Конвертация CSV в Parquet с помощью AWS Glue

Что такое колоночный формат
CSV — это текстовые строки с разделителями. На уровне пользователя данные выглядят в виде столбцов, но под капотом это строки текста. При запросе одной колонки аналитическая система вынуждена прочитать весь файл. Колонковые форматы (например, Apache Parquet) хранят данные по столбцам. Это даёт два основных преимущества:
- Меньше данных для сканирования при запросах по подмножеству колонок.
- Более плотная и эффективная компрессия за счёт однородности данных в столбце.
Если в файле 10 колонок и вы читаeте только одну, выбор Parquet может сократить объём сканированных данных на ~90% по сравнению с CSV. Это особенно важно для платёжных сервисов типа AWS Athena, где стоимость пропорциональна объёму обработанных данных.
Важные термины:
- Колонка — набор значений одного поля в таблице.
- Schema — описание колонок и типов данных.
- Краулер — компонент Glue, который обнаруживает таблицы и схему в S3.
Когда колоночные форматы не подходят
- Если вам нужен человекочитаемый формат для быстрой проверки файла вручную.
- Для мелких одноразовых файлов преобразование может быть избыточным.
- Если данные часто обновляются по отдельным строкам и вы не хотите создавать новые файлы.
Альтернативы и сопоставление
- Parquet — лучший выбор для аналитики на больших наборах данных.
- ORC — альтернатива Parquet, оптимизирована в некоторых экосистемах Hadoop.
- Avro — хорош для сериализации со схемами, чаще используется в потоках.
- Таблицы с разделением (partitioning) + Parquet — оптимальный паттерн для больших наборов логов.
Быстрый обзор процесса (методология)
- Поместите CSV в отдельную папку в S3.
- Создайте краулер Glue, чтобы зарегистрировать таблицу и схему.
- Создайте Job в Glue, выберите предложенный скрипт и укажите «Change Schema». Укажите Parquet и пустую целевую папку.
- Убедитесь, что роль IAM имеет права на чтение исходной папки и запись в целевую.
- Запустите задачу, проверьте результат в S3 и в Athena.
Пошаговое руководство по AWS Glue
1. Подготовьте исходные данные
- Поместите CSV-файл(ы) в отдельную папку S3: s3://your-bucket/path/source/
- Если у вас один файл — поместите его в отдельную папку, чтобы избежать смешения схем.
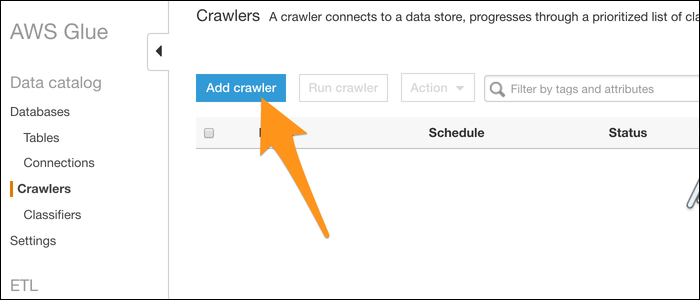
2. Создайте краулер (Crawler)
- Откройте консоль AWS Glue и начните с «Get Started» или раздела Crawler.
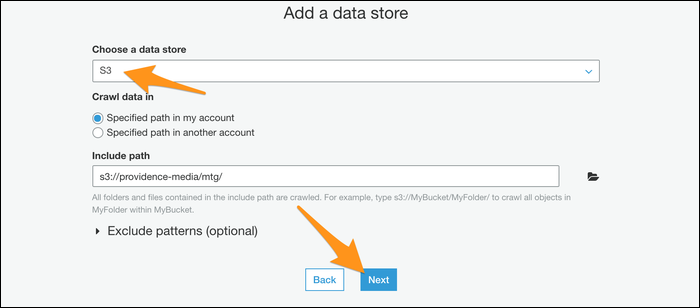
- Добавьте новый краулер и укажите источник данных — S3, путь к папке с CSV.
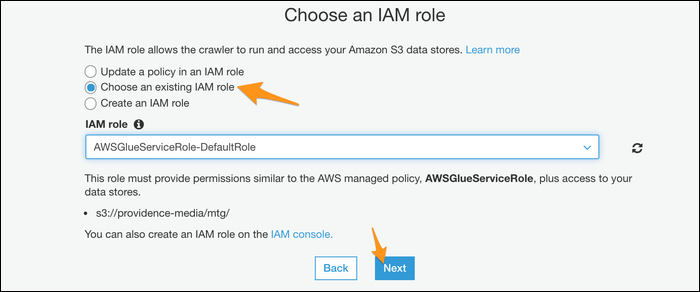
- Выберите IAM-роль для краулера (Glue должна иметь права на чтение указанной папки).
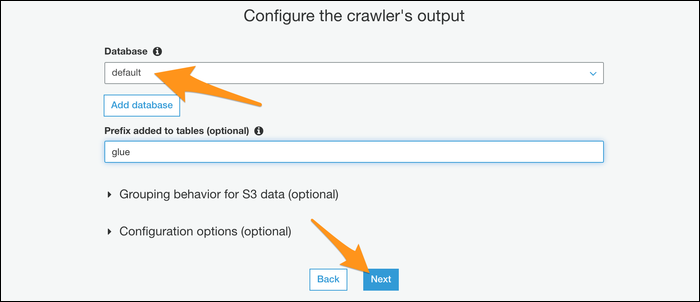
- Укажите базу данных для метаданных (Glue Data Catalog). Если базы нет — можно создать по умолчанию.
- Запустите краулер и дождитесь, пока он зарегистрирует таблицу со схемой.
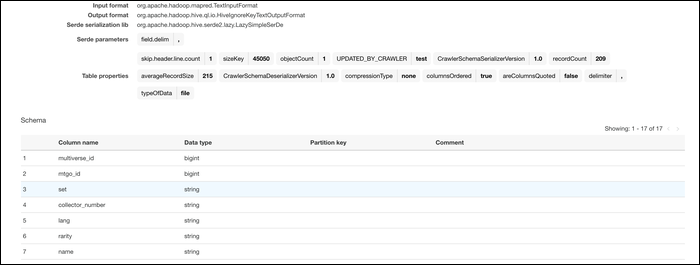
3. Проверьте импортированную таблицу
После работы краулера откройте Glue Data Catalog или Athena и убедитесь, что таблица создана с корректными типами колонок. В большинстве случаев Glue автоматически детектирует типы по содержимому.
4. Создайте задание (Job) для конвертации
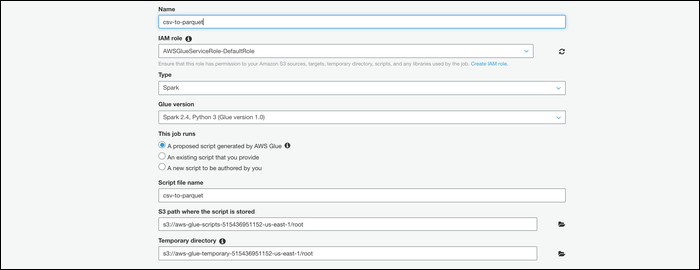
- Перейдите в раздел Jobs в Glue и создайте новое задание.
- Дайте имя, выберите ту же IAM-роль, которую использовал краулер (или роль с нужными правами).
- В качестве типа скрипта выберите «A Proposed Script Generated By AWS Glue» или локализованный эквивалент.
- На следующем шаге выберите таблицу, созданную краулером.
- Выберите «Change Schema» — это сигнал, что задача будет преобразовывать формат.

5. Укажите целевой формат и путь
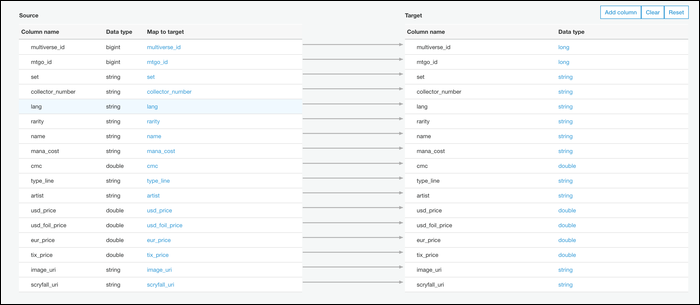
- Выберите «Create Tables In Your Data Target» и укажите Parquet.
- Укажите пустую целевую папку в S3, например: s3://your-bucket/path/target/

- При необходимости откорректируйте схему (обычно требуется один-к-одному соответствие).
6. Сохраните скрипт и запустите Job
- Сохраните предложенный Glue скрипт. В большинстве случаев скрипт подходит без изменений.
- Перед запуском убедитесь, что роль имеет права записи в target-папку.
- Нажмите «Run». Статус выполнения появится в консоли Jobs.
- По завершении проверьте появление Parquet-файлов в целевой папке S3.
Шаблон прав IAM (пример)
Важно: чаще всего ошибка запуска связана с недостаточными правами роли. Пример минимальной политики для записи/чтения S3 и взаимодействия с Glue:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::your-bucket",
"arn:aws:s3:::your-bucket/*"
]
},
{
"Effect": "Allow",
"Action": [
"glue:*",
"iam:PassRole"
],
"Resource": "*"
}
]
}Замените your-bucket на имя вашего бакета. Если вы хотите ограничить доступ, указывайте конкретные ресурсы вместо “*”.
Важно: роль Glue должна иметь возможность выполнять iam:PassRole для передачи роли своим сервисам.
Отладка и типичные проблемы
- Ошибка исполнения Job: проверьте CloudWatch Logs для конкретной ошибки.
- Нет записи в S3: вероятно, роль не имеет s3:PutObject на целевой путь.
- Неправильные типы колонок: скорректируйте схему в Data Catalog или измените маппинг в Job.
- Большие файлы вызывают таймауты — разбейте входные файлы на чанки или увеличьте ресурсы.
Примечание: иногда Glue корректно детектирует строки как string, хотя вы ожидаете integer/decimal. В таких случаях явно задавайте типы в схеме или примените преобразование в скрипте.
Автоматизация и триггеры
Glue позволяет связать работу краулера и Job через триггеры. Базовый паттерн автоматизации:
- Краулер запускается по расписанию или на событие S3 (через Lambda).
- По завершении краулера триггер запускает Job, который читает таблицу Data Catalog и пишет Parquet.
- Дополнительно — отправка уведомлений в SNS/Slack о статусе.
Это полезно для инжеста серверных логов или регулярных выгрузок.
Playbook / SOP для конвертации CSV→Parquet (короткий)
- Проверить, что исходная папка пустая от лишних файлов.
- Запуск краулера и проверка схемы в Glue Data Catalog.
- Создать Job: выбрать таблицу, задать целевой формат Parquet, указать пустой target.
- Применить IAM-политику на роль (см. шаблон выше).
- Запустить Job, мониторить CloudWatch и статус в Glue.
- Проверить файлы в S3 и тестовый запрос в Athena.
- Документировать схему и добавить тесты качества данных.
Контроль качества и критерии приёмки
- В целевой папке S3 появились Parquet-файлы.
- Количество записей в Parquet соответствует ожидаемому (проверка через Athena или Spark SQL).
- Типы колонок сопоставимы с требуемыми (int, bigint, string, timestamp и т.д.).
- Время выполнения и стоимость в пределах ожидаемого SLA.
Роли и чек-листы
Data Engineer:
- Проверить корректность схемы.
- Запланировать партиционирование, если нужно.
- Настроить тесты на целостность данных.
DevOps:
- Настроить и проверить IAM-политику.
- Настроить мониторинг (CloudWatch, алерты).
Аналитик:
- Запустить тестовые запросы в Athena.
- Проверить качество и полноту данных.
Решение: когда выбрать другой инструмент (дерево решений)
flowchart TD
A[У вас CSV в S3?] -->|Да| B{Данные большие и часто запрашиваются?}
B -->|Да| C[Glue -> Parquet 'рекомендуется']
B -->|Нет| D{Нужна потоковая обработка?}
D -->|Да| E[Используйте Apache Kafka + Flink + Parquet/ORC]
D -->|Нет| F[Оставить CSV или использовать небольшую ETL-утилиту]
A -->|Нет| G[Подготовьте источники или используйте другой коннектор]Безопасность и конфиденциальность
- Ограничьте права роли только теми ресурсами S3, которые необходимы.
- Для чувствительных данных рассмотрите шифрование на стороне сервера (SSE-S3/SSE-KMS).
- Включите журналирование доступа и аудит (S3 Access Logs, CloudTrail).
Примеры тест-кейсов для приёмки
- Конвертация файла на 10 000 строк завершилась успешно, количество строк совпадает.
- Колонка “timestamp” сохранена в формате timestamp, и запрос на временной интервал возвращает корректные строки.
- Ограничение: попытка записать в существующую не пустую целевую папку должна быть запрещена или вызывать предупреждение.
Краткое резюме
Конвертация CSV в Parquet через AWS Glue — практичный и относительно простой способ уменьшить расходы на аналитические запросы и ускорить обработку. Уделите внимание правам IAM и проверке схемы, автоматизируйте процесс через триггеры, и добавьте мониторинг и тестирование качества данных.
Important: всегда тестируйте на примере с контрольной выборкой перед массовой конвертацией.
Концовка
Если нужно, могу подготовить:
- Готовый CloudFormation/Terraform-шаблон для краулера и Job.
- Полный пример скрипта Glue с явными преобразованиями типов.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
