Как пользоваться csplit в Linux: полное руководство

csplit — популярная утилита для разделения содержимого текстового файла на отдельные файлы. В отличие от split, которая режет по байтам или строкам фиксированного размера, csplit ориентируется на контекст — номера строк или регулярные выражения в содержимом.
Краткое определение
csplit — инструмент для разделения текстовых файлов на фрагменты, определяемые контекстными строками или номерами строк. Полезен, когда нужно выделить разделы логов, отчётов, конфигураций или документов по содержимому.
Базовый синтаксис
csplit [ОПЦИЯ]... ФАЙЛ ШАБЛОН...Где “ШАБЛОН” может быть числом (номер строки), регулярным выражением (/PATTERN/), либо повтором ({N}).
Почему csplit вместо split
split удобен для простого разрезания по размеру (байты/строки). Если же нужно разделить документ по заголовкам, меткам или номерам строк — split не подходит. csplit читает содержимое и формирует фрагменты по контексту.
Установка csplit
Во многих дистрибутивах csplit уже входит в пакет coreutils. Если команда отсутствует, установите пакет:
Ubuntu / Debian:
sudo apt-get install coreutilsArch Linux:
sudo pacman -S coreutilsFedora / RHEL:
sudo dnf install coreutilsБыстрый пример: создание файла и разделение
Создайте файл и добавьте в него содержимое:
touch filename.txt
nano filename.txtПосле редактирования сохраните (Ctrl+X, затем Y в nano). Просмотреть содержимое:
cat filename.txt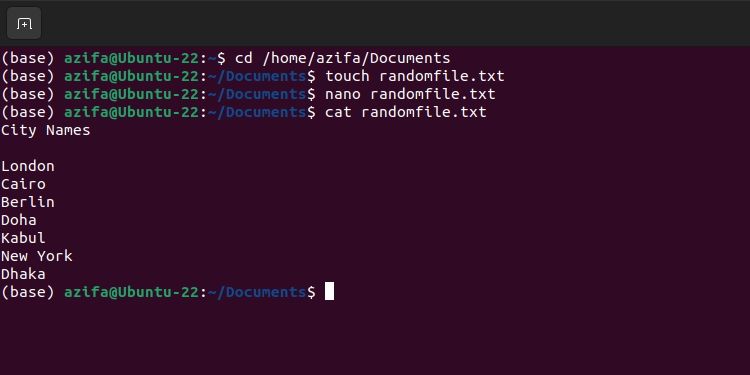
Предположим, файл содержит 9 строк с числами от 1 до 9. Чтобы разделить файл так, чтобы первая часть содержала первые две строки, а вторая — остальные, укажите номер строки, с которой начинается следующий фрагмент. Например, чтобы разделить с третьей строки:
csplit filename.txt 3Команда создаст файлы по умолчанию с префиксом xx: xx00 и xx01. Проверить можно командами ls и cat.

Часто используемые опции csplit
Ниже — список полезных опций с примерами.
Изменение префикса результирующих файлов
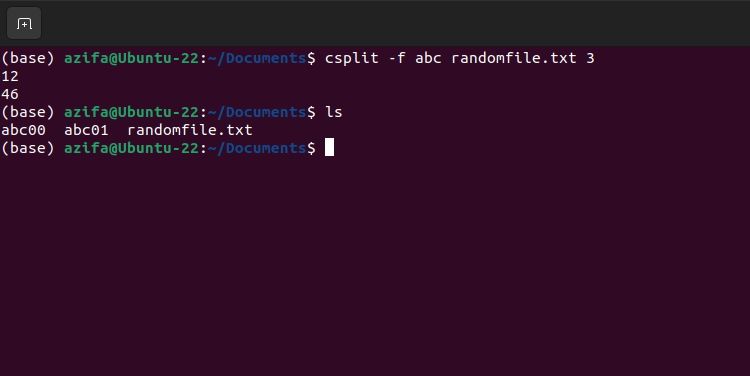
Флаг -f задаёт префикс для имён выходных файлов. По умолчанию префикс — xx.
csplit -f abc filename.txt 3После этого файлы будут abc00, abc01 и т.д.
Сохранение файлов при ошибках
Флаг -k или –keep-files не удаляет промежуточные файлы в случае ошибки выполнения.
csplit -k randomfile.txt 2 {3}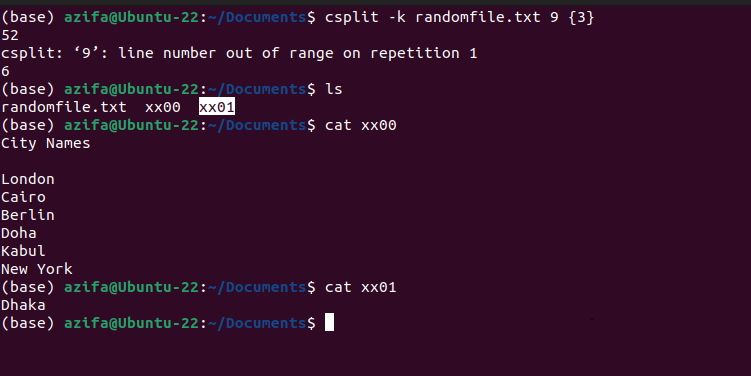
Количество цифр в суффиксе
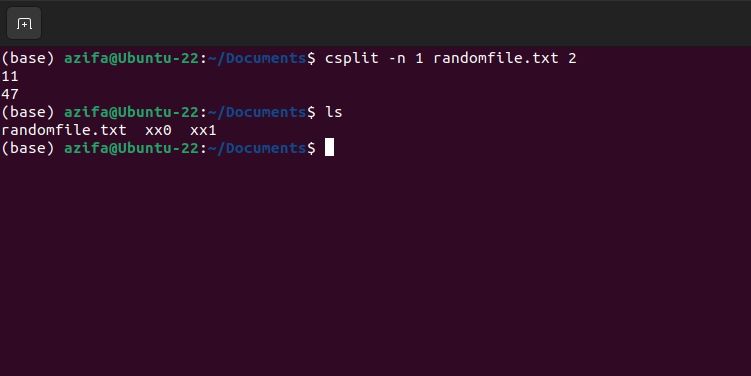
Флаг -n задаёт количество цифр в суффиксе имени.
csplit -n 1 randomfile.txt 2По умолчанию используется два знака (xx00, xx01).
Тихий режим
Флаг -s подавляет вывод размерной информации о созданных файлах.
csplit -s randomfile.txt 3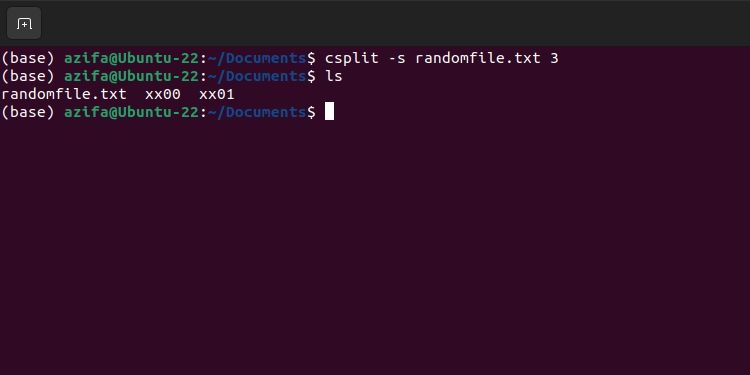
Справка и версия
csplit --help
csplit --version
Подавление совпадающей строки
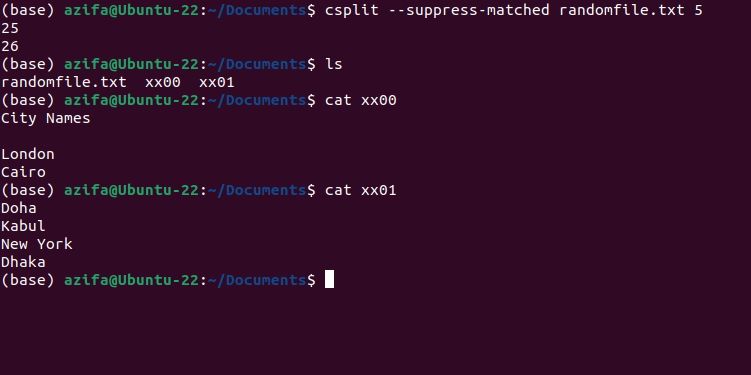
Опция –suppress-matched убирает строку, по которой произошло совпадение, из выходного фрагмента.
csplit --suppress-matched filename.txt 5Если на пятой строке было слово Berlin, оно будет опущено в результирующем фрагменте.
Как задавать шаблоны: номера строк и регулярные выражения
- Число N: разделить перед N-й строкой — укажите N. Пример: 3.
- /PATTERN/: разделить перед строкой, соответствующей регулярному выражению PATTERN. Пример: /Chapter [0-9]+/.
- %PATTERN%: разделить и удалить совпадающую строку (альтернативный синтаксис в некоторых версиях).
- {N}: повтор предыдущего шаблона N раз.
Пример: разделить файл перед каждой строкой, содержащей “—“:
csplit file.txt '/---/' '{*}'Здесь ‘{*}’ означает повторять шаблон до конца файла.
Практические сценарии использования
- Разделение логов по датам или меткам: используйте регулярные выражения, соответствующие началу блока лога.
- Отделение глав в Markdown или в тексте по заголовкам (например, /^# /).
- Извлечение отдельных писем из mbox-файла по строке “From “.
- Разделение больших CSV/TSV файлов по заголовкам секций (если есть метки разделения).
Примеры (с пояснениями)
- Разделить файл по строке, содержащей “BEGIN SECTION”:
csplit big.txt '/BEGIN SECTION/' '{*}'- Разделение с удалением строки‑разделителя:
csplit --suppress-matched big.txt '/^### /' '{*}'- Задать собственный префикс и один знак суффикса:
csplit -f part -n 1 big.txt 10- Разделить на куски по 1000 строк (альтернативный сценарий — split удобнее для этого):
split -l 1000 big.txt chunk_Когда csplit не подходит
- Если нужно разделить файл по фиксированному числу строк или байтов — split проще и быстрее.
- Для бинарных файлов csplit не предназначен — он рассчитан на текстовые данные.
- Если требуются сложные преобразования внутри фрагментов (например, фильтрация колонок), лучше сочетать csplit с awk/sed или писать скрипт.
Важно: csplit не гарантирует атомарности действий при работе в каталоге с параллельными процессами. В сценариях с высокой конкуренцией используйте временные каталоги и атомарные переименования.
Альтернативные инструменты и подходы
- split — разрезание по размеру/строкам.
- awk — гибкая обработка и условное разделение по шаблонам; полезен, если нужно одновременно преобразовать данные.
- sed — может удалять/вставлять и формировать фрагменты в потоке.
- python/perl — для сложной логики разделения и пост‑обработки.
Короткая подсказка: если задача — просто найти и разбить по шаблону без дополнительной логики, csplit проще. Если нужна трансформация данных — используйте awk/sed/python.
Ментальные модели и эвристики
- Контент‑ориентированное vs. размерное разделение: выбирайте csplit когда границы определяются содержимым (заголовки, метки), split — когда важен размер фрагмента.
- Шаблон = точка входа: при проектировании разделения сначала определите, какие строки будут служить разделителями.
- Постобработка = отдельный шаг: часто после csplit требуется переименование или валидация фрагментов — сделайте это отдельным этапом в скрипте.
Чек‑лист для ролей
Администратор:
- Проверить наличие coreutils
- Выполнить резервную копию исходного файла
- Использовать -k при возможных ошибках
- Проверить права на созданные файлы
Разработчик/автор контента:
- Определить шаблоны разделителей
- Проверить, нужно ли удалять разделяющие строки (–suppress-matched)
- Протестировать на контрольном наборе данных
CI/CD инженер:
- Поместить операции в скрипт с проверкой ошибок
- Использовать временные директории и атомарное mv
- Логировать результаты выполнения
Критерии приёмки
- Все ожидаемые фрагменты созданы и соответствуют шаблону разделения.
- Количество строк суммарно равно исходному (если не использовали –suppress-matched).
- Имена файлов соответствуют соглашению (префикс/цифры).
- Права доступа и владельцы файлов корректны.
- Процесс можно повторить без побочных эффектов.
Тестовые случаи и приемочные проверки
- Тест 1: Маленький файл (10 строк) — разделение по 3-й строке. Ожидается два файла: первые 2 строки и оставшиеся 7.
- Тест 2: Файл с несколькими совпадениями шаблона — проверить, что количество фрагментов равно количеству разделителей + 1 (если не используется повторение).
- Тест 3: Использование –suppress-matched — убедиться, что разделяющие строки отсутствуют.
- Тест 4: Отсутствие совпадения шаблона — команда должна вернуть код ошибки и не удалять уже созданные фрагменты, если использована опция -k.
Критерий успеха: тесты проходят в автоматическом окружении и файлы валидируются на соответствие ожиданиям.
Шпаргалка (Cheat sheet)
- Разделить перед строкой N: csplit file N
- Разделить по регулярному выражению: csplit file ‘/PATTERN/‘
- Повторять до конца: использовать ‘{*}’ или ‘{N}’
- Указать префикс: -f prefix
- Количество цифр: -n 1
- Подавить вывод размеров: -s
- Не удалять файлы при ошибке: -k
- Удалить совпадающую строку: –suppress-matched
Советы по безопасности и надёжности
- Работайте с копией исходного файла, если файл важен.
- Не выполняйте csplit с непроверенными регулярными выражениями в пользовательском вводе — возможны ошибки или неожиданные разделения.
- В скриптах используйте set -e и проверку кода возврата csplit.
Совместимость и переносимость
csplit входит в coreutils и присутствует в большинстве современных Unix‑подобных систем. Поведение опций может немного отличаться между версиями coreutils; при переносе скриптов учитывайте наличие флагов –suppress-matched и детализацию повторов.
Типичные ошибки и как их исправлять
- Ошибка: csplit: command not found — установите coreutils.
- Ошибка: неверный шаблон — проверьте синтаксис регулярного выражения/количество фигурных скобок.
- Несоответствие ожидаемому количеству файлов — проверьте поведение повторов (‘{N}’ vs ‘{*}’).
Примеры использования в реальных сценариях
- Извлечь статьи из большого Markdown по заголовкам уровня 1 и убрать сам заголовок:
csplit --suppress-matched book.md '/^# /' '{*}'- Разбить mbox по письмам (строки, начинающиеся с “From “):
csplit -f mail- -n 3 mbox '/^From /' '{*}'- В CI: автоматическое разделение и проверка целостности:
mkdir -p /tmp/split_test
csplit -s big.log '/^2026-/' '{*}' || exit 1
for f in xx*; do wc -l "$f"; doneКраткое резюме
csplit — простой и надёжный инструмент для разделения текстовых файлов по содержимому. Его используют, когда важны логические границы внутри файла: заголовки, метки, даты и т.п. Если задача — просто разделение по размеру, применяйте split; если требуется гибкая обработка — комбинируйте csplit с awk/sed или используйте скрипты на Python.
- Выберите csplit для разбиения по шаблонам и номерам строк.
- Используйте –suppress-matched, если разделяющая строка не должна попадать в фрагмент.
- Применяйте -f и -n для управления именами выходных файлов.
Спасибо за прочтение. Если нужно, могу подготовить готовые скрипты для конкретного формата логов или документов.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
