Проверка доступности сайтов на Python

Если вы часто получаете данные с веб-сайтов, имеет смысл автоматизировать проверку их доступности. Такая автоматизация полезна, когда у сайтов нет официального API или когда нужно быстро понять, упал ли сервис. Python — удобный язык для таких задач: синтаксис краткий и понятный, а сторонние библиотеки дают готовые инструменты для работы с HTTP.
Что делает этот пример
- Поддерживает проверку списка сайтов.
- Преобразует HTTP-коды в понятные сообщения.
- Демонстрирует базовую обработку ошибок.
Важно: код в примерах предназначен для демонстрации. Для боевого использования добавьте таймауты, логирование, повторные попытки и уведомления.
Необходимые зависимости
Установите requests, если ещё не установлена:
pip install requestsИмпорт библиотек
import requestsБиблиотека requests используется для отправки HTTP-запросов и получения ответов от сайтов.
Хранение URL-адресов в списке
Пример исходного списка сайтов из оригинала:
import requests
website_url = [
"https://www.google.co.in",
"https://www.yahoo.com",
"https://www.amazon.co.in",
"https://www.pipsnacks.com/404",
"http://the-internet.herokuapp.com/status_codes/301",
"http://the-internet.herokuapp.com/status_codes/500"
]Переменная website_url хранит список строк — URL, которые вы хотите проверить. Вы можете заменить примеры на свои адреса.
Сопоставление кодов состояния и сообщений
Чтобы вместо числовых кодов видеть понятные статусы, используйте словарь:
statuses = {
200: "Website Available",
301: "Permanent Redirect",
302: "Temporary Redirect",
404: "Not Found",
500: "Internal Server Error",
503: "Service Unavailable"
}Вы можете локализовать сообщения на русский или расширить словарь под ваши нужды.
Простейший цикл проверки (из исходного примера)
for url in website_url:
try:
web_response = requests.get(url)
print(url, statuses[web_response.status_code])
except:
print(url, statuses[web_response.status_code])Пояснения:
- Цикл for проходит по списку URL.
- try/except ловит исключения. В исходном примере обработка исключения повторно пытается обратиться к web_response — это может привести к ошибке, если запрос не удался и web_response не определён.
Важно: никогда не используйте голый except без фильтрации ошибок. Это скрывает реальные проблемы.
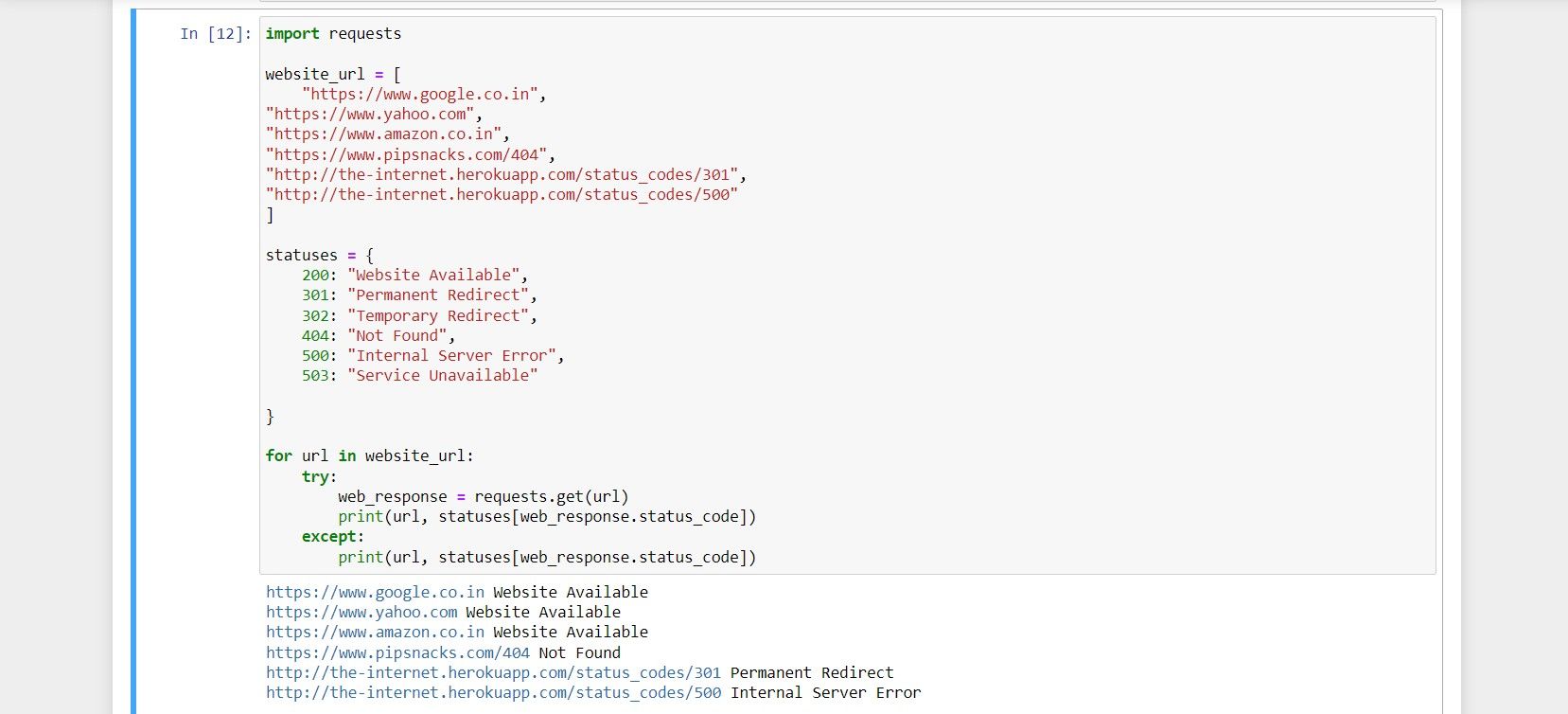
Полный исходный код (как в оригинале)
import requests
website_url = [
"https://www.google.co.in",
"https://www.yahoo.com",
"https://www.amazon.co.in",
"https://www.pipsnacks.com/404",
"http://the-internet.herokuapp.com/status_codes/301",
"http://the-internet.herokuapp.com/status_codes/500"
]
statuses = {
200: "Website Available",
301: "Permanent Redirect",
302: "Temporary Redirect",
404: "Not Found",
500: "Internal Server Error",
503: "Service Unavailable"
}
for url in website_url:
try:
web_response = requests.get(url)
print(url, statuses[web_response.status_code])
except:
print(url, statuses[web_response.status_code]) И пример вывода (фрагмент из Jupyter):
Улучшенная и безопасная реализация
Ниже — более надёжный вариант с таймаутом, пользовательским заголовком, обработкой исключений и запасным сообщением для неизвестных кодов.
import requests
from requests.exceptions import RequestException, Timeout
website_url = [
"https://www.google.co.in",
"https://www.yahoo.com",
"https://www.amazon.co.in",
"https://www.pipsnacks.com/404",
]
statuses = {
200: "Доступен",
301: "Постоянное перенаправление",
302: "Временное перенаправление",
404: "Не найден",
500: "Внутренняя ошибка сервера",
503: "Сервис недоступен",
}
headers = {"User-Agent": "SiteChecker/1.0 (+https://example.com)"}
def check_site(url, timeout=5):
try:
r = requests.get(url, headers=headers, timeout=timeout)
message = statuses.get(r.status_code, f"Код {r.status_code}")
return True, r.status_code, message
except Timeout:
return False, None, "Таймаут запроса"
except RequestException as e:
return False, None, f"Ошибка сети: {e.__class__.__name__}"
for url in website_url:
ok, code, message = check_site(url)
if ok:
print(url, code, message)
else:
print(url, message)Ключевые улучшения:
- Таймаут защищает от долгих зависаний.
- Заголовок User-Agent уменьшает риск блокировки как «бота».
- Конкретные исключения помогают понять причину отказа.
Асинхронный подход для больших списков
Если нужно проверять сотни сайтов регулярно, синхронные запросы будут медленными. Асинхронный aiohttp позволяет запускать много одновременных запросов и экономить время.
Примерный план:
- Использовать aiohttp и asyncio.
- Ограничить параллелизм семафором.
- Собрать результаты в один JSON/CSV.
(Подробный код для aiohttp не включён, чтобы не удлинять статью; при необходимости могу добавить.)
Когда этот подход не сработает
- Сайт защищён Cloudflare/капчей и возвращает страницу, а не стандартный HTTP-код.
- Сервер использует блокировку по User-Agent или по частоте запросов.
- Сайт отвечает, но сервис на нём нефункционален (например, возвращает 200, но страница пустая).
В таких случаях дополните проверку: валидируйте тело ответа, проверяйте ключевые элементы HTML или делайте тестовые запросы к API-эндпоитам.
Рекомендации по надёжности
- Добавьте повторные попытки с экспоненциальной задержкой.
- Логируйте результаты в файл или систему мониторинга.
- Интегрируйте уведомления (email, Slack, SMS) для ошибок.
- Учитывайте политике robots.txt и правила сайта.
Чек-лист для внедрения (роль: разработчик / оператор)
- Разработчик:
- Добавил таймаут и обработку исключений.
- Настроил User-Agent.
- Реализовал локальную проверку тела ответа.
- Оператор:
- Настроил расписание (cron или планировщик).
- Подключил логирование и ретеншн логов.
- Настроил уведомления для критических статусов.
Простая методология проверки (мини-метод)
- Сформировать список критичных URL.
- Проверить базовый HTTP-статус (200/3xx/4xx/5xx).
- При успехе проверить наличие ключевых элементов в теле.
- При ошибке — попытка повтора и уведомление.
- Собирать метрики (время ответа, частота ошибок).
Критерии приёмки
- Скрипт возвращает понятные сообщения для каждого URL.
- Таймаут настроен и защищает от долгих ожиданий.
- Ошибки сети не приводят к падению приложения.
- Логи сохраняются и доступны для анализа.
Итог
Проверка доступности сайтов на Python — простая задача, которую стоит автоматизировать. Начните с базового примера requests, затем добавьте таймауты, обработку исключений и логирование. Для больших объёмов подумайте об асинхронности и внешних системах мониторинга.
Ключевые действия: добавьте таймаут, используйте корректные исключения, логируйте и оповещайте команду при сбоях.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
