Как пользоваться Performance Monitor в Windows

В этой статье вы найдёте пошаговое руководство по запуску Performance Monitor, выбору и интерпретации счётчиков, созданию и расписанию Data Collector Set, анализу собранных логов и практические шаблоны и чек‑листы для разных ролей. В конце — методика диагностики, когда инструмент не помогает, альтернативы и готовые рекомендации по ускорению системы.
Почему стоит использовать Performance Monitor
Performance Monitor — это не один график из Диспетчера задач. Это гибкий фреймворк для точечного сбора множества метрик с высокой частотой выборки. Он полезен в трёх основных сценариях:
- Когда нужно записать поведение системы под рабочей нагрузкой и потом проанализировать причины замедлений.
- Когда требуется регулярный сбор данных в фоне для выявления трендов и редких аномалий.
- Когда нужно correlating (коррелировать) поведение разных подсистем, например: рост использования памяти + пики диска + высокая задержка сети.
Кратко: если вы хотите ответить на вопрос «почему этот компьютер работает медленно именно сейчас или в определённый период», Performance Monitor часто даст необходимые данные.
Important: Performance Monitor фиксирует состояние. Он помогает найти причины, но не всегда автоматически исправляет проблемы.
Как запустить Performance Monitor
Есть несколько способов открыть Performance Monitor в Windows 10 и Windows 11. Выберите тот, который вам удобен:
- Через поиск Windows: откройте меню «Пуск», введите performance monitor и запустите приложение Desktop App.
- Через Панель управления: Система и безопасность → Административные инструменты → Performance Monitor.
- Через окно Выполнить: Windows + R → perfmon → OK.
- Через Командную строку: откройте CMD → perfmon → Enter.
- Через PowerShell: запустите PowerShell → perfmon → Enter.
После запуска не пугайтесь интерфейса — он функционален, но требует небольшого обучения.
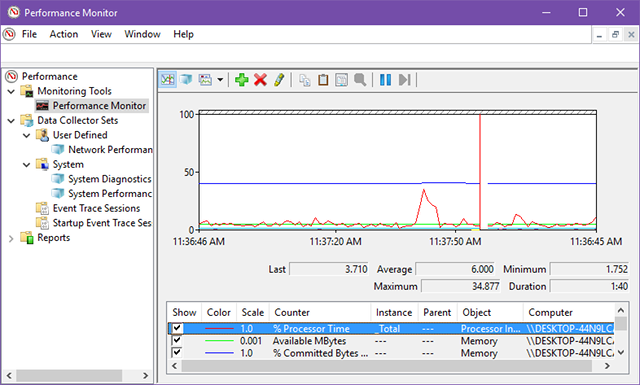
1. Что можно мониторить
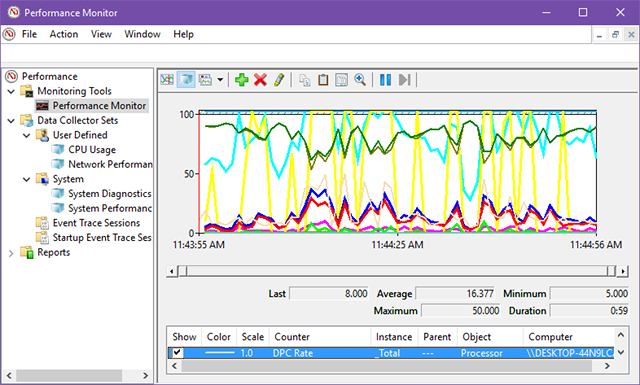
По умолчанию Performance Monitor показывает один счётчик: Processor Time. Это процент использования CPU. Но инструмент поддерживает сотни счётчиков. Каждый счётчик относится к категории — например, Memory, PhysicalDisk, Network Interface.
Ниже — часто используемые счётчики и краткое объяснение, что за ними стоит и как интерпретировать значения:
- Memory | % Committed Bytes in Use — процент используемой выделенной виртуальной памяти. Постепенный рост может указывать на утечку памяти.
- Network Interface | Bytes Total/sec — байты в секунду на интерфейсе. Если близко к пропускной способности физического канала, возможны узкие места в сети.
- Paging File | % Usage — загрузка файла подкачки. Высокая и постоянная загрузка говорит о нехватке ОЗУ.
- Physical Disk | % Disk Time — процент времени диска, занятый обработкой запросов. Долго высокий показатель — повод перейти на SSD.
- Physical Disk | % Disk Read Time — процент времени при чтении.
- Physical Disk | % Disk Write Time — процент времени при записи.
- Processor | % Interrupt Time — время процессора, затрачиваемое на прерывания от оборудования. Высокие значения (обычно >10–20%) могут указывать на проблемный драйвер или аппаратный дефект.
- Thread | % Processor Time — использование процессора отдельным потоком. Полезно при анализе поведения конкретных потоков приложения.
Совет: счётчики организованы по категориям. Удобно добавлять целые категории или отдельные счётчики в Data Collector Set.
Pro Tip: можно создавать собственные пользовательские счётчики через .NET или PowerShell, если стандартных метрик недостаточно.
2. Создание Data Collector Set
Data Collector Set — это шаблон или группа счётчиков и конфигураций для периодического или разового сбора данных. Идея проста: собрать набор метрик, сохранить его и запускать по расписанию.
Преимущества:
- Быстрый запуск заранее настроенного набора счётчиков.
- Сбор данных в файл для последующего анализа.
- Автоматический запуск по расписанию или условию.
Как создать простой Data Collector Set:
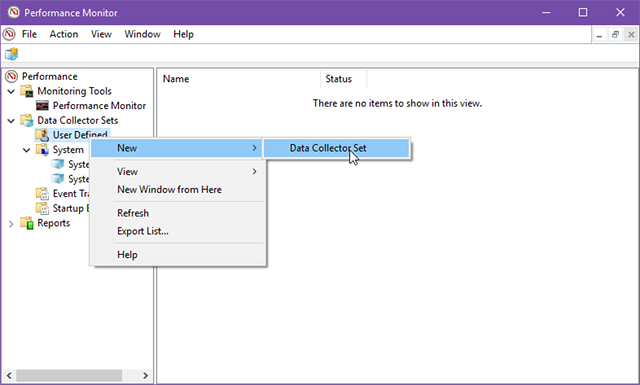
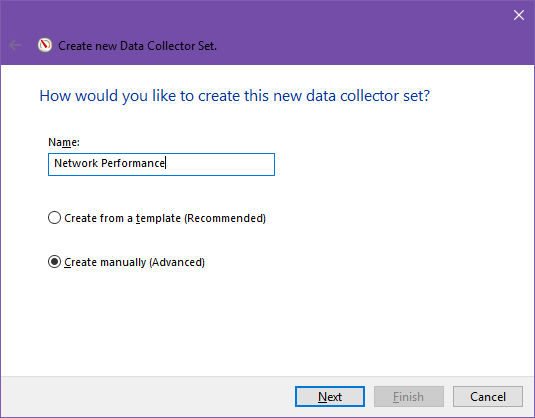
- В боковой панели правой кнопкой мыши кликните Data Collector Sets → User Defined → New → Data Collector Set.
- Дайте имя (например, Network Performance, Memory Leaks). Выберите Create manually (Advanced) и нажмите Next.
- Выберите Create data logs → Performance counter и Next.
- Нажмите Add…, выберите нужные счётчики и добавьте их.
- Очень важно: установите Sample Interval = 1 second (или другую частоту по задаче). Короткий интервал фиксирует кратковременные пики.
- Укажите папку для сохранения логов (.BLG формата), по умолчанию OK.
- Выберите пользователя, под которым будет работать набор (по умолчанию — текущая система). Сохраните и закончите.
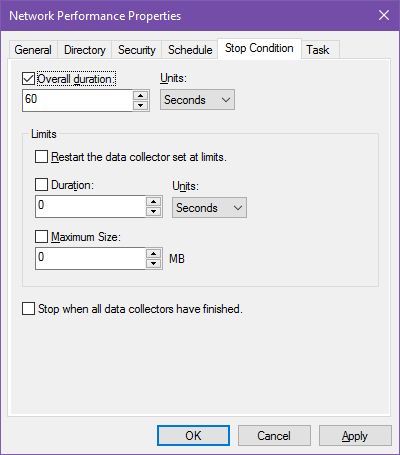
Установка времени выполнения
Чтобы задать, сколько времени набор должен собирать данные, откройте свойства набора и перейдите на вкладку Stop Condition. Установите Overall duration, например 60 seconds или 1 hour. Это полезно для одноразовых сессий сбора.
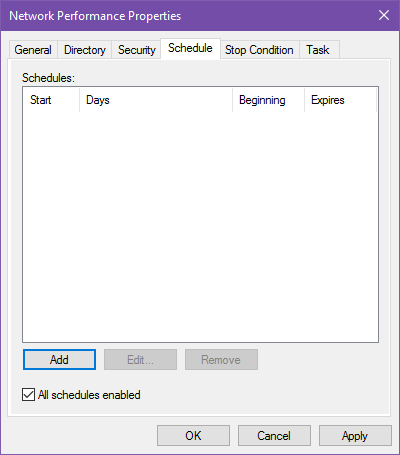
Планирование автоматического запуска
Перейдите в свойства набора → вкладка Schedule. Здесь можно добавить одно или несколько расписаний. Каждый триггер задаёт дату начала, дни недели и время.
Пример: Schedule 1 — суббота 03:30, Schedule 2 — среда 09:00. Набор будет запускаться в заданные моменты сам по себе.
3. Просмотр и анализ данных
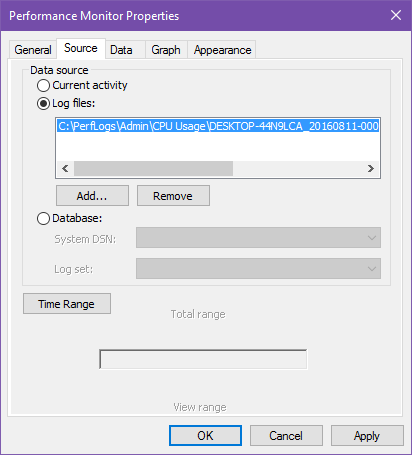
Когда Data Collector Set завершил сбор, результат сохраняется в файл .BLG. Чтобы визуализировать данные:
- Выберите Performance Monitor в боковой панели.
- Нажмите View Log Data в тулбаре.
- На вкладке Source укажите Log files → Add → выберите .BLG файл.
- На вкладке Data нажмите Add и выберите счётчики из логов, которые хотите отобразить.
- Нажмите Apply → OK.
Форматы отображения данных
Данные можно просматривать в пяти форматах. Каждый формат удобен в разных случаях:
- Lines — временные ряды, подходит для детального просмотра пиков и всплесков.
- Histograms — гистограммы распределения значений, полезно для оценки стабильности метрик.
- Reports — табличные отчёты с агрегатами (min/max/avg), удобны при формировании отчётов.
- Areas — залитые графики, хорошо отображают совокупное влияние нескольких счётчиков.
- Stacked — стековые диаграммы, показывают вклад каждого счётчика в общий объём.
Когда Performance Monitor помогает, а когда нет
Performance Monitor отлично подходит для системной диагностики, но не является универсальным лечением. Ниже — сценарии, когда инструмент эффективен, и когда нужно смотреть в другую сторону.
Когда помогает:
- Пики CPU/IO/Memory, которые можно связать с конкретным процессом или временем.
- Повторяющиеся или редкие события, которые можно поймать, запустив набор с нужной частотой.
- Сложные проблемы, где нужно correlating поведение нескольких подсистем.
Когда не поможет:
- Если проблема связана с пользовательским опытом, а не с системными ресурсами (например, неудобный интерфейс приложения).
- Если сбой происходит на уровне аппаратного контроля, недоступного через счётчики (редкие аппаратные ошибки, требующие специальных утилит производителя).
- Если нужные счётчики не собираются по политике безопасности или ограничению прав.
Note: в ситуациях с подозрением на вредоносное ПО лучше сочетать PerfMon с антивирусными сканерами и инструментами анализа сетевого трафика.
Альтернативные инструменты
Если PerfMon не покрывает ваши требования, рассмотрите:
- Windows Resource Monitor — проще, но с удобным отображением процессов и дескрипторов.
- Event Viewer — для изучения логов системы и приложений.
- Sysinternals Suite (Process Explorer, Process Monitor) — для глубокого анализа процессов и системных вызовов.
- Wireshark — для детального анализа сетевого трафика.
- Производительские утилиты для дисков и материнских плат — для S.M.A.R.T., диагностики контроллеров.
Каждый инструмент дополняет PerfMon, но не всегда заменяет его.
Практическая методика диагностики (мини‑методология)
Используйте этот упрощённый процесс для системного расследования производительности:
- Сформулируйте гипотезу кратко: что не так, когда и при каких условиях.
- Определите набор счётчиков, которые подтверждают или опровергнут гипотезу.
- Настройте Data Collector Set с частотой как минимум 1 секунда при исследовании всплесков.
- Запустите набор в нужный период, или запланируйте запуск.
- Проанализируйте .BLG в режиме Lines и Reports. Сравните пиковые моменты с логами приложений и событий.
- Сформируйте вывод и действия: патч драйвера, добавление RAM, настройка индексации, смена диска на SSD.
- Повторите проверку после внесённых изменений.
Эта методика сокращает время от симптомов до решения.
Шпаргалка по счётчикам и их интерпретации
Ниже — быстрый cheat sheet для повседневных задач. Используйте как шаблон при создании наборов.
- Узкие места CPU: Processor | % Processor Time, Processor | % Interrupt Time, Processor | Queue Length.
- Узкие места памяти: Memory | % Committed Bytes in Use, Memory | Available MBytes, Paging File | % Usage.
- Узкие места диска: PhysicalDisk | % Disk Time, PhysicalDisk | Avg. Disk sec/Read, PhysicalDisk | Avg. Disk sec/Write.
- Узкие места сети: Network Interface | Bytes Total/sec, TCPv4 | Segments/sec.
- Проблемы с индексом поиска/поисковой службой: Service | % Processor Time (для SearchIndexer), Process | Handle Count.
Шаблон набора для быстрого старта (рекомендуемые счётчики):
- Processor | % Processor Time (для всех логических процессоров)
- Memory | Available MBytes
- Memory | % Committed Bytes in Use
- PhysicalDisk(*) | % Disk Time
- PhysicalDisk(*) | Avg. Disk sec/Read
- PhysicalDisk(*) | Avg. Disk sec/Write
- Network Interface(*) | Bytes Total/sec
(*) — добавьте по каждому физическому диску/интерфейсу.
Ролевые чек‑листы (кто что должен сделать)
Администратор инфраструктуры:
- Настроить постоянный Data Collector Set для серверов (ежедневно/еженедельно).
- Хранить логи минимум 30 дней для ретроспективного анализа.
- Автоматизировать оповещения при превышении порогов.
Специалист техподдержки:
- При обращении пользователя запустить Data Collector Set с преднастроенным профилем.
- Сопоставить временной штамп замедления с логами событий и PerfMon.
- Сформировать отчёт с графиками и рекомендациями для администратора.
Разработчик приложения:
- Добавить мониторинг критичных потоков и памяти в тестовую среду.
- Сравнить профили нагрузки локально и на проде с идентичными счётчиками.
- Предоставить список подозрительных потоков и их идентификаторы.
Playbook: от симптома до решения
- Получили репорт: «ПК тормозит в 15:00».
- Настроили Data Collector Set с частотой 1s и счётчиками CPU, Memory, Disk, Network.
- Запланировали запуск на 14:50–15:05 (Stop condition = 15 min).
- После окончания загрузили .BLG в Performance Monitor и визуализировали Lines и Reports.
- Найдены пики Disk Avg. sec/Read > 30 ms в момент замедления.
- Дальше: проверили S.M.A.R.T. диска и замерили IOPS. Сделали вывод — диск HDD не справляется, рекомендован переход на SSD.
- После замены диска повторили замеры и законтролировали улучшение.
Этот playbook можно превратить в SOP в вашей организации.
Критерии приёмки
- Собранные логи покрывают период замедления с частотой не более 1 s между замерами.
- Для подтверждения узкого места есть по крайней мере два коррелирующих счётчика (например, высокий CPU и очередь процессора).
- По итогам выполненных действий наблюдается явное снижение целевых метрик (например, Avg. Disk sec/Read снизился с 40 ms до <10 ms).
Диагностическое дерево решений
flowchart TD
A[Проблема: ПК работает медленно] --> B{Есть ли явные ошибки в Event Viewer?}
B -- Да --> C[Исследовать логи событий и устранить ошибки]
B -- Нет --> D{Наблюдаются ли пиковые нагрузки?}
D -- Да --> E[Запустить Data Collector Set с 1s sample interval]
D -- Нет --> F[Провести базовый бенчмарк и тесты железа]
E --> G{Пиковые счётчики: CPU/Memory/Disk/Network}
G --> |CPU| H[Проанализировать процессы: Process Explorer, Thread %]
G --> |Disk| I[Проверить S.M.A.R.T., Avg. Disk sec/Read/Write, рассмотреть SSD]
G --> |Memory| J[Проверить утечки, увеличить RAM или оптимизировать приложения]
G --> |Network| K[Запустить сетевой анализатор: Wireshark, проверить пропускную способность]
H --> L[Внести исправления и повторно замерить]
I --> L
J --> L
K --> L
F --> M[Запустить стресс‑тесты, заменить проблемные компоненты]
L --> N[Проверка: улучшение метрик — закрыть тикет]
N --> O[Нет улучшения — escalation к поставщику/разработчику]Тестовые случаи и критерии приёмки
Примеры тесткейсов, которые можно использовать при валидации решений:
- Тест 1: Нагрузить CPU 100% на минуту; проверить, что Processor | % Processor Time корректно отображает пик.
- Тест 2: Запустить чтение/запись диска (fio/CrystalDiskMark); убедиться, что Avg. Disk sec/Read/Write отражают задержки.
- Тест 3: Искусственно увеличить потребление памяти приложением до 80% и проверить Memory | % Committed Bytes in Use.
Критерии приёмки: визуализация пиков в логах и устойчивое снижение после вмешательства.
Безопасность и приватность
- Логи .BLG могут содержать данные о запущенных процессах и временных метках. Храните их в защищённом хранилище.
- Не пересылайте логи посторонним без обезличивания, если в них может находиться чувствительная информация.
- Планируйте ротацию и удаление старых логов по политике хранения данных вашей организации.
Практические советы и распространённые ошибки
- Выставляйте Sample Interval осознанно. Для поиска коротких пиков — 1s, для долгосрочного тренда — 15–60s.
- Не добавляйте в один набор слишком много счётчиков с частотой 1s — рост нагрузки при сборе возможен. Тестируйте влияние самого мониторинга на систему.
- При анализе всегда смотрите несколько представлений: Lines для временных событий и Reports для агрегатов.
- Сохраняйте шаблоны Data Collector Set для повторного быстрого использования.
Что делать, если вы новичок
- Создайте простой Data Collector Set с рекомендованным набором счётчиков (CPU, Available MBytes, % Disk Time, Network Bytes).
- Запустите его на 60 секунд при нормальной работе системы.
- Загрузите лог и посмотрите Lines и Reports.
- Сравните средние и пиковые значения. Это поможет создать базовую «контрольную линию» производительности вашей машины.
Заключение
Performance Monitor — мощный инструмент для глубокого исследования производительности Windows. Он помогает собирать доказательные данные, планировать улучшения и подтверждать эффект внесённых изменений. Комбинируйте PerfMon с другими утилитами (Sysinternals, Event Viewer, Wireshark) и используйте методический подход: гипотеза → сбор данных → анализ → действие → проверка.
Have you used Performance Monitor before? Если нет — попробуйте создать простой Data Collector Set и собрать лог при обычной нагрузке. Это даст вам ценную отправную точку.
Summary:
- PerfMon эффективен для поиска причин медлительности.
- Создавайте Data Collector Set и планируйте сборы.
- Используйте частоту выборки 1s для поиска пиков.
- Сопоставляйте счётчики между собой и с логами событий.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
