Поиск нескольких строк с помощью grep в Linux
TL;DR
grep — лёгкий и мощный инструмент для поиска текста в файлах. Чтобы искать сразу несколько строк, используйте расширенные регулярные выражения: например, grep -E ‘word1|word2’ файл. Для больших проектов удобнее -F (fixed strings), -f (файл с шаблонами), рекурсия -r и альтернативы вроде ripgrep для скорости.
Что такое grep
grep — это утилита командной строки в Unix/Linux для поиска строк, соответствующих шаблону. Коротко: вводите шаблон, указываете файлы — получаете строки с совпадениями.
Как искать несколько строк — базовый пример
Чтобы найти строки, содержащие одно из нескольких слов, используйте оператор «или» в регулярном выражении. Пример:
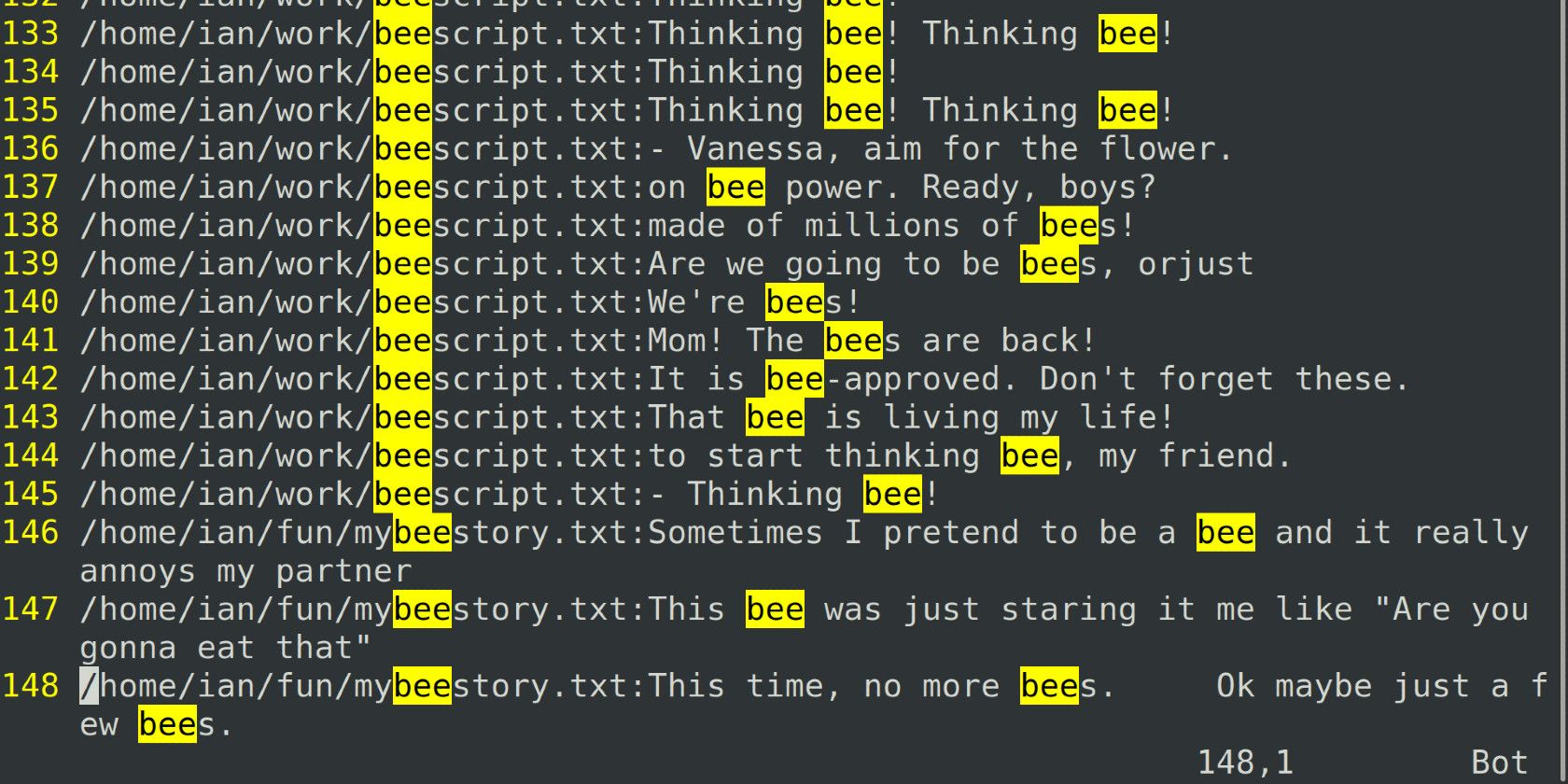
grep -E 'bee|Vanessa' ~/work/beescript.txtРазбор:
- -E — включить расширенные регулярные выражения (ERE), чтобы писать
|для «или». - ‘bee|Vanessa’ — шаблон: либо “bee”, либо “Vanessa”.
- ~/work/beescript.txt — файл для поиска.
Этот вызов вернёт все строки, где встречается любое из слов.
Полезные опции и расширения
Ниже — набор часто используемых опций, которые повышают удобство и точность поиска.
- -i — нечувствительность к регистру.
- -w — целые слова (например, “bee” не совпадёт с “beef”).
- -n — показывать номера строк.
- -H — показывать имя файла (полезно при поиске по нескольким файлам).
- -r или -R — рекурсивный поиск в каталоге.
- -F — искать фиксированные строки (быстрее, без регулярных выражений).
- -f patterns.txt — загрузить шаблоны из файла (каждая строка — отдельный шаблон).
- -P — использовать Perl-совместимые регулярные выражения (не во всех реализациях гарантировано).
Примеры расширенного использования:
# Искать в нескольких файлах и показать номера строк
grep -nE 'bee|Vanessa' ~/work/beescript.txt ~/fun/mybeestory.txt
# Рекурсивный поиск по папке, игнорировать регистр
grep -riE 'bee|Vanessa' ~/projects/bee-archive
# Использовать файл с шаблонами (один шаблон на строку)
grep -F -f ~/work/patterns.txt ~/documents/*.txt
# Показать только имена файлов, где есть совпадение
grep -lE 'bee|Vanessa' ~/projects/**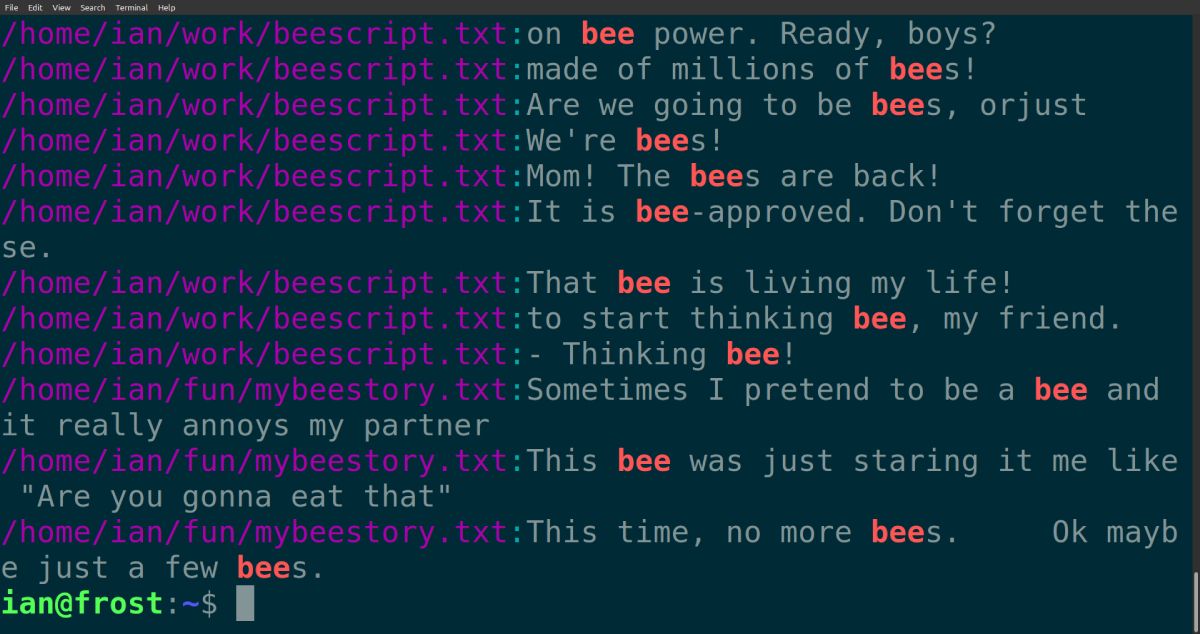
Навигация и вывод результатов
Результаты можно просмотреть удобнее или сохранить:
# Пролистывать результат
grep -E 'bee|Vanessa' ~/work/beescript.txt ~/fun/mybeestory.txt | less
# Сохранить результат в файл
grep -E 'bee|Vanessa' ~/work/beescript.txt ~/fun/mybeestory.txt > beeresults.txtless позволяет прокручивать вывод, искать по результатам и копировать фрагменты.
Когда grep не подходит и альтернативы
grep очень полезен, но у него есть лимиты:
- Большие кодовые базы/логи: может быть медленным при сканировании сотен гигабайт.
- Сложные шаблоны с lookaround: лучше использовать -P или Perl/awk.
- Поиск бинарных/сжатых файлов: нужны специализированные инструменты.
Альтернативы:
- ripgrep (rg) — быстрый и удобный для больших деревьев файлов.
- The Silver Searcher (ag) — быстрый, ориентирован на код.
- awk/sed — когда нужно не только искать, но и обрабатывать строки.
Рекомендации по производительности
- Используйте -F для поиска по фиксированным строкам — это быстрее, чем регулярки.
- Обходите большие бинарные файлы — добавляйте –binary-files=without-match.
- Ограничьте области поиска с помощью –include/–exclude и find + xargs, чтобы не сканировать всё подряд.
Пример с find + xargs:
find ~/projects -type f -name '*.txt' -print0 | xargs -0 grep -nE 'pattern1|pattern2'Файлы шаблонов и управление сложными паттернами
Если шаблонов много, поместите их в файл patterns.txt — один шаблон на строку:
bee
Vanessa
nectar
"hive"И затем:
grep -F -f patterns.txt -n ~/work/**/*.txtДля случаев, когда шаблоны содержат спецсимволы regex, -F решает проблему, ищет буквально.
Модель принятия решения: -E vs -F vs -P
- Используйте -F, когда ищете чистые строки (без рег. выражений) — это быстрее и безопаснее.
- Используйте -E для простых регулярных выражений (|, +, ?). Это удобно и переносимо.
- Используйте -P, если нужны Perl-совместимые фичи (lookahead/lookbehind), но проверяйте поддержку.
flowchart TD
A[Нужен поиск] --> B{Шаблон содержит спецсимволы?}
B -- Нет --> C[Использовать -F]
B -- Да --> D{Требуются сложные конструкции?}
D -- Нет --> E[Использовать -E]
D -- Да --> F[Использовать -P или ripgrep/awk]Чек-лист по роли
Разработчик:
- Проверить -n и -H для отладки.
- Использовать –include для фильтра типов файлов.
- Предпочесть ripgrep для больших репозиториев.
Системный администратор:
- Искать по логам с –binary-files=without-match.
- Использовать find + xargs для контроля зон поиска.
- Автоматизировать в скриптах с проверкой кода возврата.
Аналитик данных:
- Использовать -o для вывода только совпадений (если нужно подсчитать).
- Экспортировать результаты в CSV через awk при необходимости.
Примеры тест-кейсов и критерии приёмки
Критерии приёмки:
- grep возвращает все строки, содержащие хотя бы один из шаблонов.
- Номера строк и имена файлов отображаются при поиске по нескольким файлам.
- Для большого каталога время выполнения укладывается в приемлимый порог (определяется командой).
Тест-кейсы:
- Файл с известными строками — grep находит все ожидаемые совпадения.
- Несколько файлов — grep -l находит только файлы с совпадениями.
- Шаблоны со спецсимволами — проверка с -F и без, чтобы убедиться в поведении.
Подсказки по безопасности и приватности
- При поиске логов следите за правами доступа: не выводите в открытый файл конфиденциальные данные.
- Не сохраняйте постоянные результаты поиска в общедоступные каталоги.
Быстрый справочник (cheat sheet)
- grep -E ‘a|b’ file — несколько вариантов через |.
- grep -F -f patterns.txt files — шаблоны из файла, поиск буквальный.
- grep -riE ‘error|fail’ /var/log — рекурсивный нечувствительный поиск.
- rg ‘error|fail’ — альтернатива (очень быстро для больших деревьев файлов).
Когда следует делать откат или другой инструмент
Если grep слишком медленный или шаблоны слишком сложны, используйте ripgrep или напишите скрипт на Python/Perl/awk для постобработки и фильтрации.
Краткое резюме
grep остаётся базовым и надёжным инструментом для поиска текста. Для поиска нескольких строк используйте | в ERE или файл с шаблонами. Для больших объёмов данных рассматривайте -F, фильтрацию по включению/исключению и современные альтернативы вроде ripgrep.
Важно: начинайте с простых опций, проверяйте результаты на небольшом наборе файлов, а затем масштабируйте поиск.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
