Объединение нескольких Excel-файлов с помощью Python

Python полезен для работы со структурированными данными. Поскольку многие хранят данные в Excel, часто нужно консолидировать несколько файлов в один, чтобы сэкономить время и упростить анализ. Благодаря богатой экосистеме библиотек Python это делается относительно просто.
В этом руководстве показано, как установить Pandas, подготовить папку с файлами, объединить файлы в один DataFrame и экспортировать результат в Excel. Также приведены более надёжные варианты реализации, проверочные сценарии, меры безопасности и рекомендации по отладке.
Установка библиотек Pandas
Pandas — сторонняя библиотека для Python, которая предоставляет удобные структуры данных (DataFrame) и функции для работы с таблицами. Некоторые IDE и дистрибутивы (Anaconda) уже содержат Pandas.
Если в вашей среде Pandas не установлена, установите её командой:
pip install pandasЕсли вы используете Jupyter Notebook, ту же команду можно выполнить внутри ячейки или установить через менеджер пакетов среды.
Совет: при долгой работе с проектами создавайте виртуальное окружение (venv / conda) и фиксируйте зависимости в requirements.txt или environment.yml.
Подготовка папки с исходными файлами
Создайте одну папку, в которую поместите все Excel-файлы, которые нужно объединить. Ниже приведён пример путей на Windows — используйте прямые слэши (/) или экранируйте обратные (\):
input_file_path = "C:/Users/gaurav/OneDrive/Desktop/Excel files/"
output_file_path = "C:/Users/gaurav/OneDrive/Desktop/"Важно: добавьте слеш в конце, чтобы корректно соединять путь и имя файла.
Базовый способ: перевод оригинального примера
Ниже — переводы пояснений к исходному коду и сам код (оригинальные блоки сохранены далее). Для объединения используется Pandas и модуль os для получения списка файлов.
- Pandas: предоставляет DataFrame для хранения и обработки таблиц.
- os: стандартный модуль для работы с файловой системой.
Пример основных шагов:
- Получить список файлов в папке: os.listdir(input_file_path).
- Фильтровать по расширению “.xlsx”.
- Читать каждый файл в DataFrame: pd.read_excel(…).
- Добавлять данные в общий DataFrame (в оригинале использовался df.append).
- Экспортировать объединённый DataFrame в файл: df.to_excel(…).
Оригинальные фрагменты кода из источника (сохранены без изменений):
pip install pandasImport Pandas as pd
Import OSinput_file_path = "C:/Users/gaurav/OneDrive/Desktop/Excel files/"
output_file_path = "C:/Users/gaurav/OneDrive/Desktop/"dir(OS)excel_file_list = os.listdir(input_file_path)print (excel_file_list)df = pd.DataFrame()Пример имён файлов в исходной папке:
File1_excel.xlsx
File2_excel.xlsx
File3_excel.xlsxfor excel_files in excel_file_list:
if excel_files.endswith(".xlsx"):for excel_files in excel_file_list:
if excel_files.endswith(".xlsx"):
df1 = pd.read_excel(input_file_path+excel_files)for excel_files in excel_file_list:
if excel_files.endswith(".xlsx"):
df1 = pd.read_excel(input_file_path+excel_files)
df = df.append(df1)df.to_excel(output_file_path+"Consolidated_file.xlsx")Полный фрагмент кода из исходника (сохранён как в оригинале):
#Pandas is used as a dataframe to handle Excel files
import pandas as pd
import os
# change the slash from “\” to “/”, if you are using Windows devices
input_file_path = "C:/Users/gaurav/OneDrive/Desktop/Excel files/"
output_file_path = "C:/Users/gaurav/OneDrive/Desktop/"
#create a list to store all the file references of the input folder using the listdir function from the os library.
#To see the contents of a library (like the listdir function, you can use the dir function on the library name).
#Use dir(library_name) to list contents
excel_file_list = os.listdir(input_file_path)
#print all the files stored in the folder, after defining the list
excel_file_list
#Once each file opens, use the append function to start consolidating the data stored in multiple files
#create a new, blank dataframe, to handle the excel file imports
df = pd.DataFrame()
#Run a for loop to loop through each file in the list
for excel_files in excel_file_list:
#check for .xlsx suffix files only
if excel_files.endswith(".xlsx"):
#create a new dataframe to read/open each Excel file from the list of files created above
df1 = pd.read_excel(input_file_path+excel_files)
#append each file into the original empty dataframe
df = df.append(df1)
#transfer final output to an Excel (xlsx) file on the output path
df.to_excel(output_file_path+"Consolidated_file.xlsx")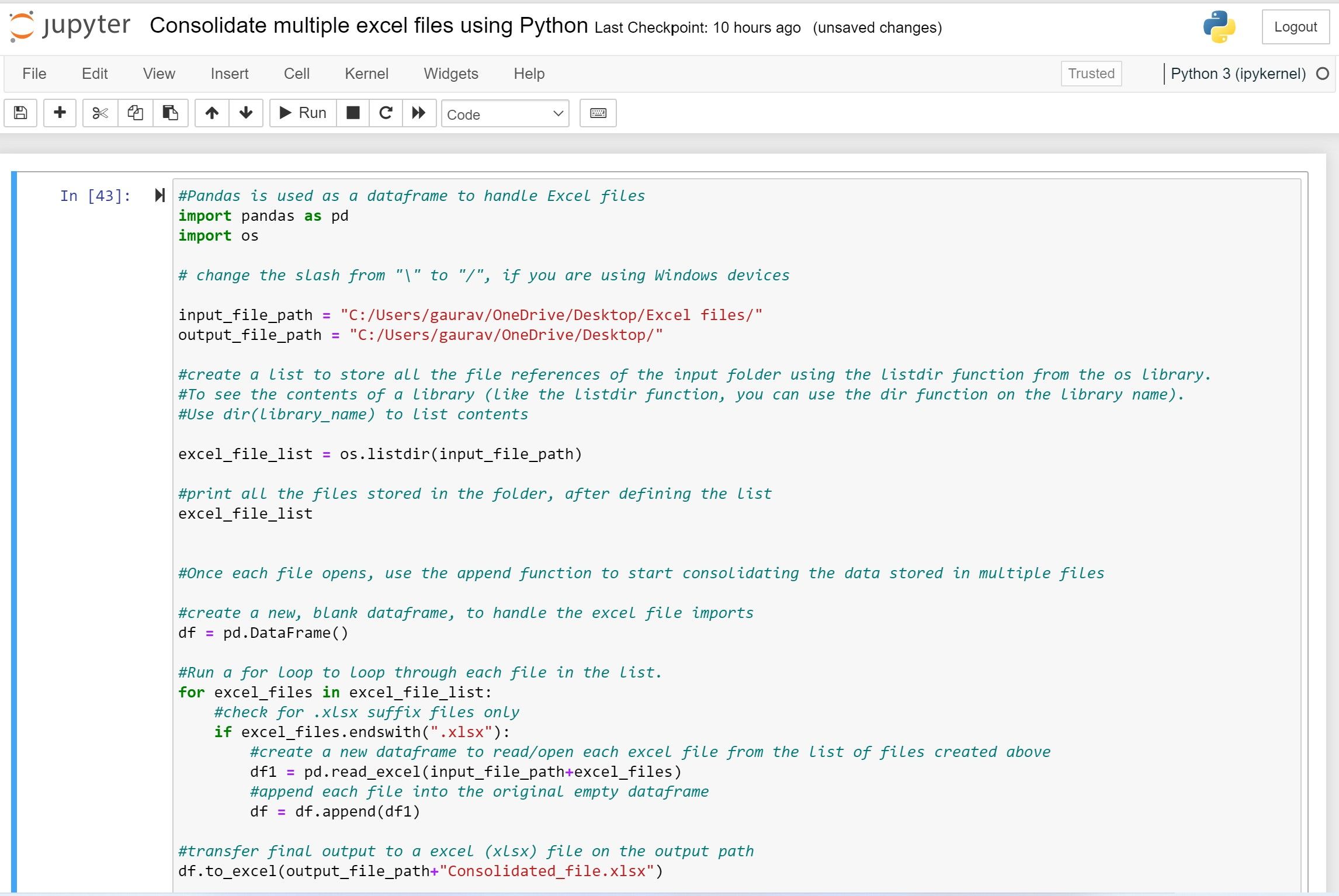
Улучшения и рекомендации
Важно понять, что код из примера работает, но его можно улучшить для стабильности, читаемости и совместимости:
- В новых версиях Pandas операция append может считаться устаревшей; предпочтительнее собирать все DataFrame в список и затем использовать pd.concat для объединения.
- Лучше использовать pathlib для работы с путями — это делает код переносимым между ОС.
- Обрабатывать возможные ошибки чтения файлов и логировать проблемные файлы.
- Явно указывать engine в pd.read_excel при необходимости (например, engine=”openpyxl”).
Ниже — более надёжный шаблон кода с обработкой ошибок и использованием pd.concat:
from pathlib import Path
import pandas as pd
input_path = Path("C:/Users/gaurav/OneDrive/Desktop/Excel files/")
output_file = Path("C:/Users/gaurav/OneDrive/Desktop/Consolidated_file.xlsx")
frames = []
for file in input_path.iterdir():
if file.suffix.lower() == ".xlsx":
try:
df = pd.read_excel(file)
frames.append(df)
except Exception as e:
print(f"Ошибка при чтении {file.name}: {e}")
if frames:
result = pd.concat(frames, ignore_index=True)
result.to_excel(output_file, index=False)
print(f"Сконсолидировано {len(frames)} файлов -> {output_file}")
else:
print("Не найдено .xlsx файлов в папке")Пояснения:
- frames — список DataFrame, которые затем конкатенируются за один вызов pd.concat (быстрее и входящая практика).
- ignore_index=True — чтобы переиндексировать строки в результирующем DataFrame.
- index=False при экспорте, чтобы не писать колонку с индексом в финальный Excel-файл.
Альтернативные подходы
- Использовать openpyxl напрямую, если нужна низкоуровневая работа с листами и форматированием.
- Конвертация в CSV с последующим объединением — полезно для простых табличных структур, где не важны форматы и формулы.
- Apache POI (через Java) или .NET-решения для специфичных корпоративных сценариев.
- Инструменты ETL (Airflow, NiFi, Talend) для непрерывной интеграции и расписаний.
Каждый подход имеет свои сильные стороны: Pandas удобнее для анализа данных, openpyxl — для редактирования формата и формул, ETL-инструменты — для масштабируемости и оркестрации.
Когда метод не сработает
- Если файлы сильно различаются по структуре (разные колонки и типы данных), простое объединение приведёт к множеству NaN и ошибок анализа.
- Если файлы очень большие (сотни тысяч строк на файл), может потребоваться построчная обработка или работа чанками (pd.read_excel не поддерживает chunking напрямую, но можно экспортировать из Excel в CSV и читать по частям).
- Если файлы защищены паролем или повреждены — Pandas не сможет их открыть без предварительной расшифровки/восстановления.
Ментальные модели и эвристики
- «Сопоставь схемы»: перед объединением проверьте, совпадают ли имена и порядок колонок.
- «Минимизируй изменения»: собирайте данные в неизменяемые списки и делайте единичную операцию объединения (pd.concat) вместо многократных append.
- «Fail fast»: валидируйте первые несколько файлов, прежде чем запускать объединение для всех.
Критерии приёмки
- Все ожидаемые файлы были прочитаны и учтены (лог/сообщение о количестве).
- Количество строк итогового файла соответствует сумме строк исходных файлов (с учётом фильтрации/дубликатов, если применимо).
- Структура колонок соответствует требуемой схеме (названия, типы данных).
- Финальный файл открывается в Excel и данные корректны.
Роль‑ориентированный чеклист для внедрения
- Аналитик:
- Проверил схемы входных файлов.
- Составил список обязательных колонок.
- Разработчик:
- Реализовал скрипт с обработкой ошибок.
- Добавил логирование и отчёт об успешных/неуспешных файлах.
- DevOps/администратор:
- Настроил расписание или триггер (если требуется автоматизация).
- Обеспечил права доступа к папке и место для вывода.
Тестовые случаи и критерии приёмки
- Тест 1: Папка с 3 корректными .xlsx — ожидается объединение и точное суммирование строк.
- Тест 2: В папке файлы с разными колонками — проверить, что итоговый DataFrame содержит union колонок и корректные NaN.
- Тест 3: Один файл повреждён — скрипт логирует ошибку и продолжает обработку других файлов.
- Тест 4: Отсутствуют .xlsx файлы — скрипт корректно сообщает об отсутствии данных.
Безопасность и приватность
- Excel-файлы часто содержат персональные данные. Обеспечьте, чтобы к папке имели доступ только уполномоченные пользователи.
- Для обработки персональных данных следуйте требованиям локального законодательства (например, в ЕС — GDPR): удаляйте или анонимизируйте PII перед распространением результирующего файла.
- Не сохраняйте временные файлы в публичных местах и удаляйте промежуточные данные после успешной обработки.
Important: если объединённый файл будет передаваться внешним сервисам, проверьте политику обмена данными и шифрование каналов передачи.
Совместимость и миграция
- Код на основе pd.concat и pathlib переносим между Windows, macOS и Linux.
- Если в вашей организации используются старые версии Pandas, проверьте, поддерживается ли pd.concat и используемые параметры. В некоторых очень старых версиях поведение read_excel или engine может отличаться.
Быстрый SOP для ежедневного использования
- Скопировать новые Excel-файлы в папку input.
- Запустить скрипт объединения (локально или как задачу по расписанию).
- Проверить лог и отчет о количестве прочитанных файлов.
- Открыть Consolidated_file.xlsx и выполнить контрольные проверки (количество строк, ключевые значения).
- Перенести итоговый файл в защищённое хранилище или запустить последующие ETL-задачи.
Шаблон команды для автоматизации (пример cron)
- В Linux добавить задачу cron, которая вызывает Python-скрипт ежедневно в 02:00.
Сводка
- Pandas даёт простой способ консолидировать Excel-файлы.
- Для производительности и надёжности предпочтительнее собирать DataFrame в список и соединять их через pd.concat.
- Обрабатывайте ошибки чтения, логируйте проблемные файлы и соблюдайте правила безопасности в отношении персональных данных.
Ключевые выводы изложены в конце:
- Простая реализация работает, но имеет ограничения по производительности и надёжности.
- Улучшенный шаблон с pathlib, pd.concat и обработкой ошибок подходит для большинства рабочих процессов.
- Добавьте проверки схемы и тестовые сценарии перед использованием в продакшене.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
