Резервное копирование в Amazon S3: руководство для дома и малого бизнеса

Amazon S3 — надёжное и гибкое объектное хранилище от AWS, подходящее для резервных копий больших объёмов данных. В статье показано, как создать аккаунт, обеспечить безопасность (MFA, IAM), создать бакет, синхронизировать данные через s3cmd или графический Cloud Explorer и настроить базовый план резервного копирования. Включены чеклисты, пример политики IAM, cron-примеры, рекомендации по выбору региона и стратегии хранения.
Ведущая компания, стоящая за CrashPlan, прекратила поддержку домашних пользователей, и многие начали искать альтернативы. Если у вас много данных для резервного копирования, Amazon Web Services (AWS) и его сервис Simple Storage Service (S3) — один из основных кандидатов. Кривая обучения кажется крутой, но на практике всё проще, чем кажется. Это руководство проведёт вас шаг за шагом: от создания учётной записи до планирования автоматического бэкапа.
Почему именно S3
S3 — это объектное хранилище, заточенное под доступ к файлам, архивирование и бэкапы. Оно не предназначено для установки ОС или запуска виртуальных машин прямо в нём, но идеально подходит для хранения снимков, фото, видео, документов и архивов.
Ключевые параметры S3, которые важно понимать:
- Безопасность и контроль доступа через IAM и политики.
- Классы хранения (storage classes) для оптимизации затрат: Standard, Infrequent Access, Reduced Redundancy и Glacier (cold storage).
- Версионирование (Versioning) для отката к предыдущим версиям файлов.
- Репликация между регионами (Cross-Region Replication) для защиты от региональных аварий.
- Гарантированная долговечность и многозональное хранение данных.
Важно: S3 — платная услуга по модели «плати за использование». Вы платите за объём хранимых данных, операции (запросы) и исходящий трафик. AWS предлагает бесплатный уровень (Free Tier) для тестирования: 5 ГБ хранения, 20 000 GET и 2 000 PUT в течение 12 месяцев.
Классы хранения и когда их использовать
- Standard — для часто используемых данных; оптимальный баланс доступности и стоимости.
- Infrequent Access (IA) — для данных, к которым обращаются редко, но требуется быстрый доступ при необходимости; дешевле хранения, дороже операций.
- Reduced Redundancy — для легко восстанавливаемых данных, где допустимы более низкая долговечность и меньшие затраты.
- Glacier / Cold Storage — для архивов и резервов, к которым обращаются крайне редко; низкая стоимость хранения, но задержки—от нескольких часов до нескольких часов (обычно 3–5 часов) при восстановлении.
Когда выбирать класс: если вы планируете часто читать/писать, выбирайте Standard. Для долгосрочного архива используйте Glacier и комбинируйте классы с lifecycle-правилами для автоматической миграции объектов.
Пример расчёта стоимости (упрощённо)
Допустим, вы хотите хранить 1 ГБ в классе Standard и выполнить 10 загрузок (PUT) за месяц. В статье-источнике пример показывает стоимость хранения порядка $0.039 за 1 ГБ в месяц и цену запроса PUT около $0.005 (примерные ориентиры регион США — Northern Virginia). AWS фактически считает операции и гигабайты отдельно, поэтому итоговая сумма складывается из хранения + количества запросов + исходящего трафика.
Совет: используйте официальный Simple Monthly Calculator (калькулятор AWS) или калькуляторы сторонних сайтов для точных прогнозов затрат по вашему сценарию.
Первые шаги: регистрация и консоль
Регистрация в AWS требует валидной банковской карты и номера телефона для верификации. После регистрации вы попадёте в AWS Management Console — единый интерфейс для всех сервисов.
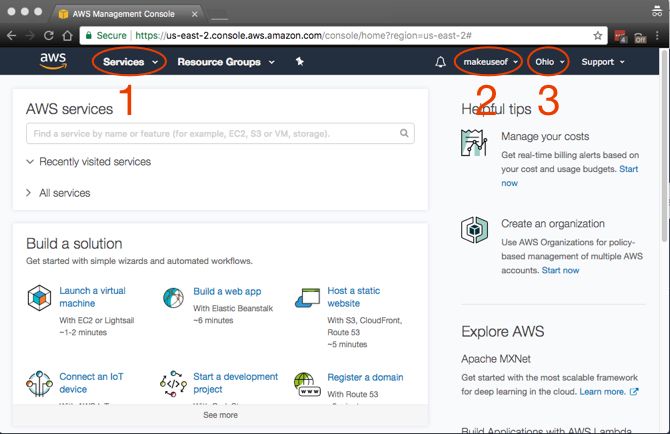
Основные элементы консоли, на которые стоит обратить внимание:
- Services — список всех сервисов AWS.
- Account — профиль и биллинг.
- Region — регион (географическое расположение) сервисов.
Подсказка по выбору региона: выбирайте ближайший регион к вашим клиентам/источникам данных для минимальной задержки и, часто, более низкой стоимости передачи данных. Однако для требований соответствия (compliance) или географической репликации выбирайте регион в другой стране.
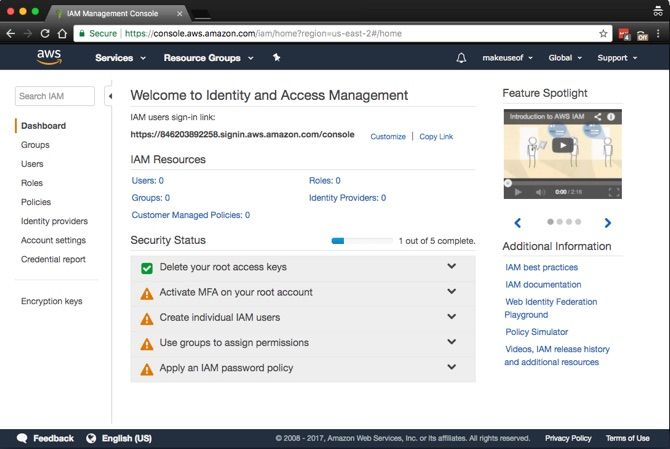
Безопасность аккаунта: MFA и базовые настройки
Прежде чем создавать пользователей и бакеты, обезопасьте root-аккаунт:
- В консоли откройте Services > Security, Identity & Compliance > IAM.
- Включите многофакторную аутентификацию (MFA) для root-аккаунта. Это повышает защиту, требуя код с мобильного приложения (например, Google Authenticator).
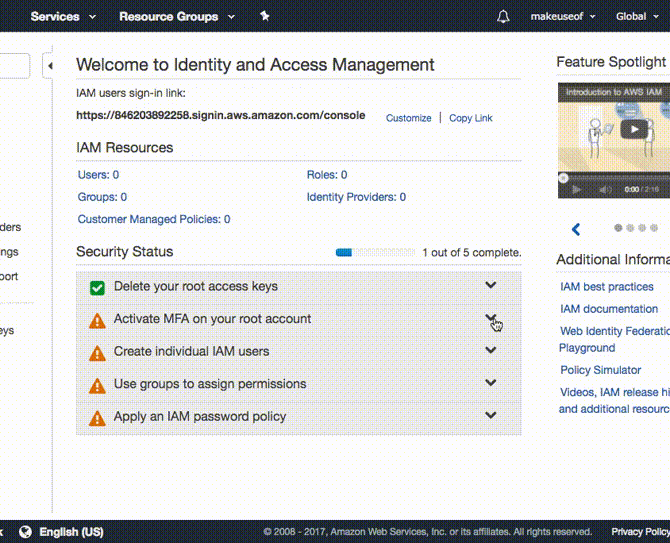
Короткая инструкция по включению виртуального MFA:
- Откройте раздел Activate MFA on your root account → Manage MFA.
- Выберите A virtual MFA device → Next Step.
- Просканируйте QR-код в Google Authenticator и введите два последовательных кода в поля Authorisation code 1 и Authorisation code 2.
- Нажмите Activate Virtual MFA.
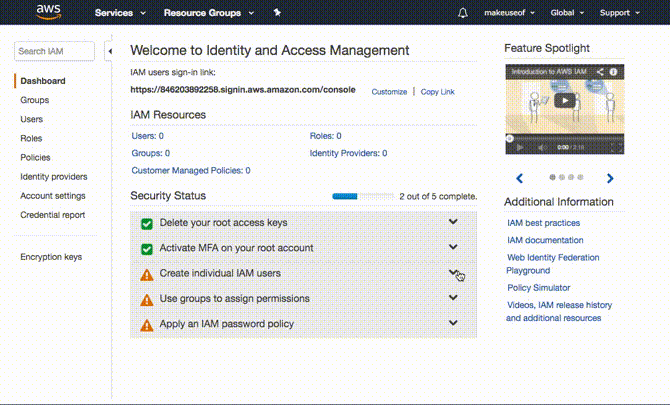
Если всё сделано правильно, в интерфейсе появится зелёная галочка — MFA активирован.
Важно: MFA защищает доступ к консоли, но для программного доступа (API) используются ключи доступа (Access key ID и Secret access key). Эти ключи храните в безопасном месте.
Пользователи, группы и политики IAM
Правильная модель доступа — не использовать root-аккаунт для автоматических бэкапов. Создавайте отдельную IAM-группу и IAM-пользователя с минимально необходимыми правами (принцип наименьших привилегий).
Процесс:
- В IAM выберите Groups → Create New Group.
- Дайте группе имя, затем на этапе Attach Policy отфильтруйте по S3 и выберите AmazonS3FullAccess или, ещё лучше, создайте кастомную политику с ограничениями только на нужные бакеты.
- Создайте пользователя: Users → Add User. Выберите Programmatic Access. Добавьте пользователя в созданную группу.
- Скачайте CSV с Access key ID и Secret access key — они будут показаны только один раз.
Ключевой совет: не храните ключи в открытом виде на машине без шифрования. Используйте менеджер секретов, файл с правами 600 или AWS Secrets Manager/SSM Parameter Store.
Пример минимальной политики (пример для одного бакета) — вставляйте и правьте под своё имя бакета:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::my-unique-bucket-name"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::my-unique-bucket-name/*"
]
}
]
}Замените my-unique-bucket-name на имя вашего бакета. Эта политика даёт доступ на перечисление содержимого бакета и работу с объектами внутри него, но не разрешает изменение настроек самого бакета.
Создание первого бакета
S3 использует концепцию бакетов. Имя бакета глобально уникально — два пользователя не могут иметь бакеты с одним и тем же именем. Имя бакета должно соответствовать правилам (обычно только строчные буквы, цифры и дефисы). Каждый бакет можно настроить индивидуально: versioning, lifecycle, encryption и т.д.
Порядок действий:
- Services > Storage > S3.
- Create bucket → введите уникальное имя (строчными буквами) → выберите регион.
- Нажмите Create.
Рекомендации при создании бакета:
- Включите Server-Side Encryption (SSE) по умолчанию для всех объектов, если ваша политика безопасности требует шифрования.
- Включите Versioning для важных данных, которые могут быть случайно перезаписаны.
- Настройте lifecycle-правила для перемещения старых данных в классы Glacier.
Работа через командную строку: s3cmd
Для пользователей Linux/Unix удобен инструмент s3cmd. Его можно установить и настроить, а затем управлять бакетами и объектами из терминала.
Установка и пример (пример для Debian/Ubuntu):
sudo apt install python-setuptools
unzip s3cmd-2.0.0
cd s3cmd-2.0.0
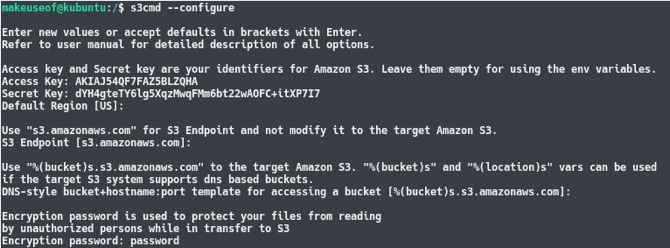
sudo python setup.py installНастройка (запустите и следуйте подсказкам):
s3cmd --configureВводите Access key ID и Secret access key, остальные опции можно оставить по умолчанию. Рекомендуется включить Encryption, если вы хотите дополнительно шифровать данные при передаче и на стороне клиента.
После настройки выполните тест:
s3cmd lsЭта команда перечислит ваши бакеты.
Синхронизация директорий через s3cmd
Команда sync очень гибкая и удобна:
s3cmd sync [LOCAL PATH] [REMOTE PATH] [PARAMETERS]Пример использования:
touch file-1.txt
touch file-2.txt
s3cmd sync ~/Backup s3://makeuseof-backupКоманда сравнивает локальную папку и удалённую и загружает отсутствующие или обновлённые файлы. Для удаления удалённых локально файлов используйте параметр –delete-removed:
rm file-1.txt
s3cmd sync ~/Backup s3://makeuseof-backup --delete-removedЭтот приём удобен для «зеркального» резервного копирования. Добавьте команду в crontab, чтобы автоматизировать:
Пример crontab для ежедневного бэкапа в 3:30 утра:
30 3 * * * /usr/bin/s3cmd sync /home/username/Backup s3://my-unique-bucket --delete-removed >> /var/log/s3-backup.log 2>&1Важно: убедитесь, что среда выполнения crontab видит те же переменные окружения и права доступа, что и ваш пользователь.
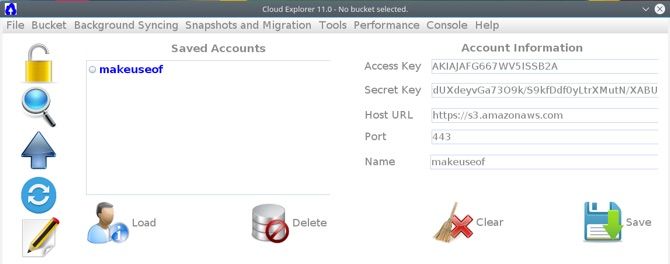
GUI-альтернатива: Cloud Explorer
Если командная строка — не ваш выбор, попробуйте Cloud Explorer. Он предоставляет интерфейс для просмотра бакетов, загрузки и синхронизации файлов. Пример установки через терминал (включает HTML-ссылку в исходном коде):
sudo apt -y install openjdk-8-headless ant git
git clone https://github.com/rusher81572/cloudExplorer.git
cd cloudExplorer
ant
cd dist
java -jar CloudExplorer.jar После запуска введите Access Key и Secret Key и сохраните профиль. Интерфейс включает: выход (Logout), поиск, загрузку, синхронизацию, текстовый редактор, список бакетов и навигацию по содержимому бакета.
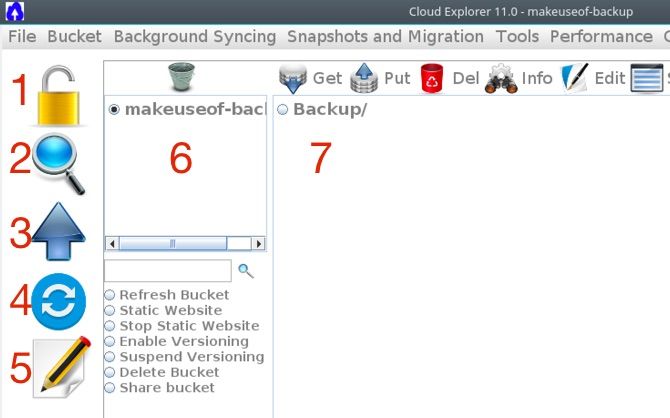
Ограничение Cloud Explorer: функция sync обычно не удаляет объекты из S3, если они удалены локально. Это может приводить к «мусорным» данным в бакете.
Настройка lifecycle-правил и архивирования
Чтобы оптимизировать расходы, используйте lifecycle-правила для автоматического перехода объектов в более дешёвые классы хранения через заданный промежуток времени.
Пример правила (логика):
- Через 30 дней с момента загрузки → перевод в Standard-IA.
- Через 365 дней → перевод в Glacier.
- Через N лет → удаление (если требуется политика жизненного цикла).
Lifecycle можно настроить в интерфейсе бакета или через JSON/инфраструктурный код. Такой подход экономит деньги на долгосрочных архивах.
Шифрование и безопасность данных
Рекомендации по безопасности хранения:
- Включите Server-Side Encryption (SSE) — либо с управлением ключей AWS (SSE-S3), либо с управлением через KMS (SSE-KMS) для лучшего контроля.
- Для дополнительной безопасности шифруйте данные на клиенте перед загрузкой (Client-Side Encryption).
- Ограничьте публичный доступ: по умолчанию не делайте бакеты публичными.
- Включите версии (Versioning) для защиты от случайного удаления/перезаписи.
- Включите аудиты доступа (CloudTrail) для критичных операций с S3.
Политика бэкапа: план и SOP
Ниже — минимальный playbook для резервного копирования домашних рабочих станций на S3.
SOP — короткий план действий:
- Создать AWS-аккаунт и включить MFA для root.
- Создать группу IAM с доступом только к конкретному бакету.
- Создать пользователя с Programmatic Access и скачать ключи.
- Создать бакет, настроить шифрование и versioning.
- Настроить s3cmd или GUI, проверить подключение и выполнить тестовую синхронизацию.
- Настроить lifecycle-правила и уведомления (SNS) при ошибках.
- Добавить задачу в crontab и настроить ротацию логов и мониторинг.
- Регулярно тестировать восстановление (restore drills).
Критерии приёмки:
- Бэкап завершился без ошибок в указанный период.
- Файлы доступны и корректны при тестовом восстановлении.
- Логи операции хранятся и доступны для аудита.
Пример короткого плана восстановления (Runbook)
- Определите последний успешный бэкап из логов /var/log/s3-backup.log.
- Используйте s3cmd get или s3cmd sync для восстановления нужных объектов:
s3cmd get s3://my-unique-bucket/path/to/file /restore/location/или
s3cmd sync s3://my-unique-bucket/path/to/folder /restore/location/- Проверить контрольную сумму и версии.
- Если объект находится в Glacier, инициировать восстановление и дождаться завершения (несколько часов).
Практические советы по экономии и мониторингу затрат
- Переносите редко используемые объекты в IA или Glacier через lifecycle.
- Минимизируйте исходящий трафик: вместо частых массовых выгрузок используйте дифф-синхронизацию.
- Используйте тегирование объектов и бакетов для отчётности по затратам.
- Настройте Billing alerts для контроля расходов.
Когда S3 не подойдёт — исключения и альтернативы
S3 отлично подходит для архивов и бэкапов, но не идеально в следующих сценариях:
- Требуется файловая система с POSIX-совместимым доступом (S3 — объектное хранилище, а не файловая система). В таких случаях рассматривайте EFS, Amazon FSx или локальные NAS.
- Нужны низкие задержки и частые случайные записи/чтение малых блоков — лучше блоковое хранилище (EBS) или специализированные файловые сервисы.
- Бюджет крайне ограничен и необходима фиксированная месячная цена — сторонние сервисы с фиксированной подпиской могут быть удобней.
Альтернативные поставщики:
- Backblaze B2 — простой ценообразование для архивов.
- Google Cloud Storage — конкурент S3 с похожими функциями.
- Microsoft Azure Blob Storage — интеграция с экосистемой Microsoft.
Сравнительная матрица (упрощённо)
- Надёжность: S3, GCS, Azure — все предлагают высокую долговечность.
- Ценообразование: зависит от региона и класса хранения; Backblaze часто дешевле для простого хранения.
- Экосистема и интеграции: AWS лидирует по количеству сервисов и готовых интеграций.
Короткая галерея крайних случаев (Edge-case gallery)
- Если вы случайно удалили данные и Versioning не включён — восстановление возможно только из доступных резервов или если объекты были реплицированы в другую систему.
- Если ключи доступа скомпрометированы — немедленно деактивируйте ключи в IAM и создайте новые.
- Если бакет стал публичным по ошибке — снимите публичный доступ и проверьте логи доступа.
Примеры сценариев: домашний пользователь и малый бизнес
Домашний пользователь:
- Нужен простой зеркальный бэкап фото/документов.
- Подходит: s3cmd sync + crontab + lifecycle → Glacier через год.
Малый бизнес:
- Нужна версия, аудит и восстановление для критичных данных.
- Подходит: Versioning + Server-Side Encryption (SSE-KMS) + CloudTrail + Cross-Region Replication.
Шаблоны и чеклисты
Чеклист безопасности при настройке бэкапа на S3:
- Root-аккаунт защищён MFA.
- Созданы IAM-группы и пользователи с минимальными правами.
- Ключи доступа сохранены безопасно и периодически ротацируются.
- Включено шифрование объектов (SSE-S3 или SSE-KMS).
- Включено Versioning для критичных бакетов.
- Настроены lifecycle-правила для экономии.
- Тестовое восстановление выполнено и задокументировано.
Роль-based checklist (администратор, пользователь, аудитор):
Администратор:
- Настроить IAM и политики, включить CloudTrail и Billing alerts.
Пользователь (оператор бэкапа):
- Настроить s3cmd/Cloud Explorer, проверить синхронизацию и логи.
Аудитор:
- Проверить шифрование, Versioning, access logs и compliance-настройки.
Decision flowchart (Mermaid)
flowchart TD
A[Нужен бэкап?] --> B{Данные часто используются?}
B -->|Да| C[Использовать Standard]
B -->|Нет| D{Доступ к данным через 30 дней?}
D -->|Да| E[Standard-IA + Lifecycle]
D -->|Нет| F[Glacier + Lifecycle]
C --> G{Требуется версия?}
G -->|Да| H[Включить Versioning]
G -->|Нет| I[Versioning не нужен]
H --> J[Настроить тестовое восстановление]
I --> JКраткая терминология (1-строчная)
- S3: объектное хранилище AWS.
- Bucket: контейнер для объектов в S3.
- Object: файл в S3.
- Lifecycle: правила управления жизненным циклом объектов.
- Versioning: хранение версий объектов.
- MFA: многофакторная аутентификация.
Примеры тестов и критерии приёмки
Тест 1 — базовый бэкап и восстановление:
- Действие: синхронизировать каталог в бакет.
- Критерии: все файлы появились в бакете; контрольная сумма совпадает.
Тест 2 — удаление и синхронизация с параметром –delete-removed:
- Действие: удалить локальный файл и выполнить sync с –delete-removed.
- Критерии: файл удалён из бакета.
Тест 3 — восстановление из Glacier:
- Действие: перевести объект в Glacier через lifecycle, инициировать восстановление.
- Критерии: объект восстановлен после ожидания времени восстановления.
Проблемы и способы их решения
Проблема: s3cmd не видит бакеты или выдаёт ошибку авторизации. Решение: проверьте Access key ID / Secret access key, убедитесь, что пользователь в нужной группе и политика даёт доступ к указанному бакету.
Проблема: высокие счета за операции. Решение: минимизируйте количество PUT/GET, используйте multipart-загрузки для больших файлов и lifecycle-правила для долгосрочного хранения.
Проблема: данные слишком чувствительны. Решение: используйте клиентское шифрование перед отправкой или SSE-KMS с управлением ключами.
Примечания по конфиденциальности и соответствию (GDPR и проч.)
Если вы храните персональные данные граждан ЕС, убедитесь, что политика хранения и регион соответствуют требованиям GDPR. Рассмотрите хранение данных в регионе ЕС и настройку прав доступа и шифрования. Документируйте срок хранения и процедуры удаления персональных данных.
Заключение и основные выводы
S3 — мощный инструмент для резервного копирования как для домашних пользователей, так и для малого бизнеса. Он предлагает гибкость по уровням хранения, интеграции с экосистемой AWS и инструменты для автоматизации. Ключевые моменты при развертывании:
- Всегда защищайте root-аккаунт и используйте MFA.
- Применяйте принцип наименьших привилегий через IAM.
- Включайте шифрование и versioning для критичных данных.
- Настройте lifecycle для экономии на долгосрочном хранении.
- Регулярно тестируйте восстановление данных.
Notes
- Не забывайте про логи и мониторинг расходов.
- Тестовое восстановление — обязательная часть процесса.
Вопрос к читателям: используете ли вы AWS для резервного копирования? Какой провайдер облачного хранения вы предпочитаете и по каким причинам? Оставьте комментарий ниже.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
