Scikit-LLM: интеграция LLM в scikit-learn и практические примеры

Scikit-LLM — это пакет Python, который упрощает интеграцию крупных языковых моделей (LLM) в экосистему scikit-learn. Он помогает решать задачи анализа текста, сохраняя знакомую декларативную модель fit/predict/transform. Если вы знакомы со scikit-learn, работать со Scikit-LLM будет проще.
Важно: Scikit-LLM не заменяет scikit-learn. scikit-learn — общая библиотека для машинного обучения. Scikit-LLM специально ориентирован на задачи обработки естественного языка с использованием LLM.
Начало работы со Scikit-LLM
Ниже — практическое руководство по установке, настройке ключа API и первым экспериментам. Сохраните примеры кода как однофайловые заметки, чтобы быстро воспроизводить эксперименты.
Установка и виртуальное окружение
Создайте виртуальное окружение в вашей IDE, чтобы избежать конфликтов зависимостей. Затем выполните:
pip install scikit-llm Эта команда установит Scikit-LLM и требуемые зависимости.
Получение и настройка API-ключа OpenAI
Scikit-LLM использует API LLM-провайдеров (например, OpenAI). Прежде чем использовать модель, получите ключ у провайдера и сохраните его в надёжном месте.
- Перейдите на страницу API вашего LLM-провайдера (в примере — OpenAI).
- Откройте профиль в правом верхнем углу и выберите управление ключами.
- Нажмите кнопку создания нового секретного ключа.
- Скопируйте ключ и сохраните его — провайдер может не показать ключ повторно.
После получения ключа в коде подключите конфигурацию Scikit-LLM:
from skllm.config import SKLLMConfig
# Set your OpenAI API key
SKLLMConfig.set_openai_key("Your API key")
# Set your OpenAI organization
SKLLMConfig.set_openai_org("Your organization ID")Пояснение: organization ID — уникальный идентификатор вашей организации в OpenAI и отличается от имени организации. Получите его в настройках организации.
Важно: Scikit-LLM требует аккаунт с моделью оплаты по факту (pay-as-you-go). Бесплатный пробный аккаунт OpenAI обычно ограничен по скорости (rate limit), что может приводить к ошибкам при массовых запросах.

Для подробностей смотрите страницу лимитов провайдера. Кроме OpenAI вы можете использовать и других LLM-поставщиков, совместимых со Scikit-LLM.
Импорт библиотек и загрузка датасета
Импортируйте pandas и необходимые классы из scikit-learn и Scikit-LLM:
import pandas as pd
from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier
from skllm.preprocessing import GPTSummarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MultiLabelBinarizer Загрузите датасет (в примере используется IMDB). Здесь показан простой способ загрузки CSV и выборка первых 100 строк для ускорения экспериментов:
# Load your dataset
data = pd.read_csv("imdb_movies_dataset.csv")
# Extract the first 100 rows
data = data.head(100)Вы можете использовать весь датасет — ограничение первых 100 записей необязательно, но полезно для быстрых проверок.
Далее выделите признаки и метки, затем разделите данные на обучающую и тестовую выборки:
# Extract relevant columns
X = data['Description']
# Assuming 'Genre' contains the labels for classification
y = data['Genre']
# Split the dataset into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) Колонка Genre содержит метки, которые мы хотим предсказывать.
Zero-shot классификация текста с Scikit-LLM
Zero-shot классификация позволяет отнести текст к заранее определённым категориям без обучения на размеченных примерах. Это удобно, когда новые категории появляются динамически или размеченные данные отсутствуют.
Пример использования ZeroShotGPTClassifier:
# Perform Zero-Shot Text Classification
zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
zero_shot_clf.fit(X_train, y_train)
zero_shot_predictions = zero_shot_clf.predict(X_test)
# Print Zero-Shot Text Classification Report
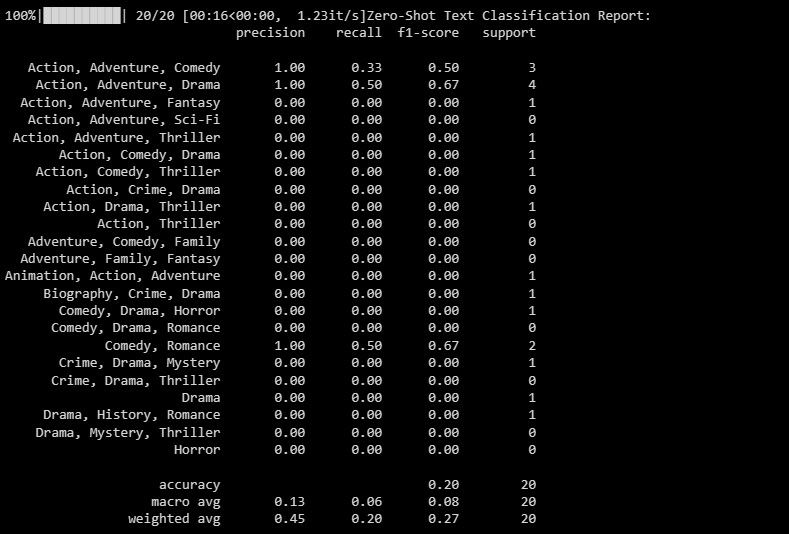
print("Zero-Shot Text Classification Report:")
print(classification_report(y_test, zero_shot_predictions))Результат показывает метрики точности по каждой метке.
Когда использовать zero-shot: быстрые проверки гипотез, прототипирование, анализ множественных классов без разметки. Когда не использовать: строгие production-системы с требованием стабильной воспроизводимости и контролируемой качества на больших объёмах — там лучше полноценное обучение на размеченных данных.
Мульти-меточная zero-shot классификация
Один документ может относиться к нескольким жанрам одновременно. Для таких задач используйте MultiLabelZeroShotGPTClassifier:
# Perform Multi-Label Zero-Shot Text Classification
# Make sure to provide a list of candidate labels
candidate_labels = ["Action", "Comedy", "Drama", "Horror", "Sci-Fi"]
multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2)
multi_label_zero_shot_clf.fit(X_train, candidate_labels)
multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test)
# Convert the labels to binary array format using MultiLabelBinarizer
mlb = MultiLabelBinarizer()
y_test_binary = mlb.fit_transform(y_test)
multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions)
# Print Multi-Label Zero-Shot Text Classification Report
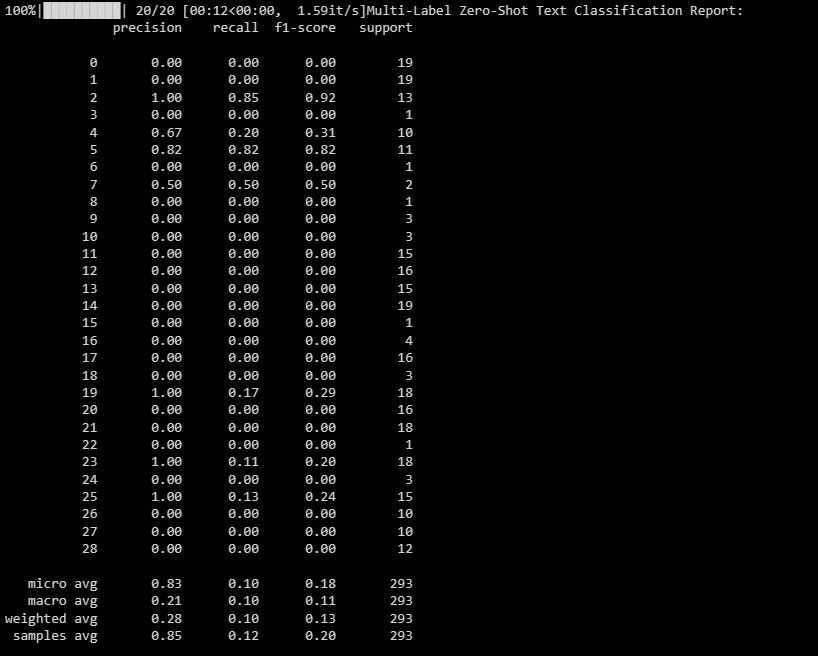
print("Multi-Label Zero-Shot Text Classification Report:")
print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary))Здесь вы задаёте кандидатов для меток, после чего модель выбирает до max_labels наиболее подходящих.
Векторизация текста
Текст нужно переводить в числовой вид для классических алгоритмов. Помимо GPT-векторизаторов, часто используют TF-IDF. Пример TF-IDF:
# Perform Text Vectorization using TF-IDF
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
# Print the TF-IDF vectorized features for the first few samples
print("TF-IDF Vectorized Features (First 5 samples):")
print(X_train_tfidf[:5]) # Change to X_test_tfidf if you want to print the test set 
GPTVectorizer в Scikit-LLM позволяет получить плотные векторы из LLM, которые часто лучше захватывают семантику, но стоят дороже по API-запросам.
Суммаризация текста
Scikit-LLM предоставляет GPTSummarizer для компактных резюме текстов:
# Perform Text Summarization
summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15)
summaries = summarizer.fit_transform(X_test)
print(summaries) 
Суммаризация полезна для оперативного обзора больших коллекций текстов, создания сниппетов и метаданных для поиска.
Когда LLM и Scikit-LLM не подходят
Important: LLM не всегда — лучшее решение. Примеры, когда стоит избегать LLM:
- Требуется строгая воспроизводимость и детерминированность ответов.
- Необходимы жёсткие ограничения затрат и высокая частота запросов при больших объёмах данных.
- Сектор с жёсткими нормативами по защите данных, где нельзя передавать пользовательские данные сторонним сервисам.
- Когда модель должна опираться на узкоспециализированные, строго структурированные знания, доступные в небольшом объёме размеченных данных — традиционная модель обученная на локальных данных может быть лучше.
Альтернативы:
- Обучение локальной классификаторной модели (Logistic Regression, RandomForest, fine-tuned transformer) на размеченных данных.
- Использование open-source LLM, развёрнутых локально или в приватном облаке.
- Гибридный подход: TF-IDF + классические модели + LLM для постобработки.
Практические эвристики и модели мышления
- Если у вас есть >1000 размеченных примеров для задачи — сначала попробуйте обучить классификатор на локальных данных; LLM пригодится в настройке признаков и генерации подсказок.
- Для быстрого прототипа используйте zero-shot, но всегда валидируйте на небольшой размеченной выборке.
- Ограничьте длину входа к LLM и используйте предварительную фильтрацию/краткую нормализацию текста для экономии токенов.
Мини-методология эксперимента:
- Определите цель и метрики (precision/recall/F1 по классам).
- Подготовьте небольшую разметку контрольной выборки (100–500 примеров).
- Прототипируйте zero-shot и сравните с классическим baseline (TF-IDF + LogisticRegression).
- Оцените качество и стоимость (оцените количество токенов/запросов).
- Приняли решение — production: либо fine-tune локально, либо оптимизировать подсказки и кэширование запросов к LLM.
Чек-листы по ролям
Data Scientist
- Подготовить контрольную выборку
- Сравнить baseline и LLM по метрикам и затратам
- Провести анализ ошибок и составить список типичных случаев
DevOps
- Настроить безопасное хранение API-ключей (секрет-менеджер)
- Настроить мониторинг затрат и лимитов API
- Настроить ретраи и обработку ошибок rate limit
Продакт-менеджер
- Уточнить SLA и допустимые задержки
- Оценить влияние на UX при задержках ответа
- Решить политику обновления моделей и rollback
Тестовые сценарии и критерии приёмки
Критерии приёмки
- Модель должна проходить контрольную выборку с F1 не ниже установленного значения по каждому ключевому классу (укажите свои пороги).
- Время ответа на один запрос не более допустимого SLA (например, 2 секунды для интерактивных задач, если используется кэширование).
- Система корректно обрабатывает ошибки провайдера и не теряет данные при таймаутах.
Тестовые сценарии
- Тест на корректность классификации для 100 контрольных примеров.
- Тест на устойчивость: серия из 1000 коротких запросов с эмитацией пиковых нагрузок.
- Тест на обработку неожиданных форматов входных данных (пустые строки, HTML-код, очень длинные тексты).
Шаблон для записи эксперимента
| Поле | Описание |
|---|---|
| Имя эксперимента | Короткое имя |
| Дата | Дата запуска |
| Данные | Описание датасета |
| Модель | Используемый LLM или локальная модель |
| Настройки | max_labels, max_tokens, openai_model и т.д. |
| Метрики | Precision/Recall/F1 по классам |
| Затраты | Оценка количества токенов/стоимости |
| Вывод | Решение: production / доработка / отклонено |
Безопасность и конфиденциальность данных
- Храните API-ключи в менеджере секретов (Vault, AWS Secrets Manager, GCP Secret Manager).
- Не логируйте сырые пользовательские тексты и ответы LLM в открытые логи.
- Для персональных данных выполните предварительную анонимизацию перед отправкой во внешние API.
- Проверьте соответствие GDPR/локальному законодательству: если обработка персональных данных регулируется, согласуйте передачу в облачные LLM или используйте локальные решения.
Рекомендации по безопасности и жестким лимитам
- Внедрите кэширование типичных запросов, чтобы снизить количество обращений к API.
- Реализуйте экспоненциальные ретраи и backoff при ошибках rate limit.
- Мониторьте расходы и настраивайте оповещения при достижении порогов бюджета.
Совместимость и миграция между провайдерами
Scikit-LLM поддерживает подключение к разным провайдерам. При смене провайдера:
- Проверьте различия в подсчёте токенов и ценообразовании.
- Проверьте изменения в форматах ответов и политики ошибок.
- Перепроверьте контрольную выборку, так как модели разных провайдеров дают разные распределения ошибок.
Decision tree распространённых сценариев
flowchart TD
A[Нужна классификация текста?] --> B{Есть размеченные данные >1000?}
B -- Да --> C[Обучить локальную модель + TF-IDF/transformer]
B -- Нет --> D{Нужен быстрый прототип?}
D -- Да --> E[Zero-shot через Scikit-LLM]
D -- Нет --> F[Собрать разметку, затем обучить модель]
E --> G{Поведение в production приемлемо?}
G -- Да --> H[Оптимизировать подсказки и кэширование]
G -- Нет --> FПримеры ошибок и как с ними работать
Типичные ошибки:
- Rate limit от провайдера — добавьте ретраи и мониторинг.
- Непредсказуемые ответы для редких классов — расширьте контрольную выборку и используйте подсказки с примерами (few-shot) или локальное дообучение.
- Высокая стоимость на объёмах — используйте гибридный подход: LLM для сложных случаев, быстрый детерминированный классификатор для простых сценариев.
Короткая инструкция по оптимизации затрат
- Сократите количество токенов — предобрабатывайте и сокращайте входы.
- Кэшируйте частые запросы и ответы.
- Группируйте запросы (batching), если это применимо.
Краткое резюме
Scikit-LLM даёт удобный API для интеграции сильных LLM в привычные пайплайны scikit-learn: zero-shot классификация, multi-label, векторизация и суммаризация. Подойдёт для быстрого прототипирования и случаев, когда размеченные данные ограничены. Для production-проекта учитывайте вопросы стоимости, приватности и стабильности. Протестируйте подход на контрольной выборке, оцените затраты и подготовьте план миграции или fallback.
Summary:
- Используйте виртуальное окружение и безопасное хранение ключей.
- Валидируйте zero-shot на контрольной выборке перед переносом в production.
- Оптимизируйте подсказки и кэширование для снижения затрат.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
