Как копировать текст с сайтов, где отключено копирование
Оглавление
- Отключить JavaScript в браузере
- Использовать режим чтения браузера
- Копировать из исходного кода страницы
- Выделить в Inspect Element
- Скриншот и распознавание текста (OCR)
- Веб‑сервисы для извлечения текста
- Расширения браузера
- Когда эти методы не работают
- Альтернативные подходы и быстрые рекомендации
- Пошаговый шаблон действий (SOP)
- Роль‑ориентированный чеклист
- Критерии приёмки
- Краткая глоссарий и примечания по приватности
- Резюме
1. Отключить JavaScript в браузере
Почему работает: многие сайты используют JavaScript, чтобы перехватывать события мыши и блокировать контекстное меню или выделение. Отключение JavaScript для конкретного сайта убирает эти скрипты и восстанавливает стандартное поведение браузера.
Важно: отключение JavaScript может повлиять на отображение страницы и работу других функций — формы, динамические загрузки, медиа и т. п.
Пошагово (пример — Google Chrome на ПК):
- Откройте Chrome и нажмите на три точки в правом верхнем углу. Выберите Настройки.
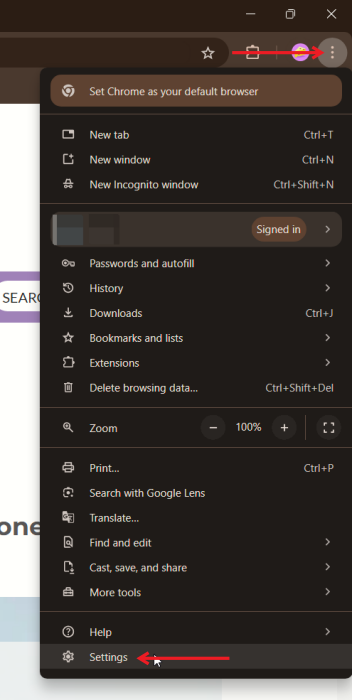
- В левом меню выберите Конфиденциальность и безопасность. На правой панели нажмите Настройки сайта.
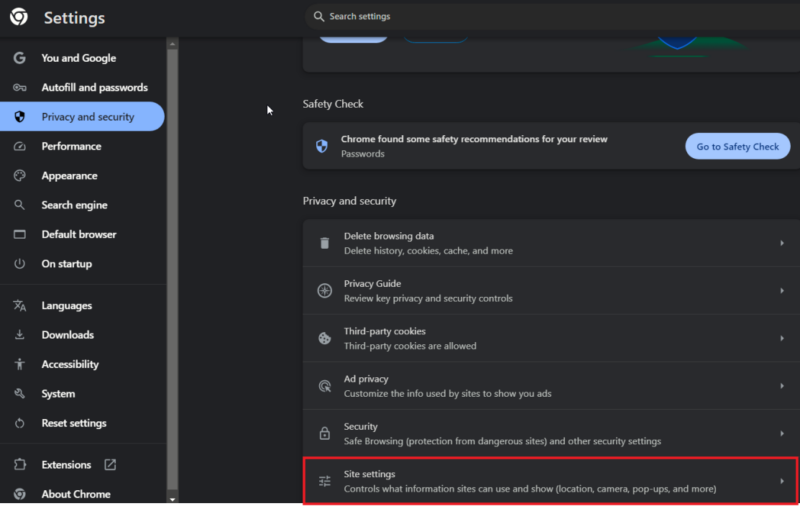
- Прокрутите вниз и выберите JavaScript.
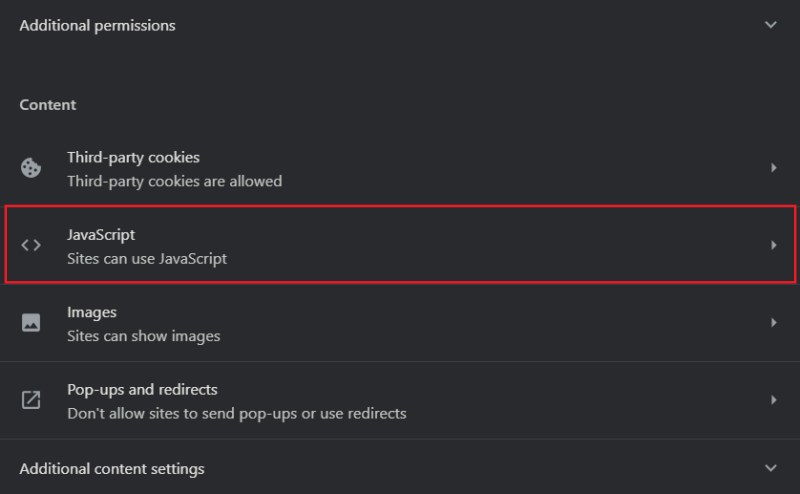
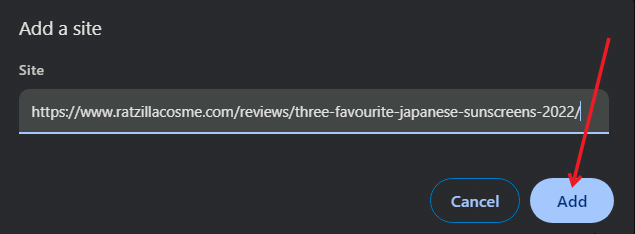
- Нажмите Добавить, чтобы заблокировать JavaScript для конкретного домена, и введите адрес сайта.
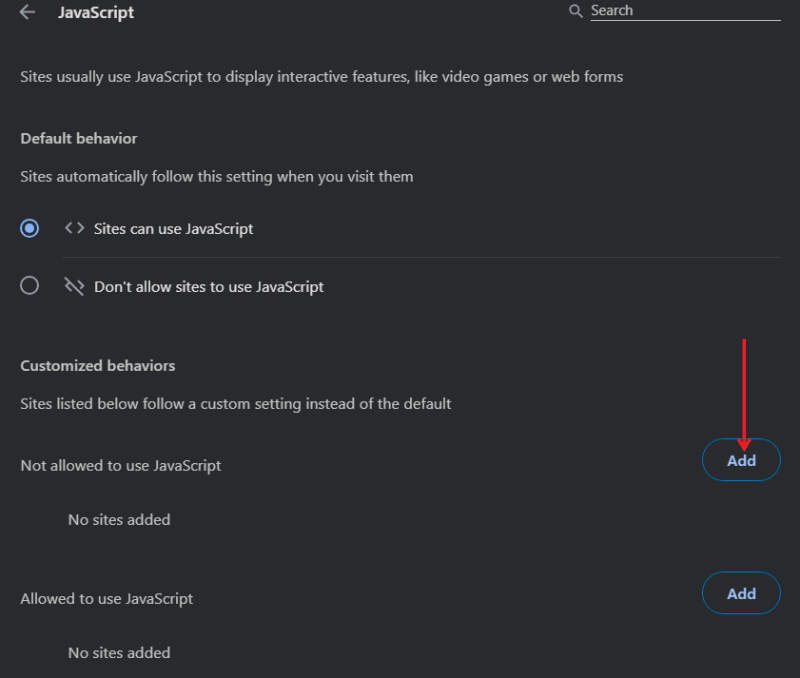
- Вернитесь на страницу и обновите её — теперь выделение и правый клик могут работать.
Советы по совместимости:
- Firefox: в обычных настройках отключение JavaScript — не тривиальная операция, для этого часто используют about:config (javascript.enabled = false) или временно включают соответствующие дополнения.
- Safari: в меню Разработка отключите выполнение JavaScript для конкретной страницы.
- На мобильных устройствах (Android/iOS) найдите настройки сайта в настройках браузера или используйте специальные приложения с управлением скриптами.
Примечание: знайте разницу между Java и JavaScript — это разные технологии.
2. Использовать режим чтения браузера
Почему работает: режим чтения удаляет оформление и скрипты, оставляя только основной текст и минимальную вёрстку. В этом представлении часто можно свободно выделять и копировать содержимое.
Как включить:
- Chrome (десктоп): откройте страницу, нажмите три точки → Дополнительные инструменты → Режим чтения.
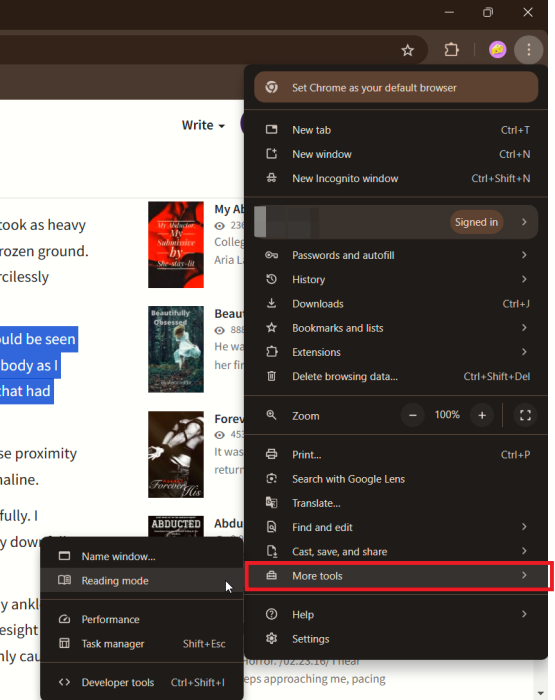
Текст откроется в боковой панели или в новой вкладке; оттуда можно выделить и скопировать.
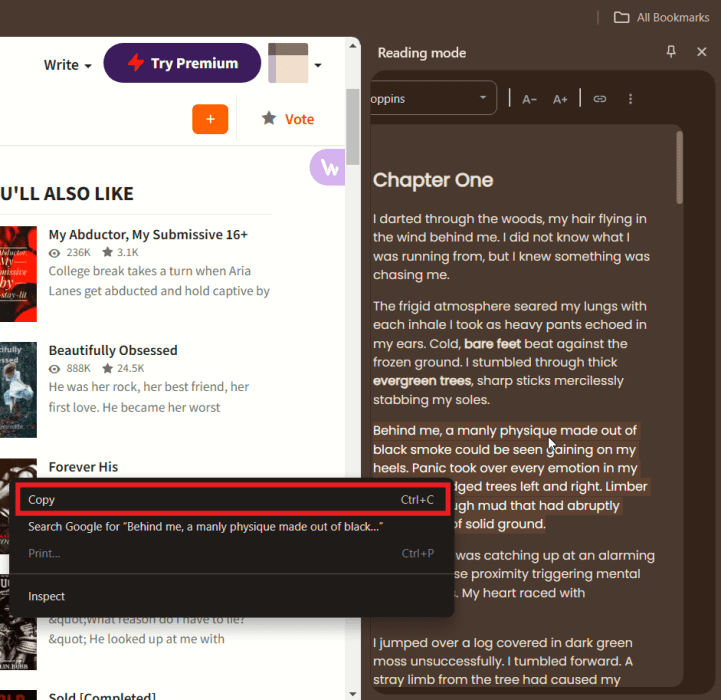
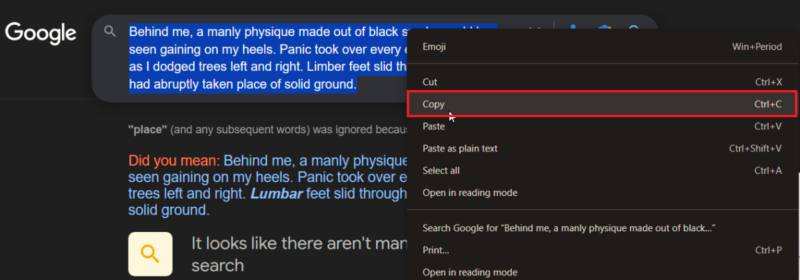
Если проблема с копированием остаётся, в режиме чтения можно правой кнопкой мыши выбрать Поиск в Google, чтобы открыть текст в новой вкладке поисковой строки, и скопировать оттуда.
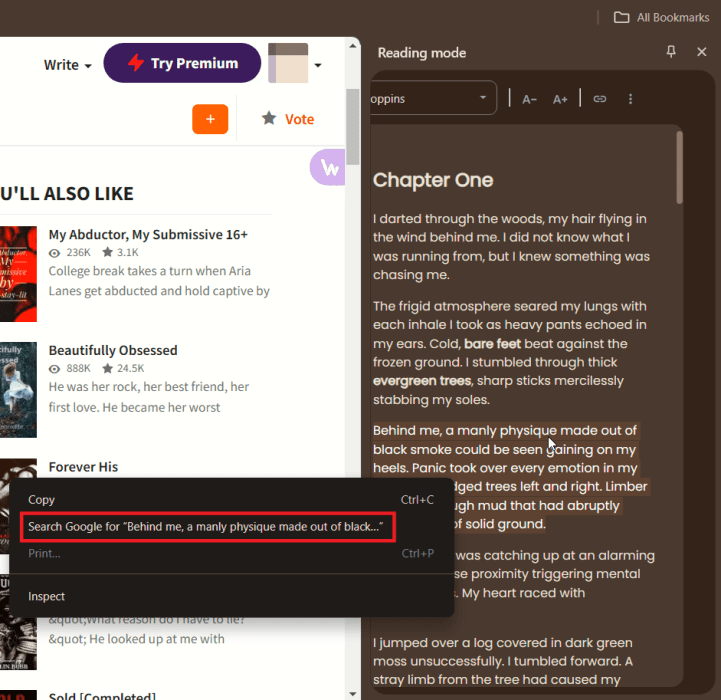
- Firefox: нажмите на значок страницы справа в адресной строке, чтобы включить режим чтения.
Когда использовать: если нужно быстро получить чистую версию статьи без оформления.
3. Копировать из исходного кода страницы
Почему работает: исходный код содержит весь текст в HTML, независимо от запретов на выделение. Это особенно полезно, если правый клик разрешён, но выделение блочно запрещено стилями или скриптами.
Как делать:
- Правый клик на странице → Просмотреть код страницы или Просмотр исходного кода.
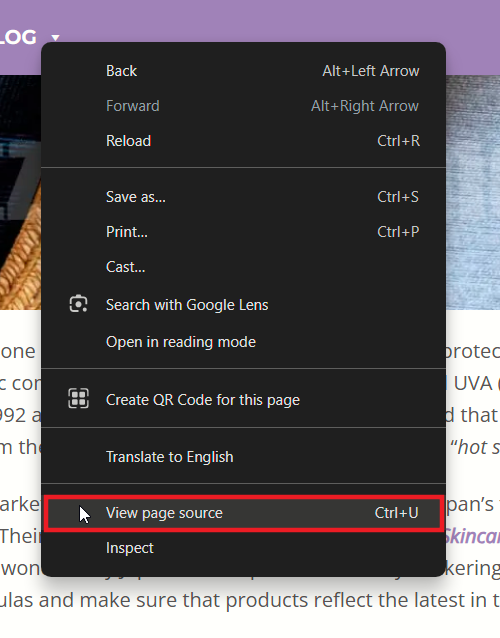
- В открывшемся окне найдите нужный фрагмент (Ctrl+F по ключевому слову) и скопируйте текст.

- Если нужно извлечь большой объём текста, скопируйте весь HTML и используйте конвертер HTML→Текст (например, wordhtml.com) для очистки разметки.
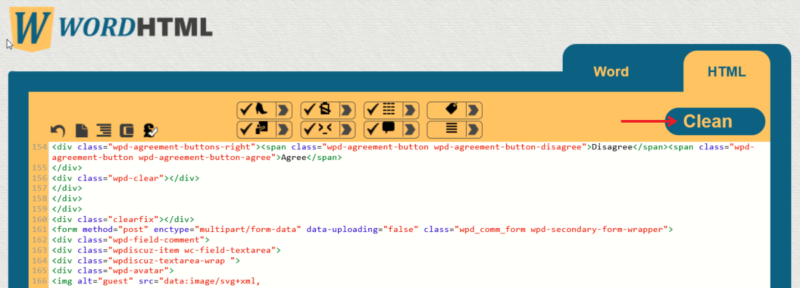
- Перейдите в вкладку Word или Plain Text и скопируйте готовый текст.
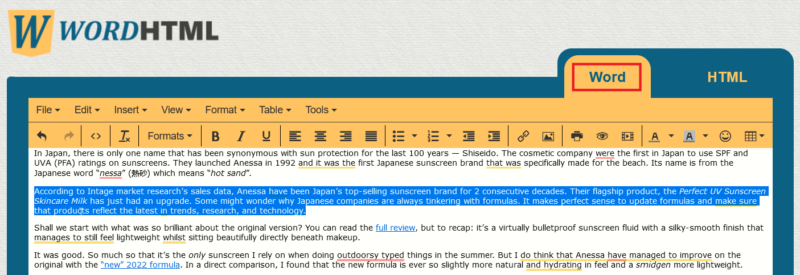
Советы:
- В исходном коде текст часто окружён тегами. Ищите читаемые строки, а не скрипты и стили.
- Для больших сайтов удобно использовать парсеры или wget/curl для локального анализа.
4. Выделить в Inspect Element
Почему работает: инструмент «Инспект» показывает DOM-структуру и позволяет моментально найти конкретный текстовый узел, даже если стиль запрещает выделение.
Как делать:
- Правый клик → Инспект.
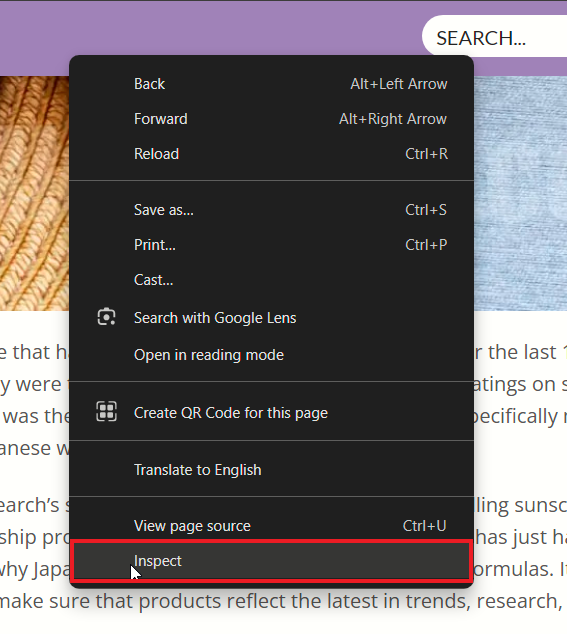
Наведите курсор на нужный фрагмент на странице — в инспекторе подсветится соответствующий элемент.
Дважды кликните по текстовому узлу в панели DOM, чтобы выделить текст, затем Ctrl+C или ПКМ → Копировать.
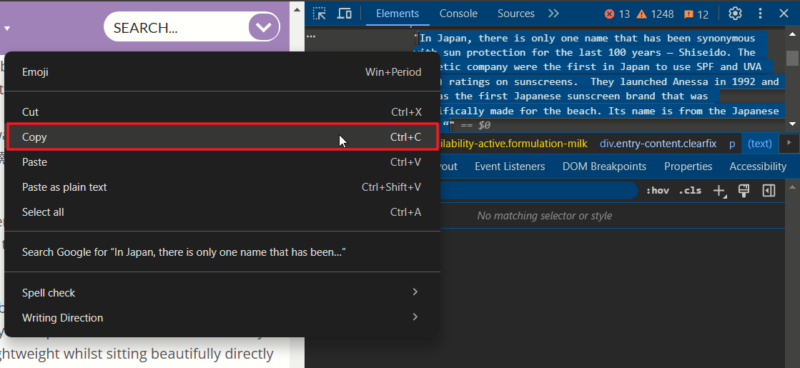
Подсказка: иногда текст разбит на несколько узлов — проверьте соседние элементы.
5. Скриншот и распознавание текста (OCR)
Почему работает: если текст защищён технически (рендеринг как изображение, canvas, нестандартная вёрстка), распознавание текста из изображения — универсальный метод.
Как делать на Windows и macOS:
- Windows: нажмите Win + Shift + S, выберите область и сохраните скрин.
- macOS: нажмите ⌘ + Shift + 4 и выделите область.

Затем загрузите изображение на сервис OCR (например, ocr2edit): загрузите файл → нажмите Start → скачайте результат.
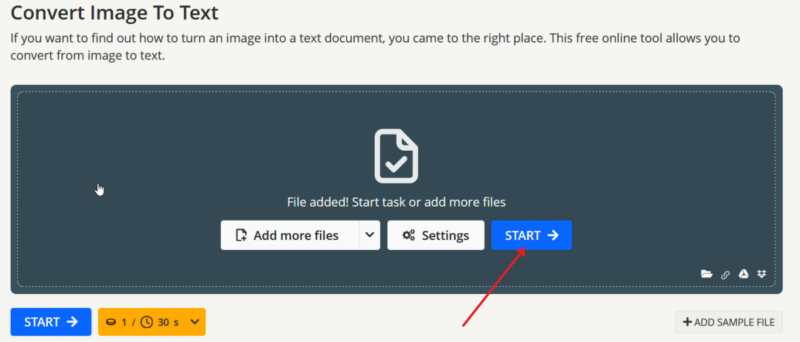
После распознавания проверьте текст на опечатки и пропуски — OCR не идеален, особенно при сложной верстке или мелком шрифте.
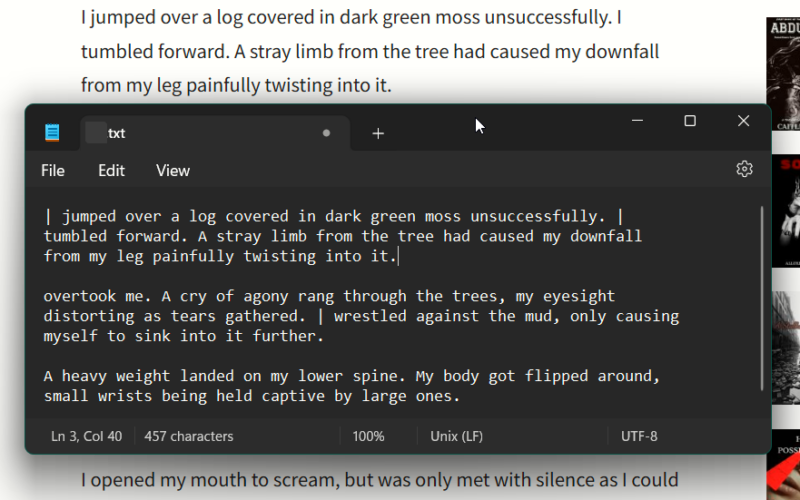
Альтернативы: используйте Google Lens, мобильные приложения (Text Scanner, Adobe Scan), встроенные возможности Google Фото.
6. Веб‑сервисы для извлечения текста
Почему работает: некоторые веб‑утилиты принимают ссылку и возвращают «очищенную» версию текста (аналог режима чтения), обходит скрипты и блокировки.
Пример — Textise: вставьте ссылку и нажмите Textise, сервис вернёт страницу только с текстом.
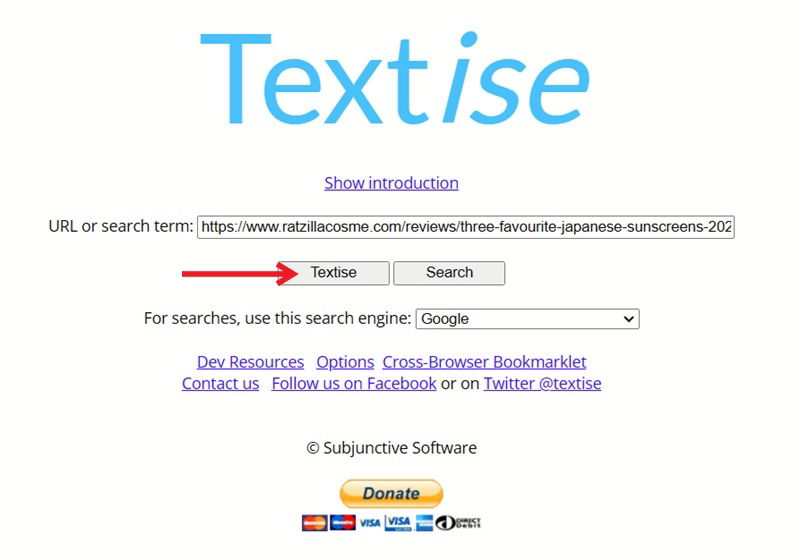
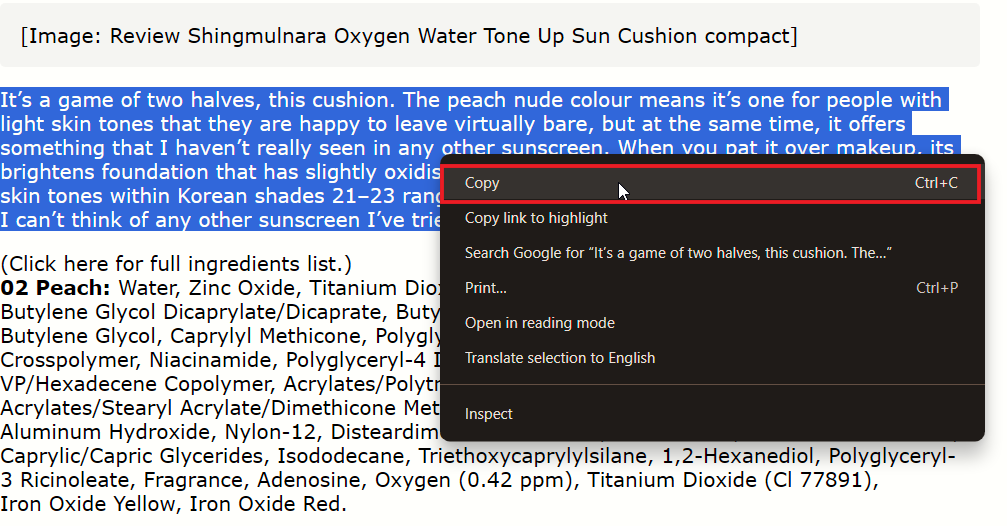
Плюсы: подходит, если у вас нет времени разбираться с настройками браузера. Минусы: сервисы могут ломаться на динамических сайтах, загружать устаревший контент или не поддерживать авторизацию.
7. Расширения браузера
Почему работает: расширения могут отменять перехват контекстного меню и блокировку выделения на стороне клиента. Пример: Enable Right-Click для Chrome.
Как использовать:
- Установите расширение из магазина браузера.
- Перейдите на страницу с блокировкой и активируйте расширение в панели инструментов.
- Попробуйте правый клик и копирование.
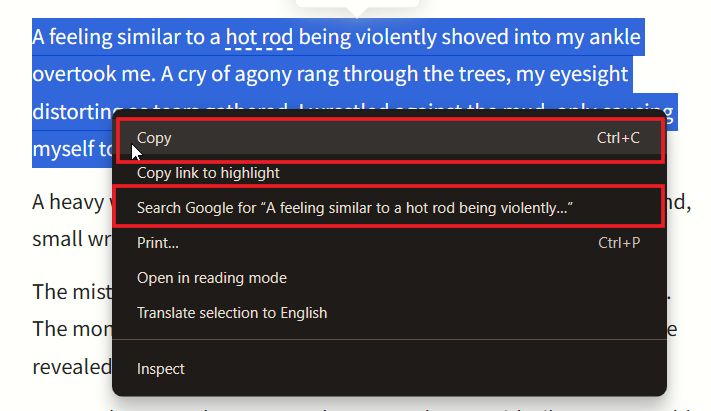
Ограничения:
- Некоторые сайты применяют более сложные меры (серверная генерация контента, canvas), где расширение бессильно.
- Расширения могут требовать доступ к данным на сайтах — учитывайте приватность.
Когда эти методы не работают
- Контент рендерится на сервере в виде изображения или canvas без возможности получить исходный текстным узлом — тут поможет OCR.
- Текст защищён DRM или доступен только после авторизации/подписки — обойти это технически или юридически нельзя.
- Сайт использует сложную динамическую подачу контента через WebSocket/динамическую подстановку — иногда можно получить данные из сетевых запросов (Network) в инструментах разработчика.
Важно: не пытайтесь обходить платный доступ, лицензии или DRM — это может нарушать закон и условия сервиса.
Альтернативные подходы
- Сохранить страницу как PDF и попытаться скопировать текст из PDF.
- Сохранить страницу локально и открыть её в текстовом редакторе/IDE для парсинга.
- Использовать командную строку: curl/wget для получения исходного HTML и последующий парсинг.
- Для массового извлечения данных применять легальные API сайта или контакт с владельцем контента и запрос на предоставление данных.
Ментальные модели и эвристики
- Простое сначала: попробуйте режим чтения или View Source прежде, чем переходить к инструментам разработчика.
- Минимизируйте влияние: отключайте JavaScript только для целевого домена, не глобально.
- Безопасность и приватность: если используете онлайн‑сервис, не отправляйте приватные или авторские тексты.
- Юридическая проверка: если контент платный или защищён авторским правом, уточните условия использования перед копированием.
Пошаговый шаблон действий (SOP)
- Попробуйте выделить текст обычным способом.
- Если не получилось, включите режим чтения — скопируйте.
- Если режим чтения недоступен, откройте Инспект и попробуйте скопировать фрагмент.
- Если Инспект не помогает, откройте Просмотр исходного кода и найдите текст.
- Если текст рендерится как изображение — сделайте скрин и примените OCR.
- Если требуется регулярно — установите безопасное расширение и ограничьте его разрешения.
- Всегда проверяйте результат и корректируйте форматирование.
Роль‑ориентированные чеклисты
Для обычного пользователя:
- [] Проверить режим чтения
- [] Попробовать правый клик → Просмотр исходного кода
- [] Сделать скрин и распознать через OCR
Для технического пользователя (разработчика/админ):
- [] Использовать Инспект → Network → найти API/JSON
- [] Запросить страницу через curl/wget
- [] Парсить HTML средствами (BeautifulSoup, Cheerio)
Для юридического/контент‑менеджера:
- [] Проверить лицензии и авторские права
- [] Связаться с владельцем контента при необходимости
- [] Документировать источник при использовании в публикациях
Критерии приёмки
- Текст извлечён в читаемом виде (без лишней разметки).
- Формулировки соответствуют оригиналу (без искажения смысла).
- Сохранена ссылка на оригинальный источник.
- Соблюдены права доступа и лицензии.
Технические советы и тесты качества
- Тест‑кейсы:
- Попробовать извлечь текст из страницы с отключённым правым кликом.
- Попробовать извлечь текст из страницы, где контент рендерится в canvas.
- Попробовать извлечь текст со страниц, требующих авторизации.
- Критерий успеха: извлечённый текст можно вставить в документ и привести к читабельному виду за ≤5 минут ручной правки.
Глоссарий (одно предложение на термин)
- JavaScript — язык программирования, который на стороне клиента управляет интерактивностью на веб‑странице.
- Инспект (Inspect Element) — панель разработчика в браузере для просмотра DOM и сетевых запросов.
- OCR — технология распознавания текста на изображениях и скриншотах.
- Режим чтения — режим в браузере, который показывает только основной текст страницы.
Приватность и юридические примечания
- Не загружайте в онлайн‑сервисы конфиденциальные или платные материалы без разрешения.
- Расширения могут требовать доступ к данным на сайтах — внимательно читайте разрешения и политику конфиденциальности.
- Копирование и дальнейшее распространение контента без согласия правообладателя может нарушать авторские права.
Когда лучше запросить доступ легально
- Если нужна большая часть или весь контент для републикации — запросите API или экспорт у владельца сайта.
- При использовании материалов в коммерческих или публичных проектах обязательно согласуйте права.
Диаграмма принятия решения
flowchart TD
A[Нельзя выделить текст?] --> B{Требуется много текста?}
B -- Нет --> C[Попробовать режим чтения]
B -- Да --> D{Доступна авторизация?}
C --> E{Получилось?}
E -- Да --> End[Готово]
E -- Нет --> D
D -- Да --> F[Откройте Инспект или Просмотр исходного кода]
D -- Нет --> G{Текст рендерится как изображение?}
F --> H{Нашли текст?}
H -- Да --> End
H -- Нет --> G
G -- Да --> I[Сделать скрин и OCR]
G -- Нет --> J[Попробовать расширение или веб‑сервис]
I --> End
J --> EndКраткая аннотация для соцсетей
Нужен текст с сайта, где отключено копирование? В статье — 7 рабочих способов: режим чтения, отключение JavaScript, Inspect, исходный код, OCR, онлайн‑сервисы и расширения браузера. Пошаговые инструкции, чеклисты и рекомендации по безопасности.
Короткое объявление (100–200 слов)
Если сайт блокирует выделение текста, это не приговор: можно отключить JavaScript только для домена, включить режим чтения, открыть исходный код, воспользоваться инструментом Инспект, сделать скрин с последующим OCR или применить веб‑сервис для извлечения текста. В статье приведены пошаговые инструкции для популярных браузеров, советы по безопасности и приватности, шаблон действий (SOP) и чеклисты для пользователей и технических специалистов. Также объяснено, когда такие методы не помогут (DRM, платный доступ) и как корректно запросить контент у владельцев. Используйте легальные методы, уважайте авторские права и проверяйте результат перед публикацией.
Image credit: Freepik All screenshots by Alexandra Arici
Похожие материалы

RDP: полный гид по настройке и безопасности

Android как клавиатура и трекпад для Windows

Советы и приёмы для работы с PDF

Calibration в Lightroom Classic: как и когда использовать

Отключить Siri Suggestions на iPhone
