном в >= 85% случаев (в зависимости от набора и условий).
- Время обработки одного изображения не превышает требуемого SLA (например, 0.5–2 секунды для прототипа).
- Ошибки логируются: изображение, результат OCR, конфигурация
Примечание: пороги корректности должны согласовываться с бизнес-требованиями и учитывать множество условий съёмки.
Примеры тест-кейсов (минимум для базовой валидации)
- Чёткая пластина, фронтальный ракурс, дневное освещение — ожидается 100% совпадение.
- Пластина под небольшим углом (~15–30°) — проверить устойчивость детекции и OCR.
- Ночное изображение с подсветкой — проверить предобработку и binarization.
- Частично закрытая пластина (брызги, грязь) — оценить способность корректно распознать часть символов.
- Пластина с нетипичным шрифтом или государственным знаком — проверить false positives.
Чек-лист развёртывания (оператор / DevOps)
- Установлен Tesseract на целевой машине и путь доступен.
- Все Python-зависимости в виртуальном окружении (requirements.txt).
- Логирование ошибок и сохранение проблемных фреймов активированы.
- Параметры OCR (psm, whitelist) вынесены в конфигурацию.
- Тестовый набор изображений для регрессионного тестирования загружен.
Конфиденциальность и права (важно)
Распознавание номерных знаков затрагивает персональные данные и может подпадать под национальные законы о защите данных (например, GDPR в ЕС). Рекомендации:
- Обнуляйте или шифруйте личные идентификаторы, если хранение длительное.
- Храните минимум данных: сохраняйте только то, что необходимо для задачи.
- Получайте юридическое обоснование или согласие на сбор изображений в публичных/частных зонах.
- Логируйте доступ и храните аудит-разрешения.
Оптимизация производительности
- Обработка батчами: если требуется массовая обработка, группируйте изображения.
- Используйте более быстрые реализации OpenCV (с поддержкой TBB, NEON на ARM).
- Для real-time применений — переход на специализированные модели детекции (YOLOv5/YOLOv8) на GPU.
Резюме и следующие шаги
Распознавание номерных знаков на Python — это сочетание классического компьютерного зрения для детекции области и OCR для распознавания символов. Для прототипа OpenCV + pytesseract работают быстро и просто. Для промышленного решения стоит рассмотреть нейросетевые детекторы и специализированные модели OCR.
Рекомендуемые следующие шаги:
- Попробуйте улучшить пайплайн предобработки для своего набора изображений.
- Сравните pytesseract и EasyOCR на ваших данных.
- Если требуется высокая точность, рассмотрите обучение модели распознавания символов.
Важное: тестируйте систему на репрезентативном наборе изображений (разные ракурсы, время суток, загрязнения), чтобы адекватно оценить качество.
Краткая памятка (1-строчное описание каждого ключевого термина):
- OpenCV: библиотека для компьютерного зрения.
- Tesseract: движок OCR; извлекает текст из изображений.
- pytesseract: Python-обёртка вокруг Tesseract.
- Canny: алгоритм детекции краёв.
- contour: замкнутый контур на бинарном изображении.
Итог: начните с простого пайплайна, отлаживайте предобработку, затем масштабируйте на более устойчивые модели по необходимости.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
