Chat with RTX: локальный ИИ‑чат от Nvidia

TL;DR
Nvidia Chat with RTX — локальное приложение для запуска LLM на ПК с видеокартой RTX. Оно использует TensorRT‑LLM и RAG (retrieval‑augmented generation) для ускорения вывода и персонализированных ответов на основе ваших файлов. Требования: RTX 30/40, Windows 11, ~16 ГБ ОЗУ и около 100 ГБ свободного места; установка требует загрузки ~35 ГБ данных. Ниже — подробная инструкция по установке, настройке RAG, сценарии использования, проверки, советы по безопасности и альтернативы.
Быстрые ссылки
- Что такое Nvidia Chat with RTX?
- Как скачать и установить Chat with RTX
- Как использовать Nvidia Chat with RTX
- Насколько хорош Chat with RTX?
- Что делать, если у меня нет GPU серии RTX 30/40
Резюме
- Chat with RTX — локальный чат‑бот, работающий на вашем ПК и использующий TensorRT‑LLM и квантованную модель Mistral‑7B.
- Минимальные требования: видеокарта RTX 30‑ или 40‑серии, 16 ГБ оперативной памяти, ~100 ГБ свободного диска, Windows 11.
- С помощью RAG можно загружать документы и видео, чтобы чат использовал ваши данные для контекстных и персонализированных ответов.
Что такое Nvidia Chat with RTX?
Nvidia Chat with RTX — это приложение, которое позволяет запускать большой языковой модуль (LLM) локально на компьютере с поддерживаемой видеокартой. Вместо обращения к облачным сервисам (как ChatGPT) вы работаете с моделью на собственном железе, что снижает утечку данных и уменьшает задержки.
Краткие определения терминов:
- LLM — большая языковая модель, обученная на текстах, генерирует естественный язык.
- TensorRT‑LLM — оптимизатор и рантайм Nvidia для ускорения инференса LLM на видеокартах RTX.
- RAG — retrieval‑augmented generation, подход, когда модель дополняет ответ информацией, найденной в локальных документах.
Преимущества такого подхода:
- Конфиденциальность: данные остаются локально.
- Скорость: оптимизация под RTX даёт низкие задержки при ответах.
- Контекстность: RAG позволяет давать ответы на основе ваших документов и видео.
Ограничения:
- Требуется достаточно мощная GPU и свободное место на диске.
- На момент выхода в некоторых сборках поддерживается одна модель (Mistral‑7B), функциональность может расширяться в следующих релизах.
Как скачать и установить Chat with RTX

Ниже — пошаговая инструкция, расширенная советами по подготовке ПК и устранению типичных проблем.
Требования к системе (локализовано):
- Видеокарта: Nvidia RTX 30‑серии или 40‑серии (поддержка CUDA и TensorRT).
- ОЗУ: минимум 16 ГБ (рекомендуется 32 ГБ для более крупных сценариев использования).
- Дисковое пространство: около 100 ГБ свободного места; установка скачивает ~35 ГБ данных, но потребуется место для модели и кэша.
- ОС: Windows 11 (последние обновления драйверов и .NET/Visual C++ Redistributable могут потребоваться).
Подготовка перед установкой:
- Обновите драйверы Nvidia до последней WHQL‑версии через GeForce Experience или сайт Nvidia.
- Убедитесь, что в системе включён режим быстрого отклика для приложений (актуально для NVMe).
- Освободите место на диске и проверьте, что антивирус не блокирует распаковку и скачивание файлов.
- Скачайте архив установки в папку с достаточным местом (лучше на SSD/NVMe).
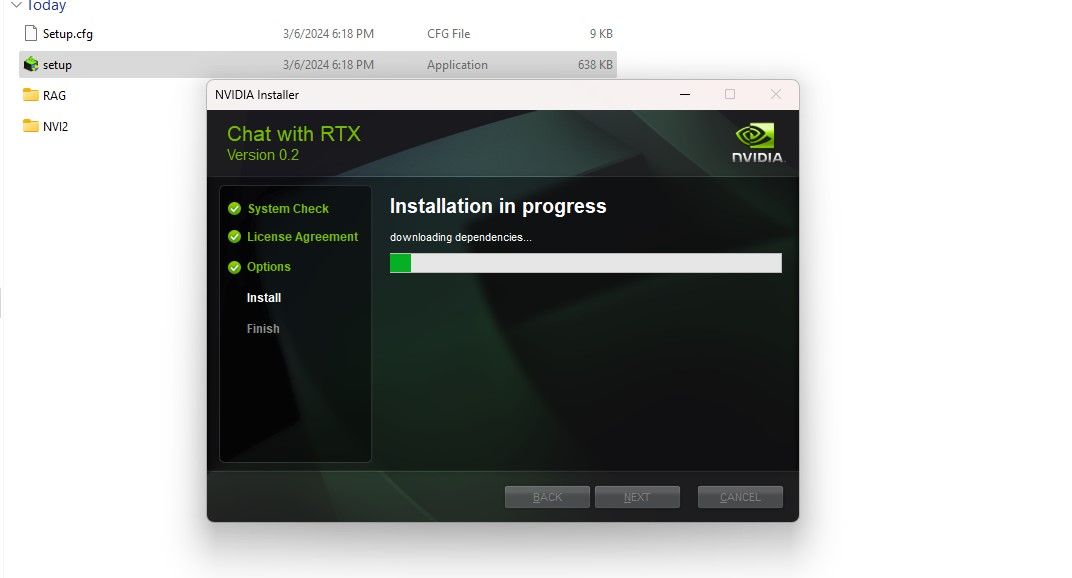
Шаги установки:
- Скачайте ZIP‑файл Chat with RTX (примерно 35 ГБ).
- Распакуйте ZIP с помощью 7‑Zip или встроенной функции «Извлечь все». Для больших архивов 7‑Zip часто надежнее.
- Откройте распакованную папку и запустите setup.exe от имени администратора (ПК‑клик → Запуск от имени администратора).
- При кастомной установке отметьте все опции, если хотите, чтобы установщик автоматически загрузил модель и зависимости.
- Установщик скачает LLM и дополнительные файлы — ожидание может занять значительное время в зависимости от скорости интернета и диска.
- После завершения нажмите «Close» или эквивалентный локализованный ответ и запустите приложение.
Чек‑лист после установки:
- Установлен ли драйвер Nvidia последних версий?
- Есть ли папка с моделью и файлом логов в каталоге приложения?
- Проходит ли приложение в режиме offline без критических ошибок?
- Видит ли Windows видеокарту и достаточно ли видеопамяти?
Типичные проблемы и их решения:
- Проблема: установка зависает на скачивании модели.
- Проверка: ограничение антивируса/файрвола; временно отключите или добавьте папку в исключения.
- Проблема: приложение не запускается из‑за .NET/VC++.
- Решение: установите недостающие компоненты Visual C++ Redistributable и обновите .NET.
- Проблема: недостаточно дискового пространства после распаковки.
- Решение: освободите место, временно переместите большие файлы, установите на диск с большим объёмом.
Как использовать Nvidia Chat with RTX
Общий поток работы с приложением:
- Подготовьте данные для RAG (если нужно).
- Укажите путь к базе (локальная папка или YouTube URL) в интерфейсе Dataset.
- Настройте параметры модели (температура, длина ответа) если они доступны.
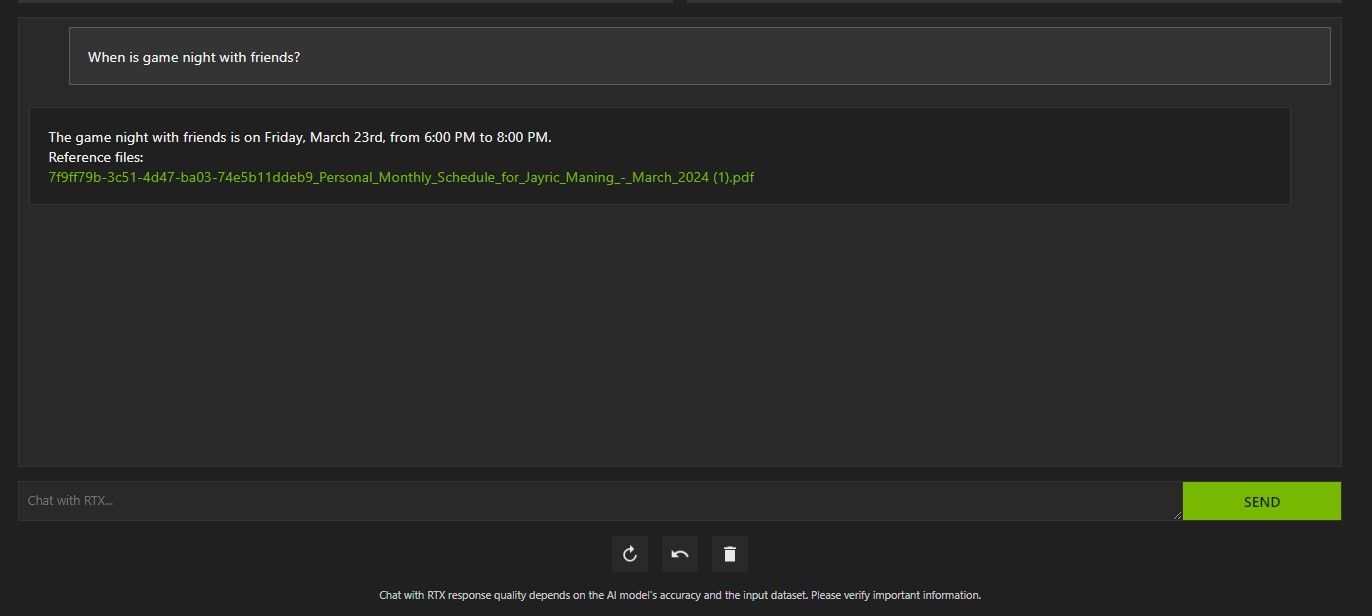
- Задавайте вопросы и проверяйте, какие документы использовались для ответа.
Шаг 1: Создание папки для RAG
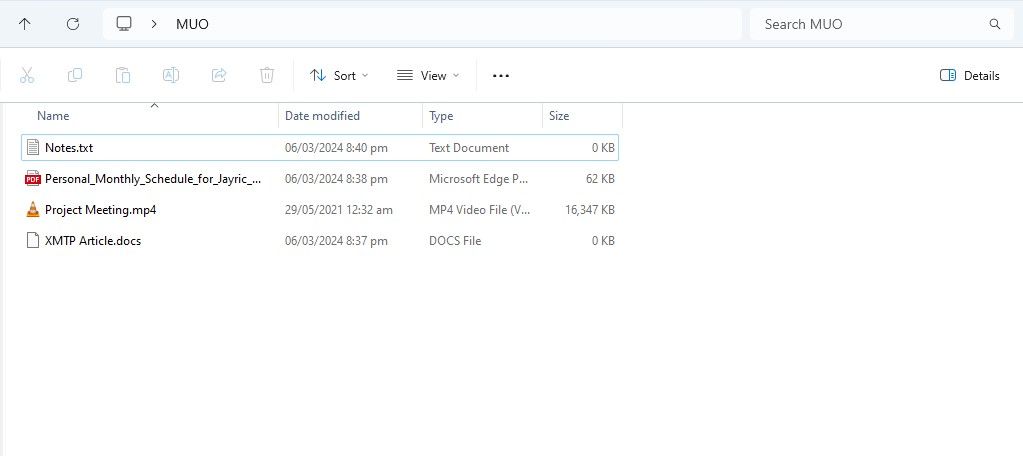
Рекомендации по содержимому папки RAG:
- Форматы: PDF, DOCX, TXT, CSV, субтитры (.srt), и ссылки на YouTube (при выборе соответствующего режима).
- Структура: организуйте файлы по темам — это ускорит поиск и снизит задержки.
- Количество: большие коллекции документов замедляют индексирование и поиск; для больших баз подумайте о разделении на тематические подкаталоги.
- Качество документов: отсканированные изображения с текстом требуют OCR‑предобработки; желательно загружать тексты в формате с доступным текстовым слоем.
Мини‑методика подготовки файлов (быстро):
- Прогоните большие PDF через OCR (если они отсканированы) и сохраните как PDF/A или TXT.
- Разделите монолитные документы на логические фрагменты (главы, разделы) — это помогает RAG находить релевантный контекст.
- Добавьте метаданные в имена файлов: YYYY‑MM‑DDтемаверсия.pdf — это поможет ориентироваться при обновлениях.
Шаг 2: Настройка окружения в приложении
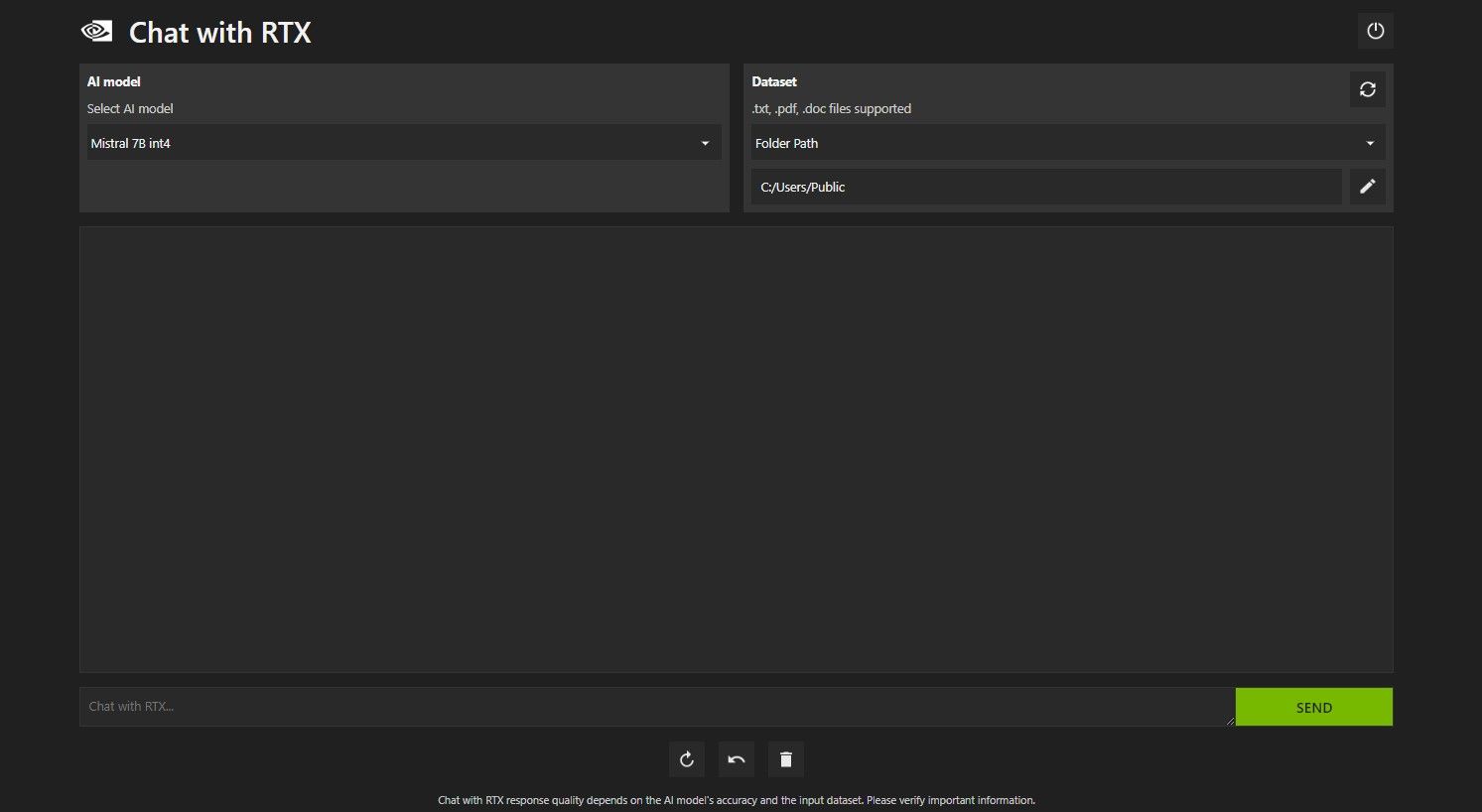
Инструкция:
- Откройте приложение и в разделе Dataset выберите опцию Folder Path.
- Нажмите на иконку редактирования (иконка карандаша) и укажите путь к вашей папке с данными.
- При наличии выбора модели можно переключиться с Mistral‑7B на другую доступную модель; если опций нет — используйте Mistral‑7B.
- Проверьте дополнительные настройки: max tokens, temperature, режим работы (online/offline), логирование.
Совет по производительности:
- Для быстрой индексации используйте SSD или NVMe; индексирование на HDD заметно медленнее.
- Если ответ слишком общий, уменьшите temperature и увеличьте max tokens.
Шаг 3: Задавайте вопросы
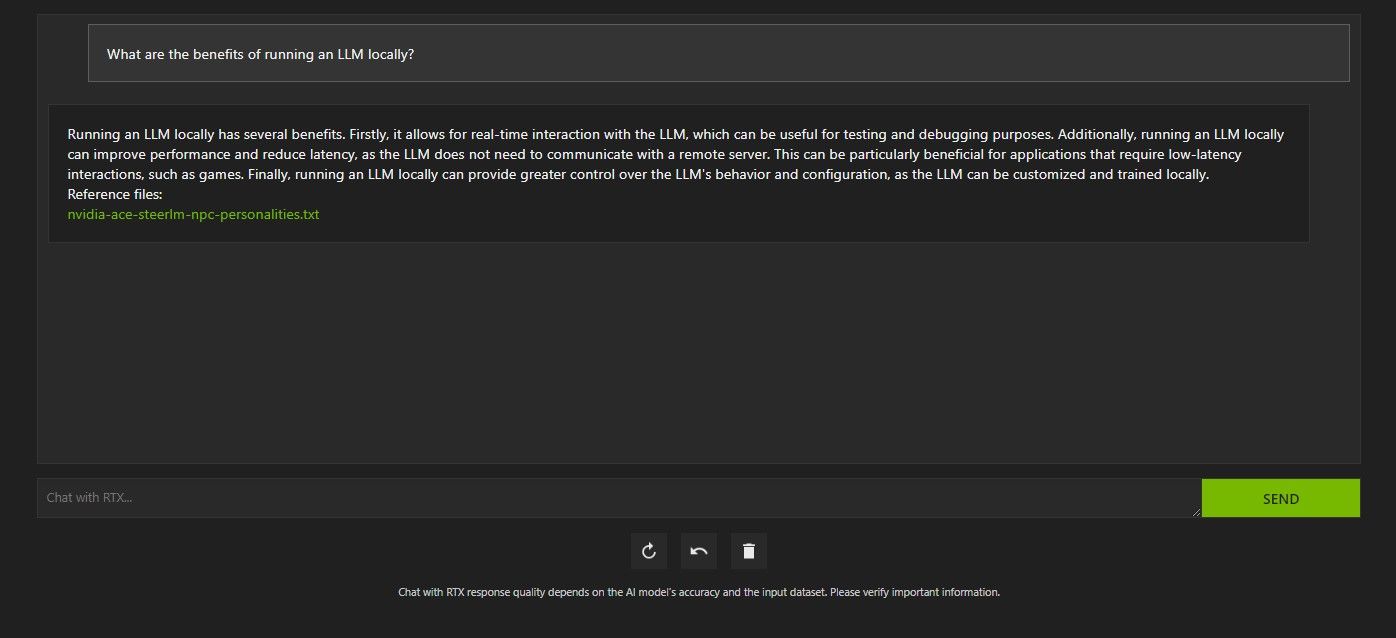
Примеры запросов по ролям:
- Для разработчика: “Сгенерируй пример кода для парсинга CSV и отображения таблицы в Python, используя мои документы в папке data/analytics”.
- Для юриста: “Сделай краткое резюме условий договора из файла 2024‑03‑contract.pdf и выдели риски”.
- Для менеджера: “Составь список задач на неделю, исходя из календаря и файла events.pdf”.
Важно: если модель использовала RAG, проверьте в интерфейсе, какие файлы были упомянуты в ответе — это помогает оценить корректность источников.
Шаг 4: Анализ YouTube‑видео
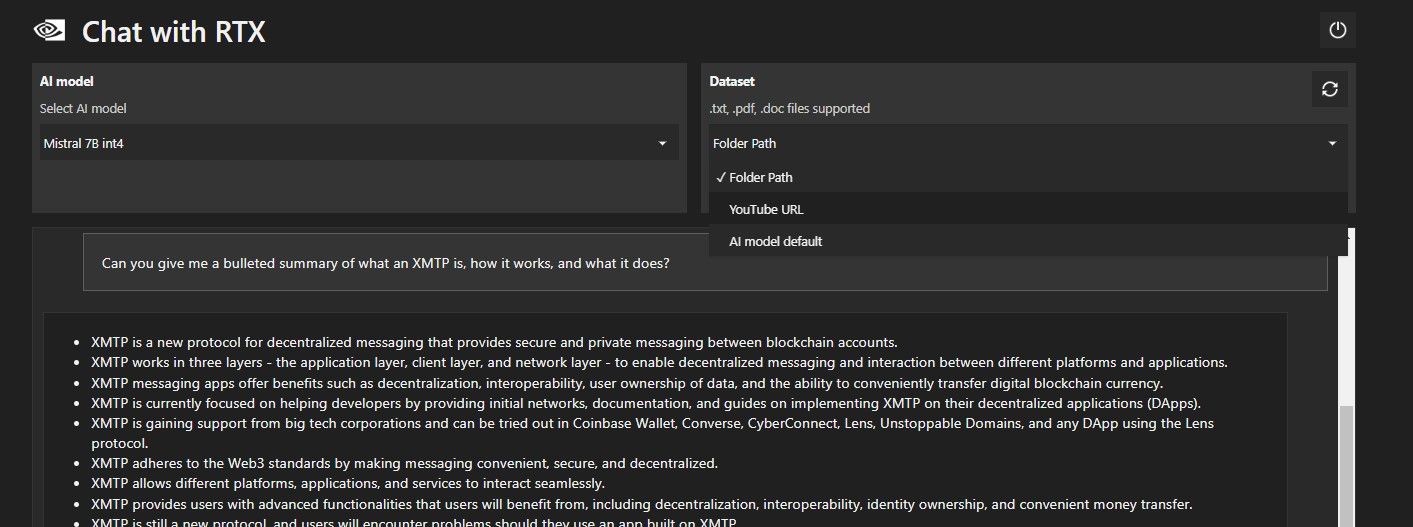
Пошагово:
- В Dataset переключите Folder Path на YouTube URL.
- Вставьте ссылку на видео и дождитесь, пока приложение извлечёт субтитры/аудио для анализа.
- Задайте вопросы: “Сделай тезисную выжимку видео” или “Какие ключевые аргументы приведены в минуте 05:00–12:00?”.
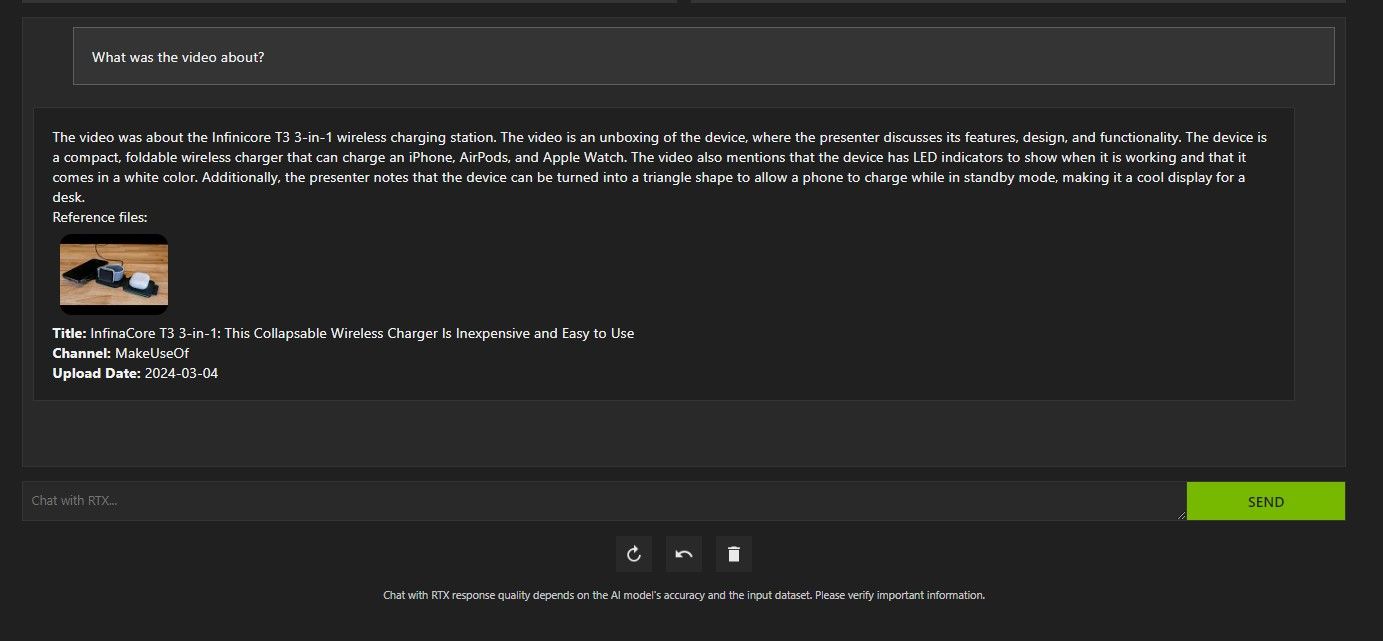
Ограничения:
- Для видео без субтитров качество извлечения зависит от распознавания речи; у коротких/шумих видео точность может снижаться.
- Длительная обработка больших видео может занять время и нагрузить систему.
Насколько хорош Chat with RTX?
Краткий ответ: полезен и выполним своей задачи, особенно если важна конфиденциальность и низкая задержка. Ниже — детальный разбор сильных и слабых сторон.
Плюсы:
- Локальный запуск — ваши данные не покидают компьютер (при корректной настройке).
- Быстрый отклик при наличии подходящего GPU благодаря TensorRT‑оптимизациям.
- RAG даёт персонализированные ответы по вашим документам и видео.
Минусы и ограничения:
- Высокие требования к железу по сравнению с лёгкими локальными решениями.
- На старых или менее мощных видеокартах функциональность недоступна.
- Версия на момент тестирования — демо; некоторые функции могут быть ограничены или изменены в релизах.
Сравнение с альтернативами:
- ChatGPT (облачный): более мощные модели, удобные интеграции, но данные отправляются в облако.
- GPT4All: лёгкая локальная альтернатива, проще в плане требований, но часто уступает по качеству и скорости на RTX‑оптимизированных установках.
- Text Generation WebUI: гибкость и тонкая настройка, требует больше ручной настройки и знаний.
Что делать, если у меня нет RTX 30/40?
Варианты для тех, у кого нет совместимой видеокарты:
- GPT4All — простая локальная опция с низкими системными требованиями; подходит для базовых задач и экспериментов.
- Text Generation WebUI — для продвинутых пользователей, предлагает больше гибкости и опций тонкой настройки.
- Облачные сервисы — использование облачных GPU (AWS, GCP, Azure) для запуска больших моделей без локальной RTX.
- Модели, оптимизированные для CPU — существуют решения, которые позволяют запустить LLM на процессоре, но они будут медленнее.
Миграционные советы:
- Экспортируйте подготовленные файлы и структуру папок из Chat with RTX, чтобы потом переиспользовать их в WebUI или GPT4All.
- Для больших коллекций данных рассмотрите предобработку и разделение на партии для поочередного индексирования.
Мини‑руководство по безопасному использованию (Security & Privacy)
- Данные остаются локально только если вы не используете опции, отправляющие запросы в облако; проверьте настройки telemety и network.
- Ограничьте доступ к папкам с данными через права пользователя, используйте шифрование диска (BitLocker) для защиты при краже устройства.
- Регулярно делайте бэкапы важных документов в зашифрованное хранилище.
- Если используете платные/онлайн подсистемы, читайте политику конфиденциальности и соглашения.
Критерии приёмки (как проверить, что всё установлено и работает корректно)
- Приложение запускается без ошибок в логах при старте.
- LLM загружен (проверяем наличие папки с моделью и её размер).
- RAG индексирует хотя бы один тестовый документ и возвращает релевантный фрагмент при запросе.
- YouTube‑анализ возвращает корректную выжимку у видео с субтитрами.
- Заданные тестовые запросы дают ответы в пределах ожидаемого времени (латентность < 5–20 с в зависимости от запроса и конфигурации).
Чек‑лист по ролям
Для конечного пользователя:
- Установить обновления Windows и драйвер Nvidia.
- Распаковать ZIP и запустить setup.exe от имени администратора.
- Создать папку для RAG и добавить 3–5 тестовых файлов.
- Проверить ответы на тестовые вопросы.
Для разработчика/интегратора:
- Проверить логи установки и инференса (debug log).
- Настроить параметры модели (температура, max tokens) и тестировать крайние случаи.
- Настроить сценарии резервного копирования и мониторинга дискового пространства.
Для IT‑администратора:
- Внедрить политику доступа к папкам и исключения антивируса.
- Убедиться в наличии образа восстановления системы и плана отката.
- Настроить инвентаризацию ПО и обновления драйверов.
Примеры тестовых запросов и критерии приёмки
- Тест 1: “Коротко опиши содержимое файла contract.pdf” — критерий: ответ содержит перечисление основных пунктов (цель, сроки, ответственность).
- Тест 2: “Сделай тезисную выжимку видео
” — критерий: ответ содержит 3–6 ключевых тезисов и метки времени. - Тест 3: “Сгенерируй пример кода для объединения CSV” — критерий: сгенерированный код компилируется/выполняется на тестовой машине.
Когда Chat with RTX может не подойти (контрпримеры)
- Большие корпоративные базы данных (миллионы документов) — локальное индексирование может быть медленным и неэффективным.
- Сложные рабочие нагрузки, требующие очень больших моделей (GPT‑4 и выше) — локальная Mistral‑7B не заменит самые крупные облачные модели.
- Сценарии с низкой толерантностью к ошибкам в юридических или медицинских выводах — требуется дополнительная валидация экспертом.
Таблица совместимости и советы по миграции
| Компонент | Требования | Советы по миграции |
|---|---|---|
| GPU | RTX 30/40 | Если нет — рассмотреть облачные GPU или лёгкие локальные решения (GPT4All). |
| Диск | SSD/NVMe лучше | Для больших баз используйте быстрый NVMe, чтобы снизить время индексирования. |
| ОС | Windows 11 | Переход с Windows 10 может требовать драйверов и обновлений .NET. |
Дерево решений: стоит ли устанавливать Chat with RTX?
flowchart TD
A[Есть RTX 30/40?] -->|Да| B[Нужна конфиденциальность данных?]
A -->|Нет| G[Рассмотреть GPT4All или облако]
B -->|Да| C[Есть 16+ ГБ ОЗУ и ~100 ГБ диска?]
B -->|Нет| H[Можно использовать облачные сервисы для гибкости]
C -->|Да| D[Устанавливать Chat with RTX]
C -->|Нет| F[Увеличить ресурсы или выбрать лёгкую локальную альтернативу]
D --> I[Подготовить данные и тестовые кейсы]Советы по оптимизации производительности
- Используйте NVMe SSD для хранения моделей и кеша.
- Увеличьте объём оперативной памяти до 32 ГБ для больших задач.
- Отключите неиспользуемые фоновые процессы и приложения, потребляющие GPU, перед запуском инференса.
- Настройте параметры модели (temperature, top_p) для управления качеством и предсказуемостью ответов.
Заключение
Chat with RTX — практичный инструмент для тех, кто хочет запускать LLM локально с акцентом на конфиденциальность и скорость на RTX‑железе. Он удобен для персональной работы, быстрого анализа документов и видео, а также для сценариев, где данные нельзя отправлять в облако. Если у вас нет совместимой видеокарты, рассмотрите GPT4All или Text Generation WebUI как альтернативы.
Ключевые выводы
- Подходит для локального, конфиденциального анализа документов и видео.
- Требует современных GPU и достаточного дискового пространства.
- Хорошо сочетается с методами RAG и предобработкой данных.
Важно: текущая версия может быть демо‑сборкой; проверяйте обновления Nvidia и читайте заметки к выпускам перед развёртыванием в продакшн.
Часто задаваемые вопросы
Нужно ли интернет‑соединение для работы Chat with RTX?
Приложение может работать локально без интернета после установки, однако для загрузки обновлений и моделей требуется соединение.
Можно ли использовать Chat with RTX на Linux?
Официальная сборка на момент публикации ориентирована на Windows 11. Для Linux стоит следить за официальными релизами и сообществом.
Как обрабатывать отсканированные PDF?
Рекомендуется прогнать их через OCR и сохранить текстовый слой — иначе RAG не сможет корректно извлечь содержимое.
Краткое резюме и дальнейшие шаги: установите приложение на тестовой машине, подготовьте несколько репрезентативных документов и прогрейте сценарии вопросов — это позволит оценить пригодность Chat with RTX именно для ваших задач.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
