Профилирование производительности приложений: руководство и практическая методика

Быстрые ссылки
- Что искать
- Как работает профилирование
- Использование профайлера производительности
Что искать
Узкое место — это любой участок кода, который существенно замедляет остальную часть приложения. Представьте узкое горлышко бутылки или узкую дорогу: даже быстрый код «за ним» будет ждать.
Типичные проблемы, которые стоит искать с помощью профайлера:
- Частые вызовы функций (там, где можно использовать кэширование или реорганизацию задач).
- Блокирующие операции ввода/вывода (синхронный доступ к диску, медленные сетевые вызовы, длительное ожидание запросов к базе данных).
- Большие циклы с тяжёлыми операциями внутри.
- Долгое время старта приложения (важно для JIT-рантаймов и сервисов с холодным стартом).
- Избыточное выделение памяти в рантаймах с сборщиком мусора.
- Участки, которые выиграли бы от параллелизации или асинхронности.
Важно: профайлеры показывают только проблемы в коде и в рантайме — они не диагностируют общую сетевую архитектуру. Если API ждёт медленной базы данных, ускорение веб-сервера не решит задержки.
Совет: даже небольшое улучшение (пара процентов) на горячем пути может значительно снизить расходы и повысить отзывчивость при большой нагрузке.
Как работает профилирование
Профайлеры отличаются от отладчиков: отладчики (breakpoints, инспекция) помогают пошагово найти баги в разработке. Профайлеры предполагают, что вы не знаете, где проблема, и собирают метрики по всему приложению, чтобы найти самые затратные участки.
Что делает профайлер:
- Встраивается в приложение или подключается к процессу.
- Использует высокоточный таймер и/или семплирование, чтобы отследить, какие функции занимают больше всего времени.
- Собирает снимки (snapshots) за выбранный период и строит представления: flame graph, дерево вызовов (Call Tree), статистику по потокам, по аллокациям памяти.
Основной визуальный элемент многих профайлеров — flame graph: интуитивное представление истории вызовов с подсветкой самых «тяжёлых» стеков.
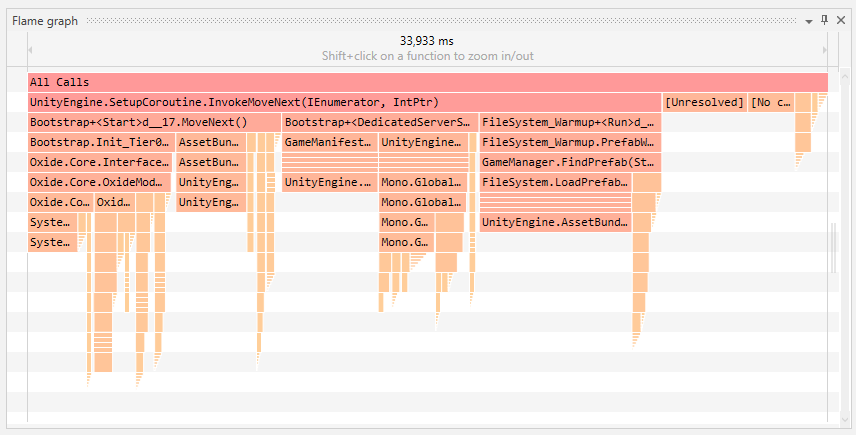
Инструмент и метод будут зависеть от языка и окружения, но концепция общая: собрать данные, отфильтровать шум, локализовать узкие места, оптимизировать и подтвердить улучшение.
Примеры популярных профайлеров по языкам:
- Java — JProfiler, профайлеры в IDEA/Eclipse/Netbeans
- Python — cProfile, Palanteer
- JavaScript — Chrome DevTools (профилирование в браузере и в Node.js)
- C# — dotTrace, встроенные средства Visual Studio
- C/C++ — Orbit и инструменты платформы
Если вы ориентируетесь на конкретные участки, простая библиотека для измерений (benchmark) или секундомер под рукой тоже помогут:
StopwatchНиже — пример использования таймера в C# и Python, когда нужен быстрый локальный бенчмарк.
// C# пример с System.Diagnostics.Stopwatch
var sw = System.Diagnostics.Stopwatch.StartNew();
DoWork();
sw.Stop();
Console.WriteLine($"Elapsed ms: {sw.ElapsedMilliseconds}");# Python пример с time
import time
start = time.perf_counter()
result = do_work()
elapsed = time.perf_counter() - start
print(f"Elapsed s: {elapsed:.6f}")Использование профайлера: пример с dotTrace
Ниже пошаговая методика для dotTrace (профайлер для .NET). Принципиально те же шаги применимы к любому профайлеру: подключение, сбор данных, фильтрация, анализ, оптимизация, валидация.
Подготовка окружения
- Убедитесь, что у вас есть репродуцируемый тестовый сценарий (локальная нагрузка, тестовая нагрузка, интеграционный тест).
- Если проблема проявляется на проде, планируйте профайлирование в тёмное время или используйте низкоинвазивные режимы.
Подключение к процессу
- dotTrace может подключиться к уже запущенному процессу или запустить приложение под контролем профайлера. Запуск из профайлера удобен для исследования проблем старта.
- Сбор данных
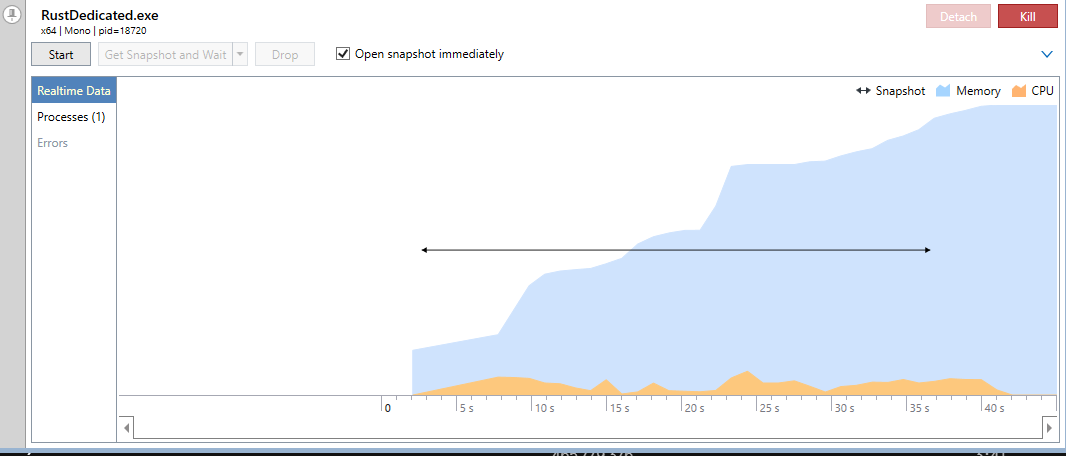
- Запустите сценарий и снимайте данные столько, сколько нужно для репрезентативности.
- Нажмите «Get Snapshot and Wait» (получить снимок), чтобы зафиксировать состояние приложения в конкретный момент.
- Первичный анализ: потоки и главная нить
- Профайлеры показывают все потоки. Если вы видите много ожидания и блокировок, сначала сузьте область до main thread или интересующего потока, чтобы не путаться в фоне.
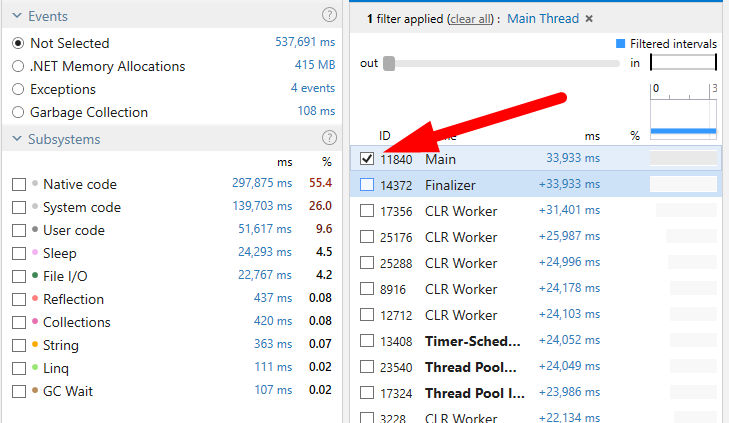
Использование подсистем и фильтров
- Фильтры «Subsystems» помогают отделить системный код (CLR, native) от вашего кода. Это удобный способ отсеять шум от библиотек.
Flame graph и дерево вызовов
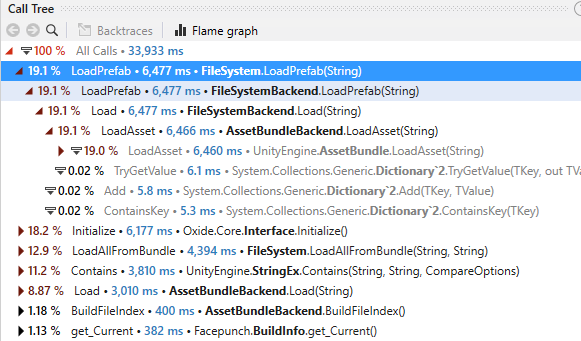
- Flame graph показывает все вызовы начиная с «All Calls». Можно зуммировать на интересующую функцию и увидеть что к ней приводит.

- Call Tree показывает вложенные функции, отсортированные по времени. Обратите внимание на проценты — это доля общего времени, занятая функцией и её потомками.
Память и GC
- CPU не всегда является проблемой — рантаймы с GC (например, .NET, Java) могут страдать от частых аллокаций. Используйте вкладки по памяти, чтобы найти участки с высокой частотой выделения.
Идентификация причин и приоритизация
- Определите «горячие» пути (hot paths). Оцените потенциальное влияние и трудозатраты на оптимизацию. Начните с наибольшего влияния при наименьших усилиях.
Внедрение изменений и проверка
- Вносите изменения небольшими шагами, запускать те же сценарии и сравнивать снимки — так вы увидите реальное влияние.
Мониторинг после релиза
- Внедрив изменения, следите за метриками в проде (latency, error rate, throughput), чтобы убедиться, что оптимизация не привела к регрессиям.
Мини-методика для сессии профилирования (SOP)
- Подготовка: воспроизводимый сценарий и чистая среда.
- Базовый снимок: собрать snapshot перед изменениями.
- Сценарий нагружения: прогнать 1–5 реплик нагрузки / тестов.
- Снимок для анализа: снять snapshot в пике.
- Анализ: flame graph → Call Tree → аллокации → фильтры.
- Гипотеза и патч: формулируем причину и план исправления.
- Рефактор/оптимизация: применять изменения в ветке разработки.
- Регрессия: запустить те же бенчмарки и сравнить.
- Деплой с мониторингом: релиз и наблюдение.
- Документация: описать найденную причину и решение.
Ролевые чек‑листы
Разработчик:
- Воспроизвел проблему локально.
- Собрал несколько снимков до/после изменений.
- Написал базовый тест/бенчмарк для регрессии.
SRE / инженер по производительности:
- Убедился, что профилирование безопасно для продакшена.
- Проверил влияние на метрики инфраструктуры.
- Подготовил план отката.
QA:
- Запустил сценарии нагрузки после оптимизаций.
- Проверил корректность функций при изменённых таймингах.
Менеджер продукта:
- Оценил приоритет оптимизаций по влиянию на пользователей.
- Согласовал окна релизов и мониторинг.
Критерии приёмки
- Время ответа ключевых сценариев снизилось или осталось в пределах SLA.
- Нет увеличения ошибок или утечек памяти.
- Релиз прошёл мониторинг без регрессий в течение оговоренного окна (например, 24–72 часа).
Тесты и критерии (пример)
- Тест производительности: 1000 запросов за N секунд (измерять p50/p90/p99).
- Критерий приёмки: p95 уменьшился на заметную долю по сравнению с базовым снимком или не вырос.
- Регрессионный тест: запустить тот же набор бенчмарков после изменений; показатели не ухудшаются.
Когда профайлинг не поможет (контрпримеры)
- Проблема в сетевой архитектуре: узкая база данных, медленный внешний API.
- Нехватка ресурсов на уровне кластера (CPU/IO/сеть) — тогда нужны масштабирование/архитектурные правки.
- Неправильные метрики: если вы оптимизируете не те показатели, которые важны бизнесу, это бесполезно.
Альтернативы и дополнения к профайлеру
- APM (Application Performance Monitoring): для постоянного мониторинга продакшена и обнаружения трендов.
- Логирование и трассировка (distributed tracing): помогает найти проблемы в распределённых системах.
- Бенчмаркинг: для сравнения алгоритмов в изолированном виде.
Ментальные модели и эвристики
- Узкое место контролирует скорость системы (по аналогии с Amdahl’s law): ускорение незначительной части работы редко даст большой эффект.
- «80/20»: часто 20% кода потребляют 80% времени.
- Измеряй, не угадывай: гипотезы полезны, но подтверждайте их профилями.
Галерея пограничных случаев
- Много фоновых потоков, создающих «шум» — фильтруйте по main thread.
- Небольшие, но частые аллокации в горячем пути — влияют на GC.
- Вызовы в сторонних библиотеках — иногда выгоднее кешировать результат, чем оптимизировать библиотеку.
План действий при ухудшении производительности в проде (инцидент‑рукбук)
- Снизить нагрузку (rate‑limit, включить fallback), если возможно.
- Включить профилирование или собрать трассы/логи для проблемного периода.
- Быстро определить, изменился ли узкий путь: CPU, latency, errors.
- Откатить последний релиз, если подозрение на регрессию в коде.
- Подготовить фиксы в отдельной ветке и прогнать тесты и бенчмарки.
- Рестарт/ребаланс сервисов при необходимости.
Краткая таблица совместимости и советы по миграции
- Для .NET: dotTrace для глубокого анализа, Benchmark.NET для микро‑бенчмарков.
- Для JVM: профилировать на хосте с одинаковой конфигурацией JVM (GC flags, heap size).
- Для Python/Node: профайлеры иногда накладывают overhead — используйте sampling режим в проде.
Краткая памятка по безопасности и приватности
- Не собирайте и не отправляйте PII в профайлы.
- В профайлеры и снимки могут попасть стэки и значения — проверяйте перед отправкой внешним инструментам.
- Ограничьте доступ к снимкам; храните их в защищённом хранилище.
Краткая выдержка — что запомнить
- Профилирование — это цикл: измерить → локализовать → оптимизировать → проверить.
- Начинайте с самых затратных и самых простых для исправления участков.
- Всегда сравнивайте снимки «до» и «после».
Короткий словарик терминов
- Snapshot — снимок состояния приложения с профайлерными данными.
- Flame graph — визуализация стека вызовов, где ширина блоков отражает потребление времени.
- Call Tree — дерево вложенных вызовов, отсортированное по сумме времени.
- Hot path — участок кода, потребляющий значительную долю времени.
Предложения для публикации в соцсетях
Подойдёт короткий анонс: “Как быстро найти узкие места в приложении: пошаговое руководство по профилированию и практические чек‑листы — от подготовки до релиза.”
Итог: профилирование — инструмент для точечной оптимизации. Оно не заменяет архитектурные решения, но помогает эффективно находить и корректировать реальные узкие места в коде.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
